







一、Hive简介
Hive起源于Facebook,Facebook公司有着大量的日志数据,而Hadoop是实现了MapReduce模式开源的分布式并行计算的框架,可轻松处理大规模数据。然而MapReduce程序对熟悉Java语言的工程师来说容易开发,但对于其他语言使用者则难度较大。因此Facebook开发团队想设计一种使用SQL语言对日志数据查询分析的工具,而Hive就诞生于此,只要懂SQL语言,就能够胜任大数据分析方面的工作,还节省了开发人员的学习成本。
Hive是建立在Hadoop文件系统上的数据仓库,它提供了一系列工具,能够对存储在HDFS中的数据进行数据提取、转换和加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的工具。Hive定义简单的类SQL查询语言(即HQL),可以将结构化的数据文件映射为一张数据表,允许熟悉SQL的用户查询数据,允许熟悉MapReduce的开发者开发mapper和reducer来处理复杂的分析工作,与MapReduce相比较,Hive更具有优势。
Hive采用了SQL的查询语言HQL,因此很容易将Hive理解为数据库。其实从结构上来看,Hive和数据库除了拥有类似的查询语言,再无类似之处,MySQL与Hive对比如下所示。
| 对比项 | Hive | MySQL |
| 查询语言 | Hive QL | SQL |
| 数据存储位置 | HDFS | 块设备、本地文件系统 |
| 数据格式 | 用户定义 | 系统决定 |
| 数据更新 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 执行延迟 | 高 | 低 |
| 可扩展性 | 高 | 低 |
| 数据规模 | 大 | 小 |
二、Hive架构
包括以下几个部分
1:用户结构:主要包括CLI、JDBC/ODBC客户端和Web接口,其中CLI为Shell命令行,JDBC/ODBC是Hive的Java接口实现,与传统数据库JDBC类似,Web接口通过浏览器访问Hive
2:元数据库:Hive将元数据存储在数据库中(MYSQL或者Derby)Hive中的元数据包括表的名字,表的列和分区及其属性,表的数据所在目录等等
3:Thrift服务器:允许客户端使用包括Java或其他很多种语言,通过编程的方式远程Hive
4:解释器,编译器,优化器,执行器:完成HQL查询语言语句从词法分析,语法分析,编译,优化以及查询计划的生成,生成的查询计划存储在HDFS中,并在随后调用执行MapReduce
三、Hive的优缺点
1:Hive的优点
适合大数据的批量处理,解决了传统关系数据库在大数据处理上的瓶颈
Hive构建在Hadoop之上,充分利用了集群的存储资源,计算资源,最终实现并行计算
Hive学习使用成本低,Hive支持标准的SQL语法,免去了编写MapReduce的过程,减少了开发成本
具有良好的扩展性,且能够实现和其他组件的结合使用
2:Hive的缺点
HQL表达能力依然有限,由于本身SQL的不足,不支持迭代计算,有些复杂的运算用HQL不易表达,还需要单独编写MapReduce来实现
Hive的运行效率低,延迟高,Hive是转换成MapReduce任务来进行数据分析,MapReduce是离线计算,所以Hive的运行效率也很低,而且是高延迟
Hive调优比较困难,由于Hive是构建在Hadoop之上的,Hive的调优还要考虑MapReduce层面,因此Hive的整体调优比较困难
四、Hive数据模型
Hive中所有的数据都存储在HDFS中,它包含数据库(Database)、表(Table)、分区表(Partition)和桶表(Bucket)四种数据类型。
Hive的内置数据类型可以分为两大类,分别是基础数据类型和复杂数据类型,Hive基础数据类型如下所示。
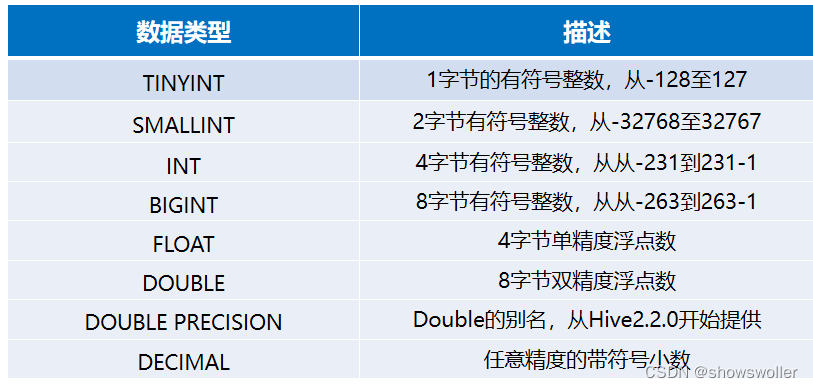

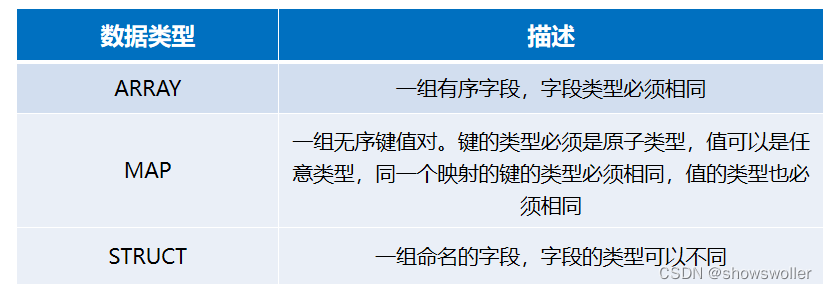
Hive复杂数据类型,具体如下所示。
创作不易 觉得有帮助请点赞关注收藏~~~
















 3980
3980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











