







SQL语句
创建表
CREATE TABLE `test` (
`id` bigint NOT NULL AUTO_INCREMENT,
`status` char(1) DEFAULT '0' COMMENT '状态(0正常 1停用)',
`del_flag` char(1) DEFAULT '0' COMMENT '删除标志(0代表存在 2代表删除)',
`create_by` varchar(64) DEFAULT '' COMMENT '创建者',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_by` varchar(64) DEFAULT '' COMMENT '更新者',
`update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_german2_ci COMMENT='test表';
select 语句
查询结果赋初值
select field1, ifnull(field2) as field2, ifnull(field3,'')as field3 from xxx where xxx
若查询字段结果为null, ifnull 函数为其赋初值为0,’‘
注:as 重命名不可少,否则在mapper.xml中 ifnull 函数会失效
字段包含关系
in : select * from A where id in (1,2,3)
FIND_IN_SET: select * from A where find_in_set(id,(1,2,3))
注: 第二个参数必须是以英文逗号分割的字符串
find_in_set(id,ids) ids=1,2,3
添加字段
ALTER TABLE `user`
ADD COLUMN `username` varchar(20) NULL DEFAULT '' COMMENT '用户名' AFTER `phone`,
ADD COLUMN `create_at` datetime NULL COMMENT '创建时间' AFTER `username`;
COLUMN 可以省略,AFTER表示添加在某个字段后面,没有则添加在最后面
修改字段
ALTER TABLE 表名 MODIFY [COLUMN] 字段名 新数据类型 新类型长度 新默认值 新注释;
COLUMN关键字可以省略不写
alter table table1 modify column1 decimal(10,2) DEFAULT NULL COMMENT '注释';
正常,能修改字段类型、类型长度、默认值、注释
*alter table sys_dept modify `create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间'
*alter table sys_dept modify `update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
删除字段
ALTER TABLE `order`
DROP COLUMN `code_no`,
DROP COLUMN `fee`,
DROP COLUMN `refund_fail_msg`;
保留两位小数
select TRUNCATE(o.amount/100, 2) from ...
批量插入数据
INSERT INTO 表名 (a,b,c) (select a,b,c from ....)
sql 字符串操作
-- 字符串拼接concat; 生成13位随机数,不够前面补0lpad(floor(rand(999) * 1000000000000000), 13, '0'))
SELECT CONCAT('zzsdw', lpad(floor(rand(999) * 1000000000000000), 13, '0')) from...
-- 字符串截取 截取user_id列前8个字符
select SUBSTRING(a.user_id, 1, 8) from ...
清空表数据并且自增id归0
truncate table 表名
存表情报错
解决在mysql存入表情时,出现 Incorrect string value: ‘\xF0\x9F…’ for column ‘XXX’ at row 1 问题
一、更改mysql字符格式
1.在mysql的安装目录下找到my.ini,作如下修改:
[mysqld]
character-set-server=utf8mb4
[mysql]
default-character-set=utf8mb4
修改后重启Mysql
2. 将已经建好的表也转换成utf8mb4
命令:
更改数据库编码:
ALTER DATABASE caitu99 CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
alter table TABLE_NAME convert to character set utf8mb4 collate utf8mb4_bin; (将TABLE_NAME替换成你的表名)
如果还不行,可以尝试修改字段编码为 utf8mb4_general_ci
然后就OK了。网上流传的一个版本增加了一个步骤,就是把mysql环境变量将character_set_client,character_set_connection,character_set_database,character_set_results,character_set_server 都修改成utf8mb4,不过我没有做这一步,也正常,所以可能是这一步是多余的,如果需要改,则按照下面介绍做修改。
3.修改mysql配置文件my.cnf(windows为my.ini)
my.cnf一般在etc/mysql/my.cnf位置。找到后请在以下三部分里添加如下内容:
[client]
default-character-set = utf8mb4
[mysql]
default-character-set = utf8mb4
[mysqld]
character-set-client-handshake = FALSE
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci
init_connect='SET NAMES utf8mb4'
二、代码中进行转义
应用maven
<dependency>
<groupId>com.github.binarywang</groupId>
<artifactId>java-emoji-converter</artifactId>
<version>0.1.1</version>
</dependency>
代码转义:
String content="123😀😀😀😀😀";
EmojiConverter instance = EmojiConverter.getInstance();
instance.toAlias(content);
content就被转义成mysql可以存储的格式
update 语句
简单
update 表名 set `column`='xxx'
update + left join
UPDATE orders
LEFT JOIN freports
ON freports.order_id = orders.id
set orders.finish_at = freports.created_at
where orders.id in(1,2,3)
复杂的sql语句 插入更新同时进行
INSERT INTO ledger_config ( deposit_cus, withdrawal_cus, account_mode, as_info, create_time, create_user, del_flag ) SELECT
commercial_number,
'222',
1,
1.00,
now(),
"admin",
0
FROM
commercial;
UPDATE commercial c
JOIN ledger_config a ON a.deposit_cus = c.commercial_number
SET c.pay_mode = 1,
c.pay_flow = 1,
c.ledger_config_id = a.id
函数Group_concat用法
完整语法如下
group_concat([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator '分隔符'])
例如:
select * from testgroup
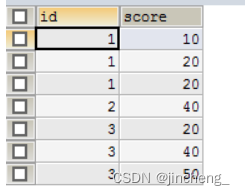
SELECT id,GROUP_CONCAT(score) FROM testgroup GROUP BY id
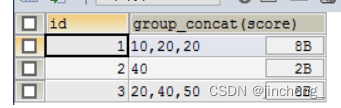
去重:
SELECT id,GROUP_CONCAT(DISTINCT score) FROM testgroup GROUP BY id
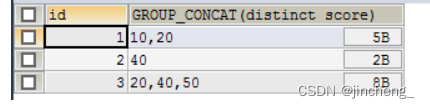
排序:
SELECT id,GROUP_CONCAT(score ORDER BY score DESC) FROM testgroup GROUP BY id
设置分隔符:
SELECT id,GROUP_CONCAT(score SEPARATOR ';') FROM testgroup GROUP BY id
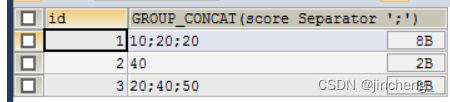
索引
添加索引
//添加索引
ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
删除索引
//删除索引
drop index index_name on table_name
修改表语句执行时加事务、关于表锁查询与解锁
更新表删除表加事务
BEGIN TRANSACTION
-- DELETE from base_invoice_apply where id in (4941)
update base_invoice_fix set regular_time = 0 , update_time = GETDATE() where area = 1501 and regular_time = 1 and regular_time_fix in (1,2)
COMMIT TRANSACTION;
-- 事务回滚
ROLLBACK TRANSACTION;
查询表锁与解锁
-- 查询锁表情况
SELECT request_session_id spid ,
OBJECT_NAME(resource_associated_entity_id) tableName
FROM sys.dm_tran_locks
WHERE resource_type = 'OBJECT';
-- 根据spid解除锁表
DECLARE @spid INT;
SET @spid = 117;
--锁表进程
DECLARE @sql VARCHAR(1000);
SET @sql = 'kill ' + CAST(@spid AS VARCHAR);
EXEC(@sql);
存储过程
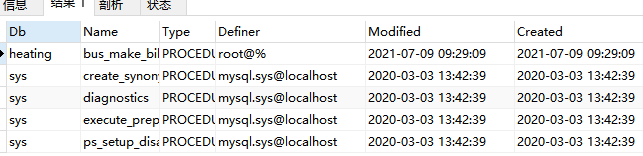
查看所有存储过程状态
show procedure status
结果如下:
查看bus_make_bill这个存储过程的详情
show create procedure bus_make_bill
结果如下:

Create Procedure 为创建存储过程语句
Left join的on和where的效率差别
假设有两个表a、b
使用on
Select * from a left join b on b.col = a.col and b.col2 = ‘aa’
使用 where
Select * from a left join b on b.col = a.col where b.col2 = ‘aa’ and b.col2 is null
// b.col2 is null作用是防止因b表中没有匹配数据,照成a表原有记录无法返回的问题
分析
1、on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表中的记录。
2、where条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有left join的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
–
结论:
Where语句的性能优于on语句
mybatis-plus 多表关联查询
/**
busUserVo.class 查询结果返回类(resultType)
selectAll() 查询指定实体类的全部字段
select() 查询指定的字段,支持可变参数,同一个select只能查询相同表的字段
selectAs() 字段别名查询,用于数据库字段与业务实体类属性名不一致时使用
leftJoin() 参数说明
第一个参数: 参与连表的实体类class
第二个参数: 连表的ON字段,这个属性必须是第一个参数实体类的属性
第三个参数: 参与连表的ON的另一个实体类属性
默认主表别名是t,其他的表别名以先后调用的顺序使用t1,t2,t3…
条件查询,可以查询主表以及参与连接的所有表的字段,全部调用mp原生的方法,正常使用没有sql注入风险
*/
Object d
ataScope = bo.getParams().get("dataScope");
List<BusUserVo> list = this.baseMapper.selectJoinList(BusUserVo.class,
new MPJLambdaWrapper<BusUser>()
.selectAll(BusUser.class)
.selectAs(SysDept::getDeptName, BusUserVo::getDeptName)
.leftJoin(SysDept.class, SysDept::getDeptId, BusUser::getDeptId)
.like(StrUtil.isNotBlank(bo.getUserName()), BusUser::getUserName, bo.getUserName())
.eq(StrUtil.isNotBlank(bo.getOpenId()), BusUser::getOpenId, bo.getOpenId())
.eq(StrUtil.isNotBlank(bo.getUserType()), BusUser::getUserType, bo.getUserType())
.like(StrUtil.isNotBlank(bo.getPhoneNumber()), BusUser::getPhoneNumber, bo.getPhoneNumber())
.like(StrUtil.isNotBlank(bo.getBizUserId()), BusUser::getBizUserId, bo.getBizUserId())
.eq(StrUtil.isNotBlank(bo.getIdNo()), BusUser::getIdNo, bo.getIdNo())
.like(StrUtil.isNotBlank(bo.getCloudUserId()), BusUser::getCloudUserId, bo.getCloudUserId())
.eq(StrUtil.isNotBlank(bo.getBankCardNo()), BusUser::getBankCardNo, bo.getBankCardNo())
.eq(StrUtil.isNotBlank(bo.getAcctProtocolNo()), BusUser::getAcctProtocolNo, bo.getAcctProtocolNo())
.eq(StrUtil.isNotBlank(bo.getStatus()), BusUser::getStatus, bo.getStatus())
.and(ObjectUtil.isNotNull(bo.getDeptId()),
wrapper -> wrapper.eq(BusUser::getDeptId, bo.getDeptId()).or().like(SysDept::getAncestors, bo.getDeptId()))
.apply(dataScope != null, dataScope != null ? " 1=1 " + dataScope.toString() : null)
);
优化sql的小技巧

避免使用 select *
原因:浪费了数据库资源,比如:内存或者 cpu。
select *不会走覆盖索引,会出现大量的回表操作,而从导致查询 sql 的性能很低。
用 union all 代替 union
我们都知道 sql 语句使用union关键字后,可以获取排重后的数据。
而如果使用union all关键字,可以获取所有数据,包含重复的数据。
排重的过程需要遍历、排序和比较,它更耗时,更消耗 cpu 资源。所以如果能用 union all 的时候,尽量不用 union。
除非是有些特殊的场景,比如 union all 之后,结果集中出现了重复数据,而业务场景中是不允许产生重复数据的,这时可以使用 union。
小表驱动大表
小表驱动大表,也就是说用小表的数据集驱动大表的数据集。
假如有 order 和 user 两张表,其中 order 表有 10000 条数据,而 user 表有 100 条数据。
这时如果想查一下,所有有效的用户下过的订单列表。
可以使用in关键字实现:
select * from order
where user_id in (select id from user where status=1)
也可以使用exists关键字实现:
select * from order
where exists (select 1 from user where order.user_id = user.id and status=1)
前面提到的这种业务场景,使用 in 关键字去实现业务需求,更加合适。
为什么呢?
因为如果 sql 语句中包含了 in 关键字,则它会优先执行 in 里面的子查询语句,然后再执行 in 外面的语句。如果 in 里面的数据量很少,作为条件查询速度更快。
而如果 sql 语句中包含了 exists 关键字,它优先执行 exists 左边的语句(即主查询语句)。然后把它作为条件,去跟右边的语句匹配。如果匹配上,则可以查询出数据。如果匹配不上,数据就被过滤掉了。
这个需求中,order 表有 10000 条数据,而 user 表有 100 条数据。order 表是大表,user 表是小表。如果 order 表在左边,则用 in 关键字性能更好。
总结一下:
in 适用于左边大表,右边小表。
exists 适用于左边小表,右边大表。
不管是用 in,还是 exists 关键字,其核心思想都是用小表驱动大表。
批量操作
如果你有一批数据经过业务处理之后,需要插入数据,该怎么办?
反例:
for(Order order: list){
orderMapper.insert(order):
}
在循环中逐条插入数据
insert into order(id,code,user_id)
values(123,'001',100);
该操作需要多次请求数据库,才能完成这批数据的插入。
但众所周知,我们在代码中,每次远程请求数据库,是会消耗一定性能的。而如果我们的代码需要请求多次数据库,才能完成本次业务功能,势必会消耗更多的性能。
那么如何优化呢?
正例:
orderMapper.insertBatch(list):
提供一个批量插入数据的方法。
insert into order(id,code,user_id)
values(123,'001',100),(124,'002',100),(125,'003',101);
这样只需要远程请求一次数据库,sql 性能会得到提升,数据量越多,提升越大。
但需要注意的是,不建议一次批量操作太多的数据,如果数据太多数据库响应也会很慢。批量操作需要把握一个度,建议每批数据尽量控制在 500 以内。如果数据多于 500,则分多批次处理。
多用 limit
有时候,我们需要查询某些数据中的第一条,比如:查询某个用户下的第一个订单,想看看他第一次的首单时间。
反例:
select id, create_date
from order
where user_id=123
order by create_date asc;
根据用户 id 查询订单,按下单时间排序,先查出该用户所有的订单数据,得到一个订单集合。然后在代码中,获取第一个元素的数据,即首单的数据,就能获取首单时间。
List<Order> list = orderMapper.getOrderList();
Order order = list.get(0);
虽说这种做法在功能上没有问题,但它的效率非常不高,需要先查询出所有的数据,有点浪费资源。
那么,如何优化呢?
正例:
select id, create_date
from order
where user_id=123
order by create_date asc
limit 1;
使用limit 1,只返回该用户下单时间最小的那一条数据即可。
此外,在删除或者修改数据时,为了防止误操作,导致删除或修改了不相干的数据,也可以在 sql 语句最后加上 limit。
这样即使误操作,比如把 id 搞错了,也不会对太多的数据造成影响。
in 中值太多
对于批量查询接口,我们通常会使用in关键字过滤出数据。比如:想通过指定的一些 id,批量查询出用户信息。
sql 语句如下:
select id,name from category
where id in (1,2,3...100000000);
如果我们不做任何限制,该查询语句一次性可能会查询出非常多的数据,很容易导致接口超时。
这时该怎么办呢?
select id,name from category
where id in (1,2,3...100)
limit 500;
可以在 sql 中对数据用 limit 做限制。
不过我们更多的是要在业务代码中加限制,伪代码如下:
public List<Category> getCategory(List<Long> ids) {
if(CollectionUtils.isEmpty(ids)) {
return null;
}
if(ids.size() > 500) {
throw new BusinessException("一次最多允许查询500条记录")
}
return mapper.getCategoryList(ids);
}
还有一个方案就是:如果 ids 超过 500 条记录,可以分批用多线程去查询数据。每批只查 500 条记录,最后把查询到的数据汇总到一起返回。
不过这只是一个临时方案,不适合于 ids 实在太多的场景。因为 ids 太多,即使能快速查出数据,但如果返回的数据量太大了,网络传输也是非常消耗性能的,接口性能始终好不到哪里去。
增量查询
有时候,我们需要通过远程接口查询数据,然后同步到另外一个数据库。
反例:select * from user;
如果直接获取所有的数据,然后同步过去。这样虽说非常方便,但是带来了一个非常大的问题,就是如果数据很多的话,查询性能会非常差。
这时该怎么办呢?
正例:
select * from user where id>#{lastId} and create_time >= #{lastCreateTime} limit 100;
按 id 和时间升序,每次只同步一批数据,这一批数据只有 100 条记录。每次同步完成之后,保存这 100 条数据中最大的 id 和时间,给同步下一批数据的时候用。
通过这种增量查询的方式,能够提升单次查询的效率。
高效的分页
有时候,列表页在查询数据时,为了避免一次性返回过多的数据影响接口性能,我们一般会对查询接口做分页处理。
在 mysql 中分页一般用的limit关键字:
select id,name,age
from user limit 10,20;
mysql 会查到 1000020 条数据,然后丢弃前面的 1000000 条,只查后面的 20 条数据,这个是非常浪费资源的。
那么,这种海量数据该怎么分页呢?
select id,name,age
from user where id > 1000000 limit 20;
先找到上次分页最大的 id,然后利用 id 上的索引查询。不过该方案,要求 id 是连续的,并且有序的。
还能使用between优化分页。
select id,name,age
from user where id between 1000000 and 1000020;
需要注意的是 between 要在唯一索引上分页,不然会出现每页大小不一致的问题。
用连接查询代替子查询
mysql 中如果需要从两张以上的表中查询出数据的话,一般有两种实现方式:子查询 和 连接查询。
子查询的例子如下:
select * from order
where user_id in (select id from user where status=1)
子查询语句可以通过in关键字实现,一个查询语句的条件落在另一个 select 语句的查询结果中。程序先运行嵌套在最内层的语句,再运行外层的语句。
子查询语句的优点是简单,结构化,如果涉及的表数量不多的话。
但缺点是 mysql 执行子查询时,需要创建临时表,查询完毕后,需要再删除这些临时表,有一些额外的性能消耗。
这时可以改成连接查询。具体例子如下:
select o.* from order o
inner join user u on o.user_id = u.id
where u.status=1
join 的表不宜过多
根据阿里巴巴开发者手册的规定,join 表的数量不应该超过3个。
select a.name,b.name.c.name,d.name
from a
inner join b on a.id = b.a_id
inner join c on c.b_id = b.id
inner join d on d.c_id = c.id
inner join e on e.d_id = d.id
inner join f on f.e_id = e.id
inner join g on g.f_id = f.id
如果 join 太多,mysql 在选择索引的时候会非常复杂,很容易选错索引。
并且如果没有命中,nested loop join 就是分别从两个表读一行数据进行两两对比,复杂度是 n^2。
所以我们应该尽量控制 join 表的数量。
正例:
select a.name,b.name.c.name,a.d_name
from a
inner join b on a.id = b.a_id
inner join c on c.b_id = b.id
如果实现业务场景中需要查询出另外几张表中的数据,可以在 a、b、c 表中冗余专门的字段,比如:在表 a 中冗余 d_name 字段,保存需要查询出的数据。
不过我之前也见过有些 ERP 系统,并发量不大,但业务比较复杂,需要 join 十几张表才能查询出数据。
所以 join 表的数量要根据系统的实际情况决定,不能一概而论,尽量越少越好。
join 时要注意
我们在涉及到多张表联合查询的时候,一般会使用join关键字。
而 join 使用最多的是 left join 和 inner join。
left join:求两个表的交集外加左表剩下的数据。
inner join:求两个表交集的数据。
使用 inner join 的示例如下:
select o.id,o.code,u.name
from order o
inner join user u on o.user_id = u.id
where u.status=1;
如果两张表使用 inner join 关联,mysql 会自动选择两张表中的小表,去驱动大表,所以性能上不会有太大的问题。
使用 left join 的示例如下:
select o.id,o.code,u.name
from order o
left join user u on o.user_id = u.id
where u.status=1;
如果两张表使用 left join 关联,mysql 会默认用 left join 关键字左边的表,去驱动它右边的表。如果左边的表数据很多时,就会出现性能问题。
要特别注意的是在用 left join 关联查询时,左边要用小表,右边可以用大表。如果能用 inner join 的地方,尽量少用 left join。
控制索引的数量
众所周知,索引能够显著地提升查询 sql 的性能,但索引数量并非越多越好。
因为表中新增数据时,需要同时为它创建索引,而索引是需要额外的存储空间的,而且还会有一定的性能消耗。
阿里巴巴的开发者手册中规定,单表的索引数量应该尽量控制在5个以内,并且单个索引中的字段数不超过5个。
mysql 使用 B+ 树的结构来保存索引,在 insert、update 和 delete 操作时,需要更新 B+ 树索引。如果索引过多,会消耗很多额外的性能。
那么,问题来了,如果表中的索引太多,超过了 5 个该怎么办?
这个问题要辩证地看,如果你的系统并发量不高,表中的数据量也不多,其实超过 5 个也可以,只要不要超过太多就行。
但对于一些高并发的系统,请务必遵守单表索引数量不要超过 5 的限制。
那么,高并发系统如何优化索引数量?
能够建联合索引,就别建单个索引,可以删除无用的单个索引。
将部分查询功能迁移到其他类型的数据库中,比如:Elastic Seach、HBase 等,在业务表中只需要建几个关键索引即可。
选择合理的字段类型
char表示固定字符串类型,该类型的字段存储空间是固定的,会浪费存储空间。
alter table order
add column code char(20) NOT NULL;
varchar表示变长字符串类型,该类型的字段存储空间会根据实际数据的长度调整,不会浪费存储空间。
alter table order
add column code varchar(20) NOT NULL;
如果是长度固定的字段,比如用户手机号,一般都是 11 位的,可以定义成 char 类型,长度是 11 字节。
但如果是企业名称字段,假如定义成 char 类型,就有问题了。
如果长度定义得太长,比如定义成了 200 字节,而实际企业长度只有 50 字节,则会浪费 150 字节的存储空间。
如果长度定义得太短,比如定义成了 50 字节,但实际企业名称有 100 字节,就会存储不下,而抛出异常。
所以建议将企业名称改成 varchar 类型,变长字段存储空间小,可以节省存储空间,而且对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
我们在选择字段类型时,应该遵循这样的原则:
1.能用数字类型,就不用字符串,因为字符的处理往往比数字要慢。
2.尽可能使用小的类型,比如:用 bit 存布尔值,用 tinyint 存枚举值等。
3.长度固定的字符串字段,用 char 类型。
4.长度可变的字符串字段,用 varchar 类型。
5.金额字段用 decimal,避免精度丢失问题。
还有很多原则,这里就不一一列举了。
提升 group by 的效率
我们有很多业务场景需要使用group by关键字,它主要的功能是去重和分组。
通常它会跟having一起配合使用,表示分组后再根据一定的条件过滤数据。
反例:
select user_id,user_name from order
group by user_id
having user_id <= 200;
这种写法性能不好,它先把所有的订单根据用户 id 分组之后,再去过滤用户 id 大于等于 200 的用户。
分组是一个相对耗时的操作,为什么我们不先缩小数据的范围之后,再分组呢?
正例:
select user_id,user_name from order
where user_id <= 200
group by user_id
使用 where 条件在分组前,就把多余的数据过滤掉了,这样分组时效率就会更高一些。
其实这是一种思路,不仅限于 group by 的优化。我们的 sql 语句在做一些耗时的操作之前,应尽可能缩小数据范围,这样能提升 sql 整体的性能。
索引优化
sql 优化当中,有一个非常重要的内容就是:索引优化。
很多时候 sql 语句,走了索引和没有走索引,执行效率差别很大。所以索引优化被作为 sql 优化的首选。
索引优化的第一步是:检查 sql 语句有没有走索引。
那么,如何查看 sql 走了索引没?
可以使用explain命令,查看 mysql 的执行计划。
例如:
explain select * from `order` where code='002';
结果:

通过这几列可以判断索引使用情况,执行计划包含列的含义如下图所示:

说实话,sql 语句没有走索引,排除没有建索引之外,最大的可能性是索引失效了。
下面说说索引失效的常见原因:

如果不是上面的这些原因,则需要再进一步排查一下其他原因。
此外,你有没有遇到过这样一种情况:明明是同一条 sql,只有入参不同而已,有的时候走的索引 a,有的时候却走的索引 b?
没错,有时候 mysql 会选错索引。必要时可以使用force index来强制查询 sql 走某个索引。














 669
669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









