






URL:统一资源定位符,由协议加资源名称构成,如:http://www.baidu.com,协议是http,名称就是后面的些些。
Java中构造URL的方法:

其它方法:

下面进行一些测试:
package love.jimo;
import java.net.MalformedURLException;
import java.net.URL;
public class URLTest {
public static void main(String[] args) {
try {
//创建URL实例
URL baidu = new URL("http://www.baidu.com");
//?后面是参数,#后后面是锚点
URL url = new URL(baidu,"/index.html?username=jimo#test");
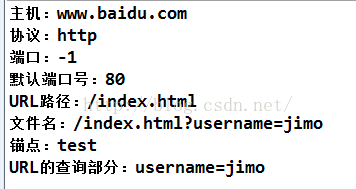
System.out.println("主机:"+url.getHost());
System.out.println("协议:"+url.getProtocol());
//未指定端口号,默认使用80端口,只是这时的getPort()返回值为-1
System.out.println("端口:"+url.getPort());
System.out.println("默认端口号:"+url.getDefaultPort());
System.out.println("URL路径:"+url.getPath());
System.out.println("文件名:"+url.getFile());
System.out.println("锚点:"+url.getRef());
System.out.println("URL的查询部分:"+url.getQuery());
} catch (MalformedURLException e) {
e.printStackTrace();
}
}
}
再来一个连网的例子:
package love.jimo;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.MalformedURLException;
import java.net.URL;
public class URLTest2 {
public static void main(String []args){
/*
* 读取百度主页
*/
try {
URL url = new URL("http://www.baidu.com");
//通过URL的openStream方法获得URL对象的资源的字节输入流
InputStream is = url.openStream();
//将字节输入流转换为字符输入流
InputStreamReader isr = new InputStreamReader(is);
//为字符输入流创建缓冲区
BufferedReader br = new BufferedReader(isr);
//循环读取数据
String data = null;
while(null != (data = br.readLine())){
System.out.println(data);
}
//关闭输入流
is.close();
isr.close();
br.close();
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
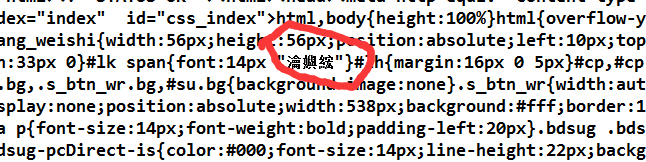
可以看到乱码的出现,因为百度用的utf-8编码,而编译器默认的gbk,所以这样改:
<span style="white-space:pre"> </span>//将字节输入流转换为字符输入流
InputStreamReader isr = new InputStreamReader(is,"utf-8");
将此文件保存为HTML并用浏览器打开时也出现了乱码:
只有调整浏览器的编码了。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









