






芯片字符OCR文字识别项目实战教学文档 (本文提供完整数据集、项目代码、英伟达4090D显卡服务器环境)
一、环境准备与数据预处理
1.0 进入ocr项目
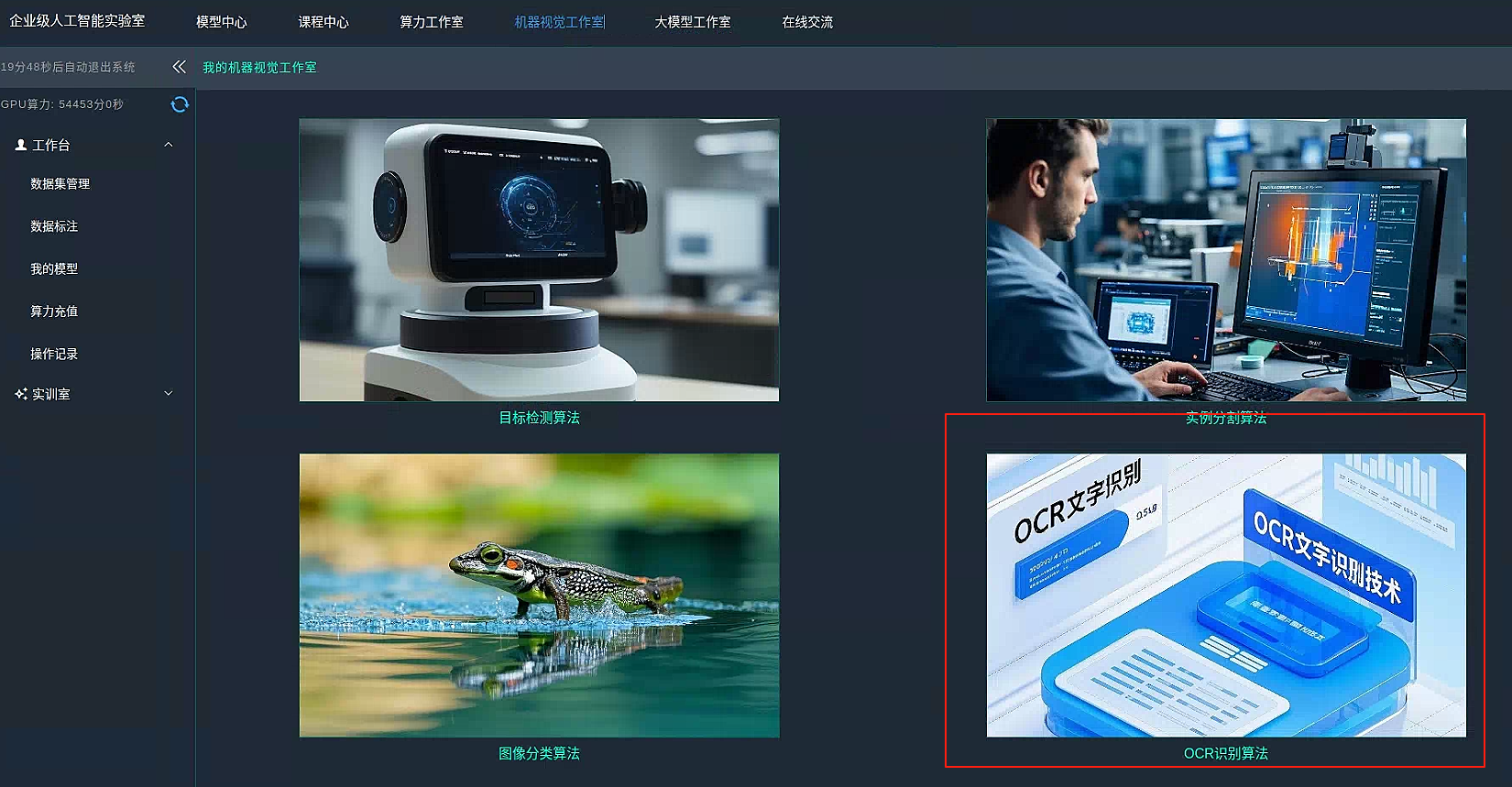
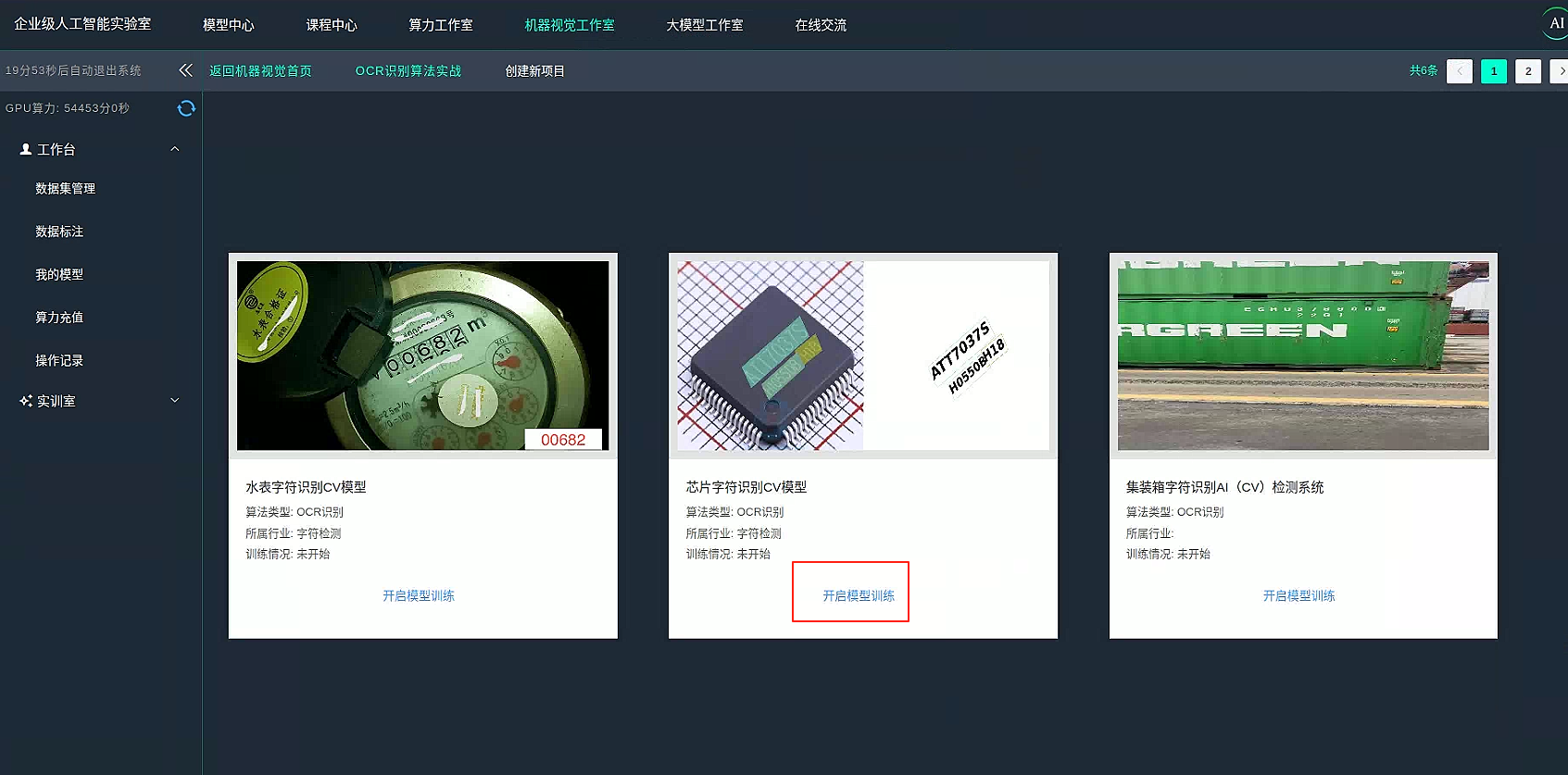
选择芯片项目并开启训练
进入data_yaml 文件夹
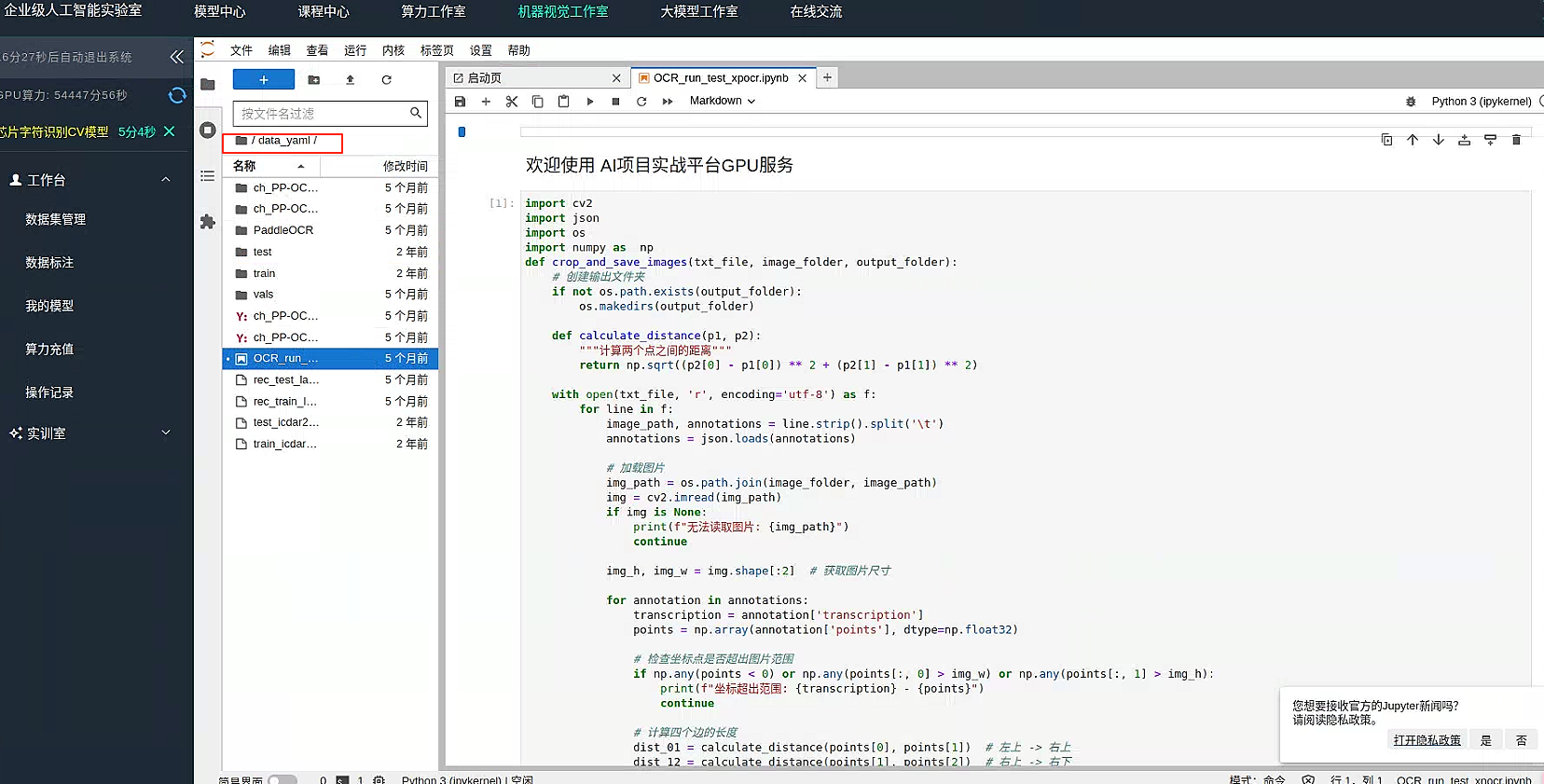
开始芯片ocr识别项目吧
1.1 安装依赖库
! apt-get update
! apt-get install -y libjpeg-dev libpng-dev
! pip install --upgrade pillow
! apt-get install fonts-noto-cjk
- 作用:安装图像处理所需的依赖库,以及为OCR提供中文字体支持。
- 解释:
libjpeg-dev/libpng-dev:提供JPEG和PNG图像解码的支持,确保能读取常见的图像格式。fonts-noto-cjk:安装Noto字体库,解决中文显示问题,避免OCR结果中的中文字符乱码。pillow:升级到最新版本,确保你能使用图像处理库中的最新特性和修复。
1.2 图像裁剪与透视校正
def crop_and_save_images(txt_file, image_folder, output_folder):
# 核心功能:根据标注文件裁剪并校正文字区域
# 详细实现

-
关键步骤:
- 读取标注文件中的坐标点和文字内容,确保OCR定位到正确的区域。
- 计算四边形的边长和角度,确定文字区域的方向。
- 使用透视变换(Perspective Transform)将倾斜的文字区域转为矩形,这样可以改善OCR的准确性。
- 保存校正后的图片,文件名采用文字内容,便于后续操作和管理。
-
为什么需要透视变换:
- 透视变换可以解决图像拍摄时的角度倾斜问题,使得OCR识别时,文字区域能够变成规则矩形,从而提高文字识别的精度。
1.3 生成标签文件
def generate_txt_from_files(folder_path, output_txt):
# 示例输出:文件名 -> "test.jpg test"
# 详细实现

- 作用:根据图像和对应的文字标签,创建模型训练所需的标签文件。
- 文件格式:
图片路径\t文字标签- 例如:
./images/test.jpg test
- 例如:
- 设计原因:
- PaddleOCR要求训练数据以
图像路径+标签的形式组织,这种格式便于后续的批量加载和处理。
- PaddleOCR要求训练数据以
二、模型训练
2.1 检测模型训练
! python train.py -c ch_PP-OCRv3_det_student.yml \
-o Global.pretrained_model=best_accuracy.pdparams
-
关键参数:
-c:指定检测模型配置文件,这里选择了ch_PP-OCRv3_det_student.yml,它是一个预定义的配置文件,适用于中文检测。-o Global.pretrained_model:指定加载的预训练模型,在此基础上进行微调。best_accuracy.pdparams是预训练模型的权重文件。
-
训练日志解析:
[2024/11/27 11:32:28] ppocr INFO: acc: 0.929687, loss: 6.364352acc:表示当前模型的检测准确率(越高越好,通常应接近1)。loss:表示当前模型的损失值(越低越好,损失值越低,表示模型训练越好)。
2.2 识别模型训练
! python train.py -c ch_PP-OCRv3_rec_distillation.yml \
-o Global.pretrained_model=best_accuracy
-
关键技术:知识蒸馏(Teacher-Student模型)
- 在知识蒸馏中,Teacher模型作为高性能模型,指导Student模型进行训练,从而让Student模型能够在有限的数据或计算资源下取得更好的性能。
-
关键指标:
Teacher_acc: 0.625448, Student_acc: 0.646953Teacher_acc:Teacher模型的准确率。Student_acc:Student模型的准确率。通过蒸馏,Student模型会逐渐逼近Teacher模型的表现。


三、模型推理与部署
3.1 模型转换
# 检测模型转换
! python export_model.py -c ch_PP-OCRv3_det_student.yml \
-o Global.save_inference_dir=./det_inference/
# 识别模型转换
! python export_model.py -c ch_PP-OCRv3_rec_distillation.yml \
-o Global.save_inference_dir=./rec_inference/
- 作用:将训练好的模型导出为部署所需的推理格式,便于在生产环境中使用。
- 生成文件:
model.pdmodel:保存模型的结构。model.pdiparams:保存模型的训练参数(权重)。

3.2 串联推理
! python predict_system.py --image_dir=./test \
--det_model_dir=./det_inference \
--rec_model_dir=./rec_inference
-
处理流程:
- 检测模型:用于定位图片中的文字区域。
- 识别模型:识别并解析定位到的文字区域内容。
-
典型输出:
[2024/11/27 11:39:43] ppocr INFO: result: {"Student": {"label": "35I-LQFP44", "score": 0.946}}label:OCR识别的结果,表示图像中的文字内容。score:置信度,表示模型对识别结果的确信程度,值越接近1越可靠。

四、结果分析与优化建议
4.1 常见问题处理
- 中文显示异常:
- 修改
utility.py中的字体路径,确保使用正确的中文字体:font_path="/usr/share/fonts/noto/NotoSansCJK-Regular.ttc"
- 修改
- 坐标越界警告:
- 在处理标注文件时,检查标注文件中的坐标是否超出了图像的实际尺寸,避免出现越界问题。
4.2 性能优化方向
- 数据增强:通过增加图像的旋转、模糊、对比度等方式进行数据增强,以提升模型的鲁棒性。
- 模型调参:
# ch_PP-OCRv3_rec_distillation.yml Optimizer: learning_rate: decay: step: [500, 1000] # 调整学习率衰减节点- 学习率衰减策略有助于在训练后期稳定模型的表现。
五、可视化展示
import os
import random
from PIL import Image
import matplotlib.pyplot as plt
# 指定图片文件夹路径
folder_path = '/root/data_yaml/inference_results/' # 替换成你自己的文件夹路径
# 获取文件夹中所有图片文件(假设是 JPG 格式,可以根据实际情况调整)
image_files = [f for f in os.listdir(folder_path) if f.endswith(('.jpg', '.jpeg', '.png'))]
# 随机选择4张图片
selected_images = random.sample(image_files, 4)
# 创建一个 2x2 的图像展示
fig, axes = plt.subplots(2, 2, figsize=(20, 20))
# 遍历选择的图片,读取并展示
for i, ax in enumerate(axes.flat):
img_path = os.path.join(folder_path, selected_images[i])
img = Image.open(img_path)
ax.imshow(img)
ax.axis('off')
ax.set_title(selected_images[i])
# 展示图片
plt.tight_layout()
plt.show()
- 说明:
- 这里展示的是推理结果图像的可视化,通常你会希望通过
plt.subplots创建多个子图来展示不同的结果。 imshow用来显示图像,图像的路径为"./inference_results/45.jpg",你可以根据实际需求修改路径和文件名。
- 这里展示的是推理结果图像的可视化,通常你会希望通过

- 绿色框:检测框,表示检测到的文字区域。
- 红色文本:识别的文字内容和对应的置信度。
通过本流程,您可以快速搭建一个支持中文场景的OCR系统。理想情况下,训练集上的准确率可达到92%以上。在实际部署时,建议根据业务需求补充相关数据并微调模型,以进一步提高识别效果。
完整项目代码实战操作,请进入“人工智能教学实训平台”https://www.lswai.com 体验完整操作流程。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









