







需要原卷和答案可以点赞关注收藏评论区留言私信
对题目解法有疑问也可留言
下面以具体考试题目来讲解编译原理考试中的重点题目,大致可以分为以下几道大题
1:正则表达式转换为NFA,NFA转换为DFA,DFA最小化
2:LR(0)分析,构造LR(0)自动机,进一步对SLR(1)进行分析,由于LR(1)状态数太多过于复杂,考试中一般不会手动构造
3:语义分析中注释语法树的构造与对节点求值
4:中间代码生成中的生成三地址码等等
下面着重讲解正则表达式转换为NFA,NFA转换为DFA,DFA最小化这三个过程,考试中通常作为一道大题的三个小问呈现,必须掌握
下面是一些基本概念的编译器结构的填空题
- Fill in the blanks
a. Normally, A complier consists of a number of phases. They are Scanner, _________________, ______________________, ______________________, Code Generator, and ___________________.
b. The logical units the scanner generates are called Tokens. For a modern programming language, there are five types of token. They are ________________, _______________, __________________, ____________________, ________________.
答案
a. __Grammar_Parser_, ____Sematic Analyzer___, __Source Code Optimizer_, _Target Code Optimizer _.
b.__Reserved Words____, ___Identifier______, ___Number____, ____Operator___, __Special Symbol__
c.
a) “int” is a ___ Reserved Word b) “printf” is a ___Reserved Word c) “s” is a (an) _ Identifier __
d) “= =” is a _____ Operator_____ e) “0” is a______ Number_ ____
d. Terminal symbol Non-Terminal symbol, start symbol ,and ___Product Rules
-
- Compiler —— 一种应用程序,将源代码转换为指定的目标代码。
- Source code —— 文本文件,其中内容是按照指定的文法规则描述特定的算法,
- Scanner —— 将文本字符串按照词法规则,转换为特定的内部标识,供编译器后续分析。
- Tokens ——源文件中最基本的信息单元
- Terminal symbol ——文法规则中不需要产生式定义的符号
Ambiguous Grammar —使用不同推导方法,推导出不同语法树,就称该文法为二义文法
一、正则表达式转换为NFA
Construct minimum-state DFA for the following regular expression: a(b|ab)*, which includes:
Convert the regular express into NFA first
Convert the NFA into DFA
Minimize the state of DFA
让我们看看正则表达式是如何转换为NFA的,主要是对三个规则的应用,对正则表达式中连接,并,闭包三个运算的具体展开
答案如下

二、NFA转换为DFA
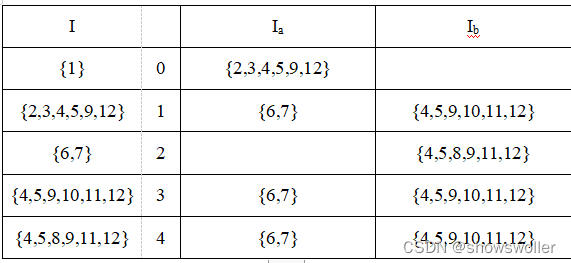
接下来把NFA转换为DFA,一般用到的是子集构造法,这里博主用自己的话通俗易懂的描述以下
有一个表 表的列为输入符号和I
第一列第一行I填入从开始状态出发经过任意个空集能到达的状态 Ia Ib填从I中状态出发经过一个a或者一个b所能到达的状态,经过一个a或者一个b后后面可以跟任意个空集(注意空集必须出现在a或b的后面)
然后把第一行的Ia Ib填入第二行的I中,重复上面的规则,直至没有新状态加入I中,然后给I中状态重新编号即可
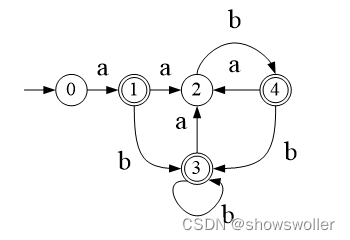
新状态构造后的DFA如下
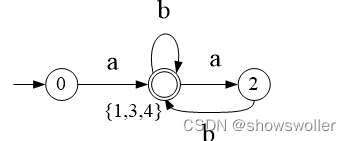
三、DFA最小化
DFA最小化一般就是进行状态的划分,把不可区分的状态分为一类
状态间可区分定义:两个状态输入同一个输入符号时,一个进入非接受状态,另一个进入接受状态则说这个输入符号区分这两个状态
一开始将状态划分为接受状态和非接受状态两类,然后反复运用上面规则直至不能划分即可
上述DFA最小化如下
创作不易 觉得有帮助请点赞关注收藏~~~
















 4021
4021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











