







 本文介绍了线性模型在处理线性可分数据时的优势,但面对线性不可分数据时的局限性。为解决这一问题,引入了非线性模型,通过特征转换将非线性问题转化为线性可分问题,例如使用圆形分类。通过映射变换,将数据从原始空间转换到高维空间,使得在新空间中数据线性可分。然而,高维空间的复杂度和模型的VC-Dimension可能导致过拟合,影响泛化能力。因此,需要找到合适的特征转换和模型复杂度平衡,以提高模型的预测性能。
本文介绍了线性模型在处理线性可分数据时的优势,但面对线性不可分数据时的局限性。为解决这一问题,引入了非线性模型,通过特征转换将非线性问题转化为线性可分问题,例如使用圆形分类。通过映射变换,将数据从原始空间转换到高维空间,使得在新空间中数据线性可分。然而,高维空间的复杂度和模型的VC-Dimension可能导致过拟合,影响泛化能力。因此,需要找到合适的特征转换和模型复杂度平衡,以提高模型的预测性能。
非线性模型
线性模型在处理线性可分的资料时具有良好的表现,通过计算
w
T
x
w^Tx
wTx得到分数
s
s
s,然后进行取正负号操作也即:
s
i
g
n
(
s
)
sign(s)
sign(s),将数据进行分类。通过不断的优化得到一个相对完美的
w
w
w,就在空间中确定了一条直线,将数据进行完美的分类:
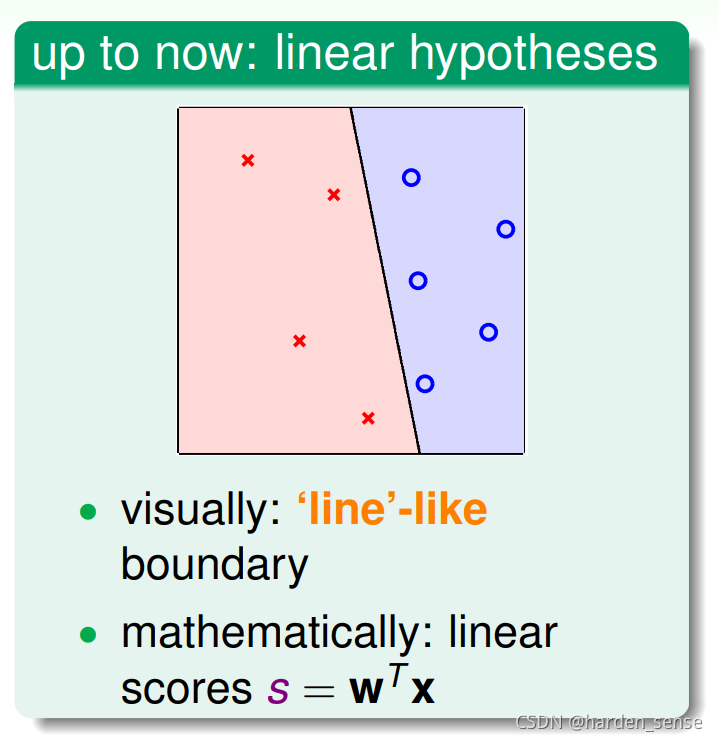
但是,这种分类方式具有一定的局限性。对于线性不可分的数据,就显得有些力不从心了:
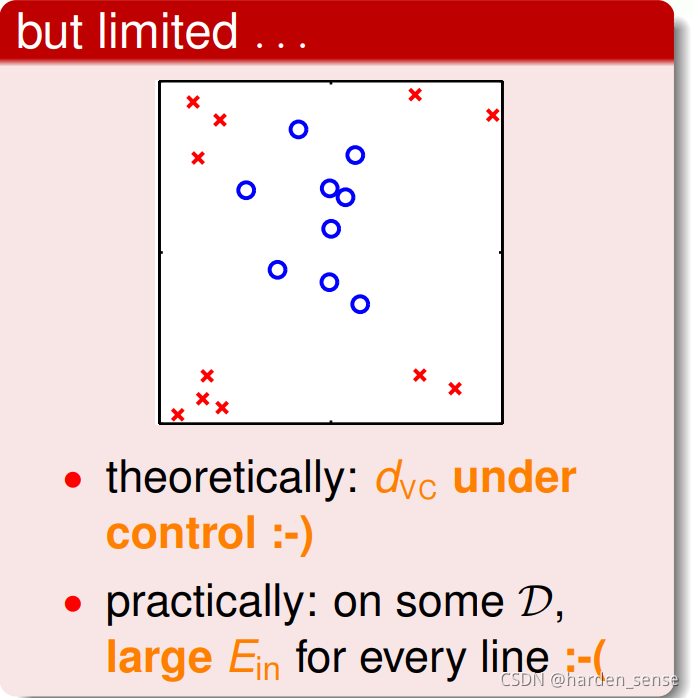
对于上图的这种情况,无论怎么优化直线,在数据集D上的都不可能用一条直线将数据分开。这就意味着模型在训练集上会犯很大的错误,因此导致他的预测效果并不会很好。为了解决上述问题可以引入非线性模型来进行分类。
列如可以用一个圆来对数据进行分类:
h
S
E
P
(
x
)
=
s
i
g
n
(
−
x
1
2
−
x
2
2
+
0.6
)
h_{SEP}(x)=sign(-x_1^2-x_2^2+0.6)
hSEP(x)=sign(−x12−x22+0.6)
该公式的含义为:样本点到原点距离的平方和与0.6进行对比,换句话说也就是用一个圆形将样本进行分类,如果在圆的内部就是+1,否则就是-1,这种方式称为圆形可分:
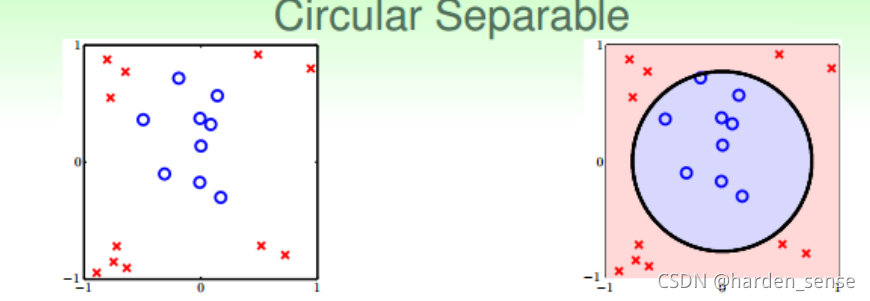
将上面的
h
S
E
P
h_{SEP}
hSEP进行转化,变为熟悉的线性模型:
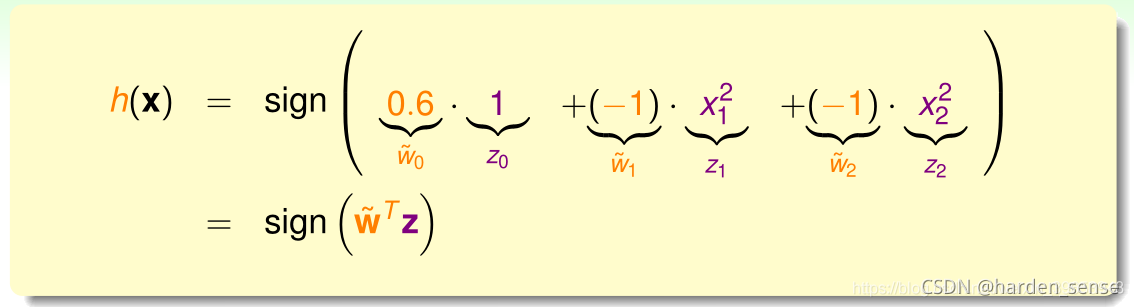
原公式中,
h
(
x
)
h(x)
h(x)的权重为:
w
0
=
0.6
,
w
1
=
−
1
,
w
2
=
−
1
w_0=0.6,w_1=-1,w_2=-1
w0=0.6,w1=−1,w2=−1,但是
h
(
x
)
h(x)
h(x)的特征不是线性模型的
(
1
,
x
1
,
x
2
)
(1,x_1,x_2)
(1,x1,x2)而是
(
1
,
x
1
2
,
x
2
2
)
(1,x_1^2,x_2^2)
(1,x12,x22),令
z
0
=
1
,
z
1
=
x
1
2
,
z
2
=
x
2
2
z_0=1,z_1=x_1^2,z_2=x_2^2
z0=1,z1=x12,z2=x22
h
(
x
)
h(x)
h(x)就成为了上式:
这种令
x
n
到
z
n
x_n到z_n
xn到zn的变换可以看作将
X
X
X空间中的点映射到
Z
Z
Z空间中去,也就是将
X
X
X空间中的圆形映射到
Z
Z
Z空间中,使得原空间中的数据在新空间中线性可分。

如果在
X
X
X空间中的圆形区域映射到
Z
Z
Z空间线性可分,那么在
Z
Z
Z空间中线性可分得区域映射到
X
X
X空间中一定是一个圆形区域吗?答案是否定的。
X
X
X空间中的分类面可能是椭圆、双曲线、等多种情况。

通过这种形式的转换
Z
Z
Z空间中的一条直线,对应
X
X
X空间中的一个特殊的二次曲线。之所以说特殊是因为表示的圆只能是过原点的,而不能是任意的圆。如果想要表示X空间中的任意二次曲线,应该设计一个更大的Z空间:

通过上面的特征转化,Z空间中的每一个超平面就对应着X空间中的一条二次曲线,则X空间中的假设空间
H
H
H为:

非线性变换
从X空间到Z空间的转换获得了更好的假设函数,相当于在X空间获得了好的二次曲线假设,Z空间中的线性可分,对应于X空间中的二次曲线。
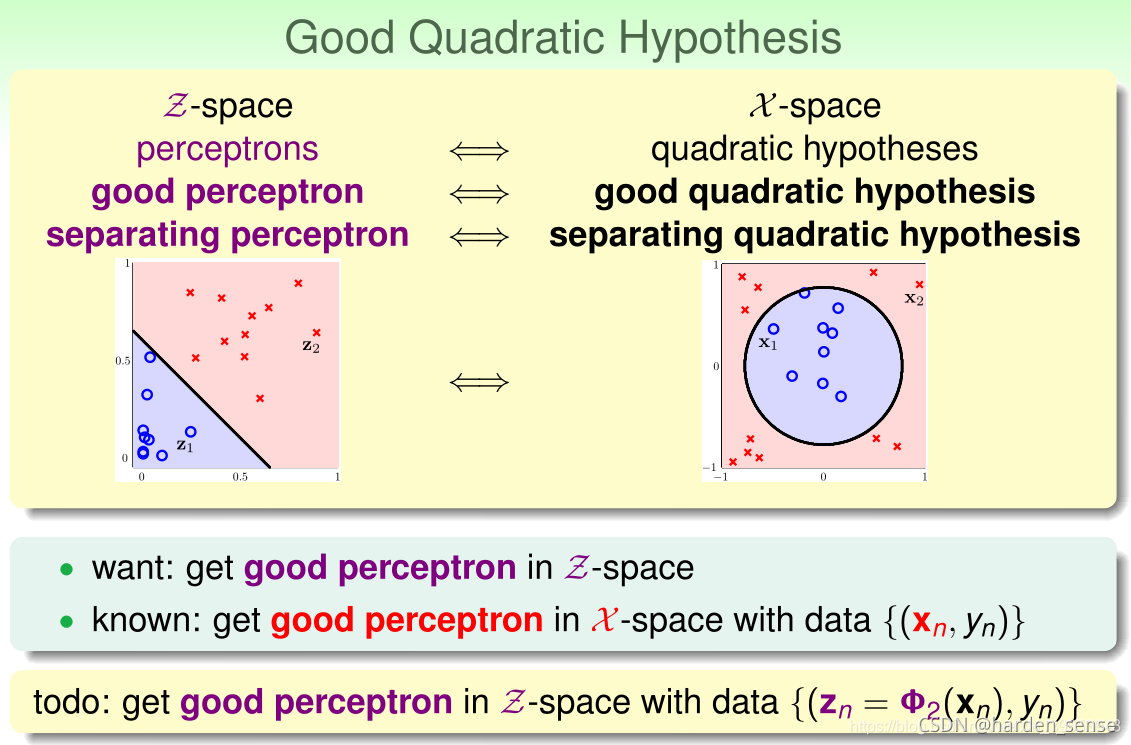
利用映射变换的思想,通过映射关系,把
X
X
X空间中的最高阶二次多项式转换为
Z
Z
Z空间中的一次向量z,从二次假设转换成了感知机问题。用z值代替x多项式,向量z的个数和X空间中的x的多项式个数相同。这样在Z空间中利用线性分类器进行训练。训练好以后,在将z替换为x的多项式即可。
- X X X空间的数据为 ( x n , y n ) (x_n,y_n) (xn,yn), Z Z Z空间的数据集为[ z n = ( Φ ( x n ) , y n ) z_n=(\Phi(x_n),y_n) zn=(Φ(xn),yn)],
- 通过特征变换函数 Φ \Phi Φ将 X X X空间线性不可分的数据集变化为Z空间中线性可分的数据集。
- 使用线性空间中表现良好的感知机模型,获得最优权重
- 最后得到最优假设函数
g
(
x
=
w
T
Φ
(
x
)
)
g(x=w^T\Phi(x))
g(x=wTΦ(x))
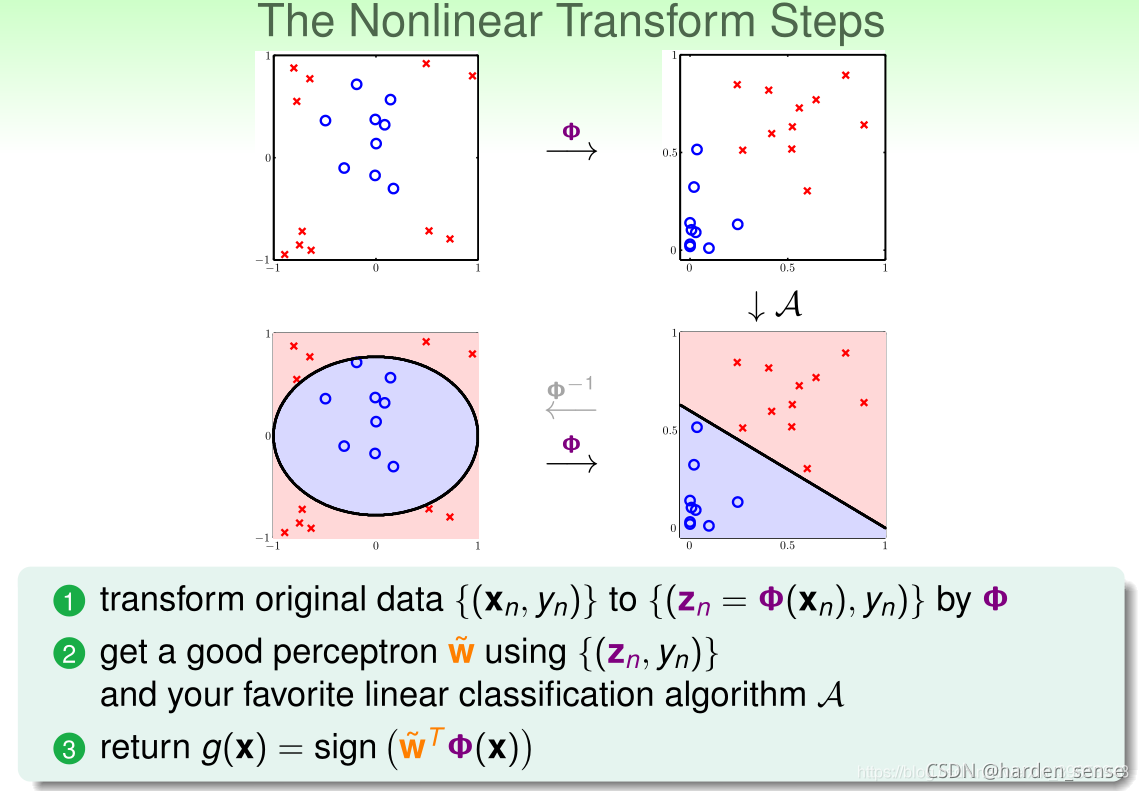
上图中就体现了这个过程,判断样本属于哪个类别,可以先将原空间中的点经过映射到另一个空间。然后对映射空间进行线性分类,最后在进行转化到原空间。这类空间的构成为: - 非线性变化函数 Φ \Phi Φ:通过特征变换,将非线性问题转化为线性可分问题。
- 利用线性模型分类:包括二分类,逻辑回归等
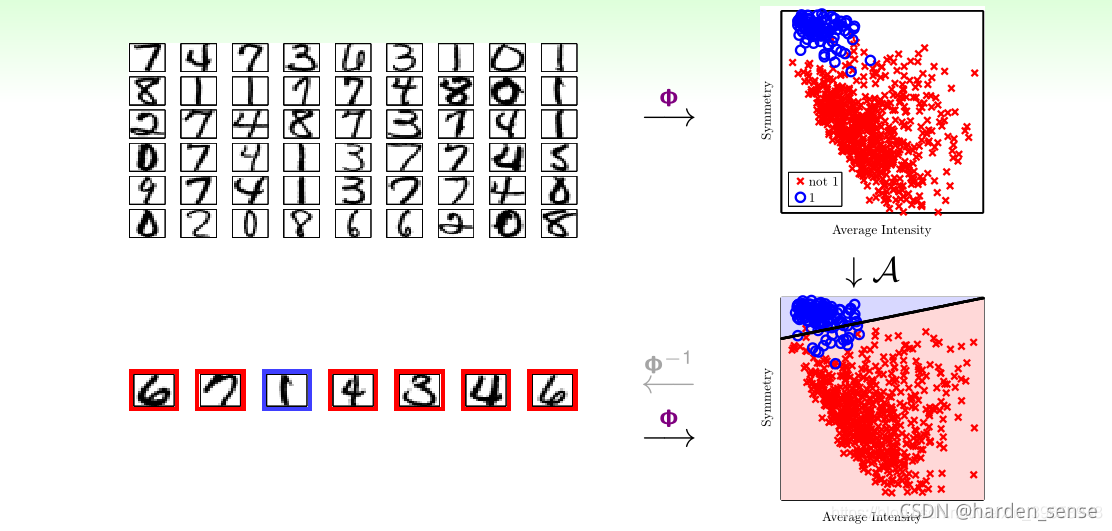
特征转换的思想非常常见,比如之前介绍的手写数字识别问题,从原始的像素特征值转化为具体的特征,如:密度、对称性等等。
非线性变化的代价
如果X的特征维度为d维,也就是说包含d个特征,那么二次多项式的个数为,也即Z空间的维度为:
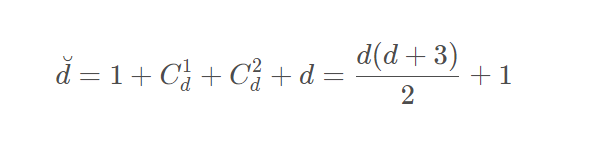
如果X为二维
(
x
1
,
x
2
)
(x_1,x_2)
(x1,x2)那么他的二次多项式就有六项
(
1
,
x
1
,
x
2
,
x
1
x
2
,
x
1
2
,
x
2
2
)
(1,x_1,x_2,x_1x_2,x_1^2,x_2^2)
(1,x1,x2,x1x2,x12,x22)
如果阶数为
Q
Q
Q,X的空间维度为d,那么Z空间的维度为:
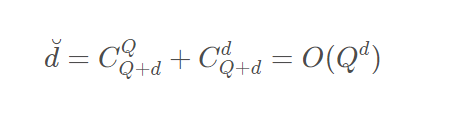
从上面的结果可以看出,
Z
Z
Z空间维度个数的时间复杂度是
Q
d
Q^d
Qd,随着Q和d的增大空间复杂度也在不断增大。

特征转换还带来了另一个问题,之前我们已经学习了,模型参数的自由度大概是模型VC维度。z域中特征个数随着Q和d增加变得很大,即自由度也会增加,VC-dimendiom增大。前面已经讨论过如果VC-dimension过大,模型的泛化能力将会变差。

下例解释了 VC-Dimension 过大,导致分类效果不佳的原因:

上图中,左边用直线进行线性分类,有部分点分类错误;右边用四次曲线进行非线性分类,所有点都分类正确,那么哪一个分类效果好呢?单从平面上这些训练数据来看,四次曲线的分类效果更好,但是四次曲线模型很容易带来过拟合的问题,虽然它的
E
i
n
E_{in}
Ein比较小泛化能力上,左边的分类器更好。也就是说,VC-Dimension 过大会带来过拟合问题。
那么如何选择合适的Q,避免过拟合,提高模型泛化能力呢?一般情况下,为了尽量减少特征自由度,会根据训练样本的分布情况,人为地减少、省略一些项。但是,这种人为地删减特征会带来一些“自我分析”代价,虽然对训练样本分类效果好,但是对训练样本外的样本,不一定效果好。所以,一般情况下,还是要保存所有的多项式特征,避免对训练样本的人为选择。

X X X空间到 X X X多项式空间的转换
转换过程如下所示:

- 果特征维度是一维的,变换多项式只有常数项
- 如果特征维度是两维的,变换多项式包含了一维的 Φ 0 ( x ) \Phi_0(x) Φ0(x)
- 如果特征维度是三维的,变换多项式包含了二维 Φ 1 ( x ) \Phi_1(x) Φ1(x)
以此类推VC-Dimention 和
E
i
n
E_{in}
Ein满足如下关系:

从上图可明显的看出来,VC的值一定要合适,不能过大,也不能过小。否则都可能造成在实际预测时的情况不是很好。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









