







💓 博客主页:借口的CSDN主页
⏩ 文章专栏:《热点资讯》
计算机编程中迭代器模式在简化代码与提升性能方面的应用与实践
在软件开发过程中,我们经常需要遍历集合中的元素来进行各种操作。传统的循环结构虽然能够满足基本需求,但在面对复杂数据结构或大规模数据集时,往往显得力不从心。迭代器模式(Iterator Pattern)作为一种通用的设计模式,不仅提供了更加优雅的解决方案,还带来了诸多性能上的优势。本文将深入探讨迭代器模式的核心概念及其应用场景。
迭代器模式是指提供一种方法顺序访问一个聚合对象中的各个元素,而又不需要暴露其内部表示。它将遍历逻辑封装在一个独立的对象中,使得客户端代码可以专注于业务处理。
早在面向对象编程语言兴起之初,迭代器就已经作为标准库的一部分出现在许多系统中。例如,STL(Standard Template Library)为C++引入了丰富的容器类和迭代器接口。
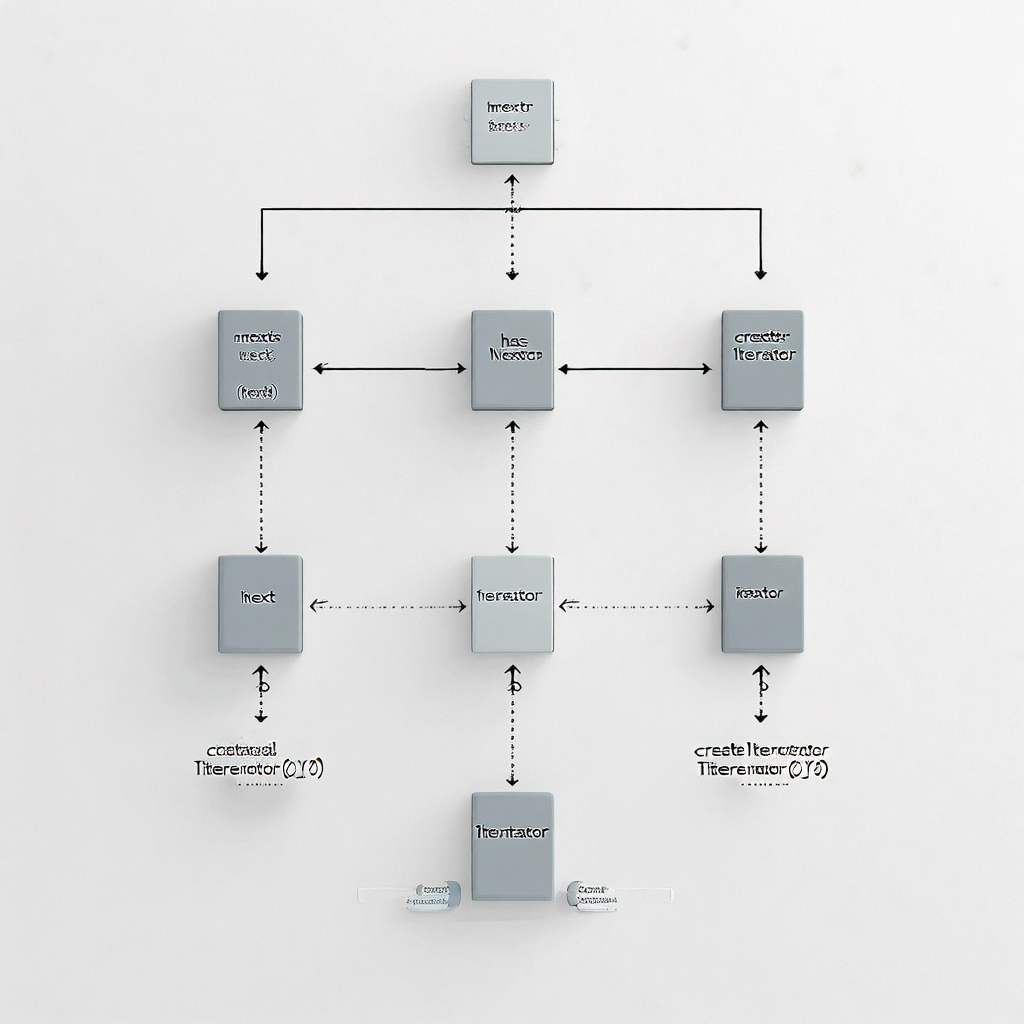
迭代器模式通过定义统一的操作接口,隐藏了不同集合类型之间的差异。这有助于提高代码复用性和可维护性。
# Python代码示例:自定义迭代器实现
from abc import ABC, abstractmethod
class Iterator(ABC):
@abstractmethod
def has_next(self) -> bool:
pass
@abstractmethod
def next(self) -> object:
pass
class MyList:
def __init__(self, items):
self._items = items
self._position = 0
def create_iterator(self):
return ListIterator(self)
class ListIterator(Iterator):
def __init__(self, my_list):
self._my_list = my_list
def has_next(self):
return self._my_list._position < len(self._my_list._items)
def next(self):
if not self.has_next():
raise StopIteration()
item = self._my_list._items[self._my_list._position]
self._my_list._position += 1
return item
my_list = MyList([1, 2, 3])
iterator = my_list.create_iterator()
while iterator.has_next():
print(iterator.next())
上述Python代码片段展示了如何创建一个简单的迭代器类ListIterator来遍历自定义列表MyList。
迭代器模式有效地分离了数据存储和访问机制,降低了模块间的依赖关系。这对于大型项目的架构设计尤为重要。
借助组合、继承等手段,可以轻松地为现有迭代器添加新功能,如过滤、映射等。
// Java代码示例:使用Stream API进行流式处理
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class StreamExample {
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> evenNumbers = numbers.stream()
.filter(n -> n % 2 == 0)
.collect(Collectors.toList());
System.out.println(evenNumbers);
}
}
这段Java代码说明了如何利用内置的Stream API对整数列表进行筛选操作,只保留偶数值。
对于类似的任务,可以直接复用现有的迭代器实例,避免编写冗余代码。
清晰的迭代逻辑使得程序更容易理解和调试。特别是当涉及到嵌套循环或条件分支时,这一点尤为明显。
许多现代编程语言都支持领域特定语言(Domain-Specific Language, DSL),它们允许用户以更加自然的方式表达业务规则。而迭代器正是构建DSL不可或缺的一部分。
# Ruby代码示例:Rails路由配置作为DSL
Rails.application.routes.draw do
get 'home/index'
root 'home#index'
end
上述Ruby代码片段展示了如何使用Rails框架提供的DSL语法简洁地定义URL映射规则。
惰性求值是指直到真正需要结果时才开始计算。这种方式可以节省不必要的资源消耗,并且适用于无限序列等特殊场景。
// C++代码示例:懒加载实现
#include <iostream>
#include <vector>
using namespace std;
vector<int> generate_numbers(int start, int end) {
vector<int> result;
for (int i = start; i <= end; ++i) {
result.push_back(i);
}
return result;
}
void print_odd_numbers(int start, int end) {
auto numbers = generate_numbers(start, end); // Eager evaluation
for (auto num : numbers) {
if (num % 2 != 0) {
cout << num << endl;
}
}
}
void print_odd_numbers_lazy(int start, int end) {
for (int i = start; i <= end; ++i) { // Lazy evaluation
if (i % 2 != 0) {
cout << i << endl;
}
}
}
int main() {
print_odd_numbers(1, 10);
print_odd_numbers_lazy(1, 10);
return 0;
}
上述C++代码片段对比了两种不同的奇数打印方式,其中print_odd_numbers_lazy采用了惰性求值策略。
相比于一次性加载所有数据到内存中,迭代器可以根据需要逐步获取信息。这不仅减少了初始开销,也提高了系统的响应速度。
某些迭代器实现了并行化的遍历算法,可以在多核处理器上获得更好的加速效果。
# Python代码示例:使用concurrent.futures模块进行并发执行
from concurrent.futures import ThreadPoolExecutor
import math
def is_prime(n):
if n < 2:
return False
for i in range(2, int(math.sqrt(n)) + 1):
if n % i == 0:
return False
return True
def find_primes(limit):
with ThreadPoolExecutor(max_workers=4) as executor:
futures = [executor.submit(is_prime, i) for i in range(limit)]
primes = [future.result() for future in futures if future.result()]
return primes
primes = find_primes(100)
print(primes)
这段Python代码展示了如何结合ThreadPoolExecutor实现素数查找任务的并发处理。
STL是C++中最著名的容器和算法库之一,它内置了大量的迭代器类型,如前向迭代器(Forward Iterator)、双向迭代器(Bidirectional Iterator)等。这些工具极大地简化了程序员的工作量。
Python标准库提供了诸如map()、filter()、reduce()等一系列高阶函数,它们都是基于迭代器模式构建的。此外,生成器(Generator)也是实现惰性求值的重要手段。
过度使用迭代器可能会导致程序变得难以理解和维护。为此,应当遵循适度原则,仅在必要时引入相关技术。
尽管迭代器模式具有很多优点,但在某些情况下仍然存在性能问题。可以通过提前优化热点路径、减少不必要的迭代次数等方式加以改善。
对于初学者来说,掌握多种迭代器知识需要花费较多时间和精力。建议从简单例子入手,逐步积累经验。
综上所述,迭代器模式作为一种经典的设计模式,在简化代码结构、提升运行效率等方面展现出了独特魅力。未来,随着更多创新性技术和工具的出现,相信会有更多高效的应用场景涌现出来。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









