







觉得有帮助麻烦点赞关注收藏~~~
一、OCR文字识别的概念
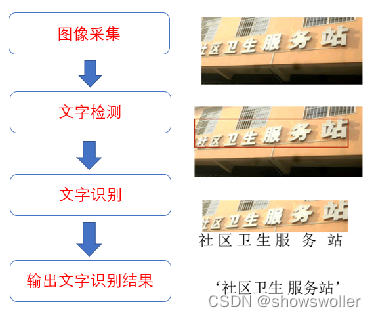
OCR(Optical Character Recognition)图像文字识别是人工智能的重要分支,赋予计算机人眼的功能,可以看图识字。如图6-1所示,图像文字识别系统流程一般分为图像采集、文字检测、文字识别及结果输出四个部分。 识别流程图如下
二、文字检测
传统的问题检测算法
输入一张文字图像,传统的文字检测算法将文字检测出来,要有图像预处理和文字行提取两个阶段,其中图像预处理包括几何校正、模糊校正、二值化等,文字行提取是基于版面分析获取文字行区域
预处理之后即可进行文字识别,文字行识别主要有基于切分的文字识别和不依赖切分的文字识别这两种方法,基于切分的文字识别方法需要先将文字行切分成单字,然后提取文字的方向梯度直方图或者通过卷积神经网络得到的特征信息,最后将提取的特征送入AdaBoost、SVM等分类器中进行识别,而不依赖于切分的文字识别方法能够对文本行直接进行识别,无须切分处理,主要包括基于滑窗的文字识别方法和基于序列的文字识别方法
基于深度学习的文字检测算法
基于深度学习的文本检测,通常遵循前面介绍的经典算法R-CNN网络框架,首先提取可能包含有文本的候选区域,之后利用卷积神经网络将其分类为文本或者非文本区域,并通过回归的方式校正文本区域的坐标位置信息。下面介绍CTPN CRAFT是目前最流行的两种文本检测算法,下面将着重介绍CTPN和CRAFT两种文本检测算法
1:基于CTPN的文本检测算法
CTPN算法是在目标检测算法Fasetr R-CNN模型上改进的算法,CTPN网络结果本质上是全卷积神经网络,通过在卷积特征图上以固定步长的滑动窗孔检测文本行,输出细粒度文本候选框序列。文本检测的难点在于文本的长度是不固定的,可以是很长的文本,也可以是很短的文本。CTPN针对文字检测的特点,提出了关键性的创新,即提出了垂直锚点机制,具体的做法是只预测文本的竖直方向上的位置,水平方向的位置不预测,与Faster R-CNN中的锚点类似,但是不同的是,垂直锚点的宽度是固定的16像素,而高度则从11像素到273像素变化,检测得到细粒度的文字检测结果,采用RNN循环网络将检测的小尺度文本进行连接,得到需要的文本框
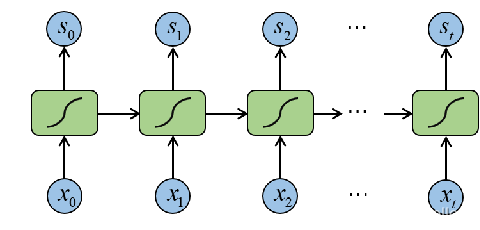
CTPN结构如下图所示,在后面加入了LSTM层,首先将原图片输入VGG-16卷积神经网络的前五个卷积层,在第五层卷积层进行了卷积操作后,特征图输入到双向LSTM中,之后将双向LSTM层连接到512维的全连接层,再将全连接层特征输入到三个分类器中来预测候选框的文本或非文本分数、坐标信息以及文本框边缘调整补偿值,最后通过文本线将多个候选框构造成一个文本框


2:基于CRAFT算法的文本检测算法
CRAFT算法实现文本行的检测如下图所示,首先将完整的文字区域输入CRAFT文字检测网络,得到字符级的文字得分结果热图和字符级文本连接得分热图,最后根据连通域得到每个文本行的位置

CRAFT算法通过探索每个字符和字符之间的亲和力来有效的检测文本区域,通过学习中间模型估计真实图像的字符集标签,并利用了合成图像的给定字符集注释,克服了缺乏单个字符级注释的缺点,为了估计字符之间的亲和力,使用关联性表示来训练网络,,CRAFT模型在解码部分用了类似图像分割U-Net算法的结构,最终的输出有两个通道:文字区域分数和连接分数
网络输入文字区域分数和连接之后,下面就要把字符区域合成文本行,首先通过阈值过滤文字区域分数,进行二值化,然后通过连通域分析算法,得到最终的文本行
创作不易 觉得有帮助请点赞关注收藏~~~















 6374
6374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











