







觉得有帮助麻烦点赞关注收藏~~~
基于深度学习的视频分析算法是依赖于数据训练的,数据是深度学习的主要原料,对于算法性能的提升是非常重要的。本章将重点介绍数据的获取、标注、增强及处理方法。
一、数据获取
训练数据的来源主要包括网上公开数据库和自采数据库两种
网上公开数据库的优点在于数据类型全、标注比较规范,而缺点在于与实际的需求场景差距较大
自采数据库是根据项目需求自行采集的数据,根据需求完成数据标注。自采数据库的缺点是场景较为单一,移植性差等。
一般会采用公开数据库和自采数据库结合的方式完成数据训练
二、数据标注
下面主要介绍目标检测和图像分割的数据标注方法 以下两种软件都是开源软件,可以直接下载获取
1:目标检测与识别标注软件LabelImg
对于标注图像中目标需要借助标注软件LabelImg,该软件是一个专门为创建自己的数据集而研发的可视化图像标注软件,它由Python语言创建的,并调用QT制作图形界面,最后给出的标注信息与PASCAL VOC格式一致,最终保存成XML文件

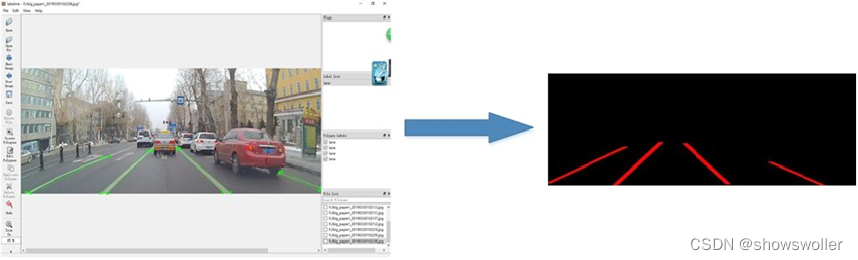
2:图像分割软件LabelMe
图像分割样本的标注一般采用LabelMe软件,对于图像中车道线的标注采用LabelMe软件,与LaeblImg相比,它可以采用多个点来描述标注对象的外形,这在弯道中的车道线标注是很重要的功能,LabelMe的保存格式为json格式,训练时需要把它转化为图像标注格式(PNG格式的图片标签)
三、数据增强
训练数据数量的增加可以大大提高模型的泛化能力,所以在训练之前一般要进行数据增加,视觉模型的数据增强策略通常是针对特定的数据集或者特定的机器学习网络架构,例如进行模型训练时通常使用随机变换,变换的主要方式包括:传统的图像领域的数据增强技术是以仿射变化为基础的,例如旋转、缩放、平移等等,以及一些简单的图像处理手段,这些变换的前提是不改变图像的类别属性,并且只能局限在图像域,这种基于几何变换和图像操作的数据增强方法可以在一定程度上缓解神经网络过拟合的问题,提高泛化能力,但是与增加原始数据相比,增加的数据并没有从根本上解决数据不足的难题,同时这种数据增强方式需要人为设定转换函数和对应的参数,一般都是凭借经验知识,最优数据增强难以实现,所以模型的泛化性能提升有限,然而数据增强的另一种方法,图像合成可以使生成的图像更加真实,多样并满足输入条件,从真正意义上扩充了数据域,提升训练模型的鲁棒性
最近深度卷积神经网络的发展催生了很多深度图像合成模型,如变分自编码器,生成对抗网络,自回归模型等等,这些基于合成的方法相比传统的数据增强方法虽然过程更加复杂,通常都需要训练和学习,但是合成的样本更加多样和复杂,从真正意义上扩充了数据域
创作不易 觉得有帮助请点赞关注收藏~~~















 2883
2883











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











