







为了让基于类型的操作更加方便地执行,Redis 创建了自己的类型系统。
设计上:
(1)所有的redis键和值是redisObject 对象。
(2)redis的对象含有几种数据类型:字符串、哈希表、列表、集合和有序集类型。
每种数据类型有两种编码方式:
(3)对 redisObject 对象的多态操作,是基于类型(数据类型和编码类型)检查来调用多态函数。
Redis 基于数据类型和编码类型调用多态函数的步骤:
1. 根据给定 key ,在数据库字典中查找和它像对应的 redisObject ,如果没找到,就返回NULL 。
2. 检查 redisObject 的 type 属性和执行命令所需的类型是否相符,如果不相符,返回类型错误。
3. 根据 redisObject 的 encoding 属性所指定的编码,选择合适的操作函数来处理底层的数据结构。
4. 返回数据结构的操作结果作为命令的返回值。
1、 对象处理机制
键的类型和操作命令:
在 Redis 的命令中,用于对键(key)进行处理的命令占了很大一部分,而对于键所保存的值的
类型(后简称“键的类型”),键能执行的命令又各不相同。
比如说,LPUSH 和 LLEN 只能用于列表键,而 SADD 和 SRANDMEMBER 只能用于集合键,等等。另外一些命令,比如 DEL 、TTL 和 TYPE ,可以用于任何类型的键,但是,要正确实现这些命令,必须为不同类型的键设置不同的处理方式:比如说,删除一个列表键和删除一个字符串键的操作过程就不太一样。
以上的描述说明,Redis 必须让每个键都带有类型信息,使得程序可以检查键的类型,并为它选择合适的处理方式。
数据类型的编码:
另外,在前面介绍各个底层数据结构时有提到,Redis 的每一种数据类型,比如字符串、列表、有序集,它们都拥有不只一种底层实现(Redis 内部称之为编码,encoding),这说明,每当对某种数据类型的键进行操作时,程序都必须根据键所采取的编码,进行不同的操作。
比如说,集合类型就可以由字典和整数集合两种不同的数据结构实现,但是,当用户执行ZADD 命令时,他/她应该不必关心集合使用的是什么编码,只要 Redis 能按照 ZADD 命令的指示,将新元素添加到集合就可以了。
数据类型的多态:
这说明,操作数据类型的命令除了要对键的类型进行检查之外,还需要根据数据类型的不同编码进行多态处理。
为了解决以上问题,Redis 构建了自己的类型系统,这个系统的主要功能包括:
• redisObject 对象。
• 基于 redisObject 对象的类型检查。
• 基于 redisObject 对象的显式多态函数。
• 对 redisObject 进行分配、共享和销毁的机制。
以下小节将分别介绍类型系统的这几个方面。
Note: 因为 C 并不是面向对象语言,这里将 redisObject 称呼为对象一是为了讲述的方便,二是希望通过模仿 OOP 的常用术语,让这里的内容更容易被理解,redisObject 实际上是只是一个结构类型。
2、 redisObject 数据结构
redisObject 是 Redis 类型系统的核心,数据库中的每个键、值,以及 Redis 本身处理的参数,都表示为这种数据类型。
redisObject 的定义位于 redis.h :
/*
* Redis 对象
*/
typedef struct redisObject {
// 类型
unsigned type:4;
// 对齐位
unsigned notused:2;
// 编码方式
unsigned encoding:4;
// LRU 时间(相对于 server.lruclock)
unsigned lru:22;
// 引用计数
int refcount;
// 指向对象的值
void *ptr;
} robj;type 、encoding 和 ptr 是最重要的三个属性。
type 记录了对象所保存的值的类型,它的值可能是以下常量的其中一个(定义位于 redis.h):
/*
* 对象类型
*/
# define REDIS_STRING 0 // 字符串
# define REDIS_LIST 1 // 列表
# define REDIS_SET 2 // 集合
# define REDIS_ZSET 3 // 有序集
# define REDIS_HASH 4 // 哈希表encoding 记录了对象所保存的值的编码,它的值可能是以下常量的其中一个(定义位于redis.h):
/*
* 对象编码
*/
# define REDIS_ENCODING_RAW 0 // 编码为字符串
# define REDIS_ENCODING_INT 1 // 编码为整数
# define REDIS_ENCODING_HT 2 // 编码为哈希表
# define REDIS_ENCODING_ZIPMAP 3 // 编码为 zipmap
# define REDIS_ENCODING_LINKEDLIST 4 // 编码为双端链表
# define REDIS_ENCODING_ZIPLIST 5 // 编码为压缩列表
# define REDIS_ENCODING_INTSET 6 // 编码为整数集合
# define REDIS_ENCODING_SKIPLIST 7 // 编码为跳跃表ptr 是一个指针,指向实际保存值的数据结构,这个数据结构由 type 属性和 encoding 属性决定。
举个例子,如果一个 redisObject 的 type 属性为 REDIS_LIST , encoding 属性为REDIS_ENCODING_LINKEDLIST ,那么这个对象就是一个 Redis 列表,它的值保存在一个双端链表内,而 ptr 指针就指向这个双端链表;
另一方面,如果一个 redisObject 的 type 属性为 REDIS_HASH , encoding 属性为REDIS_ENCODING_ZIPMAP ,那么这个对象就是一个 Redis 哈希表,它的值保存在一个 zipmap里,而 ptr 指针就指向这个 zipmap ;诸如此类。
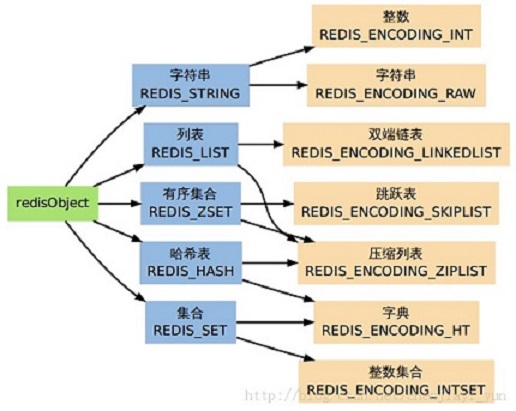
下图展示了 redisObject 、Redis 所有数据类型、以及 Redis 所有编码方式(底层实现)三者之间的关系:
这个图展示了 Redis 各种数据类型,以及它们的编码方式。
Note: REDIS_ENCODING_ZIPMAP 没有出现在图中,因为从 Redis 2.6 开始,它不再是任何数据类型的底层结构。
3、 命令的类型检查和多态
有了 redisObject 结构的存在,在执行处理数据类型的命令时,进行类型检查和对编码进行多态操作就简单得多了。
当执行一个处理数据类型的命令时,Redis 执行以下步骤:
1. 根据给定 key ,在数据库字典中查找和它像对应的 redisObject ,如果没找到,就返回NULL 。
2. 检查 redisObject 的 type 属性和执行命令所需的类型是否相符,如果不相符,返回类型错误。
3. 根据 redisObject 的 encoding 属性所指定的编码,选择合适的操作函数来处理底层的数据结构。
4. 返回数据结构的操作结果作为命令的返回值。
作为例子,以下展示了对键 key 执行 LPOP 命令的完整过程:

4、对象共享
有一些对象在 Redis 中非常常见,比如命令的返回值 OK 、ERROR 、WRONGTYPE 等字符,另外,一些小范围的整数,比如个位、十位、百位的整数都非常常见。为了利用这种常见情况,Redis 在内部使用了一个 Flyweight 模式 :通过预分配一些常见的值对象,并在多个数据结构之间共享这些对象,程序避免了重复分配的麻烦,也节约了一些 CPU时间。
Redis 预分配的值对象有如下这些:
• 各种命令的返回值,比如执行成功时返回的 OK ,执行错误时返回的 ERROR ,类型错误时返回的 WRONGTYPE ,命令入队事务时返回的 QUEUED ,等等。
• 包 括 0 在 内, 小 于 redis.h/REDIS_SHARED_INTEGERS 的 所 有 整 数(REDIS_SHARED_INTEGERS 的默认值为 10000)
因为命令的回复值直接返回给客户端,所以它们的值无须进行共享;另一方面,如果某个命令的输入值是一个小于 REDIS_SHARED_INTEGERS 的整数对象,那么当这个对象要被保存进数据库时,Redis 就会释放原来的值,并将值的指针指向共享对象。
作为例子,下图展示了三个列表,它们都带有指向共享对象数组中某个值对象的指针:

三个列表的值分别为:
• 列表 A :[20130101, 300, 10086] ,
• 列表 B :[81, 12345678910, 999] ,
• 列表 C :[100, 0, -25, 123] 。
Note: 共享对象只能被带指针的数据结构使用。
需要提醒的一点是,共享对象只能被字典和双端链表这类能带有指针的数据结构使用。
像整数集合和压缩列表这些只能保存字符串、整数等字面值的内存数据结构,就不能使用共享对象。
1) 引用计数以及对象的销毁
当将 redisObject 用作数据库的键或者值,而不是用来储存参数时,对象的生命期是非常长的,因为 C 语言本身没有自动释放内存的相关机制,如果只依靠程序员的记忆来对对象进行追踪和销毁,基本是不太可能的。
另一方面,正如前面提到的,一个共享对象可能被多个数据结构所引用,这时像是“这个对象被引用了多少次?”之类的问题就会出现。
为了解决以上两个问题,Redis 的对象系统使用了引用计数技术来负责维持和销毁对象,它的运作机制如下:
• 每个 redisObject 结构都带有一个 refcount 属性,指示这个对象被引用了多少次。
• 当新创建一个对象时,它的 refcount 属性被设置为 1 。
• 当对一个对象进行共享时,Redis 将这个对象的 refcount 增一。
• 当使用完一个对象之后,或者取消对共享对象的引用之后,程序将对象的 refcount 减一。
• 当对象的 refcount 降至 0 时,这个 redisObject 结构,以及它所引用的数据结构的内存,都会被释放。
小结
• Redis 使用自己实现的对象机制来实现类型判断、命令多态和基于引用计数的垃圾回收。
• 一种 Redis 类型的键可以有多种底层实现。
• Redis 会预分配一些常用的数据对象,并通过共享这些对象来减少内存占用,和避免频繁地为小对象分配内存。
5、数据类型
(1) 字符串
REDIS_STRING (字符串)是 Redis 使用得最为广泛的数据类型,它除了是 SET 、GET 等命令的操作对象之外,数据库中的所有键,以及执行命令时提供给 Redis 的参数,都是用这种类型保存的。
字符串编码
字符串类型分别使用 REDIS_ENCODING_INT 和 REDIS_ENCODING_RAW 两种编码:
• REDIS_ENCODING_INT 使用 long 类型来保存 long 类型值。
• REDIS_ENCODING_RAW 则使用 sdshdr 结构来保存 sds (也即是 char* )、long long 、double 和 long double 类型值。
换句话来说,在 Redis 中,只有能表示为 long 类型的值,才会以整数的形式保存,其他类型的整数、小数和字符串,都是用 sdshdr 结构来保存。

编码的选择
新创建的字符串默认使用 REDIS_ENCODING_RAW 编码,在将字符串作为键或者值保存进数据库时,程序会尝试将字符串转为 REDIS_ENCODING_INT 编码。
字符串命令的实现
Redis 的字符串类型命令,基本上是通过包装 sds 数据结构的操作函数来实现的,没有什么需要说明的地方。
(2) 哈希表
REDIS_HASH (哈 希 表) 是 HSET 、 HLEN 等 命 令 的 操 作 对 象, 它 使 用REDIS_ENCODING_ZIPLIST 和 REDIS_ENCODING_HT 两种编码方式:

字典编码的哈希表
当哈希表使用字典编码时,程序将哈希表的键(key)保存为字典的键,将哈希表的值(value)保存为字典的值。
哈希表所使用的字典的键和值都是字符串对象。
下图展示了一个包含三个键值对的哈希表:

压缩列表编码的哈希表
当使用 REDIS_ENCODING_ZIPLIST 编码哈希表时,程序通过将键和值一同推入压缩列表,从而形成保存哈希表所需的键 -值对结构:

新添加的 key-value 对会被添加到压缩列表的表尾。
当进行查找/删除或更新操作时,程序先定位到键的位置,然后再通过对键的位置来定位值的位置。
编码的选择
创建空白哈希表时,程序默认使用 REDIS_ENCODING_ZIPLIST 编码,当以下任何一个条件被满足时,程序将编码从切换为 REDIS_ENCODING_HT :
• 哈希表中某个键或某个值的长度大于 server.hash_max_ziplist_value(默认值为 64)。
• 压缩列表中的节点数量大于 server.hash_max_ziplist_entries(默认值为 512 )。
哈希命令的实现
哈希类型命令的实现全都是对字典和压缩列表操作函数的包装,以及几个在两种编码之间进行转换的函数,没有特别要讲解的地方。
(3)列表
REDIS_LIST (列 表) 是 LPUSH 、 LRANGE 等 命 令 的 操 作 对 象, 它 使 用REDIS_ENCODING_ZIPLIST 和 REDIS_ENCODING_LINKEDLIST 这两种方式编码:

编码的选择
创建新列表时 Redis 默认使用 REDIS_ENCODING_ZIPLIST 编码,当以下任意一个条件被满足时,列表会被转换成 REDIS_ENCODING_LINKEDLIST 编码:
• 试 图 往 列 表 新 添 加 一 个 字 符 串 值, 且 这 个 字 符 串 的 长 度 超 过server.list_max_ziplist_value (默认值为 64 )。
• ziplist 包含的节点超过 server.list_max_ziplist_entries (默认值为 512 )。
列表命令的实现
因为两种底层实现的抽象方式和列表的抽象方式非常接近,所以列表命令几乎就是通过一对一地映射到底层数据结构的操作来实现的。
既然这些映射都非常直观,这里就不做赘述了,在以下的内容中,我们将焦点放在 BLPOP 、BRPOP 和 BRPOPLPUSH 这个几个阻塞命令的实现原理上。
阻塞的条件
BLPOP 、BRPOP 和 BRPOPLPUSH 三个命令都可能造成客户端被阻塞,以下将这些命令统称为列表的阻塞原语。
阻塞原语并不是一定会造成客户端阻塞:
• 只有当这些命令被用于空列表时,它们才会阻塞客户端。
• 如果被处理的列表不为空的话,它们就执行无阻塞版本的 LPOP 、RPOP 或 RPOPL-PUSH 命令。
作为例子,以下流程图展示了 BLPOP 决定是否对客户端进行阻塞过程:
当一个阻塞原语的处理目标为空键时,执行该阻塞原语的客户端就会被阻塞。阻塞一个客户端需要执行以下步骤:
1. 将客户端的状态设为“正在阻塞”,并记录阻塞这个客户端的各个键,以及阻塞的最长时限(timeout)等数据。
2. 将客户端的信息记录到 server.db[i]->blocking_keys 中(其中 i 为客户端所使用的数据库号码)。
3. 继续维持客户端和服务器之间的网络连接,但不再向客户端传送任何信息,造成客户端阻塞。
步骤 2 是将来解除阻塞的关键,server.db[i]->blocking_keys 是一个字典,字典的键是那些造成客户端阻塞的键,而字典的值是一个链表,链表里保存了所有因为这个键而被阻塞的客户端(被同一个键所阻塞的客户端可能不止一个):

在上图展示的 blocking_keys 例子中,client2 、client5 和 client1 三个客户端就正被key1 阻塞,而其他几个客户端也正在被别的两个 key 阻塞。
当客户端被阻塞之后,脱离阻塞状态有以下三种方法:
1. 被动脱离:有其他客户端为造成阻塞的键推入了新元素。
2. 主动脱离:到达执行阻塞原语时设定的最大阻塞时间。
3. 强制脱离:客户端强制终止和服务器的连接,或者服务器停机。
以下内容将分别介绍被动脱离和主动脱离的实现方式。
阻塞因 LPUSH 、RPUSH 、LINSERT 等添加命令而被取消通过将新元素推入造成客户端阻塞的某个键中,可以让相应的客户端从阻塞状态中脱离出来(取消阻塞的客户端数量取决于推入元素的数量)。
LPUSH 、 RPUSH 和 LINSERT 这三个添加新元素到列表的命令,在底层都由一个pushGenericCommand 的函数实现,这个函数的运作流程如下图:

当向一个空键推入新元素时,pushGenericCommand 函数执行以下两件事:
1. 检查这个键是否存在于前面提到的 server.db[i]->blocking_keys 字典里,如果是的话,那么说明有至少一个客户端因为这个 key 而被阻塞,程序会为这个键创建一个
redis.h/readyList 结构,并将它添加到 server.ready_keys 链表中。
2. 将给定的值添加到列表键中。
readyList 结构的定义如下:
typedef struct readyList {
redisDb *db;
robj *key;
} readyList;readyList 结构的 key 属性指向造成阻塞的键,而 db 则指向该键所在的数据库。
举个例子,假设某个非阻塞客户端正在使用 0 号数据库,而这个数据库当前的 blocking_keys属性的值如下:

如果这时客户端对该数据库执行 PUSH key3 value ,那么 pushGenericCommand 将创建一个db 属性指向 0 号数据库、key 属性指向 key3 键对象的 readyList 结构,并将它添加到服务器server.ready_keys 属性的链表中:

在我们这个例子中,到目前为止,pushGenericCommand 函数完成了以下两件事:
1. 将 readyList 添加到服务器。
2. 将新元素 value 添加到键 key3 。
虽然 key3 已经不再是空键,但到目前为止,被 key3 阻塞的客户端还没有任何一个被解除阻塞状态。
为了做到这一点,Redis 的主进程在执行完 pushGenericCommand 函数之后,会继续调用handleClientsBlockedOnLists 函数,这个函数执行以下操作:
1. 如果 server.ready_keys 不为空,那么弹出该链表的表头元素,并取出元素中的readyList 值。
2. 根据 readyList 值所保存的 key 和 db ,在 server.blocking_keys 中查找所有因为 key而被阻塞的客户端(以链表的形式保存)。
3. 如果 key 不为空,那么从 key 中弹出一个元素,并弹出客户端链表的第一个客户端,然后将被弹出元素返回给被弹出客户端作为阻塞原语的返回值。
4. 根据 readyList 结构的属性,删除 server.blocking_keys 中相应的客户端数据,取消客户端的阻塞状态。
伪代码如下:

先阻塞先服务(FBFS)策略
值得一提的是,当程序添加一个新的被阻塞客户端到 server.blocking_keys 字典的链表中时,它将该客户端放在链表的最后,而当 handleClientsBlockedOnLists 取消客户端的阻塞时,它从链表的最前面开始取消阻塞。
这个链表形成了一个 FIFO 队列,最先被阻塞的客户端总值最先脱离阻塞状态, Redis 文档称这种模式为先阻塞先服务(FBFS, first-block-first-serve)。
举个例子,在下图所示的阻塞状况中,如果客户端对数据库执行 PUSH key3 value ,那么只有client3 会被取消阻塞,client6 和 client4 仍然阻塞;如果客户端对数据库执行 PUSH key3 value1 value2 ,那么 client3 和 client4 的阻塞都会被取消,而客户端 client6 依然处于阻塞状态:

阻塞因超过最大等待时间而被取消。前面提到过,当客户端被阻塞时,所有造成它阻塞的键,以及阻塞的最长时限会被记录在客户端里面,并且该客户端的状态会被设置为“正在阻塞”。
每次 Redis 服务器常规操作函数(server cron job)执行时,程序都会检查所有连接到服务器的客户端,查看那些处于“正在阻塞”状态的客户端的最大阻塞时限是否已经过期,如果是的话,就给客户端返回一个空白回复,然后撤销对客户端的阻塞。
伪代码如下:

(4) 集合
REDIS_SET (集 合) 是 SADD 、 SRANDMEMBER 等 命 令 的 操 作 对 象, 它 使 用REDIS_ENCODING_INTSET 和 REDIS_ENCODING_HT 两种方式编码:

编码的选择
第一个添加到集合的元素,决定了创建集合时所使用的编码:
• 如果第一个元素可以表示为 long long 类型值(也即是,它是一个整数),那么集合的初始编码为 REDIS_ENCODING_INTSET 。
• 否则,集合的初始编码为 REDIS_ENCODING_HT 。
编码的切换
如果一个集合使用 REDIS_ENCODING_INTSET 编码,那么当以下任何一个条件被满足时,这个集合会被转换成 REDIS_ENCODING_HT 编码:
• intset 保存的整数值个数超过 server.set_max_intset_entries (默认值为 512 )。
• 试图往集合里添加一个新元素,并且这个元素不能被表示为 long long 类型(也即是,它不是一个整数)。
字典编码的集合
当使用 REDIS_ENCODING_HT 编码时,集合将元素保存到字典的键里面,而字典的值则统一设为 NULL 。
作为例子,以下图片展示了一个以 REDIS_ENCODING_HT 编码表示的集合,集合的成员为 elem1、elem2 和 elem3 :

集合命令的实现
Redis 集合类型命令的实现,主要是对 intset 和 dict 两个数据结构的操作函数的包装,以及一些在两种编码之间进行转换的函数,大部分都没有什么需要解释的地方,唯一比较有趣的是SINTER 、SUNION 等命令之下的算法实现,以下三个小节就分别讨论它们所使用的算法。
求交集算法
SINTER 和 SINTERSTORE 两个命令所使用的求并交集算法可以用 Python 表示如下:
# coding: utf-8
def sinter(*multi_set):
# 根据集合的基数进行排序
sorted_multi_set = sorted(multi_set, lambda x, y: len(x) - len(y))
# 使用基数最小的集合作为基础结果集,有助于降低常数项
result = sorted_multi_set[0].copy()
# 剔除所有在 sorted_multi_set[0] 中存在
# 但在其他某个集合中不存在的元素
for elem in sorted_multi_set[0]:
for s in sorted_multi_set[1:]:
if (not elem in s):
result.remove(elem)
break
return result算法的复杂度为 O(N2) ,执行步数为 S * T ,其中 S 为输入集合中基数最小的集合,而 T 则为输入集合的数量。
求并集算法
SUNION 和 SUNIONSTORE 两个命令所使用的求并集算法可以用 Python 表示如下:
# coding: utf-8
def sunion(*multi_set):
result = set()
for s in multi_set:
for elem in s:
# 重复的元素会被自动忽略
result.add(elem)
return result算法的复杂度为 O(N ) 。
求差集算法
Redis 为 SDIFF 和 SDIFFSTORE 两个命令准备了两种求集合差的算法。
以 Python 代码表示的算法一定义如下:
# coding: utf-8
def sdiff_1(*multi_set):
result = multi_set[0].copy()
sorted_multi_set = sorted(multi_set[1:], lambda x, y: len(x) - len(y))
# 当 elem 存在于除 multi_set[0] 之外的集合时
# 将 elem 从 result 中删除
for elem in multi_set[0]:
for s in sorted_multi_set:
if elem in s:
result.remove(elem)
break
return result这个算法的复杂度为 O(N2) ,执行步数为 S T ,其中 S 为输入集合中基数最小的集合,而
T 则为除第一个集合之外,其他集合的数量。
以 Python 代码表示的算法二定于如下:
# coding: utf-8
def sdiff_2(*multi_set):
# 用第一个集合作为结果集的起始值
result = multi_set[0].copy()
for s in multi_set[1:]:
for elem in s:
# 从结果集中删去其他集合中包含的元素
if elem in result:
result.remove(elem)
return result这个算法的复杂度同样为 O(N2) ,执行步数为 S ,其中 S 为所有集合的基数总和。
Redis 使用一个程序决定该使用那个求差集算法,程序用 Python 表示如下:
# coding: utf-8
from sdiff_1 import sdiff_1
from sdiff_2 import sdiff_2
def sdiff(*multi_set):
# 算法一的常数项较低,给它一点额外的优先级
algo_one_advantage = 2
algo_one_weight = len(multi_set[0]) * len(multi_set[1:]) / algo_one_advantage
algo_two_weight = sum(map(len, multi_set))
if algo_one_weight <= algo_two_weight:
return sdiff_1(*multi_set)
else:
return sdiff_2(*multi_set)(5) 有序集
REDIS_ZSET (有 序 集) 是 ZADD 、 ZCOUNT 等 命 令 的 操 作 对 象, 它 使 用REDIS_ENCODING_ZIPLIST 和 REDIS_ENCODING_SKIPLIST 两种方式编码:

编码的选择
在通过 ZADD 命令添加第一个元素到空 key 时,程序通过检查输入的第一个元素来决定该创建什么编码的有序集。如果第一个元素符合以下条件的话,就创建一个 REDIS_ENCODING_ZIPLIST 编码的有序集:
• 服务器属性 server.zset_max_ziplist_entries 的值大于 0 (默认为 128 )。
• 元素的 member 长度小于服务器属性 server.zset_max_ziplist_value 的值(默认为 64)。
否则,程序就创建一个 REDIS_ENCODING_SKIPLIST 编码的有序集。
编码的转换
对于一个 REDIS_ENCODING_ZIPLIST 编码的有序集,只要满足以下任一条件,就将它转换为REDIS_ENCODING_SKIPLIST 编码:
• ziplist 所保存的元素数量超过服务器属性 server.zset_max_ziplist_entries 的值(默认值为 128 )
• 新添加元素的 member 的长度大于服务器属性 server.zset_max_ziplist_value 的值(默认值为 64 )
ZIPLIST 编码的有序集
当使用 REDIS_ENCODING_ZIPLIST 编码时,有序集将元素保存到 ziplist 数据结构里面。
其中,每个有序集元素以两个相邻的 ziplist 节点表示,第一个节点保存元素的 member 域,第二个元素保存元素的 score 域。
多个元素之间按 score 值从小到大排序,如果两个元素的 score 相同,那么按字典序对 member进行对比,决定那个元素排在前面,那个元素排在后面。
SKIPLIST 编码的有序集
当使用 REDIS_ENCODING_SKIPLIST 编码时,有序集元素由 redis.h/zset 结构来保存:
/*
* 有序集
*/
typedef struct zset {
// 字典
dict *dict;
// 跳跃表
zskiplist *zsl;
} zset;zset 同时使用字典和跳跃表两个数据结构来保存有序集元素。
其中,元素的成员由一个 redisObject 结构表示,而元素的 score 则是一个 double 类型的浮点数,字典和跳跃表两个结构通过将指针共同指向这两个值来节约空间(不用每个元素都复制两份)。
下图展示了一个 REDIS_ENCODING_SKIPLIST 编码的有序集:

通过使用字典结构,并将 member 作为键,score 作为值,有序集可以在 O(1) 复杂度内:
• 检查给定 member 是否存在于有序集(被很多底层函数使用);
• 取出 member 对应的 score 值(实现 ZSCORE 命令)。
另一方面,通过使用跳跃表,可以让有序集支持以下两种操作:
• 在 O(log N ) 期望时间、O(N ) 最坏时间内根据 score 对 member 进行定位(被很多底层函数使用);
• 范围性查找和处理操作,这是(高效地)实现 ZRANGE 、ZRANK 和 ZINTERSTORE等命令的关键。
通过同时使用字典和跳跃表,有序集可以高效地实现按成员查找和按顺序查找两种操作。

















 3234
3234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









