









一、说明
主要是对Spark安装过程和与Elasticsearch的对接进行简单描述,期间遇到了较多的坑,特此记录一下。
因项目中使用的Elasticsearch2.3.2集群,所以需安装Spark1.6.0与之对应。对应关系是从Maven中心库发现的。
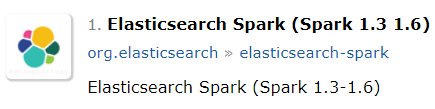

二、环境准备(相互之间都有对应关系)
- scala-2.10.6
- hadoop-2.6.5
- winutils2.7.1
- Spark1.6.0 (官网上不能下载了,坑啊)
- Elaticsearch2.3.2
- Idea + java1.8
1-4打包下载地址:链接: https://pan.baidu.com/s/18c0gnHCQKhZu6IxdcPjWDw 提取码: jumz
三、实施步骤
备注:安装路径要特别注意,不要出现空格、中文等
1、scala安装:
- 安装到指定文件夹中,环境变量中添加系统变量SCALA_HOME:D:\soft\scala-2.10.6;
- Path中加入:%SCALA_HOME%\bin;
- CLASSPATH中加入:%SCALA_HOME%\bin;
- cmd中检查安装情况:scala -version。安装成功见下图:

2、Hadoop安装:
- 解压到指定文件夹中,环境变量中添加系统变量HADOOP_HOME:D:\soft\hadoop-2.6.5;
- Path中加入:%HADOOP_HOME%\bin;
- 将winutils.exe拷贝至hadoop的bin目录下(spark的安装需要,不拷贝会报错)
- cmd:1、cd / 2、hadoop fs -rm -r /tmp/hive
- cmd中检查安装情况:hadoop version。安装成功见下图:

3、Spark安装:
- 解压到指定文件夹中,环境变量中添加系统变量SPARK_HOME:D:\soft\spark-1.6.0-bin-hadoop2.6;
- Path中加入:%SPARK_HOME%\bin;
- cmd中检查安装情况:spark-shell。安装成功见下图:

4、Idea中scala插件安装
- File-Settings-Plugins-Browse respositories,搜索scala插件,安装后重启Idea即可。如下图

四、入门小程序(计数统计+Es查询数据)

- 新建Maven scala项目:
- 代码已打包,下载地址:链接: https://pan.baidu.com/s/14hrCnuvYY_XQD68VbS2CmQ 提取码: 6bta
- 配置scala sdk:
- 运行

五、备注
- 如果pom没有报任何错,但是程序报有些类找不到,那就说明有些包下载失败。点击右侧的Maven Projects,会发现有些包下载错误。这就需要我们去maven的缓存目录将下载失败的目录删掉或者lastUpdated类型的文件,然后reimport
- artifactId为 elasticsearch-spark_2.10、spark-core_2.10类似结构的,下划线后面的2.10表示的是scala的版本,一定要和所使用的的scala版本进行对应,切记。















 3602
3602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









