









目录
简述
这篇文件主要是讲kafka消费者相关使用,诸如,offset的使用,消费者的相关配置,多线程消费模式和springboot整合。至于这些里面涉及到原理等相关深入的知识会放到下一篇文件kafka的消费者原理中具体展开讲述。
一. kafka消费者
一般的消费方式有两种:pull模式和push模型;kafka消费者采用从broker中主动pull拉取数据,之所以没有采用push模型是因为每个消费者的消费速率不一致,broker无法适应各个消费者所需要的消费速率。但是pull模型也是有其缺点的,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据。
消费者需要订阅主题(Topic),多个消费者(Consumer)组成一个消费者组(Consumer Group)。
这里的消费者组是一个逻辑的上概念。这里需要注意一个主题(topic)分为多个分区(partition),一个消费者(consumer group)分为多个消费者。那么分区和消费者的对应关系有三种:
分区数目<消费者数目:多余的消费者会处于空闲状态,其他的消费者会和分区一一对应;
分区树目=消费者数目:一个消费者会对应一个分区的消息进行消费;
分区数目>消费者数目:不同的分区消息会均横地分配到这些消费者;
另一个理解就是一个分区不能同时被consumer group中的多个consumer消费。所以在消费的消息的时候最佳的配置就是主题的分区数和消费组中的consumer数量一致。
二. 构建测试工程
下面搭建一个测试工程,方便后面的演示。先创建一个maven项目,需要加入kafka依赖:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
创建一个测试的主题,并启动我们上篇文件中的生产者向主题中写入数据。

在配置文件中配置消费者客户端,写一个最简单配置的消费者:
public class ConsumerExample {
private KafkaConsumer<String, String> consumer;
private String topicName = "test-consumer";
public ConsumerExample(Boolean isSingle) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.31.32:9091,192.168.31.32:9092,192.168.31.32:9093");
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test-group");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
this.consumer = new KafkaConsumer<>(properties);
if (isSingle) {
// 订阅单个分区
this.consumer.assign(Arrays.asList(new TopicPartition(topicName, 0)));
} else {
this.consumer.subscribe(List.of(topicName));
}
}
public void simpleConsumer() {
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String,String> record : records) {
System.out.printf("partition = %d, offset = %d, key = %s, value = %s\n", record.partition(), record.offset(), record.key(), record.value());
}
// 手动提交offset
this.consumer.commitAsync();
}
}
public static void main(String[] args) {
ConsumerExample consumerExample = new ConsumerExample(true);
consumerExample.simpleConsumer();
}
}
启动消费者客客户端项目,通过上一个项目的生产者客户端发送消息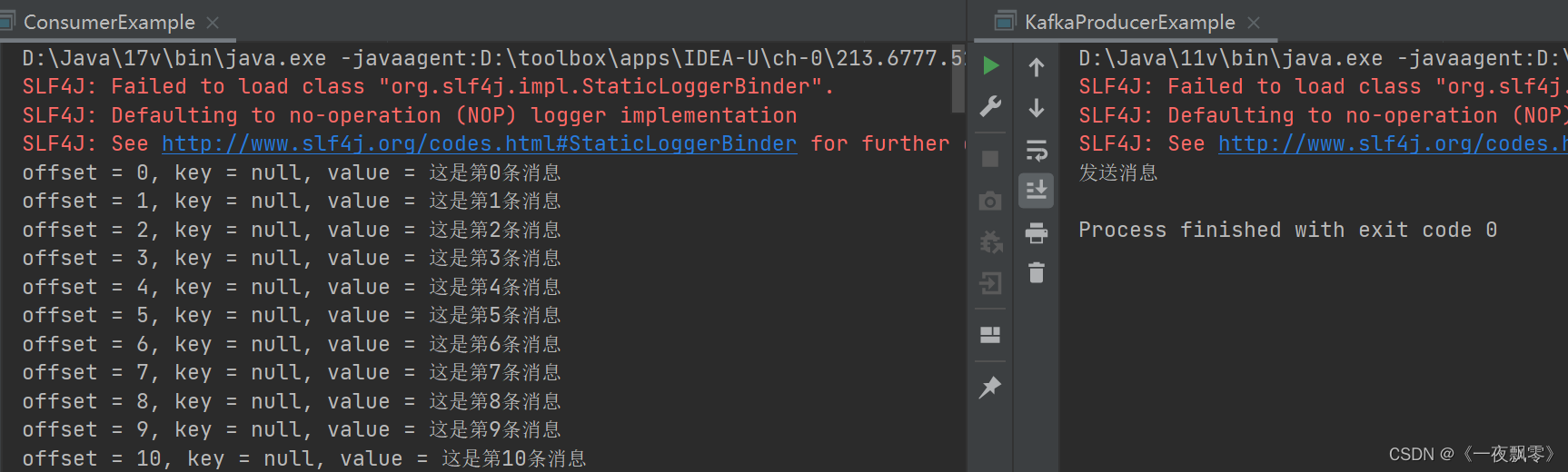
测试项目可以了,接下来进行kafka的消费者相关使用实践。
三. offset提交
第一部分演示的消息消费,如果再次启动去消费就会发现,上次的消息无法消费到了。这是因为在消费者客户端配置的时候设置了自动提交:enable-auto-commit:true。
3.1. 手动提交offset
在生产中使用的时候,在消费消息的时候会执行业务逻辑会遇到各种情况,一半消费的时候需要手动进行提交,下面看一下如何手动提交offset。
先将配置:enable-auto-commit:false
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.31.32:9091,192.168.31.32:9092,192.168.31.32:9093");
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test-group");
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false); // 将自动提交设置为false
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Arrays.asList("test-consumer"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String,String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s\n", record.offset(), record.key(), record.value());
}
// 手动提交offset
consumer.commitAsync();
}
3.2. 按照分区消费
接着看一下如何对每个分区的数据进行消费:
public void partitionAllConsumer() {
this.consumer.subscribe(List.of(TOPIC_NAME));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
// 获取所有分区,遍历
records.partitions().forEach(item -> {
// 获取分区对应的消息集合
List<ConsumerRecord<String, String>> partitionRecodes = records.records(item);
// 遍历消息
partitionRecodes.forEach(inner -> {
System.out.printf("分区 = %d, offset = %s, key = %s, value = %s\n", inner.partition(), inner.offset(), inner.key(), inner.value());
});
// 计算对应的offset的值
long offset = partitionRecodes.get(partitionRecodes.size() - 1).offset();
Map<TopicPartition, OffsetAndMetadata> offsetMap = new HashMap<>(1);
// 这里需要注意这里为下次消费的起始位置
offsetMap.put(item, new OffsetAndMetadata(offset + 1));
// 手动提交消息
this.consumer.commitSync(offsetMap);
});
}
}
另外这里还可以订阅指定分区的数据进行消费:
// 订阅多个指定的分区数据
public void partitionConsumer() {
// 订阅0号分区
TopicPartition partition = new TopicPartition(TOPIC_NAME, 0);
this.consumer.assign(List.of(partition));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
if (partitionRecords.isEmpty()) {
continue;
}
for(ConsumerRecord<String, String> item : partitionRecords) {
System.out.printf("分区 = %d, offset = %s, key = %s, value = %s\n", item.partition(), item.offset(), item.key(), item.value());
}
// 计算对应的offset的值
long offset = partitionRecords.get(partitionRecords.size() - 1).offset();
// 这里需要注意这里为下次消费的起始位置
Map<TopicPartition, OffsetAndMetadata> offsetMap = Collections.singletonMap(partition, new OffsetAndMetadata(offset + 1));
// 手动提交消息
this.consumer.commitSync(offsetMap);
}
}
3.3. 指定offset消费
kafka的api中提供了四种方法去指定offset进行消费。
void seek(TopicPartition partition, long offset);
void seek(TopicPartition partition, OffsetAndMetadata offsetAndMetadata);
void seekToBeginning(Collection<TopicPartition> partitions);
void seekToEnd(Collection<TopicPartition> partitions);
这里的seekToBeginning和seekToEnd是可以一次性重设n个分区的位移,使用比较简单,而seek只允许重设指定分区的位移,即为每个分区都单独设置位移,下面演示一下seek的使用。这里有两种方法进行指定offset操作。
第一种:使用seek进行操作
public void consumerByOffset(long offset) {
this.consumer.subscribe(List.of(TOPIC_NAME));
// 获取分区信息
Set<TopicPartition> partitions = this.consumer.assignment();
while (partitions.isEmpty()) {
this.consumer.poll(Duration.ofSeconds(1));
partitions = this.consumer.assignment();
}
// 设置每个分区指定offset开始消费
for (TopicPartition partition : partitions) {
this.consumer.seek(partition, offset);
}
// 消费数据
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String,String> record : records) {
System.out.printf("分区 = %d, offset = %d, key = %s, value = %s\n", record.partition(), record.offset(), record.key(), record.value());
}
// 手动提交offset
consumer.commitAsync();
}
}
这里的获取TopicPartition列表有时间限制,还有一种操作方法:
public void consumerByOffset(long offset) {
// 获取分区信息
List<PartitionInfo> partitionInfos = this.consumer.partitionsFor(TOPIC_NAME);
List<TopicPartition> partitions = partitionInfos.stream()
.map(item -> new TopicPartition(TOPIC_NAME, item.partition()))
.collect(Collectors.toList());
this.consumer.subscribe(List.of(TOPIC_NAME));
// 设置每个分区指定offset开始消费
this.consumer.poll(Duration.ofMillis(100));
for (TopicPartition partition : partitions) {
this.consumer.seek(partition, offset);
}
// 消费数据
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String,String> record : records) {
System.out.printf("分区 = %d, offset = %d, key = %s, value = %s\n", record.partition(), record.offset(), record.key(), record.value());
}
// 手动提交offset
consumer.commitAsync();
}
}
第二种:借助commitSync操作
public void consumerByOffset1(long offset) {
Map<TopicPartition, OffsetAndMetadata> partitionMap = new HashMap<TopicPartition, OffsetAndMetadata>(3);
partitionMap.put(new TopicPartition(TOPIC_NAME, 0), new OffsetAndMetadata(offset));
partitionMap.put(new TopicPartition(TOPIC_NAME, 1), new OffsetAndMetadata(offset));
partitionMap.put(new TopicPartition(TOPIC_NAME, 2), new OffsetAndMetadata(offset));
// 提交各个分区的offset位置
this.consumer.commitSync(partitionMap);
// 订阅主题,这里也可以订阅指定的分区
this.consumer.subscribe(List.of(TOPIC_NAME));
// 消费数据
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String,String> record : records) {
System.out.printf("分区 = %d, offset = %d, key = %s, value = %s\n", record.partition(), record.offset(), record.key(), record.value());
}
// 手动提交offset
consumer.commitAsync();
}
}
这里需要注意,每次执行group.id不可以重复。
3.4. 按照时间消费
这里时间回拨进行消费也是日常中比较重要的一个操作。下面演示一个如何消费一小时之前的数据。
public void consumerOffsetByTime1() {
this.consumer.subscribe(List.of(TOPIC_NAME));
Set<TopicPartition> assignment = new HashSet<>();
while (assignment.size() == 0) {
consumer.poll(Duration.ofMillis(1000));
assignment = consumer.assignment();
}
// 设置各个分区的消费时间
Map<TopicPartition, Long> partitionLongMap = new HashMap<>();
for (TopicPartition partition : assignment) {
partitionLongMap.put(partition, System.currentTimeMillis() - 3600 * 1000);
}
// 将时间转换为offset
Map<TopicPartition, OffsetAndTimestamp> timestampMap = this.consumer.offsetsForTimes(partitionLongMap);
for (TopicPartition partition : assignment) {
OffsetAndTimestamp timestamp = timestampMap.get(partition);
if (Objects.nonNull(timestamp)) {
// 设置消费位置
System.out.printf("设置分区:%s,从%s开始消费\n", partition.partition(), timestamp.offset());
this.consumer.seek(partition, timestamp.offset());
}
}
// 消费数据
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String,String> record : records) {
System.out.printf("分区 = %d, offset = %d, key = %s, value = %s\n", record.partition(), record.offset(), record.key(), record.value());
}
// 手动提交offset
consumer.commitAsync();
}
}
四. 消费者分组操作
在上一部分指定offset的时候,可能遇到无法获取分区数据导致一直无法消费,可以试着删除一下消费者分组。
获取所有的消费者分组:
bin/kafka-consumer-groups.sh --bootstrap-server {kafka服务器地址} --list
查询消费者分组详情:
bin/kafka-consumer-groups.sh --bootstrap-server {kafka服务器地址} --describe --group {消费组}
删除消费者分组:
bin/kafka-consumer-groups.sh --bootstrap-server {kafka服务器地址} --delete --group {消费组名称}
五. 多线程消费数据
多线程消费模式有两种,一种是消费者组中一个消费者对应一个分区,另一种是类似netty,一个消费者订阅主题然后分发数据给异步线程去处理。
5.1. 一对一模式
这种就是一个分区对应同一个消费者组中的一个消费者,如下图所示。下面看一下具体的实现。
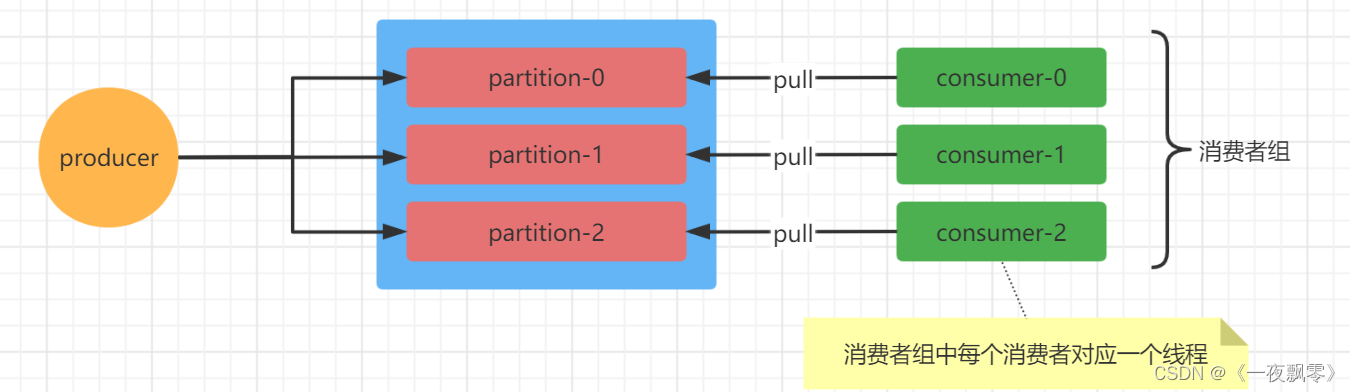
这里每个partition对应一个线程客户端,另一个需要注意的是KafkaConsumer不是线程安全的,KafkaProducer是线程安全的。需要在使用的时候注意。这种方法可以手动提交offset,数据处理是阻塞的,一般用于数据一致性强的场景中。
public class FirstConsumerThread {
// topic名称
public static final String TOPIC_NAME = "test-consumer";
public FirstConsumerThread() {
}
public static class KafkaConsumerThread implements Runnable {
// 消费者分组
private static final String GROUP_ID = "test-group";
private final KafkaConsumer<String, String> consumer;
private final TopicPartition partition;
public KafkaConsumerThread(String topicName, Integer partition) {
// 基础配置信息
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.31.32:9091,192.168.31.32:9092,192.168.31.32:9093");
properties.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// 指定某一个partition
this.partition = new TopicPartition(topicName, partition);
// 构建KafkaConsumer
this.consumer = new KafkaConsumer<>(properties);
// 订阅paritition
this.consumer.assign(List.of(this.partition));
}
@Override
public void run() {
try {
while (true) {
// 拉取数据
ConsumerRecords<String, String> records = this.consumer.poll(Duration.ofMillis(10000));
// 获取对应的partiton数据
List<ConsumerRecord<String, String>> partitionRecords = records.records(this.partition);
for (ConsumerRecord<String, String> record : partitionRecords) {
// 处理数据
System.out.printf("[%s] partition = %d, offset = %d, key = %s, value = %s\n", Thread.currentThread().getName(), record.partition(), record.offset(), record.key(), record.value());
}
// 获取offset
long lastOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
// 手动提交offset
this.consumer.commitSync(Collections.singletonMap(this.partition, new OffsetAndMetadata(lastOffset + 1)));
}
} finally {
this.consumer.close();
}
}
}
public static void main(String[] args) throws InterruptedException {
// 自定义的一个连接池
ConsumerThreadPool pool = new ConsumerThreadPool(3, "kafka-consumer-");
for (int i = 0; i < 3; i++) {
pool.submit(new KafkaConsumerThread(TOPIC_NAME, i));
}
Thread.sleep(15000);
pool.stop();
}
}
代码也很简单,就是每个partition对应可一个KafkaConsumer客户端进行消费。这种消费模式都会创建多个KafkaConsumer。
5.2. 多对一模式
这种就一个消费者去订阅主题让多个线程去消费数据,如下图所示,下面看一个具体的实现。
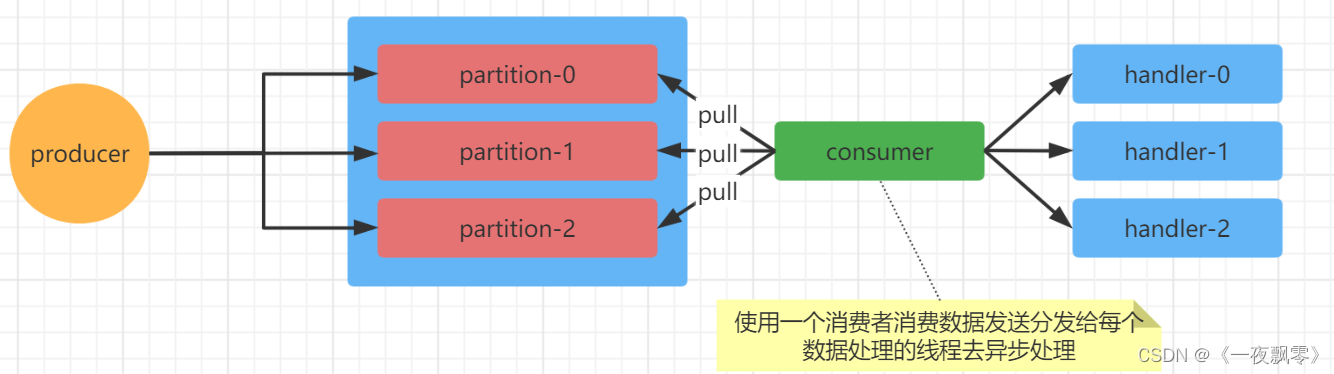
这种模式是没法手动提交offset,但是消息处理是异步非阻塞的。
public class SecondConsumerThread {
private static final String GROUP_ID = "test-group";
private static final String TOPIC_NAME = "test-consumer";
private final KafkaConsumer<String, String> consumer;
private final ExecutorService service;
public SecondConsumerThread(Integer workerNum) {
// 基础配置
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.31.32:9091,192.168.31.32:9092,192.168.31.32:9093");
properties.put(ConsumerConfig.GROUP_ID_CONFIG, GROUP_ID);
// 这是的自动提交配置是true
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
consumer = new KafkaConsumer<>(properties);
// 订阅主题
consumer.subscribe(List.of(TOPIC_NAME));
// 创建一个线程池
service = new ThreadPoolExecutor(workerNum, workerNum, 0L, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<>(1000), new ThreadPoolExecutor.CallerRunsPolicy());
}
public void consumer() {
while (true) {
// 拉取消息
ConsumerRecords<String, String> records = this.consumer.poll(Duration.ofMillis(10000));
// 消费
for (final ConsumerRecord<String, String> record : records) {
// 交给线程去处理数据
this.service.submit(new MessageHandler(record));
}
}
}
public void stop() {
if (Objects.nonNull(this.consumer)) {
this.consumer.close();
}
if (Objects.nonNull(this.service)) {
this.service.shutdown();
}
}
// 消息处理线程
private static class MessageHandler implements Runnable {
private final ConsumerRecord<String, String> record;
public MessageHandler(ConsumerRecord<String, String> record) {
this.record = record;
}
@Override
public void run() {
// TODO 处理数据
System.out.printf("[%s] partition = %d, offset = %d, key = %s, value = %s\n", Thread.currentThread().getName(), record.partition(), record.offset(), record.key(), record.value());
}
}
public static void main(String[] args) throws InterruptedException {
SecondConsumerThread thread = new SecondConsumerThread(5);
thread.consumer();
Thread.sleep(15000);
thread.stop();
}
}
六. 消费者重要配置
下面看一下消费者核心配置:
enable.auto.commit:开启自动提交,默认是true,消费者的偏移量将在后台定期提交。
auto.commit.interval.ms:自动提交频率,默认是5000。
client.id:客户端ID。
check.crcs:是否开启数据校验,默认是true。
bootstrap.servers:服务器配置,多个用逗号分隔开。
connections.max.idle.ms:关闭空间连接时间,默认是540000
group.id:唯一标识用户群组,同一个group每个partition只会分配到一个consumer。
max.poll.records:拉取最大记录,默认是500,一次轮询调用返回的记录最大数量。
max.poll.interval.ms:拉取记录时间间隔,默认300000,5分钟;使用消费者组管理轮询调用之间的最大延迟时间,如果在过期之前没有调用拉取,将会认为消费者失败,组内将重新平衡,将分区分配给另一个消费者成员。
request.timeout.ms:请求超时时间,默认是30000,30秒;配置控制客户端等待请求响应的最长时间,如果超时之前没有收到响应,客户端需要重新发送请求。
session.timeout.ms:消费者session超时时间,用于检测检测worker程序失败的超时,worker定时发送心跳,用以表明存活。
auto.offset.reset:初始偏移量,默认是latest。
earliest:如果主题中不存在已经提交的offest时(从没有提交保存过偏移量)则从头开始消费;如果主题存在已经提交的offest时(之前提交保存过偏移量)则从已经提交的offest处开始消费;
latest:如果主题中不存在已经提交的offest时(从没有提交保存过偏移量)则从最新的数据消费,也就是新产生的数据;如果主题存在已经提交的offest时(之前提交保存过偏移量)则从已经提交的offest处开始消费;
none:主题中各分区都存在已提交的offset时,从提交的offest处开始消费,只要有一个分区不存在已提交的offset,则抛出异常;
key.deserializer:用于实现org.apache.kafka.common. serialize .Deserializer接口的key的反序列化类。
value.descerializer:用于实现org.apache.kafka.common. serialize .Deserializer接口的value的反序列化类
max.partitioni.fetch.bytes:每个分区服务器将返回的最大数据量
partition.assignment.strategy:消费者订阅分区策略,当使用组管理时,客户端将使用分区分配策略的类名在使用者实例之间分配分区所有权。
fetch.max.bytes:拉取最大字节,默认是52428800,50M
hearbeat.interval.ms:心跳时间,默认是3000,3秒;使用Kafka的组管理工具时,从心跳到消费者协调器的预期时间。心跳被用来确保消费者的会话保持活跃,并在新消费者加入或离开组时促进再平衡。
fetch.max.wait.ms:拉取阻塞时间,默认是500,如果没有足够的数据立即满足fetch.min.bytes提供的要求,服务器在响应fetch请求之前将阻塞的最长时间。
fetch.min.bytes:拉取最小字节数,默认是1,服务器应该为获取请求返回的最小数据量。如果没有足够的数据可用,请求将等待那么多数据累积后再响应请求。默认的1字节设置意味着,只要数据的一个字节可用,或者获取请求超时等待数据到达,就会响应获取请求。将此设置为大于1的值将导致服务器等待更大数量的数据累积,这可以稍微提高服务器吞吐量,但代价是增加一些延迟。
exclude.interval.topics:公开内部主题,默认是true。是否应该将来自内部主题(如偏移量)的记录公开给使用者,消费者共享offset。如果设置为true,从内部主题接收记录的唯一方法是订阅它。
isolation.level:隔离级别,默认是read_uncommitted。控制如何以事务方式读取写入的消息。
七. 整合springboot
7.1. 测试项目创建
创建一个普通的Springboot项目,增加kafka依赖:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
增加消费者配置项:
spring:
kafka:
consumer:
group-id: test-consumer-group
bootstrap-servers:
- 192.168.31.32:9091
- 192.168.31.32:9092
- 192.168.31.32:9093
# 每次返回消息记录数
max-poll-records: 100
listener:
# 开启批量消息
type: batch
消费者配置:
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
@Slf4j
@Component
public class KafkaConsumer {
@KafkaListener(topics = {"test-consumer-2"})
public void consumer(String msg) {
System.out.println(msg);
log.info("拉取的消息:{}", msg);
}
}
7.2. 批量消费
上面演示的只能接受一条消息一次,但是在配置文件的时候是按批次拉取的,下面演示一下批量消费消息。
import lombok.extern.slf4j.Slf4j;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import java.util.List;
@Slf4j
@Component
public class KafkaConsumer {
@KafkaListener(topics = {"test-consumer-2"}, groupId = "consumer-1")
public void consumer(List<ConsumerRecord<String, String>> records) {
for (ConsumerRecord<String, String> record : records) {
log.info("拉取的消息:partition = {}, offset = {}, key = {}, value = {}", record.partition(), record.offset(), record.key(), record.value());
}
}
}
7.3. 并发消费
在配置增加并发数:
spring:
kafka:
consumer:
...
listener:
# 开启批量消息
type: batch
# 设置并发数
concurrency: 3

7.4. 手动提交和异常处理
配置手动提交也很简单,将配置enable-auto-commit: false,另外如果消费者对消息消费处理的时候如果发生了异常,spring-kafka为我们提供了专门的异常处理器(ConsumerAwareListenerErrorHandler),通过异常处理器,我们可以处理consumer在消费时发生的异常。下面看代码演示
spring:
kafka:
consumer:
# 关闭自动提交
enable-auto-commit: false
listener:
# 设置提交模式,这里必须设置,否则会报错:No Acknowledgment available as an argument, the listener container must have a MANUAL Ackmode to populate the Acknowledgment
ack-mode: manual_immediate
配置异常处理:
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.listener.ConsumerAwareListenerErrorHandler;
@Slf4j
@Configuration
public class CustomListenerErrorHandler {
@Bean
public ConsumerAwareListenerErrorHandler listenerErrorHandler(){
return (message,exception,consumer)-> {
log.warn("消费者:{}, 异常:{}", consumer, message.getPayload());
return null;
};
}
}
监听消费消息,在errorHandler种配置上面定义的异常处理,在方法种增加一个参数Acknowledgment就可以手动提交offset了。
@KafkaListener(topics = {"test-consumer-2"}, groupId = "consumer-1", errorHandler = "listenerErrorHandler")
public void consumer(List<ConsumerRecord<String, String>> records, Acknowledgment acknowledgment) {
try {
for (ConsumerRecord<String, String> record : records) {
log.info("拉取的消息:partition = {}, offset = {}, key = {}, value = {}", record.partition(), record.offset(), record.key(), record.value());
}
// 提交offset
acknowledgment.acknowledge();
} catch (Exception e){
}
}
7.5. 过滤器配置
过滤器可以配置过滤条件进行消费,这里的配置和上面的异常处理是一样的:
/**
* 消息过滤器
* @return
*/
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> filterContainerFactory(){
ConcurrentKafkaListenerContainerFactory<String, String> factory=new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory);
//被过滤器的消息将被丢弃
factory.setAckDiscarded(true);
//消息过滤策略
factory.setRecordFilterStrategy(consumerRecord -> {
// 这里的过滤策略自己填写就可以
int parseInt = Integer.parseInt(consumerRecord.key().split("-")[1]);
log.info("获取的key: {}", parseInt);
// 返回true消息则被过滤
return parseInt % 2 == 0;
});
return factory;
}
在@KafkaListener中注入containerFactory。
@KafkaListener(topics = {"test-consumer-2"}, groupId = "consumer-test-3", errorHandler = "listenerErrorHandler", containerFactory = "filterContainerFactory")
public void consumer(List<ConsumerRecord<String, String>> records, Acknowledgment acknowledgment) {
try {
for (ConsumerRecord<String, String> record : records) {
log.info("拉取的消息:partition = {}, offset = {}, key = {}, value = {}", record.partition(), record.offset(), record.key(), record.value());
}
acknowledgment.acknowledge();
} catch (Exception e){
log.warn("拉取消息发生异常:{}", e.getMessage());
}
}
到此kafka的一些相关应用就写完了,后续将对kafka消费者原理进行深入的讲解。
















 726
726











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









