






MySQL数据库编程思路及技巧分享
一、引言
在当今信息化高速发展的时代,数据库已成为企业信息化建设的核心。MySQL作为一款开源的关系型数据库管理系统,以其高效、稳定、易用等特点赢得了众多开发者的青睐。本文将分享MySQL数据库编程的思路及技巧,希望能为学习数据库编程的同学们提供一些有益的参考。
二、MySQL数据库编程思路
数据库设计
根据需求分析结果,设计合理的数据库结构。注意表的字段设计要合理、规范,避免冗余和浪费。同时,要考虑表的关联关系,确保数据的一致性和完整性。
数据操作
在数据库编程中,数据操作是最核心的部分。包括数据的增删改查(CRUD)操作。
1.基本的CRUD操作代码
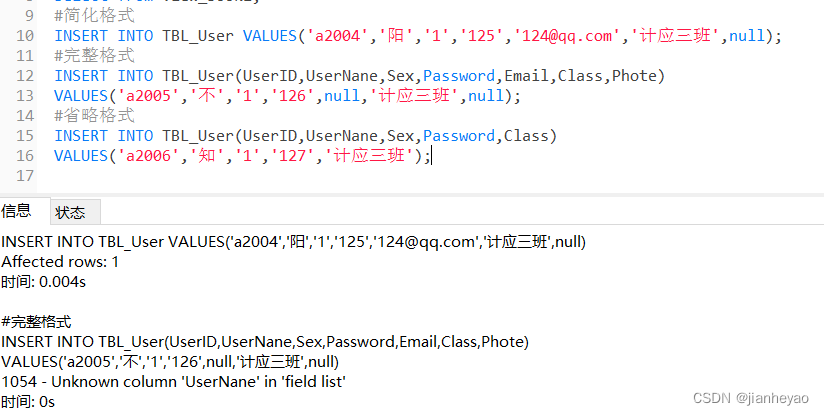
(1).创建表(Create)
首先,我们需要一个表来存储数据。以下是一个简单的用户表(users)的创建示例:
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL,
age INT
);
(2).插入数据(Insert)
向users表中插入一条新用户数据:
INSERT INTO users (name, email, age) VALUES ('John Doe', 'john@example.com', 30);
(3) 查询数据(Select)
查询所有用户
SELECT * FROM users;
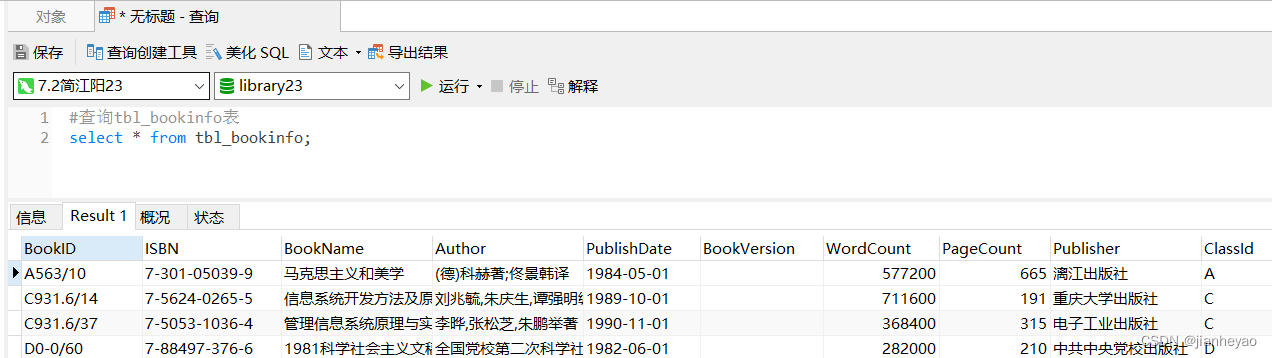
查询年龄大于25的用户
SELECT * FROM users WHERE age > 25;
查询并返回特定字段(例如,只返回名字和邮箱)
SELECT name, email FROM users;
(4)更新数据(Update)
将ID为1的用户的年龄更新为35:
UPDATE users SET age = 35 WHERE id = 1;

(5)删除数据(Delete)
删除ID为2的用户:
DELETE FROM users WHERE id = 2;

(6) 使用事务(Transaction)
以下是一个使用事务的示例,用于确保数据的一致性:
START TRANSACTION;
-- 假设我们要将用户ID为1的年龄增加1,并将其邮箱更新为新的值
UPDATE users SET age = age + 1 WHERE id = 1;
UPDATE users SET email = 'newemail@example.com' WHERE id = 1;
-- 如果以上两条语句都成功执行,则提交事务
COMMIT;
-- 如果在执行过程中发生错误,则回滚事务
-- ROLLBACK;
2.数据完整性
(1)实体完整性(Entity Integrity)
实体完整性要求每个数据表都必须有主键,且主键的值必须是唯一的,不能为空(NULL)。
主键的作用是为表中的每一行提供一个唯一的标识符,从而确保数据的唯一性。
在关系型数据库中,实体完整性通常通过主键约束(Primary Key Constraint)来实现。
(2)域完整性(Domain Integrity)
域完整性是指对数据表中字段属性的约束,包括字段的值域、字段的类型及字段有效规则等。
它确保数据表中的每一列都包含正确的数据类型和范围内的值。
域完整性可以通过设置数据类型、默认值、非空约束(NOT NULL)、CHECK约束等方式来实现。
(3)参照完整性(Referential Integrity)
参照完整性是指关系中的外键必须是另一个关系的主键有效值,或是NULL。
它确保了两个表之间的数据关系的一致性,防止了无效或不一致的数据引用。
参照完整性通常通过外键约束(Foreign Key Constraint)来实现,当在一个表中插入或更新数据时,数据库管理系统会检查这些更改是否违反了外键约束。
3.子查询
(1)子查询在 SELECT 子句中使用
子查询可以在 SELECT 子句中作为表达式的一部分,通常用于返回单个值。
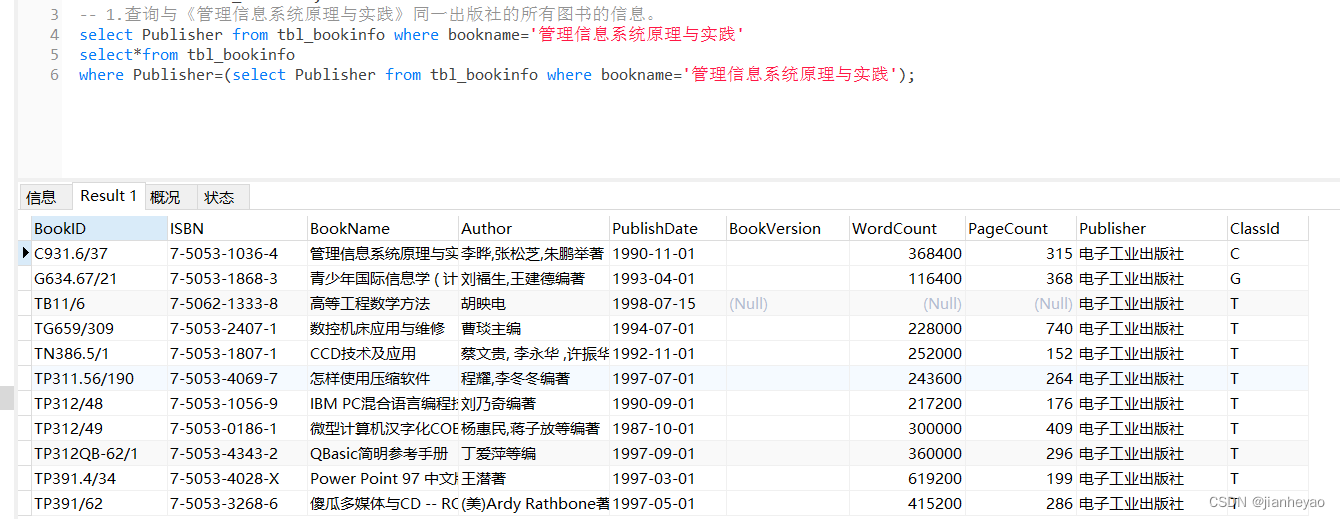
示例:查询每个部门的平均工资,并返回平均工资高于 3000 的部门名称和平均工资。
SELECT department_name, (SELECT AVG(salary) FROM employees WHERE employees.department_id = departments.id) AS avg_salary
FROM departments
WHERE (SELECT AVG(salary) FROM employees WHERE employees.department_id = departments.id) > 3000;
(2) 子查询在 FROM 子句中使用(内联视图或派生表)
子查询可以作为虚拟表(内联视图或派生表)在 FROM 子句中使用。
示例:查询每个部门的员工数量。
SELECT department_name, COUNT(*) AS num_employees
FROM (
SELECT department_id, employee_name
FROM employees
) AS employee_departments
JOIN departments ON employee_departments.department_id = departments.id
GROUP BY department_name;
(3) 子查询在 WHERE 子句中使用
子查询在 WHERE 子句中经常用于过滤记录。
示例:查询工资高于本部门平均工资的员工信息。
SELECT *
FROM employees e1
WHERE e1.salary > (
SELECT AVG(salary)
FROM employees e2
WHERE e2.department_id = e1.department_id
);
(4)子查询在 HAVING 子句中使用
HAVING 子句通常与 GROUP BY 一起使用,用于过滤分组后的结果。子查询可以在 HAVING 子句中提供分组条件。
示例:查询员工数量超过 5 人的部门。
SELECT department_name, COUNT(*) AS num_employees
FROM employees
GROUP BY department_id, department_name
HAVING num_employees > (SELECT COUNT(*) FROM departments WHERE num_employees <= 5); -- 注意:这里的 departments.num_employees 是假设的,实际中需要另外计算
(5)EXISTS 子查询
EXISTS 子查询用于检查子查询是否返回任何结果。如果子查询返回至少一行,则 EXISTS 返回 TRUE。
示例:查询有员工的部门。
SELECT department_name
FROM departments
WHERE EXISTS (
SELECT 1
FROM employees
WHERE employees.department_id = departments.id
);
(6) IN 子查询
IN 子查询允许将某个列的值与子查询返回的结果集进行比较。
示例:查询在部门 ID 为 1、2 或 3 的部门工作的员工信息。
SELECT *
FROM employees
WHERE department_id IN (1, 2, 3);
-- 或者使用子查询来动态获取部门 ID
SELECT *
FROM employees
WHERE department_id IN (SELECT id FROM departments WHERE some_condition);
4.索引、视图和存储过程
(1)使用索引(Index)
假设我们在users表的email字段上创建一个索引,以便更快地通过邮箱查找用户:
CREATE INDEX idx_email ON users(email);
现在,当我们按邮箱查询用户时,数据库将能够更快地定位到数据:
SELECT * FROM users WHERE email = 'john@example.com';
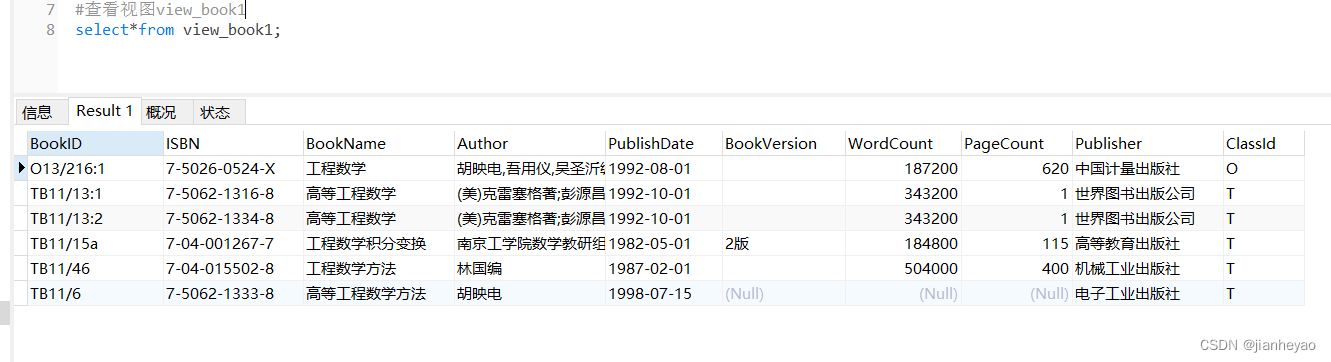
(2) 使用视图(View)
假设我们想要一个只包含年龄大于30岁的用户的视图:
CREATE VIEW senior_users AS
SELECT * FROM users WHERE age > 30;
现在,我们可以直接查询这个视图来获取年龄大于30岁的用户,而不需要每次都写完整的WHERE子句:
SELECT * FROM senior_users;
(3)使用存储过程(Stored Procedure)
假设我们想要一个存储过程来插入新用户,并自动分配一个唯一的ID:
DELIMITER //
CREATE PROCEDURE InsertNewUser(IN p_name VARCHAR(50), IN p_email VARCHAR(100), IN p_age INT)
BEGIN
INSERT INTO users (name, email, age) VALUES (p_name, p_email, p_age);
SELECT LAST_INSERT_ID() AS new_user_id; -- 返回新插入用户的ID
END //
DELIMITER ;
现在,我们可以调用这个存储过程来插入新用户,并立即获取他们的ID:
CALL InsertNewUser('Jane Smith', 'jane@example.com', 28);
性能优化
性能优化是数据库编程中不可忽视的一环。我们可以通过优化SQL语句、调整数据库参数、使用缓存等技术手段来提高数据库的性能。
安全性保障
在数据库编程中,安全性至关重要。我们要采取一系列措施来保障数据库的安全,如设置用户权限、备份与恢复、数据加密等。
三、MySQL数据库编程技巧
优化SQL语句
SQL语句的性能直接影响数据库的查询性能。我们可以通过减少全表扫描、使用连接(JOIN)代替子查询、优化嵌套查询等方式来优化SQL语句。
1.以下是一些优化SQL语句的示例,包括减少全表扫描、使用连接(JOIN)代替子查询以及优化嵌套查询:
(1)减少全表扫描
示例:假设我们有一个users表,并且我们想要查询所有名为"John"的用户。
未优化的SQL(可能导致全表扫描):
SELECT * FROM users WHERE name = 'John';
优化:如果name字段上已经有了索引,那么上述查询就是优化的。但如果没有索引,我们应该添加一个索引来减少全表扫描:
CREATE INDEX idx_name ON users(name);
(2)使用连接(JOIN)代替子查询
示例:假设我们有两个表,users和orders,我们想要查询所有下过订单的用户及其订单数量。
使用子查询的SQL:
SELECT u.id, u.name, (SELECT COUNT(*) FROM orders o WHERE o.user_id = u.id) AS order_count
FROM users u;
使用JOIN的SQL(通常更高效):
SELECT u.id, u.name, COUNT(o.id) AS order_count
FROM users u
LEFT JOIN orders o ON u.id = o.user_id
GROUP BY u.id, u.name;
(3)优化嵌套查询
示例:假设我们想要查询所有下过订单且订单金额大于100的用户。
未优化的嵌套查询(可能不是最高效的):
SELECT *
FROM users u
WHERE EXISTS (
SELECT 1 FROM orders o WHERE o.user_id = u.id AND o.amount > 100
);
优化后的SQL(使用JOIN):
SELECT DISTINCT u.*
FROM users u
JOIN orders o ON u.id = o.user_id AND o.amount > 100;
或者,如果只需要用户ID和名称,可以直接在SELECT子句中指定这些字段,而不需要使用DISTINCT。
四、总结
1.关键字及术语
表一
| create | 创建(数据库、表等) |
| show | 查看(数据库、表等) |
| drop | 删除(数据库、表等) |
| alter | 修改(数据库、表等) |
| insert | 插入(数据、记录) |
| delete | 删除(数据、记录) |
| update | 修改(数据、记录) |
| set | 设置 |
| query | 查询 |
| year | 年 |
| field | 字段 |
| delimiter | 分隔符 |
| exists | 存在 |
| int | 整数类型 |
| tinyint | 微整数类型 |
| smallint | 小整数类型 |
| mediumint | 中整数类型 |
| bigint | 大整数类型 |
| unsigned | 无符号的 |
| zerofill | 填充0 |
| float | 单精度浮点类型 |
| double | 双精度浮点类型 |
| decimal | 定点小数类型 |
| numeric | 数字 |
| fixed | 固定类型 |
| char | 定长字符类型 |
| varchar | 可变长字符类型 |
| binary | 二进制类型 |
| enum | 单选类型/枚举类型 |
| set | 多选类型(数据类型的一种) |
| bit | 比特类型 |
表二
| primary key | 主键 |
| unique key | 唯一键 |
| auto_increment | 自增长 |
| default | 默认值 |
| comment | 说明 |
| index | 索引 |
| key | 键 |
| foreign key | 外键 |
| fulltext key | 全文索引 |
| constraint | 约束 |
| engine | 存储引擎 |
| show | 显示 |
| describe | 描述 |
| rename | 重命名 |
| load | 加载 |
| identify | 标识 |
| null | 空 |
| not null | 非空 |
| datetime | 日期时间 |
| date | 日期 |
| time | 时间 |
| timestamp | 时间戳 |
| text | 长文本类型 |
| blob | 二进制形式的长文本类型 |
| values | 值 |
表三
| select | 选择;查询;检索 |
| from | 从… |
| order | 顺序 |
| distinct | 区分的 |
| where | 哪里 |
| group | 组 |
| as | 作为 |
| in | 在…里面 |
| like | 像…一样 |
| limit | 限制 |
| count | 计数 |
| avg | 平均 |
| max | 最大 |
| min | 最小 |
| sum | 总和 |
| asc | 升序的 |
| desc | 降序的 |
| join | 连接 |
| inner | 内部的 |
| cross | 交叉的 |
| left | 左边 |
| right | 右边 |
| outer | 外面的 |
| in | 在…里面 |
| any | 任意一个 |
| all | 全部 |
| some | 其中一部分 |
| union | 联合的 |
| replace | 替换 |
2.常见错误号
| 序号 | 错误号 | 说明 |
| 1 | #1064 | 语法错误 |
| 2 | #1049 | 数据库对象不存在 |
| 3 | #1007 | 数据库对象已存在 |
| 4 | #1146 | 表对象不存在 |
| 5 | #1050 | 表(视图)对象已存在 |
| 6 | #1054 | 某列(字段)不存在 |
| 7 | #1136 | 列的个数与值的个数不一致 |
| 8 | #1366 | 值与数据类型或字符集不匹配(#1265#1292) |
| 9 | #1406 | 值超过定义长度 |
| 10 | #1048 | 某列(字段)不允许空(检查不允许空列、主键列) |
| 11 | #1364 | 某列(字段)不允许空又没有默认值(检查不允许空列、主键列) |
| 12 | #1062 | 某列(字段)不允许重复值(检查唯一键列、主键列) |
| 13 | #1451 | 违反外键约束,主表的当前值在被外键引用(主表删除或修改记录时) |
| 14 | #1452 | 违反外键约束,外键引用的值主表不存在(从表插入或修改记录时) |
| 15 | #1046 | 没有选择数据库 |
| 16 | #1005 | 外键定义出错 |
| 17 | #1068 | 重复的主键定义 |















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









