









一、理解DOM
从一个简单的HTML文档理解树的概念:
- <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
- <html xmlns="http://www.w3.org/1999/xhtml">
- <head>
- <meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
- <title>DOM TEST</title>
- </head>
- <body>
- <h1>DOM TEST HEADING</h1>
- <hr />
- <!--Just a comment-->
- <p>A paragraph of <em>text</em> is just an example</p>
- <ul id="ul"><li><a href="#">Yahoo!</a></li></ul>
- </body>
- </html>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>DOM TEST</title>
</head>
<body>
<h1>DOM TEST HEADING</h1>
<hr />
<!--Just a comment-->
<p>A paragraph of <em>text</em> is just an example</p>
<ul id="ul"><li><a href="#">Yahoo!</a></li></ul>
</body>
</html>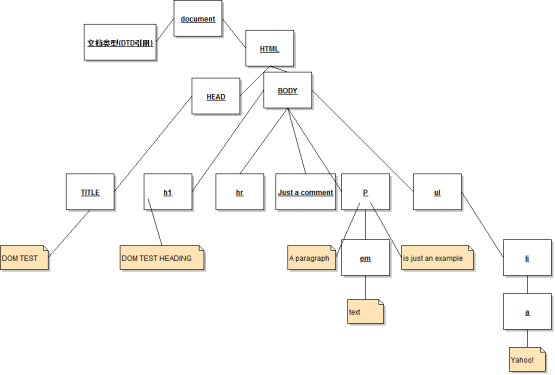
二、DOM中常用属性及方法:(如未特别举出文档事例,均采用文章开头的HTML文档,测试在chrome中通过:JavaScript控制台)
(一)nodeName:String 文本节点的nodeName总是#text
document.getElementById("ul").nodeName; // UL (nodeName返回始终为大写)
(二)nodeValue:String 通常用于文本节点(元素节点返回为null)
document.getElementsByTagName("title")[0].firstChild.nodeValue //DOM TEST
(三)nodeType:Number 节点类型常量值
DOM浏览器中:
元素节点类型:Node.ELEMENT_NODE 1
文本节点类型:Node.TEXT_NODE 3
document.getElementById("ul").nodeType; // 1
(四)firstChild:Node 指向子节点列表中第一个节点
document.getElementsByTagName("title")[0].firstChild.nodeName; //#text
(五)lastChild:Node 指向子节点列表中最后个节点
(六)childNodes:NodeList 所有子节点列表
var doc = document.getElementById("ul").childNodes;for(d in doc){alert(doc[d].nodeName)};
(七)parentNode:Node 返回父节点
document.getElementById("ul").parentNode.nodeName; //BODY
(八)previousSibling:Node 返回前一个兄弟节点
document.getElementsByTagName("em")[0].previousSibling.nodeValue;//A paragraph of
(九)nextSibling:Node 返回下一个兄弟节点
document.getElementsByTagName("em")[0].nextSibling.nodeValue;
// is just an example
(十)hasChildNodes():Boolean 判断是否包含子节点
document.getElementsByTagName("em")[0].nextSibling.hasChildNodes(); //false
(十一)appendChild(node)
var text = document.createTextNode("test"); //创建一个文本节点
var li = document.createElement("li"); //创建一个元素
li.appendChild(text); //li元素追加子节点text
document.getElementById("ul").appendChild(li); //ul追加子节点li
(十二)removeChild(node)
document.getElementById("ul").removeChild(document.getElementById("ul").lastChild);
(十三)insertBefore(new,old) 在old前插入一个new节点
var text = document.createTextNode("test");
var li = document.createElement("li");li.appendChild(text);
var doc = document.getElementById("ul");
doc.insertBefore(li,doc.firstChild);
(十四)cloneNode() 无参:克隆节点本身,浅层克隆;true:深层克隆
//深层克隆 所有子节点
var ul = document.getElementById("ul");
var cloneNode = ul.cloneNode(true);
ul.appendChild(cloneNode);
//浅层 仅元素本身
var li = document.getElementById("ul").firstChild;
var c = li.cloneNode();
document.getElementById("ul").appendChild(c); //只有<li>
(十五)innerHTML 特别的table及select元素不支持这样的赋值
var html = document.getElementById("ul").innerHTML;
alert(html);
(十六)getElementById(); 通过ID获取元素
(十七)getElementsByTagName() 通过元素标签名获取元素(数组)
(十八)getElementsByName() 通过元素name获取元素,通常用于radio、checkbox
三、实例:
通过两个按钮添加删除元素,输入框内容为添加内容
- <script type="text/javascript">
- window.onload = init;
- var ul;
- function init(){
- document.getElementsByTagName("input")[1].onclick = add;
- document.getElementsByTagName("input")[2].onclick = remove;
- ul = document.getElementsByTagName("ul")[0];
- }
- function add(){
- var txt = document.getElementsByTagName("input")[0].value;
- if(txt!=""){
- var liText = document.createTextNode(txt);
- var li = document.createElement("li");
- li.appendChild(liText);
- ul.insertBefore(li,ul.firstChild);
- document.getElementsByTagName("input")[0].value = "";
- }
- }
- function remove(){
- /*if(ul.hasChildNodes()){
- ul.removeChild(ul.firstChild);
- }*/
- var li = document.getElementsByTagName("li");
- if(li.length>0){
- ul.removeChild(li[li.length-1]);
- }
- }
- </script>
- </head>
- <body>
- <ul>
- <li>文字1</li>
- <li>文字2</li>
- </ul>
- <div>
- 输入<input type="text" /><br />
- <input type="button" value="+" />
- <input type="button" value="-" />
- </div>
<script type="text/javascript">
window.onload = init;
var ul;
function init(){
document.getElementsByTagName("input")[1].onclick = add;
document.getElementsByTagName("input")[2].onclick = remove;
ul = document.getElementsByTagName("ul")[0];
}
function add(){
var txt = document.getElementsByTagName("input")[0].value;
if(txt!=""){
var liText = document.createTextNode(txt);
var li = document.createElement("li");
li.appendChild(liText);
ul.insertBefore(li,ul.firstChild);
document.getElementsByTagName("input")[0].value = "";
}
}
function remove(){
/*if(ul.hasChildNodes()){
ul.removeChild(ul.firstChild);
}*/
var li = document.getElementsByTagName("li");
if(li.length>0){
ul.removeChild(li[li.length-1]);
}
}
</script>
</head>
<body>
<ul>
<li>文字1</li>
<li>文字2</li>
</ul>
<div>
输入<input type="text" /><br />
<input type="button" value="+" />
<input type="button" value="-" />
</div>
代码中多行注释的部分,在FF类型浏览器中需要点击两次删除才真正的删除,这是因为
- <ul>
- <li>文字1</li>
- <li>文字2</li>
- </ul>
<ul>
<li>文字1</li>
<li>文字2</li>
</ul>
这几行代码是敲入的,每行有“/n”,IE自动忽略换行,而FF不忽略,点击第一次删除是删除换行符,第二次才是删除LI















 985
985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









