







基于物品的协同过滤算法
1. 数据
使用movielens-100k数据集中的u1.base文件作为实验集
2.实验
在demo1中建立用户-评分矩阵和用户看过的电影id列表,根据用户看过的电影计算电影间相似度,根据项亮的《推荐系统实践》中方法计算用户相似度。
相似度公式:
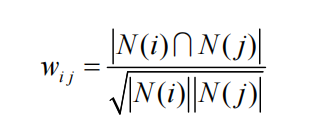
import pandas as pd
import numpy as np
import math
#建立用户-评分矩阵
user_rating = np.zeros((944, 1683))#数据集共943个用户,1682部电影,0行0列不用
#print(user_rating)
def Create_User_rating_Table(data):
for it in data:
user_rating[it[0]][it[1]]=it[2]
print(user_rating)
#outfile = "F:\\协同过滤推荐算法\\基于物品\\user_rating.csv"
#data1=pd.DataFrame(user_rating)
#print(data1.shape)
#data1.to_csv(outfile, index=False, header=False)
#建立用户看过的电影id列表
def Create_User_items(user_rating):
user_item=[]
for user in range(1,944):
items=[]
for item in range(1,1683):
if user_rating[user][item] != 0:
items.append(item)
user_item.append(items)
print(user_item)
outfile = "F:\\协同过滤推荐算法\\基于物品\\user_item.csv"
data = pd.DataFrame(user_item)
data.to_csv(outfile, index=False, header=False)
return user_item
#计算物品相似度
def Create_Item_Sim(user_item):
Item_Sim = np.zeros((1683, 1683)) # 数据集共1682部电影,0行0列不用
N=np.zeros(1683)
for items in user_item:
for it1 in items:
N[it1] += 1
for it2 in items:
if it1 == it2:
continue
Item_Sim[it1][it2] += 1
Item_Sim[it2][it1] += 1
print(Item_Sim)
W = np.zeros((1683, 1683))
for it1 in range(1,1683):
for it2 in range(1,1683):
if it1 == it2 :
continue
if math.sqrt(N[it1]*N[it2]) == 0:
W[it1][it2] = 0.0
continue
W[it1][it2]=Item_Sim[it1][it2]/math.sqrt(N[it1]*N[it2])
print(W)
return W
file="F:\\协同过滤推荐算法\\ml-100k\\u1.base"
lieming=["用户id", "电影id", "评分", "时间"]
data = pd.read_table(file, names=lieming)
#print(data)
list_data = np.array(data)#转换数组
#print(list_data)
data=list_data.tolist()#转换list
#创建用户评分矩阵
Create_User_rating_Table(data)
#创建用户看过的电影id的列表
user_items=Create_User_items(user_rating)
#根据用户看过的电影id计算电影间的相似度
Item_sim = Create_Item_Sim(user_items)
#输出
outfile = "F:\\协同过滤推荐算法\\基于物品\\item_sim.csv"
data1 = pd.DataFrame(Item_sim)
data1.to_csv(outfile, index=False, header=False)
用户评分矩阵

物品相似度矩阵:

在demo2中利用物品间的相似度,计算用户u对电影i的感兴趣值。
根据用户u看过的电影列表,找到看过电影的K个最近邻,计算用户u对这K个最近邻的感兴趣值,最后根据感兴趣值排序得到推荐列表。
计算用户u对电影j的感兴趣值公式:
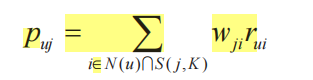
用户看过的电影i与未看过的电影j的相似度*用户u对电影i的评分。
import pandas as pd
import numpy as np
import xlwt
def Create_User_items(user_rating):
user_item=[]
for user in range(1,944):
items=[]
for item in range(1,1683):
if user_rating[user][item] != 0:
items.append(item)
user_item.append(items)
#print(user_item)
return user_item
#计算电影u相关的所有电影
def Count_User_Interest(Sim_W,K,user_item,user_rating):
userid = 0
Recommend = {}
for items in user_item:
userid += 1
cur_recommend = []
for item in items:
cur = []
cur_rating=user_rating[userid][item]
cur_item_sim = Sim_W[item]
for it1 in range(1,1683):
if cur_item_sim[it1] != 0:
cur.append([it1,cur_item_sim[it1]])
cur.sort(key=(lambda x:x[1]), reverse=True)
cur_sort=cur[0:K]
for item2 in cur_sort:
if item2 in items:
continue
item2[1]*=cur_rating
#去重
flag = 0
for cur_re in cur_recommend:
if item2[0] == cur_re[0]:
flag = 1
if item2[1]>cur_re[1]:
cur_re[1] = item2[1]
if flag == 0:
cur_recommend.append(item2)
for cur_item in cur_recommend:#将每一个二元组放入推荐字典中
Recommend.setdefault(userid,[]).append(cur_item)
#输出
for userid in range(1,944):
outfile = "F:\\协同过滤推荐算法\\基于物品\\推荐结果集合\\Recommend{}.csv".format(userid)
Recommend[userid].sort(key=(lambda x:x[1]), reverse=True)
data = pd.DataFrame(Recommend[userid])
data.to_csv(outfile, index=False, header=False)
print(Recommend[userid],len(Recommend[userid]))
return Recommend
file1="F:\\协同过滤推荐算法\\基于物品\\user_rating.csv"
data1=pd.read_csv(file1, header=None)#header取消列名
user_rating=np.array(data1)
#print(user_rating)
file2="F:\\协同过滤推荐算法\\基于物品\\item_sim.csv"
data1=pd.read_csv(file2,header=None)
item_sim=np.array(data1)
#得到用户喜欢物品的列表
user_item = Create_User_items(user_rating)
#得到推荐列表
Count_User_Interest(item_sim,30,user_item,user_rating)
用户1的推荐列表(第一列为电影id,第二列为感兴趣值):

数据和详细代码在仓库
















 1164
1164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











