







写在前面,本人初次学习深度学习,本文用于记录和梳理知识点。
一、简单层的实现
1.乘法层的实现
层的实现中有两个共通的方法(接口)forward()和backward()。forward()对应正向传播,backward()对应反向传播。
#实现乘法类
class Mullayer:
def __init__(self): #初始化变量x、y,用于保存正向传播时的输入值
self.x = None
self.y = None
def forward(self,x,y): #正向传播时,接收x和y,将他们相乘后输出
self.x = x
self.y = y
out = x * y
print('self.y',self.y,'\n','self.x',self.x)
return out
def backward(self,dout): #反向传播时,将上游传过来的导数(dout)乘以正向传播的翻转值,然后传给下游
dx = dout * self.y #翻转x和y
dy = dout * self.x
print('dout * self.y = dx ', dout, '*', self.y,'=',dx)
print('dout * self.x = dy ', dout, '*', self.x,'=',dy)
return dx,dy
下面测试实现该示例:

#以下测试
apple_price = 100
apple_num = 2
tax = 1.1
#layer 初始化两个类层
mul_apple_layer = Mullayer()
mul_tax_layer = Mullayer()
#forward 首先需要进行正向传播
print('正向传播计算苹果总价(mul_apple_layer)')
apple_price_sum = mul_apple_layer.forward(apple_price,apple_num)
print('apple_price_sum',apple_price_sum)
print('正向传播就算税后总价(mul_tax_layer)')
price = mul_tax_layer.forward(apple_price_sum,tax)
print('税后price',price)
#backward 计算各个变量的导数
dprice = 1
print('\n消费税导数计算(mul_tax_layer)')
dapple_price,dtax = mul_tax_layer.backward(dprice)
print('dtax',dtax)
print('苹果个数及苹果单价导数计算(mul_apple_layer)')
dapple,dapple_num = mul_apple_layer.backward(dapple_price)
print('dapple',dapple,'\n','dapple_num',dapple_num,'\n')
结果如下:
 结果结合代码及注释方便理解。
结果结合代码及注释方便理解。
2.加法层的实现
加法层实现代码如下
#加法层的实现
class AddLayer:
def __init__(self):
pass #空语句
def forward(self,x,y):
out = x + y
print('out = x + y ',out,'=',x,'+',y)
return out
def backward(self,dout):
dx = dout * 1
dy = dout * 1
print('dout * 1 = dx ', dout, '* 1', '=', dx)
print('dout * 1 = dy ', dout, '* 1', '=', dy)
return dx,dy
测试以下示例:
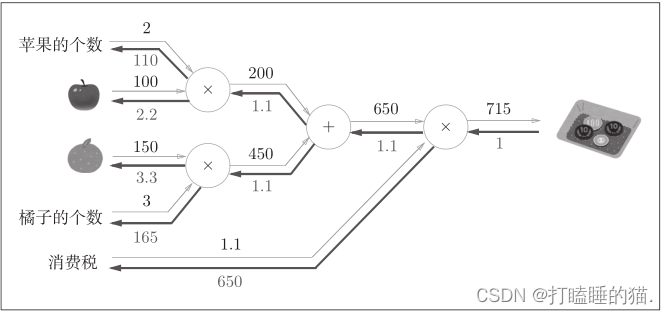
#以下测试
apple = 100
apple_num = 2
orange_num = 3
orange = 150
tax = 1.1
#layer 该示例中有三个乘法层,一个加法层
mul_apple_layer = Mullayer()
mul_orange_layer = Mullayer()
add_apple_orange_layer = AddLayer()
mul_tax_layer = Mullayer()
#forward 正向传播
print('正向传播计算苹果总价(mul_apple_layer)')
apple_price = mul_apple_layer.forward(apple,apple_num)
print('正向传播计算橘子总价(mul_orange_layer)')
orange_price = mul_orange_layer.forward(orange,orange_num)
print('正向传播计算水果总价总价(add_apple_orange_layer)')
all_price = add_apple_orange_layer.forward(apple_price,orange_price)
print('计算水果税后价格(mul_tax_layer)')
price = mul_tax_layer.forward(all_price,tax)
#backward
dprice = 1
print('\n消费税导数(mul_tax_layer)')
dprice,dtax = mul_tax_layer.backward(dprice)
print('苹果总价和橘子总价导数(mul_tax_layer)')
dapple_price,dorange_price = add_apple_orange_layer.backward(dprice)
print('苹果个数、苹果单价导数(mul_apple_layer)')
dapple,dapple_num = mul_apple_layer.backward(dapple_price)
print('橘子个数、橘子单价导数(mul_orange_layer)')
dorange,dorange_num = mul_orange_layer.backward(dorange_price)
print('\ndtax',dtax,'\n','dapple_price',dapple_price,'\n',\
'dorange_price',dorange_price,'\n','dapple_num',dapple_num,'\n','dapple',dapple,'\n',\
'dorange_num',dorange_num,'\n','dorange',dorange)
结果如下:

3.激活函数层的实现
3.1 激活函数ReLU如下:
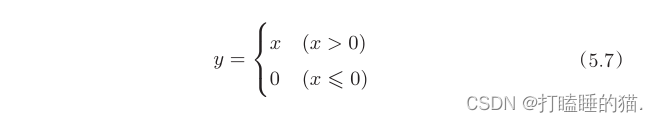
求y关于x的导数
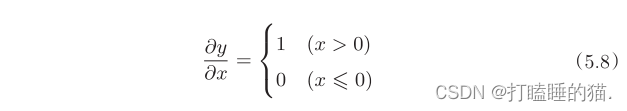
在式(5.8)中,如果正向传播时的输入x大于0,则反向传播会将上游的值原封不动地传给下游。反过来,如果正向传播时的x小于等于0,则反向传播中传给下游的信号将停在此处。
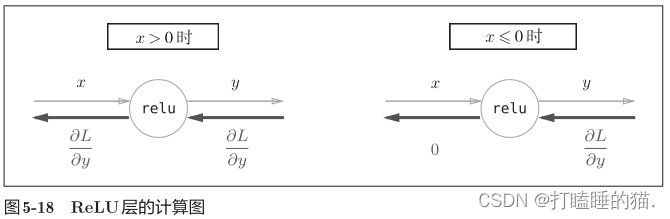
代码实现与测试如下;
import numpy as np
class Relu:
def __init__(self):
self.mask = None
def forward(self,x):
self.mask = (x <= 0)
print('mask',self.mask)
out = x.copy()
print('out',out)
out[self.mask] = 0
print('正向传播结果\n', out)
return out
def backward(self,dout):
dout[self.mask] = 0
dx = dout
return dx
#测试
x_relu = Relu()
x = np.array([[1.0,-0.5],[-2.0,3.0]])
out = x_relu.forward(x)
dx = x_relu.backward(out)
print('反向传播结果\n',dx)
结果如下:

如5-18所示,如果正向传播时的输入值小于等于0,则反向传播的值为0。因此,反向传播中会使用正向传播时保存的 mask ,将从上游传来的 dout 的mask 中的元素为 True 的地方设为0。
3.2 Sigmoid层
sigmid函数如下:
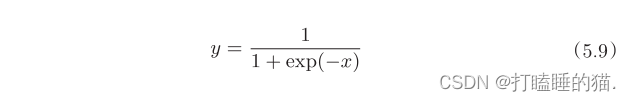
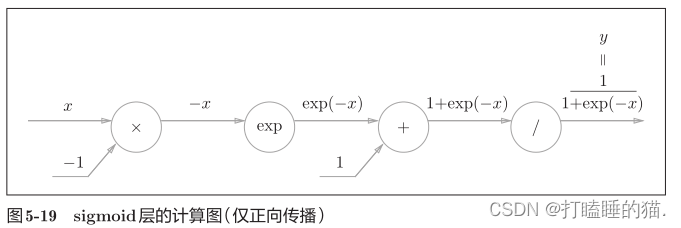
新的节点“exp”会进行y=exp(x)的计算,“/”节点会进行y=1/x的计算

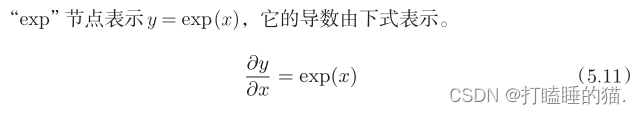
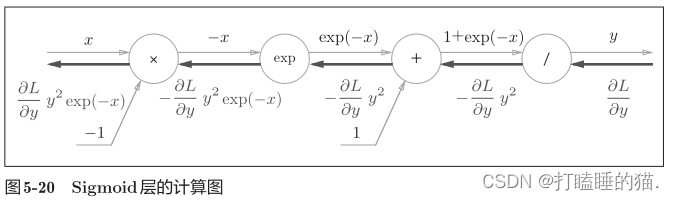
最后结果只根据正向传播时的输入x和输出y就可以算出来,图5-20的计算图可以画成图5-21的集约化的“sigmoid”节点。
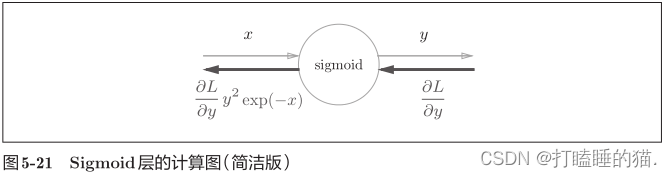
进一步整理:
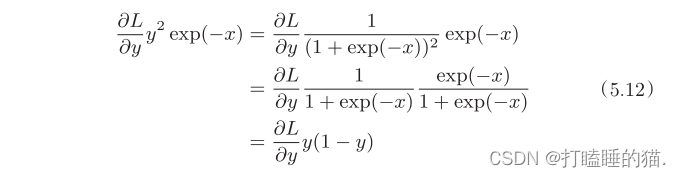
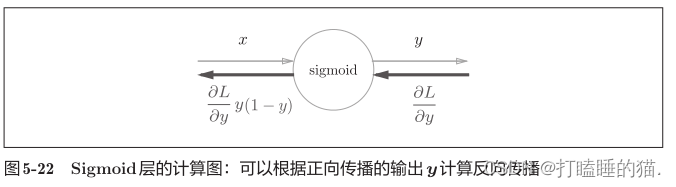
代码实现:
import numpy as np
class Sigmoid:
def __init__(self):
self.out = None
def forward(self,x):
out = 1 / (1 + np.exp(-x))
self.out = out
return out
def backward(self,dout):
dx = dout * (1.0 - self.out) * self.out
return dx
#测试
x_sigmoid = Sigmoid()
out = x_sigmoid.forward(2)
print('正向传播结果',out)
dx = x_sigmoid.backward(1)
print('反向传播导数',dx)
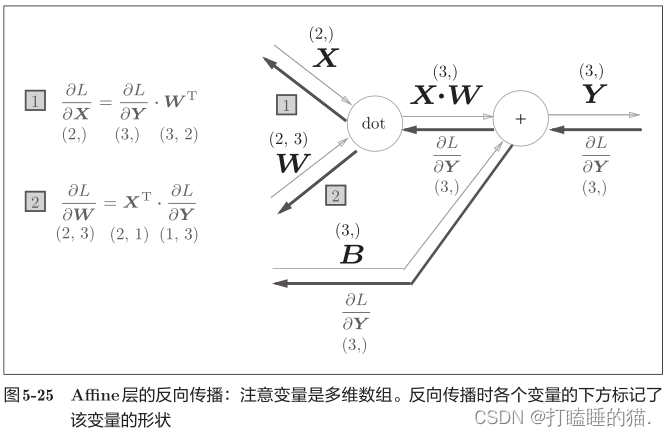
3.3 Affine层
神经网络的正向传播中,计算加权信号总和使用 Y = np.dot(x,w) + b 。Affine层的正向传播就是该公式的计算过程
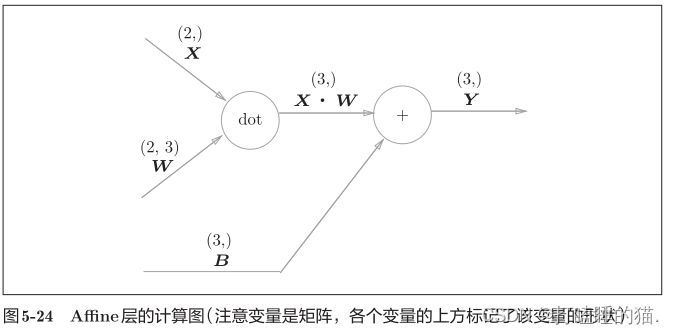
批版本的Affine层
前面的Affine层的输入X是以单个数据为对象,下面介绍N个数据一起进行正向传播的情况,也就是批版本的Affine层
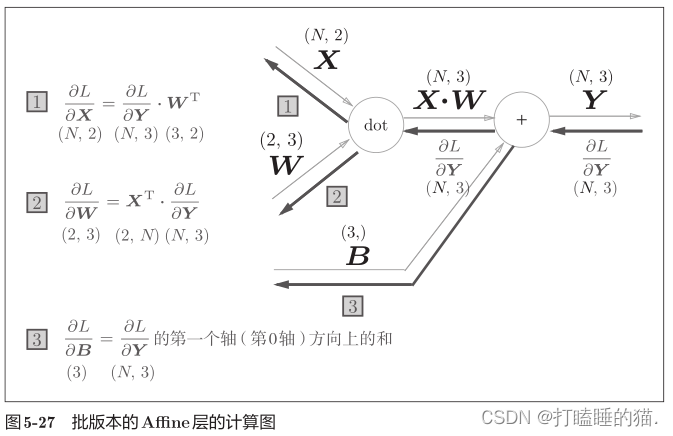
代码实现与测试:
import numpy as np
class Affine:
def __init__(self,w,b):
self.w = w
self.b = b
self.x = None
self.dw = None
self.db = None
def forward(self,x):
self.x = x
out = np.dot(x,self.w) + self.b
return out
def backward(self,dout):
dx = np.dot(dout,self.w.T)
self.dw = np.dot(self.x.T,dout)
self.db = np.sum(dout,axis=0) #np.sum()对第0轴(以数据为单位的轴,axis=0)方向上的元素进行求和
return dx
#测试
x = np.array([[1,2],[3,4]])
w = np.array([[1,2,1],[3,4,1]])
b = np.random.rand(3)
test = Affine(w,b)
out = test.forward(x)
# print(out)
dx = test.backward(out)
print('dx\n',dx,'\n','dw\n',test.w,'\n','db\n',test.db)
3.3 Softmax-with-Loss层
输出层的softmax函数会将输入值正规化之后再输出。softmax函数的输出是0.0到1.0之间的实数,并且输出值的总和为1,所以可以把softmax函数的输出解释为“概率”,softmax函数用于分类问题。
下面来实现Softmax层,考虑到这里也包含作为损失函数的交叉熵误差,所以称为“Softmax-with-Loss层”。
Softmax-with-Loss层有些复杂,详细导出过程参照附录A。
下面是简化版,假设进行3类分类,从前面的层接收3个输入值,然后softmax层将输入值(a1,a2,a3)正规化,输出(y1,y2,y3)。cross entropy error层接收softmax的输出值(y1,y2,y3)和监督数据(t1,t2,t3),从这些数据中输出损失L.
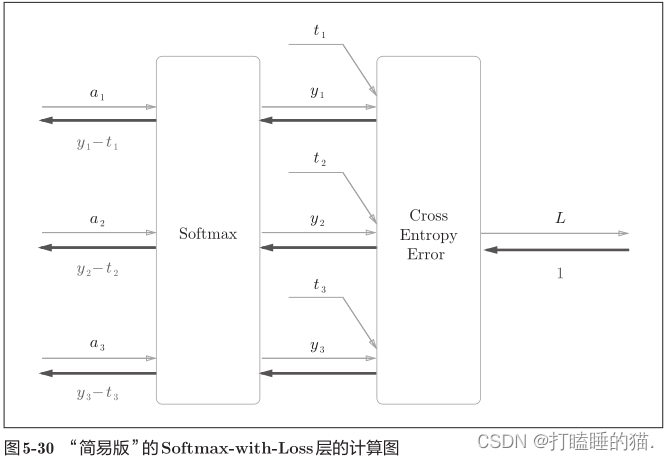
(y1,y2,y3)是Softmax层的输出,(t1,t2,t3)监督数据,所以(y1-t1,y2-t2,y3-t3)是softmax层的输出和教师标签的差分。神经网络的反向传播会把这个差分表示的误差传递给前面的层,这是神经网络学习中的重要性质。
神经网络学习的目的就是通过调整权重参数,神经网络的输出接近教师标签。
代码实现:
import numpy as np
from common.functions import *
class SoftmaxWithLoss:
def __init__(self):
self.loss = None #损失
self.y = None #softmax的输出
self.t = None #监督数据
def forward(self,x,t):
self.t = t
self.y = softmax(x)
self.loss = cross_entropy_error(self.y,self.t)
return self.loss
def backward(self,dout=1):
batch_size = self.t.shape[0] #反向传播时,将要传播的值除以批的大小(batch_size)后,传递给前面的层的是单个数据的误差
print('batch_size',batch_size)
dx = (self.y - self.t) / batch_size
return dx
#测试
t = np.array([[0,1,0],[0,0,1]])
x = np.array([[2,4,3],[3,4,5]]) #相当于上图的a值
test = SoftmaxWithLoss()
test.forward(x,t)
print('softmax输出值y\n',test.y,'\n监督标签t\n',test.t,'\n损失值\n',test.loss)
dx = test.backward()
print('误差\n',dx)
结果如下:

3.4误差反向传播法的实现
3.4.1 神经网络学习的全貌图
神经网络学习的步骤如下:
前提
神经网络中有合适的权重和偏置,调整权重和偏置以便拟合训练数据的过程称为学习。神经网络学习分为以下四个步骤
步骤1(mini-batch)
从训练数据中随机选择一部分数据。
步骤2(计算梯度)
计算损失函数关于各个权重参数的梯度。
步骤3(更新参数)
将权重参数沿梯度方向进行微小的更新。
步骤4(重复)
重复步骤1、步骤2、步骤3。
补充知识:高斯分布
高斯分布是随机分布中最常见的一种,又称为正态分布,源于误差分布。一般特征,距离真值越远,观测例数越少。若随机变量X服从一个数学期望为μ、方差为σ2的正态分布,记为N(μ,σ2)。其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。所以初始化权重时的高斯分布的规模值相当于决定分布的幅度。
下面基于误差反向传播法的两层神经网络的实现代码:
展示两层神经网络构建示例图:
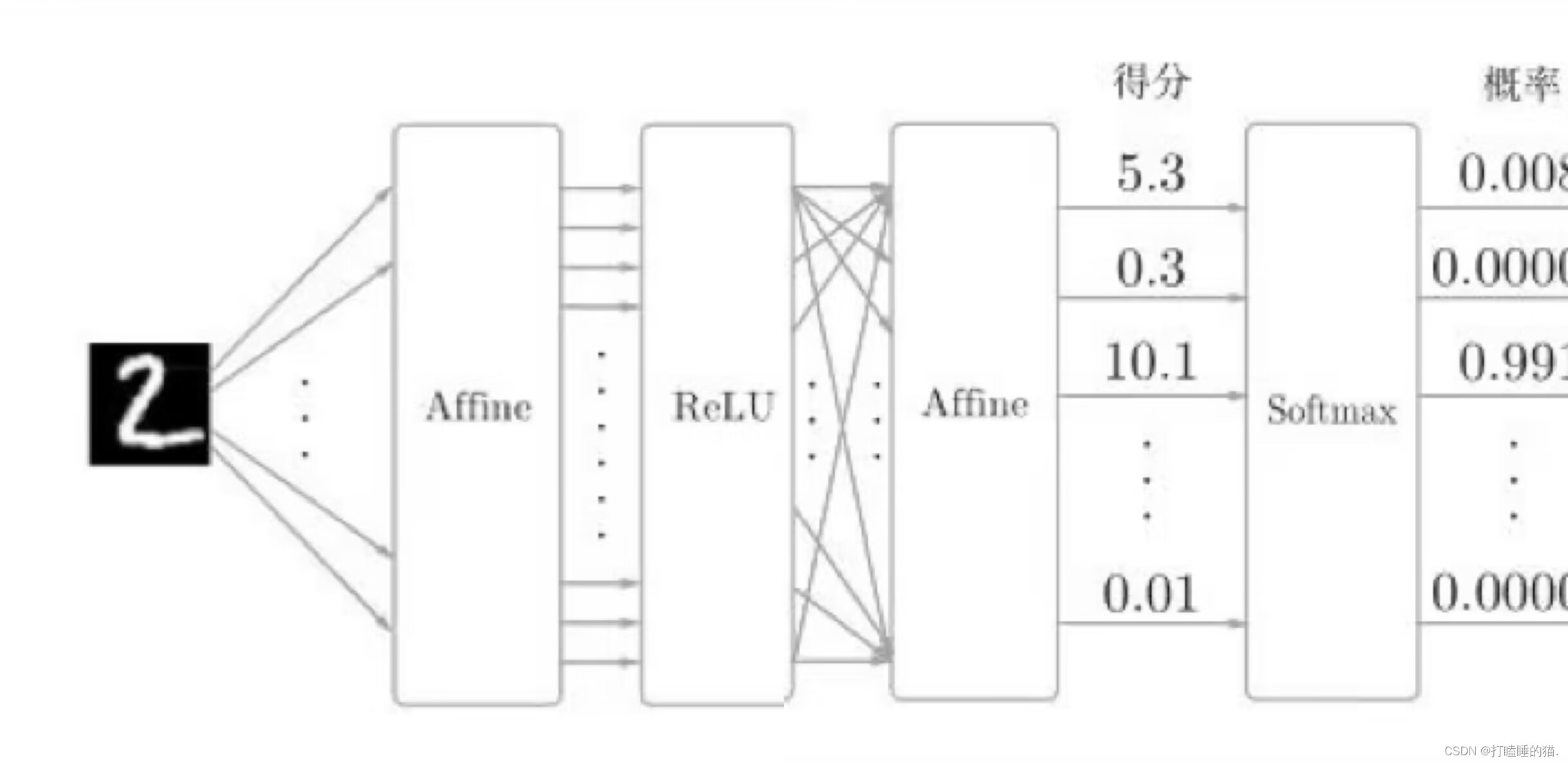
#相当于第三版的神经网络学习 3.0
#基于误差反向传播法的神经网络构建
import numpy as np
from common.layers import *
from dataset.mnist import load_mnist
from common.gradient import numerical_gradient #通过数值微分计算权重参数的梯度
from collections import OrderedDict
#引入OrderedDict有序字典,有序指 它可以记住向字典里添加元素的顺序.
# 因此,神经网络的正向传播只需要按照添加元素的顺序调用各层的forward()方法就可以完成处理,
# 而反向传播只需按照相反的顺序调用各层即可。
# Affine层和ReLU层的内部会正确处理正向和反向传播,所以这里需要的是仅仅以正确的顺序连接各层,
# 再按照顺序或者逆序调用各层
class TwoLayerNet:
def __init__(self,input_size,hidden_size,output_size,weight_init_std = 0.01):
#输入层的神经元数、隐藏层的神经元数、输出层的神经元数、初始化权重时的高斯分布的规模
#初始化权重
self.params = {}
self.params['W1'] = weight_init_std * \
np.random.rand(input_size,hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * \
np.random.rand(hidden_size,output_size)
self.params['b2'] = np.zeros(output_size)
#以下 生成层和predict相当于 #神经网络的设计及输出(进行识别推理,x是图像数据)
#生成层 // 激活函数层的实现
self.layers = OrderedDict() #记住向字典里添加元素的顺序,也就是各激活函数的顺序
self.layers['Affine1'] = Affine(self.params['W1'],self.params['b1'])
self.layers['Relu1'] = Relu()
self.layers['Affine2'] = Affine(self.params['W2'],self.params['b2'])
self.lastLayer = SoftmaxWithLoss()
def predict(self,x):
for layer in self.layers.values():
x = layer.forward(x)
return x
#x:输入数据 t:监督数据
def loss(self,x,t):
y = self.predict(x)
return self.lastLayer.forward(y,t)
#计算识别精确度,即能在多大程度上正确分类
def accuracy(self,x,t):
y = self.predict(x)
y = np.argmax(y,axis=1) #argmax获取最大值元素的索引
#对比y 与 t的标签是否对应
if t.ndim != 1 : t = np.argmax(t,axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
# 计算权重参数的梯度
#通过数值微分计算(效率太低)
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
grads = {}
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
#通过误差反向传播法计算权重参数的梯度 3.0版本的重要更新函数
def gradient(self,x,t):
#forward
self.loss(x,t)
#backward 构建反向传播层
dout = 1
dout = self.lastLayer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
#设定反向传播的值 存放在grads字典中
grads = {}
grads['W1'] = self.layers['Affine1'].dW
grads['b1'] = self.layers['Affine1'].db
grads['W2'] = self.layers['Affine2'].dW
grads['b2'] = self.layers['Affine2'].db
return grads
下面测试两种权重参数梯度计算方法的误差:
#正式测试
#获取数据
(x_train,t_train),(x_test,t_test) = \
load_mnist(normalize=True,one_hot_label=True)
#初始化构建network
network = TwoLayerNet(input_size=784,hidden_size=50,output_size=10)
#获取前三个训练数据
x_batch = x_train[:3]
t_batch = t_train[:3]
#测试两种梯度计算方法的误差
grad_numerical = network.numerical_gradient(x_batch,t_batch)
grad_backprop = network.gradient(x_batch,t_batch)
#求各个权重的绝对误差的平均值
#print('grad_numerical.keys()',grad_numerical.keys())
#print('grad_numerical.keys()',grad_backprop.keys())
#dict_keys(['W1', 'b1', 'W2', 'b2'])
for key in grad_numerical.keys():
diff = np.average(np.abs(grad_backprop[key] - grad_numerical[key]))
print(key + ':' +str(diff))
结果如下:

可以看出,通过数值微分和误差反向传播法求出的梯度的差非常小,说明误差反向传播法的实现没有错误。
下面使用误差反向传播法的学习的实现(和第四章的两层神经网络差不多,这里是为了测试通过误差反向传播法计算权重参数的梯度,从而更新),神经网络的学习的实现就是使用mini-batch学习,所谓mini-batch学习,就是从训练数据中随机选择一部分数据(称为mini-batch),再以这些mini-batch为对象,使用梯度法不断的减小损失函数的值,以其为指标,去更新初始化的权重参数,已达到最终可以使得识别图像成功的最佳权重参数的过程,关键点在于,网络的构建,计算梯度的算法实现:
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from ch05.TwoLayerNet import TwoLayerNet
#读入图像数据
(x_train,t_train),(x_test,t_test) = load_mnist(normalize=True,one_hot_label=True)
network = TwoLayerNet(input_size=784,hidden_size=50,output_size=10)
#超参数
iters_num = 10000 #适当设定循环的次数
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
# print('x_train.shape',x_train.shape)
train_loss_list = [] #记录损失函数的值
train_acc_list = [] #存储训练数据精确度
test_acc_list = [] #存储测试数据精确度
#平均每个epoch的重复次数
iter_per_epoch = max(train_size / batch_size,1) #(60000/100 = 600)
for i in range(iters_num):
#获取mini-batch
batch_mask = np.random.choice(train_size,batch_size) #每次从60000个训练数据中取100个数据
# print(batch_mask)
x_batch = x_train[batch_mask] #(100, 784)的训练数据数组
# print('x_batch\n',x_batch.shape)
t_batch = t_train[batch_mask]
# print('训练正确解标签',t_train.shape) #(60000, 10)
# print('t_batch\n',t_batch)
#通过误差反向传播法计算权重参数的梯度
grad = network.gradient(x_batch,t_batch)
# print('梯度\n',grad)
#更新权重参数
for key in ('W1','b1','W2','b2'):
#不断的去更新权重参数,学习率可表示更新的幅度
network.params[key] -= learning_rate * grad[key]
#记录学习过程
loss = network.loss(x_batch,t_batch) #存储损失函数的值
# print('loss',loss)
train_loss_list.append(loss) #存储损失函数的值
#每经过一个epoch,就对所有训练数据和测试数据计算识别精确度
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train,t_train)
test_acc = network.accuracy(x_test,t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print('训练数据精确度,测试数据精确度',train_acc,test_acc)
#绘制图形 绘制训练数据精确度和测试数据精确度随着权重参数更新
x = np.arange(len(train_acc_list))
print('横坐标',x)
plt.plot(x,train_acc_list,label='train acc')
plt.plot(x,test_acc_list,label='test acc',linestyle='--')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0,1.0) #指定y轴的范围
plt.legend(loc='lower right')
plt.show()
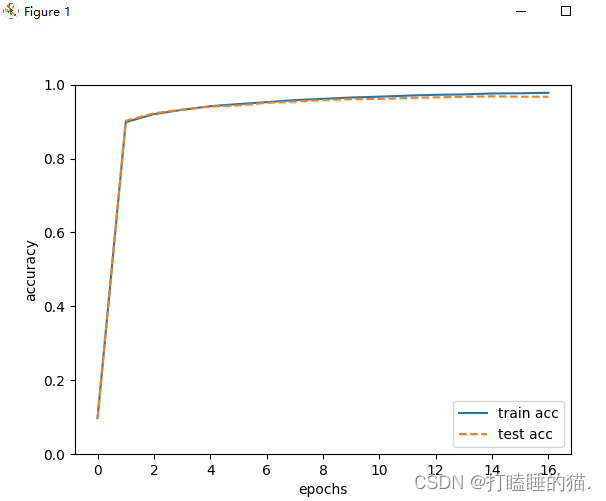
结果如下,可以看到精确度不断的提高:

小结:
本章我们介绍了将计算过程可视化的计算图,并使用计算图,介绍了神经网络中的误差反向传播法,并以层为单位实现了神经网络中的处理。我们学过的层有ReLU层、Softmax-with-Loss层、Affine层、Softmax层等,这些层中实现了 forward 和 backward 方法,通过将数据正向和反向地传播,可以高效地计算权重参数的梯度。通过使用层进行模块化,神经网络中可以自由地组装层,轻松构建出自己喜欢的网络。
本章所学的内容
• 通过使用计算图,可以直观地把握计算过程。
• 计算图的节点是由局部计算构成的。局部计算构成全局计算。
• 计算图的正向传播进行一般的计算。通过计算图的反向传播,可以计算各个节点的导数。
• 通过将神经网络的组成元素实现为层,可以高效地计算梯度(反向传播法)。
• 通过比较数值微分和误差反向传播法的结果,可以确认误差反向传播法的实现是否正确(梯度确认)。















 878
878











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











