







 本文深入解析哨兵思想在编程中的应用,特别是在数组和列表中如何简化边界条件处理,提升代码效率和健壮性。
本文深入解析哨兵思想在编程中的应用,特别是在数组和列表中如何简化边界条件处理,提升代码效率和健壮性。
读懂本文需要了解的知识点
cortex-m中常见的寄存器
R14(LR)
R14,LR,链接寄存器;主要作用就是保存子程序的返回地址,以便在执行完子程序时恢复现场;如果子程序多于1级,则需要把前一级的R14压入堆栈;
简单来说就是在cortex-m中,函数的返回是通过lr寄存器返回的
R15(PC)
R15为程序计数器(即PC),可以在程序里直接插入PC以跳转到相应的地址(不过不更新LR),如果修改它,就能改变程序的执行流。一般来说pc指向哪,程序就执行到哪。
LiteOS的哨兵思想
在rtos中,一般来说任务函数是不允许退出的,否则任务将通过lr寄存器返回。但在LiteOS中,系统在任务初始化时将任务的上下文初始化情况如下:r0寄存器被设置为任务的taskid ,pc寄存器被设置为osTaskEntry(),lr寄存器被设置为osTaskExit()。
VOID *osTskStackInit(UINT32 uwTaskID, UINT32 uwStackSize, VOID *pTopStack)
{
·····
pstContext->uwR4 = 0x04040404L;
pstContext->uwR5 = 0x05050505L;
pstContext->uwR6 = 0x06060606L;
pstContext->uwR7 = 0x07070707L;
pstContext->uwR8 = 0x08080808L;
pstContext->uwR9 = 0x09090909L;
pstContext->uwR10 = 0x10101010L;
pstContext->uwR11 = 0x11111111L;
pstContext->uwPriMask = 0;
pstContext->uwR0 = uwTaskID;
pstContext->uwR1 = 0x01010101L;
pstContext->uwR2 = 0x02020202L;
pstContext->uwR3 = 0x03030303L;
pstContext->uwR12 = 0x12121212L;
pstContext->uwLR = (UINT32)osTaskExit;
pstContext->uwPC = (UINT32)osTaskEntry;
pstContext->uwxPSR = 0x01000000L;
return (VOID *)pstContext;
}
在osTaskEntry()函数中会调用用户的任务函数主体 (VOID)pstTaskCB->pfnTaskEntry(pstTaskCB->uwArg),并在返回(退出)后调用LOS_TaskDelete()删除自己,所以尽管lr寄存器被设置成了osTaskExit(),但实际上并不会真正返回到这个函数中,这就大大提高了代码的健壮性。当然这些操作对用户来说是不可见的,大家可以将osTaskEntr()函数理解为是哨兵,在用户函数退出的时候,哨兵发现了,就把自己删除掉而不是通过lr返回到osTaskExit()中。
LITE_OS_SEC_TEXT_INIT VOID osTaskEntry(UINT32 uwTaskID)
{
//这里可以看做是哨兵函数
LOS_TASK_CB *pstTaskCB;
OS_TASK_ID_CHECK(uwTaskID);
pstTaskCB = OS_TCB_FROM_TID(uwTaskID);
/* 在这里进入用户的任务主体中,一般不会返回退出 */
(VOID)pstTaskCB->pfnTaskEntry(pstTaskCB->uwArg);
g_usLosTaskLock = 0;
/* 如果用户任务退出了,那么就在这里退出就把自己删除(哨兵发现了用户任务退出) */
(VOID)LOS_TaskDelete(pstTaskCB->uwTaskID);
}
因为通过lr返回的函数,是不安全的,当然也可以在这个函数中将任务显式删除,RT-Thread就是这样子处理的,但哨兵函数的处理思想显然更高明。
LITE_OS_SEC_TEXT_MINOR VOID osTaskExit(VOID)
{
__disable_irq();
while(1);
}
不知道大家有没有看过《哪吒之魔童降世》,哨兵就有点像这两个结界兽,哪吒在里面怎么捣鼓无所谓,只要不越出结界就没有问题。

哨兵编程思想的引伸
虽然无论是通过lr退出后将任务显式删除,还是通过哨兵思想的处理,其最终的结果都是一样的,都是为了代码的健壮性。而这不是本文讨论的重点,我们要学会将哨兵思想运用在其他地方以完成需要的工作。
哨兵思想在数组中的应用
简单来说,在使用数组的时候,我们肯定要对数组限制对吧,不然数组下标越界就产生很大的问题,严重时导致系统崩溃。
那么举个《大话数据结构》的例子吧:
顺序查找一个数组,n为数组的长度,key为要查找的值(关键字)。
方法1
int Sequential_Search(int *a,int n,int key)
{
//数组从0开始
int i;
for(i=0;i<=n;i++)
{
if(a[i]==key)
return i;
}
return -1; //返回-1就是查找失败
}
方法2
int Sequential_Search2(int *a int n,int key)
{
int i=0;
a[0]=key; //哨兵
i=n;
while(a[i]!=key)
{
i--;
}
return i; //返回0就是查找失败
}
在方法1中每次循环都需要对i进行是否越界的判断,而方法2查找方向的尽头设置哨兵元素,避免了查找过程中每次比较后都要判断查找位置是否越界的小技巧,看似与原先差别不大,但是总数据较多时,效率提高很明显,是非常好的编程技巧。当然,“哨兵”也不一定在数组开始,也可以在数组的末端甚至是任何位置。
哨兵思想在列表中的应用
双向链表 L,为了简化对边界条件的判断与维护,可以单独地生成一个结构对象与其他链表结点一致的结点L.sentinel,L.sentinel 作为该链表的哨兵变量。
L.sentinel.next指向表头;L.sentinel.prev指向表尾;
当双向链表中不含哨兵L.sentinel时(需要维护一个L.head),插入链表(头部)的代码如下:
void list_insert(L, x)
{
x.next = L.head;
if(L.head != NULL)
{
L.head.prev = x;
}
L.head = x;
x.prev = NULL;
}
正因为next域指向表头,在对链表处理的过程中可以省去头指针,直接用对哨兵的引用来代替对头指针的引用。
使用哨兵之后便可以省去条件判断语句:
void list_insert(L, x)
{
x.next = L.sentinel.next;
L.sentinel.next.prev = x;
L.sentinel.next = x;
x.prev = L.sentinel;
}
实际应用的情况
就拿图像处理来说吧,比如扫描一幅图像(假设是用二维数组存放),或者对图像帧进行滤波。一般来说查找某个点的特性,都会扫描该点的周围区域。
例如我要将图中的黑点过滤掉,那么我会对黑点周围的区域进行比较,会涉及到黑点的上下左右的数组(假设这图像是二维数组)。
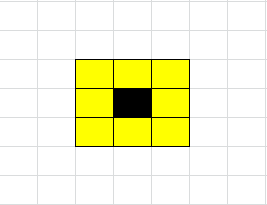
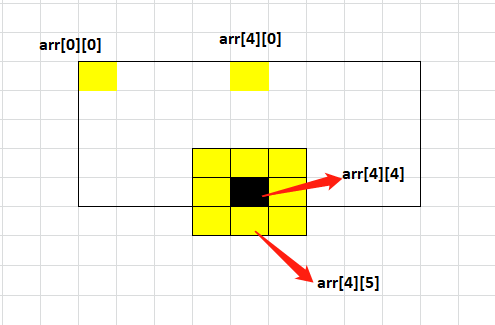
那么假如黑点在边界呢?我们假设直接对这黑点周围的数组操作,必然产生越界,假如整个数组最大就是arr[8][4],那么黑点的下方区域就是arr[4][5]了,直接操作就是越界了,因此这是不可取的,那么在程序中我们可能就是在边界进行判断,这样一来边界与非边界的处理就是不一样的代码了,对于写代码的人和读代码的人也是不友好。那么怎么办呢?我们可以使用哨兵思想,简化边界条件的处理条件。
简化边界的处理:
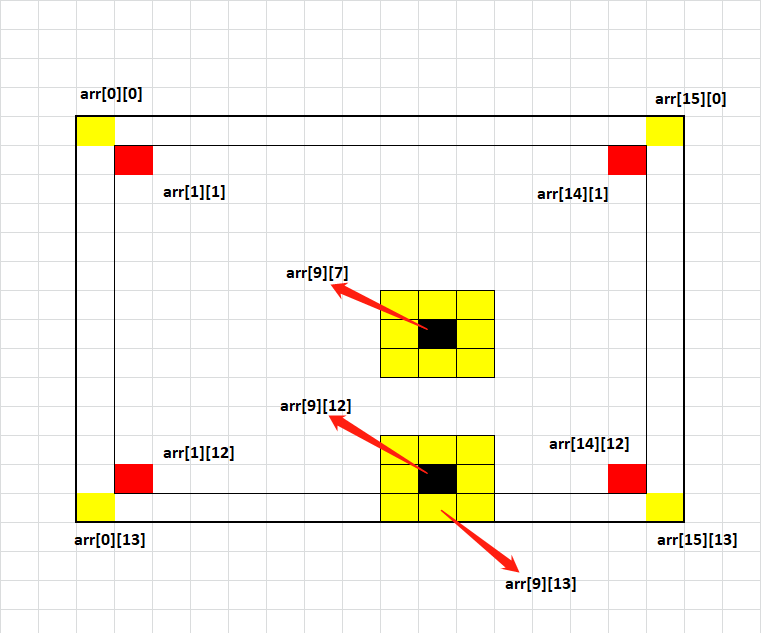
那么我们可以将图像的边界扩大(对用户是隐藏的边界)或者缩小处理的范围,我们就用第二种方法来简化边界,如下:
将整个图像(二维数组)arr[15][13]大小的数据进行简化边界,真正处理的区域就是arr[1][1]到arr[14][12]区域(浅色黑框),这些区域被定义为新的边界,即使在处理时遇到新的边界点arr[9][13],也不需要判断是否越界,直接按照非边界点处理即可,因为真正的边界是arr[15][13]区域(深色加粗黑框)。同理对于扩大边界处理的思想也是一样的。
那为什么要怎么做呢?简单来说,就是为了更好写程序,让程序有更高的效率。
对于程序来说,它看不到边界,也就是没有边界这一说法,它认为所处理的区域就是正常区域,那么写程序就不需要考虑边界问题了,免去了边界的判断。假设这幅图像是非常大的,如果在每次处理的时候都要判断是否越界,必然影响效率,因此这种简化边界的思想会很好,能提高效率,但提高的效率还是有限的,只能是减小它的常数因子(系数),而不能改变时间复杂度的渐近确界。
总结:
- 哨兵基本不能降低数据结构相关操作的渐近确界,但其可以降低常数因子,就好比时间复杂度为
O(n²)的算法,你即使再怎么使用哨兵思想,都没办法将它的时间复杂度变为O(n)。 - 哨兵的设计可以使得代码更简洁,可以省去一些由于
边界环境不同而作出的特殊处理。 - 在某些情况下哨兵可以使得循环语句更紧凑,降低运行时间里 n 或者 n²
项的系数。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









