







最近,项目做一个公司新闻网站,分为PC&移动端(h5),数据来源是从HSZX与huanqiu2个网站爬取,主要使用java编写的WebMagic作为爬虫框架,数据分为批量抓取、增量抓取,批量抓当前所有历史数据,增量需要每10分钟定时抓取一次,由于从2个网站抓取,并且频道很多,数据量大,更新频繁;开发过程中遇到很多的坑,今天腾出时间,感觉有必要做以总结。
工具说明:
1、WebMagic是一个简单灵活的爬虫框架。基于WebMagic,你可以快速开发出一个高效、易维护的爬虫。
官网地址:http://webmagic.io/
文档说明:http://webmagic.io/docs/zh/
2、jsoup是Java的一个html解析工作,解析性能很不错。
文档地址:http://www.open-open.com/jsoup/
3、Jdiy一款超轻量的java极速开发框架,javaEE/javaSE环境均适用,便捷的数据库CRUD操作API。支持各大主流数据库。
官网地址:http://www.jdiy.org/jdiy.jd
一、使用到的技术,如下:
WebMagic作为爬虫框架、httpclient作为获取网页工具、Jsoup作为分析页面定位抓取内容、ExecutorService线程池作为定时增量抓取、Jdiy作为持久层框架
二、历史抓取代码,如下:
package com.spider.huanqiu.history;
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.lang3.StringUtils;
import org.jdiy.core.Rs;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import com.spider.huasheng.history.Pindao;
import com.spider.utils.Config;
import com.spider.utils.ConfigBase;
import com.spider.utils.DateUtil;
import com.spider.utils.HttpClientUtil;
import com.spider.utils.service.CommService;
/**
* 描 述:抓取xxx-国际频道历史数据
* 创建时间:2016-11-9
* @author Jibaole
*/
public class HQNewsDao extends ConfigBase implements PageProcessor{
public static final String index_list = "(.*).huanqiu.com/(.*)pindao=(.*)";//校验地址正则
public static String pic_dir = fun.getProValue(PINDAO_PIC_FILE_PATH);//获取图片保存路径
// 部分一:抓取网站的相关配置,包括编码、重试次数、抓取间隔、超时时间、请求消息头、UA信息等
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(6000)
.addHeader("Accept-Encoding", "/").setUserAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.59 Safari/537.36");
@Override
public Site getSite() {
return site;
}
@Override
public void process(Page page) {
try {
//列表页
if (page.getUrl().regex(index_list).match()) {
List<String> Urllist =new ArrayList<String>();
String url =page.getUrl().toString();
String pageUrl = url.substring(0,url.lastIndexOf("?"));
String pindaoId =url.substring(url.lastIndexOf("=")+1);
Urllist = saveNewsListData(pageUrl,pindaoId);
page.addTargetRequests(Urllist);//添加地址,根据url对该地址处理
}
//可增加else if 处理不同URL地址
} catch (Exception e) {
e.printStackTrace();
}
}
private List<String> saveNewsListData(String pageUrl,String pindaoId) {
List<String> urlList = new ArrayList<String>();
Document docList = null;
String newsIdFirst="";
String pageListStr=HttpClientUtil.getPage(pageUrl);//HttpClientUtil方式获取网页内容
if(StringUtils.isNotEmpty(pageListStr)){
try {
docList = Jsoup.parse(pageListStr);
Elements fallsFlow=docList.getElementsByClass("fallsFlow");
if(!fallsFlow.isEmpty()){
Elements liTag=fallsFlow.get(0).getElementsByTag("li");
if(!liTag.isEmpty()){
for(int i=0;i<liTag.size();i++){
String title="",contentUrl="",newsId="",pic="",absContent="",pushTime="",timeFalg="";
Element obj=liTag.get(i);
try{
contentUrl=obj.getElementsByTag("h3").select("a").attr("href");
if(StringUtils.isNotEmpty(contentUrl)){
title=obj.getElementsByTag("h3").select("a").attr("title");//标题
Rs isTitle = CommService.checkNewsName(title); //校验新闻标题
if(!isTitle.isNull()){
continue;
}
System.err.println("<<<<<<--DAO------当前抓取文章为(xxx历史):"+title+"------------");
newsId = contentUrl.substring(contentUrl.lastIndexOf("/") + 1,contentUrl.lastIndexOf(".html"));
if(!pageUrl.contains(".htm") && i == 0){
newsIdFirst = newsId;
}
//图片
if(!obj.getElementsByTag("img").attr("src").isEmpty()){
pic=obj.getElementsByTag("img").first().attr("src");
if(StringUtils.isNotEmpty(pic) ){
pic = fun.downloadPic(pic,pic_dir+"list/"+newsId+"/");//获取列表图片,保存本地
}
}
if(!obj.getElementsByTag("h5").isEmpty()){
//简介
absContent = obj.getElementsByTag("h5").first().text();
if(StringUtils.isNotEmpty(absContent) && absContent.indexOf("[")>0){
absContent = absContent.substring(0, absContent.indexOf("["));
}
}
if(!obj.getElementsByTag("h6").isEmpty()){
pushTime = obj.getElementsByTag("h6").text();
timeFalg=pushTime.substring(0, 4);
}
String hrmlStr=HttpClientUtil.getPage(contentUrl);
if(StringUtils.isNotEmpty(hrmlStr)){
Document docPage = Jsoup.parse(hrmlStr);
Elements pageContent = docPage.getElementsByClass("conText");
if(!pageContent.isEmpty()){
String comefrom = pageContent.get(0).getElementsByClass("fromSummary").text();//来源
if(StringUtils.isNotEmpty(comefrom) && comefrom.contains("环球")){
String author=pageContent.get(0).getElementsByClass("author").text();//作者
Element contentDom = pageContent.get(0).getElementById("text");
if(!contentDom.getElementsByTag("a").isEmpty()){
contentDom.getElementsByTag("a").removeAttr("href");//移除外跳连接
}
if(!contentDom.getElementsByClass("reTopics").isEmpty()){
contentDom.getElementsByClass("reTopics").remove();//推荐位
}
if(!contentDom.getElementsByClass("spTopic").isEmpty()){
contentDom.getElementsByClass("spTopic").remove(); //去除排行榜列表
}
if(!contentDom.getElementsByClass("editorSign").isEmpty()){
contentDom.getElementsByClass("editorSign").remove();//移除编辑标签
}
String content = contentDom.toString();
if(!StringUtils.isEmpty(content)){
content = content.replaceAll("\r\n|\r|\n|\t|\b|~|\f", "");//去掉回车换行符
content = replaceForNews(content,pic_dir+"article/"+newsId+"/");//替换内容中的图片
while (true) {
if(content.indexOf("<!--") ==-1 && content.indexOf("<script") == -1){
break;
}else{
if(content.indexOf("<!--") >0 && content.lastIndexOf("-->")>0){
String moveContent= content.substring(content.indexOf("<!--"), content.indexOf("-->")+3);//去除注释
content = content.replace(moveContent, "");
}
if(content.indexOf("<script") >0 && content.lastIndexOf("</script>")>0){
String moveContent= content.substring(content.indexOf("<script"), content.indexOf("</script>")+9);//去除JS
content = content.replace(moveContent, "");
}
}
}
}
if(StringUtils.isEmpty(timeFalg) || "2016".equals(timeFalg) ||
"28".equals(pindaoId) || "29".equals(pindaoId) || "30".equals(pindaoId)){
Rs news= new Rs("News");
news.set("title", title);
news.set("shortTitle",title);
news.set("beizhu",absContent);
news.set("savetime", pushTime);
if(StringUtils.isNotEmpty(pic)){
news.set("path", pic);
news.set("mini_image", pic);
}
news.set("pindaoId", pindaoId);
news.set("status", 0);//不显示
news.set("canComment", 1);//是否被评论
news.set("syn", 1);//是否异步
news.set("type", 1);//是否异步
news.set("comefrom",comefrom);
news.set("author", author);
news.set("content", content);
news.set("content2", content);
CommService.save(news);
System.err.println("------新增(xxx历史):"+title+"------>>>>>>>");
}else{
break;
}
}
}
}
}
}catch (Exception e) {
e.printStackTrace();
}
}
}
if(!pageUrl.contains(".htm")){
//得到分页内容
Element pages = docList.getElementById("pages");
int num = pages.getElementsByTag("a").size();
String pageMaxStr = pages.getElementsByTag("a").get(num-2).text();
int pageMax=0;
if(StringUtils.isNotEmpty(pageMaxStr)){
pageMax= Integer.parseInt(pageMaxStr);
}
if(pageMax>historyMaxPage){//控制历史抓取页数
pageMax = historyMaxPage;
}
for(int i=1 ;i<pageMax;i++){//翻页请求
String link = "";
link = pageUrl+(i+1)+".html?pindao="+pindaoId;
urlList.add(link);//循环处理url,翻页内容
}
//获取增量标识
Rs flag = CommService.checkPd(pindaoId,pageUrl,Config.SITE_HQ);
//初始化
if(flag.isNull()){
Rs task= new Rs("TaskInfo");
task.set("pindao_id", pindaoId);
task.set("news_id", newsIdFirst);
task.set("page_url", pageUrl);
task.set("site", Config.SITE_HQ);
task.set("create_time", DateUtil.fullDate());
CommService.save(task);
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
return urlList;
}
public static void main(String[] args) {
List<String> strList=new ArrayList<String>();
strList.add("http://www.xxx/exclusive/?pindao="+Pindao.getKey("国际"));
//滚动新闻
strList.add("http://www.xxx/article/?pindao="+Pindao.getKey("国际"));
for(String str:strList){
Spider.create(new HQNewsDao()).addUrl(str).thread(1).run();
}
}
//所有频道Action
public static void runNewsList(List<String> strList){
for(String str:strList){
Spider.create(new HQNewsDao()).addUrl(str).thread(1).run(); //添加爬取地址、设置线程数
}
}
}
三、增量抓取代码,如下(在历史上改动):
说明:增量每10分钟执行一次,每次只抓取最新一页数据,根据增量标识(上一次第一条新闻news_id),存在相同news_id或一页爬完就终止抓取。
package com.spider.huanqiu.task;
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.lang3.StringUtils;
import org.jdiy.core.Rs;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import com.spider.huasheng.history.Pindao;
import com.spider.utils.Config;
import com.spider.utils.ConfigBase;
import com.spider.utils.DateUtil;
import com.spider.utils.HttpClientUtil;
import com.spider.utils.service.CommService;
public class HQNewsTaskDao extends ConfigBase implements PageProcessor{
public static final String index_list = "(.*).huanqiu.com/(.*)pindao=(.*)";
public static String pic_dir = fun.getProValue(PINDAO_PIC_FILE_PATH);
public static String new_id="";
// 部分一:抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(6000)
.addHeader("Accept-Encoding", "/").setUserAgent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.59 Safari/537.36");
@Override
public Site getSite() {
return site;
}
@Override
public void process(Page page) {
try {
//列表页
if (page.getUrl().regex(index_list).match()) {
List<String> Urllist =new ArrayList<String>();
String url =page.getUrl().toString();
String pageUrl = url.substring(0,url.lastIndexOf("?"));
String pindaoId =url.substring(url.lastIndexOf("=")+1);
Rs isFlag = CommService.checkPd(pindaoId,pageUrl,Config.SITE_HQ);
if(!isFlag.isNull()){
new_id=isFlag.getString("news_id");
}
Urllist = saveNewsListData(pageUrl,pindaoId);
page.addTargetRequests(Urllist);
}
} catch (Exception e) {
e.printStackTrace();
}
}
private List<String> saveNewsListData(String pageUrl,String pindaoId) {
List<String> urlList = new ArrayList<String>();
Document docList = null;
String pageListStr=HttpClientUtil.getPage(pageUrl);
if(StringUtils.isNotEmpty(pageListStr)){
try {
docList = Jsoup.parse(pageListStr);
Elements fallsFlow=docList.getElementsByClass("fallsFlow");
if(!fallsFlow.isEmpty()){
String newsIdFirst="";
Boolean isIng = true;
Elements liTag=fallsFlow.get(0).getElementsByTag("li");
if(!liTag.isEmpty()){
for(int i=0;i<liTag.size() && isIng;i++){
String title="",contentUrl="",newsId="",pic="",absContent="",pushTime="";
Element obj=liTag.get(i);
try{
contentUrl=obj.getElementsByTag("h3").select("a").attr("href");
if(StringUtils.isNotEmpty(contentUrl)){
title=obj.getElementsByTag("h3").select("a").attr("title");//标题
Rs isTitle = CommService.checkNewsName(title); //校验新闻标题
if(!isTitle.isNull()){
continue;
}
System.err.println("---------当前抓取文章为(增量):"+title+"------------");
newsId = contentUrl.substring(contentUrl.lastIndexOf("/") + 1,contentUrl.lastIndexOf(".html"));
if(!newsId.equals(new_id)){
if(!pageUrl.contains(".htm") && i == 0){
newsIdFirst = newsId;
}
//图片
if(!obj.getElementsByTag("img").attr("src").isEmpty()){
pic=obj.getElementsByTag("img").first().attr("src");
if(StringUtils.isNotEmpty(pic) ){
pic = fun.downloadPic(pic,pic_dir+"list/"+newsId+"/");
}
}
if(!obj.getElementsByTag("h5").isEmpty()){
//简介
absContent = obj.getElementsByTag("h5").first().text();
if(StringUtils.isNotEmpty(absContent) && absContent.indexOf("[")>0){
absContent = absContent.substring(0, absContent.indexOf("["));
}
}
if(!obj.getElementsByTag("h6").isEmpty()){
pushTime = obj.getElementsByTag("h6").text();
}
String hrmlStr=HttpClientUtil.getPage(contentUrl);
if(StringUtils.isNotEmpty(hrmlStr)){
Document docPage = Jsoup.parse(hrmlStr);
Elements pageContent = docPage.getElementsByClass("conText");
if(!pageContent.isEmpty()){
String comefrom = pageContent.get(0).getElementsByClass("fromSummary").text();//来源
if(StringUtils.isNotEmpty(comefrom) && comefrom.contains("环球")){
String author=pageContent.get(0).getElementsByClass("author").text();//作者
Element contentDom = pageContent.get(0).getElementById("text");
if(!contentDom.getElementsByTag("a").isEmpty()){
contentDom.getElementsByTag("a").removeAttr("href");//移除外跳连接
}
if(!contentDom.getElementsByClass("reTopics").isEmpty()){
contentDom.getElementsByClass("reTopics").remove();//推荐位
}
if(!contentDom.getElementsByClass("spTopic").isEmpty()){
contentDom.getElementsByClass("spTopic").remove();
}
if(!contentDom.getElementsByClass("editorSign").isEmpty()){
contentDom.getElementsByClass("editorSign").remove();//移除编辑
}
String content = contentDom.toString();
if(!StringUtils.isEmpty(content)){
content = content.replaceAll("\r\n|\r|\n|\t|\b|~|\f", "");//去掉回车换行符
content = replaceForNews(content,pic_dir+"article/"+newsId+"/");//替换内容中的图片
while (true) {
if(content.indexOf("<!--") ==-1 && content.indexOf("<script") == -1){
break;
}else{
if(content.indexOf("<!--") >0 && content.lastIndexOf("-->")>0){
String moveContent= content.substring(content.indexOf("<!--"), content.indexOf("-->")+3);//去除注释
content = content.replace(moveContent, "");
}
if(content.indexOf("<script") >0 && content.lastIndexOf("</script>")>0){
String moveContent= content.substring(content.indexOf("<script"), content.indexOf("</script>")+9);//去除JS
content = content.replace(moveContent, "");
}
}
}
}
if(StringUtils.isNotEmpty(content) && StringUtils.isNotEmpty(title)){
Rs news= new Rs("News");
news.set("title", title);
news.set("shortTitle",title);
news.set("beizhu",absContent);
news.set("savetime", pushTime);
if(StringUtils.isNotEmpty(pic)){
news.set("path", pic);
news.set("mini_image", pic);
}
news.set("pindaoId", pindaoId);
news.set("status", 1);//不显示
news.set("canComment", 1);//是否被评论
news.set("syn", 1);//是否异步
news.set("type", 1);//是否异步
news.set("comefrom",comefrom);
news.set("author", author);
news.set("content", content);
news.set("content2", content);
CommService.save(news);
}
}
}
}
}else{
isIng=false;
break;
}
}
}catch (Exception e) {
e.printStackTrace();
}
}
}
if(!pageUrl.contains(".htm")){
//增量标识
Rs flag = CommService.checkPd(pindaoId,pageUrl,Config.SITE_HQ);
//初始化
if(flag.isNull()){
Rs task= new Rs("TaskInfo");
task.set("pindao_id", pindaoId);
task.set("news_id", newsIdFirst);
task.set("page_url", pageUrl);
task.set("site", Config.SITE_HQ);
task.set("create_time", DateUtil.fullDate());
CommService.save(task);
}else if(StringUtils.isNotEmpty(newsIdFirst)){
flag.set("news_id", newsIdFirst);
flag.set("update_time", DateUtil.fullDate());
CommService.save(flag);
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
return urlList;
}
public static void main(String[] args) {
List<String> strList=new ArrayList<String>();
strList.add("http://www.xxx/exclusive/?pindao="+Pindao.getKey("国际"));
//滚动新闻
strList.add("http://www.xxx/article/?pindao="+Pindao.getKey("国际"));
for(String str:strList){
Spider.create(new HQNewsTaskDao()).addUrl(str).thread(1).run();
}
}
//所有频道Action
public static void runNewsList(List<String> strList){
for(String str:strList){
Spider.create(new HQNewsTaskDao()).addUrl(str).thread(1).run();
}
}
}
四、定时抓取,配置如下:
1、web.xml重配置监听
<!-- 添加:增量数据抓取监听 -->
<listener>
<listener-class>com.spider.utils.AutoRun</listener-class>
</listener>
package com.spider.utils;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
import javax.servlet.ServletContextEvent;
import javax.servlet.ServletContextListener;
import com.spider.huanqiu.timer.HQJob1;
import com.spider.huanqiu.timer.HQJob2;
import com.spider.huanqiu.timer.HQJob3;
import com.spider.huanqiu.timer.HQJob4;
import com.spider.huasheng.timer.HSJob1;
import com.spider.huasheng.timer.HSJob2;
/**
* 描 述:监听增量抓取Job
* 创建时间:2016-11-4
* @author Jibaole
*/
public class AutoRun implements ServletContextListener {
public void contextInitialized(ServletContextEvent event) {
ScheduledExecutorService scheduExec = Executors.newScheduledThreadPool(6);
/*
* 这里开始循环执行 HSJob()方法了
* schedule(param1, param2,param3)这个函数的三个参数的意思分别是:
* param1:你要执行的方法;param2:延迟执行的时间,单位毫秒;param3:循环间隔时间,单位毫秒
*/
scheduExec.scheduleAtFixedRate(new HSJob1(), 1*1000*60,1000*60*10,TimeUnit.MILLISECONDS); //延迟1分钟,设置没10分钟执行一次
scheduExec.scheduleAtFixedRate(new HSJob2(), 3*1000*60,1000*60*10,TimeUnit.MILLISECONDS); //延迟3分钟,设置没10分钟执行一次
scheduExec.scheduleAtFixedRate(new HQJob1(), 5*1000*60,1000*60*10,TimeUnit.MILLISECONDS); //延迟5分钟,设置没10分钟执行一次
scheduExec.scheduleAtFixedRate(new HQJob2(), 7*1000*60,1000*60*10,TimeUnit.MILLISECONDS); //延迟7分钟,设置没10分钟执行一次
scheduExec.scheduleAtFixedRate(new HQJob3(), 9*1000*60,1000*60*14,TimeUnit.MILLISECONDS); //延迟9分钟,设置没10分钟执行一次
scheduExec.scheduleAtFixedRate(new HQJob4(), 11*1000*60,1000*60*10,TimeUnit.MILLISECONDS); //延迟11分钟,设置没10分钟执行一次
}
public void contextDestroyed(ServletContextEvent event) {
System.out.println("=======timer销毁==========");
//timer.cancel();
}
}
3、具体执行业务(举一个例子)
package com.spider.huasheng.timer;
import java.util.ArrayList;
import java.util.List;
import java.util.TimerTask;
import com.spider.huasheng.task.HSTaskDao;
import com.spider.huasheng.task.HSTaskDao1;
import com.spider.huasheng.task.HSTaskDao2;
/**
* 描 述:国际、社会、国内、评论等频道定时任务
* 创建时间:2016-11-9
* @author Jibaole
*/
public class HSJob1 implements Runnable{
@Override
public void run() {
System.out.println("======>>>开始:xxx-任务1====");
try {
runNews();
runNews1();
runNews2();
} catch (Throwable t) {
System.out.println("Error");
}
System.out.println("======xxx-任务1>>>结束!!!====");
}
/**
* 抓取-新闻 频道列表
*/
public void runNews(){
List<String> strList=new ArrayList<String>();
/**##############>>>16、国际<<<##################*/
//国际视野
strList.add("http://xxx/class/2199.html?pindao=国际");
/**##############>>>17、社会<<<##################*/
//社会
strList.add("http://xxx/class/2200.html?pindao=社会");
/**##############>>>18、国内<<<##################*/
//国内动态
strList.add("http://xxx/class/1922.html?pindao=国内");
HQNewsTaskDao.runNewsList(strList);
}
/**
* 抓取-新闻 频道列表
*/
public void runNews1(){
List<String> strList=new ArrayList<String>();
/**##############>>>19、评论<<<##################*/
//华声视点
strList.add("http://xxx/class/709.html?pindao=评论");
//财经观察
strList.add("http://xxx/class/2557.html?pindao=评论");
/**##############>>>20、军事<<<##################*/
//军事
strList.add("http://xxx/class/2201.html?pindao=军事");
HQNewsTaskDao.runNewsList(strList);
}
/**
* 抓取-新闻 频道列表
*/
public void runNews2(){
List<String> strList=new ArrayList<String>();
/**##############>>>24、财经<<<##################*/
//财讯
strList.add("http://xxx/class/2353.html?pindao=财经");
//经济观察
strList.add("http://xxx/class/2348.html?pindao=财经");
/**##############>>>30、人文<<<##################*/
//历史上的今天
strList.add("http://xxx/class/1313.html?pindao=人文");
//正史风云
strList.add("http://xxx/class/1362.html?pindao=人文");
HSTaskDao2.runNewsList(strList);
}
}
五、使用到的工具类
1、HttpClientUtil工具类
package com.spider.utils;
import java.io.BufferedReader;
import java.io.File;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpStatus;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.http.HttpEntity;
import org.apache.http.NameValuePair;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.conn.ssl.DefaultHostnameVerifier;
import org.apache.http.conn.util.PublicSuffixMatcher;
import org.apache.http.conn.util.PublicSuffixMatcherLoader;
import org.apache.http.entity.ContentType;
import org.apache.http.entity.StringEntity;
import org.apache.http.entity.mime.MultipartEntityBuilder;
import org.apache.http.entity.mime.content.FileBody;
import org.apache.http.entity.mime.content.StringBody;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
public class HttpClientUtil {
private final static String charset = "UTF-8";
private RequestConfig requestConfig = RequestConfig.custom().setSocketTimeout(15000)
.setConnectTimeout(15000)
.setConnectionRequestTimeout(15000)
.build();
private static HttpClientUtil instance = null;
private HttpClientUtil(){}
public static HttpClientUtil getInstance(){
if (instance == null) {
instance = new HttpClientUtil();
}
return instance;
}
/**
* 发送 post请求
* @param httpUrl 地址
*/
public String sendHttpPost(String httpUrl) {
HttpPost httpPost = new HttpPost(httpUrl);// 创建httpPost
return sendHttpPost(httpPost);
}
/**
* 发送 post请求
* @param httpUrl 地址
* @param params 参数(格式:key1=value1&key2=value2)
*/
public String sendHttpPost(String httpUrl, String params) {
HttpPost httpPost = new HttpPost(httpUrl);// 创建httpPost
try {
//设置参数
StringEntity stringEntity = new StringEntity(params, "UTF-8");
stringEntity.setContentType("application/x-www-form-urlencoded");
httpPost.setEntity(stringEntity);
} catch (Exception e) {
e.printStackTrace();
}
return sendHttpPost(httpPost);
}
/**
* 发送 post请求
* @param httpUrl 地址
* @param maps 参数
*/
public String sendHttpPost(String httpUrl, Map<String, String> maps) {
HttpPost httpPost = new HttpPost(httpUrl);// 创建httpPost
httpPost.setHeader("Content-Type","application/x-www-form-urlencoded;charset="+charset);
httpPost.setHeader("User-Agent","Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.");
// 创建参数队列
List<NameValuePair> nameValuePairs = new ArrayList<NameValuePair>();
for (String key : maps.keySet()) {
nameValuePairs.add(new BasicNameValuePair(key, maps.get(key)));
}
try {
httpPost.setEntity(new UrlEncodedFormEntity(nameValuePairs, "UTF-8"));
} catch (Exception e) {
e.printStackTrace();
}
return sendHttpPost(httpPost);
}
/**
* 发送 post请求(带文件)
* @param httpUrl 地址
* @param maps 参数
* @param fileLists 附件
*/
public String sendHttpPost(String httpUrl, Map<String, String> maps, List<File> fileLists) {
HttpPost httpPost = new HttpPost(httpUrl);// 创建httpPost
MultipartEntityBuilder meBuilder = MultipartEntityBuilder.create();
for (String key : maps.keySet()) {
meBuilder.addPart(key, new StringBody(maps.get(key), ContentType.TEXT_PLAIN));
}
for(File file : fileLists) {
FileBody fileBody = new FileBody(file);
meBuilder.addPart("files", fileBody);
}
HttpEntity reqEntity = meBuilder.build();
httpPost.setEntity(reqEntity);
return sendHttpPost(httpPost);
}
/**
* 发送Post请求
* @param httpPost
* @return
*/
private String sendHttpPost(HttpPost httpPost) {
CloseableHttpClient httpClient = null;
CloseableHttpResponse response = null;
HttpEntity entity = null;
String responseContent = null;
try {
// 创建默认的httpClient实例.
httpClient = HttpClients.createDefault();
httpPost.setConfig(requestConfig);
// 执行请求
response = httpClient.execute(httpPost);
entity = response.getEntity();
responseContent = EntityUtils.toString(entity, "UTF-8");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
// 关闭连接,释放资源
if (response != null) {
response.close();
}
if (httpClient != null) {
httpClient.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
return responseContent;
}
/**
* 发送 get请求
* @param httpUrl
*/
public String sendHttpGet(String httpUrl) {
HttpGet httpGet = new HttpGet(httpUrl);// 创建get请求
return sendHttpGet(httpGet);
}
/**
* 发送 get请求Https
* @param httpUrl
*/
public String sendHttpsGet(String httpUrl) {
HttpGet httpGet = new HttpGet(httpUrl);// 创建get请求
return sendHttpsGet(httpGet);
}
/**
* 发送Get请求
* @param httpPost
* @return
*/
private String sendHttpGet(HttpGet httpGet) {
CloseableHttpClient httpClient = null;
CloseableHttpResponse response = null;
HttpEntity entity = null;
String responseContent = null;
try {
// 创建默认的httpClient实例.
httpClient = HttpClients.createDefault();
httpGet.setConfig(requestConfig);
// 执行请求
response = httpClient.execute(httpGet);
entity = response.getEntity();
responseContent = EntityUtils.toString(entity, "UTF-8");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
// 关闭连接,释放资源
if (response != null) {
response.close();
}
if (httpClient != null) {
httpClient.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
return responseContent;
}
/**
* 发送Get请求Https
* @param httpPost
* @return
*/
private String sendHttpsGet(HttpGet httpGet) {
CloseableHttpClient httpClient = null;
CloseableHttpResponse response = null;
HttpEntity entity = null;
String responseContent = null;
try {
// 创建默认的httpClient实例.
PublicSuffixMatcher publicSuffixMatcher = PublicSuffixMatcherLoader.load(new URL(httpGet.getURI().toString()));
DefaultHostnameVerifier hostnameVerifier = new DefaultHostnameVerifier(publicSuffixMatcher);
httpClient = HttpClients.custom().setSSLHostnameVerifier(hostnameVerifier).build();
httpGet.setConfig(requestConfig);
// 执行请求
response = httpClient.execute(httpGet);
entity = response.getEntity();
responseContent = EntityUtils.toString(entity, "UTF-8");
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
// 关闭连接,释放资源
if (response != null) {
response.close();
}
if (httpClient != null) {
httpClient.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
return responseContent;
}
/**
* 利用httpClient获取页面
* @param url
* @return
*/
public static String getPage(String url){
String result="";
HttpClient httpClient = new HttpClient();
GetMethod getMethod = new GetMethod(url+"?date=" + new Date().getTime());//加时间戳,防止页面缓存
try {
int statusCode = httpClient.executeMethod(getMethod);
httpClient.setTimeout(5000);
httpClient.setConnectionTimeout(5000);
if (statusCode != HttpStatus.SC_OK) {
System.err.println("Method failed: "+ getMethod.getStatusLine());
}
// 读取内容
//byte[] responseBody = getMethod.getResponseBody();
BufferedReader reader = new BufferedReader(new InputStreamReader(getMethod.getResponseBodyAsStream()));
StringBuffer stringBuffer = new StringBuffer();
String str = "";
while((str = reader.readLine())!=null){
stringBuffer.append(str);
}
// 处理内容
result = stringBuffer.toString();
} catch (Exception e) {
System.err.println("页面无法访问");
}
getMethod.releaseConnection();
return result;
}
}
/**
* 下载图片到本地
* @param picUrl 图片Url
* @param localPath 本地保存图片地址
* @return
*/
public String downloadPic(String picUrl,String localPath){
String filePath = null;
String url = null;
try {
URL httpurl = new URL(picUrl);
String fileName = getFileNameFromUrl(picUrl);
filePath = localPath + fileName;
File f = new File(filePath);
FileUtils.copyURLToFile(httpurl, f);
Function fun = new Function();
url = filePath.replace("/www/web/imgs", fun.getProValue("IMG_PATH"));
} catch (Exception e) {
logger.info(e);
return null;
}
return url;
}1、替换咨询内容图片方法
/**
* 替换内容中图片地址为本地地址
* @param content html内容
* @param pic_dir 本地地址文件路径
* @return html内容
*/
public static String replaceForNews(String content,String pic_dir){
String str = content;
String cont = content;
while (true) {
int i = str.indexOf("src=\"");
if (i != -1) {
str = str.substring(i+5, str.length());
int j = str.indexOf("\"");
String pic_url = str.substring(0, j);
//下载图片到本地并返回图片地址
String pic_path = fun.downloadPicForNews(pic_url,pic_dir);
if(StringUtils.isNotEmpty(pic_url) && StringUtils.isNotEmpty(pic_path)){
cont = cont.replace(pic_url, pic_path);
str = str.substring(j,str.length());
}
} else{
break;
}
}
return cont;
}/**
* 下载图片到本地
* @param picUrl 图片Url
* @param localPath 本地保存图片地址
* @return
*/
public String downloadPicForNews(String picUrl,String localPath){
String filePath = "";
String url = "";
try {
URL httpurl = new URL(picUrl);
HttpURLConnection urlcon = (HttpURLConnection) httpurl.openConnection();
urlcon.setReadTimeout(3000);
urlcon.setConnectTimeout(3000);
int state = urlcon.getResponseCode(); //图片状态
if(state == 200){
String fileName = getFileNameFromUrl(picUrl);
filePath = localPath + fileName;
File f = new File(filePath);
FileUtils.copyURLToFile(httpurl, f);
Function fun = new Function();
url = filePath.replace("/www/web/imgs", fun.getProValue("IMG_PATH"));
}
} catch (Exception e) {
logger.info(e);
return null;
}
return url;
}获取文件名称,根绝时间戳自定义
/**
* 根据url获取文件名
* @param url
* @return 文件名
*/
public static String getFileNameFromUrl(String url){
//获取后缀
String sux = url.substring(url.lastIndexOf("."));
if(sux.length() > 4){
sux = ".jpg";
}
int i = (int)(Math.random()*1000);
//随机时间戳文件名称
String name = new Long(System.currentTimeMillis()).toString()+ i + sux;
return name;
}
五、遇到的坑
1、增量抓取经常遇到这2个异常,如下
抓取超时:Jsoup 获取页面内容,替换为 httpclient获取,Jsoup去解析
页面gzip异常(这个问题特别坑,导致历史、增量抓取数据严重缺失,线上一直有问题)

解决方案:
这个是WebMagic的框架源码有点小Bug,如果没有设置Header,默认页面Accept-Encoding为:gzip
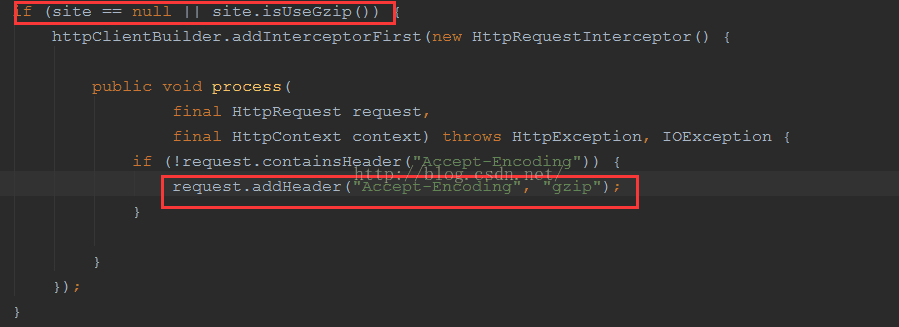
2、定时抓取
由ScheduledExecutorService多线程并行执行任务,替换Timer单线程串行
原方式代码,如下:
package com.spider.utils;
import java.util.Timer;
import javax.servlet.ServletContextEvent;
import javax.servlet.ServletContextListener;
import com.spider.huanqiu.timer.HQJob1;
import com.spider.huanqiu.timer.HQJob2;
import com.spider.huanqiu.timer.HQJob3;
import com.spider.huanqiu.timer.HQJob4;
import com.spider.huasheng.timer.HSJob1;
import com.spider.huasheng.timer.HSJob2;
/**
* 描 述:监听增量抓取Job
* 创建时间:2016-11-4
* @author Jibaole
*/
public class AutoRun implements ServletContextListener {
//HS-job
private Timer hsTimer1 = null;
private Timer hsTimer2 = null;
//HQZX-job
private Timer hqTimer1 = null;
private Timer hqTimer2 = null;
private Timer hqTimer3 = null;
private Timer hqTimer4 = null;
public void contextInitialized(ServletContextEvent event) {
hsTimer1 = new Timer(true);
hsTimer2 = new Timer(true);
hqTimer1 = new Timer(true);
hqTimer2 = new Timer(true);
hqTimer3 = new Timer(true);
hqTimer4 = new Timer(true);
/*
* 这里开始循环执行 HSJob()方法了
* schedule(param1, param2,param3)这个函数的三个参数的意思分别是:
* param1:你要执行的方法;param2:延迟执行的时间,单位毫秒;param3:循环间隔时间,单位毫秒
*/
hsTimer1.scheduleAtFixedRate(new HSJob1(), 1*1000*60,1000*60*10); //延迟1分钟,设置没10分钟执行一次
hsTimer2.scheduleAtFixedRate(new HSJob2(), 3*1000*60,1000*60*10); //延迟3分钟,设置没10分钟执行一次
hqTimer1.scheduleAtFixedRate(new HQJob1(), 5*1000*60,1000*60*10); //延迟5分钟,设置没10分钟执行一次
hqTimer2.scheduleAtFixedRate(new HQJob2(), 7*1000*60,1000*60*10); //延迟7分钟,设置没10分钟执行一次
hqTimer3.scheduleAtFixedRate(new HQJob3(), 9*1000*60,1000*60*10); //延迟9分钟,设置没10分钟执行一次
hqTimer4.scheduleAtFixedRate(new HQJob4(), 11*1000*60,1000*60*10); //延迟11分钟,设置没10分钟执行一次
}
public void contextDestroyed(ServletContextEvent event) {
System.out.println("=======timer销毁==========");
//timer.cancel();
}
}
3、定时多个任务时,使用多线程,遇到某个线程抛异常终止任务
解决方案:在多线程run()方法里面,增加try{}catch{}
4、通过HttpClient定时获取页面内容时,页面缓存,抓不到最新内容
解决方案:在工具类请求URL地址后面增加:url+"?date=" + new Date().getTime()
六、一些方面的处理
1、页面抓取规则调整
先抓列表,在抓内容;改为 抓取列表的同时,需要获取内容详情
2、保存数据方式作调整
先抓取标题等概要信息,保存数据库,然后,更新内容信息,根据业务需求再删除一些非来源文章(版权问题);改为:直接控制来源,得到完整数据,再做批量保存;
3、页面有一个不想要的内容,处理方法
注释、JS代码、移除无用标签块
想了解更多,加微信公众号(jblPaul)
















 1521
1521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









