






本文参考coursera的machine learning课程的内容,在此向Andrew Ng致敬
聚类
K-均值是最普及的聚类算法,算法接受一个未标注的数据集,然后将数据聚成不同的组
K-均值是一个迭代算法,假设我们想要将数据聚类成n个组,方位为:
- 首先选择K个随机的点,称为聚类中心(cluster centroids)
- 对于数据集中的任何数据,按照距离K个中心点的距离,将其与距离最近的中心点关联起来,与同一个中心点关联的所有点聚成一类
- 计算每一个组的平均值,将该组的聚类中心移动到平均值的位置
- 重复2-4,直至中心点不再变化
我们用 u1,u2,u3......uk 表示聚类中心,用 c(1),c(2),c(3)......c(m) 来储存与第i个实例数据所对应的聚类中心,故算法伪代码如下:
Repeat{
for i=1 to m
c_(i):=index(1 to K) of cluster centroid closest to x_(i)
for k=1 to k
u_(k):=average(mean) of points assigned to cluster k有的时候,可能会发现有的分类中没有得到任何点包含在其中,这种情况下有2中做法
1.丢弃掉这个分类,那么就得到了K-1个分类,这是比较常用的做法
2.重新初始化一个centroid 作为新的分类替换掉空的分类,重新得到K-1个分类,然后继续计算
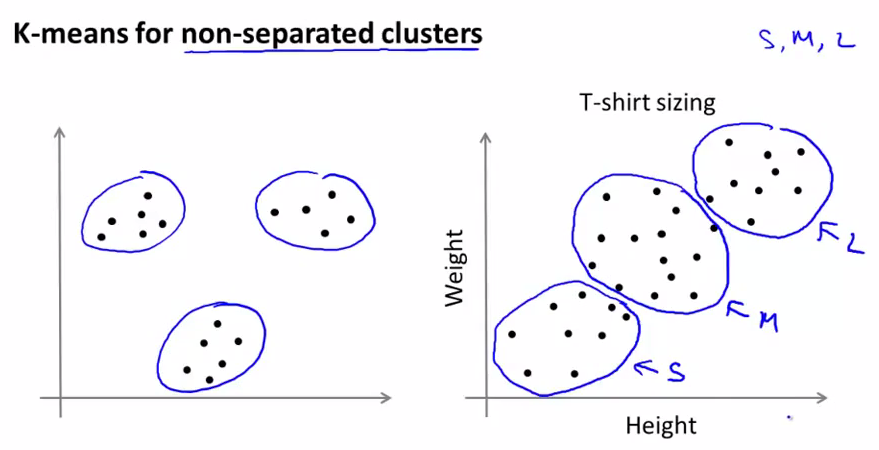
即使是针对区分性不是很好的数据,如下,K-means也可以得到很好的分类结果。
优化目标
K-均值最小化问题,是要最小化所有的数据点和与其关联的中心点之间的距离之和,因此K-均值的代价函数(又称畸变函数)为:
J(c1,.....,cm,u1,......uk)=1m∑mi=1||x(i)−uc(i)||2
其中
uc(i)
代表与
x(i)
最近的聚类中心点。
我们的优化目标是找出使得代价函数最小的所有c和u:

现在我们看一下K-means算法,可以发现cluster assignment部分在不改变中心点的情况下通过改变分类,来优化了总体的距离平方和。
而move centroid部分通过不改变分类的情况下,改变中心点来优化了总体距离平方和。
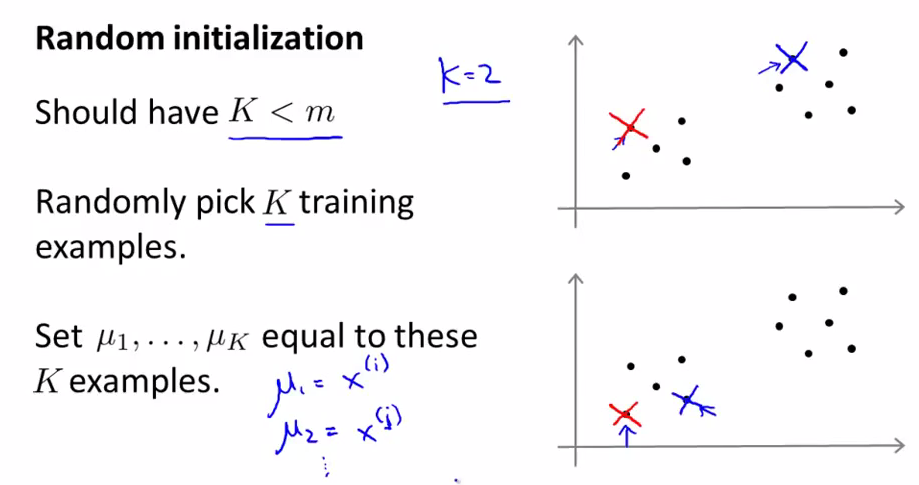
随机初始化
在运行K-均值算法前,我们首先随机初始化所有的聚类中心点,下面介绍怎么做:
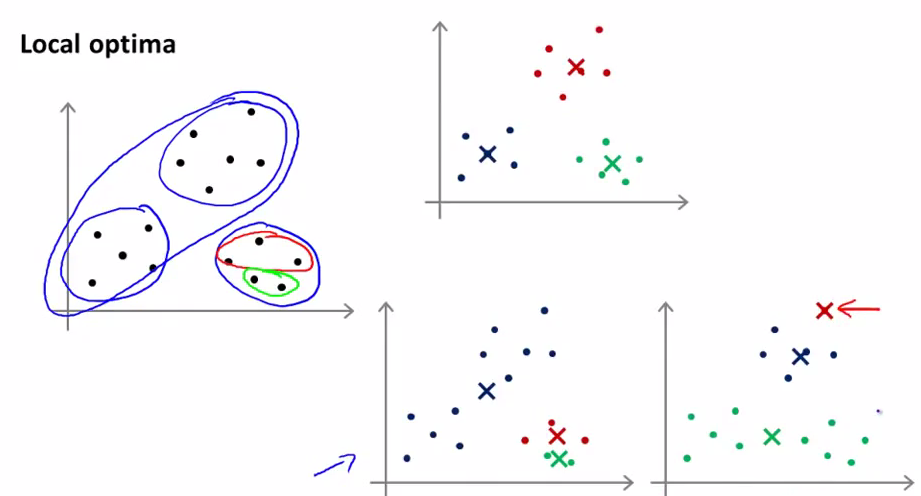
K-均值的一个问题是,他有可能会停留在一个局部最小值处,而这取决于初始化的情况。如图就是三种不同的聚类结果。
对于局部最优的问题,当分类个数不是很多的时候,可以进行多次K-means算法来找到其中最小的cost function,但是当K比较大的时候,可能第一次的结果就会是一个不错的分类,后面的多次重复计算可能只能提供一点点优化。下面对于K取值2-10的分类来说,执行50-1000次K-means算法来找到最优分类是比较合理的选择。

选择聚类数
没有所谓最好的选择聚类数的方法,通常是根据不同的问题,人工进行选择。选择的时候思考我们运用K-均值聚类的动机是什么,然后选择最好的服务于该目标的聚类数。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









