







常用编码学习 2021.4.27
1、为什么了解不同编码?因为经常遇到
无论是读取txt记事本文件,或是用过各种编程IDE,或是开发网站平台jsp、html,都不可避免地要接触到编码方式encoding。既然有编码,那就需要解码,知道了编码方式才能够从容地去解码得到想要的结果,类似于密码破解翻译。同时,编码方式也决定了文件的读取和写入方式,网页数据传输、后台和前端API的调用需要考虑数据的编码unicode or utf-8 or GBK等,因此要尤为注意。下面是经常遇到的不同编码场景。
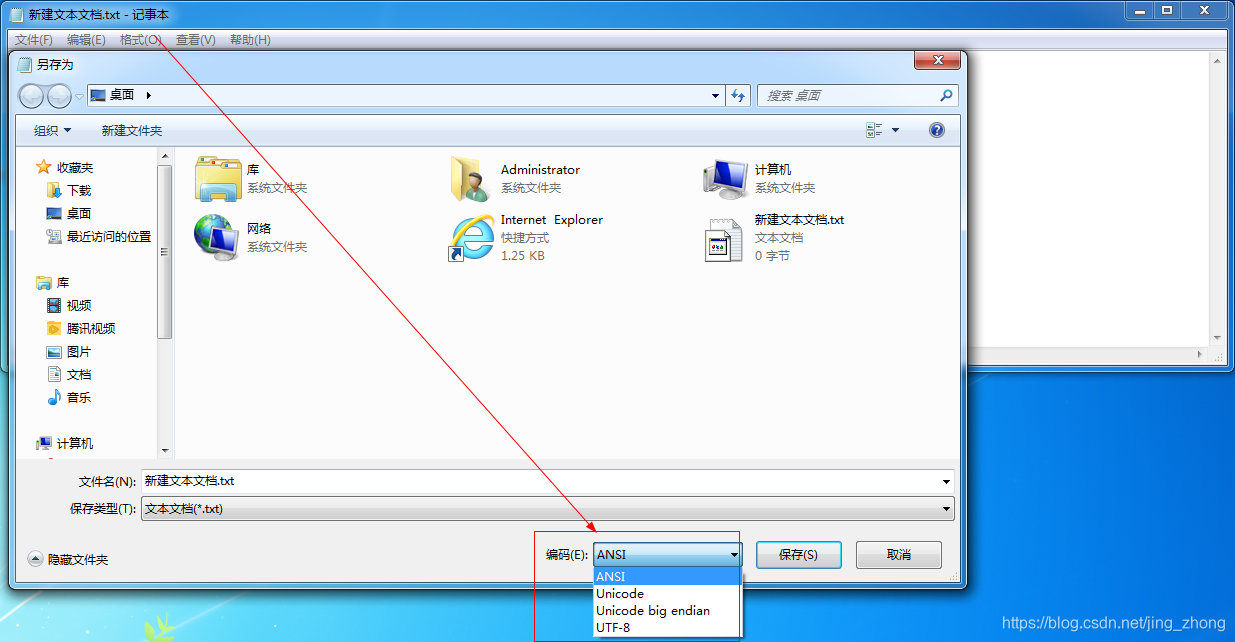
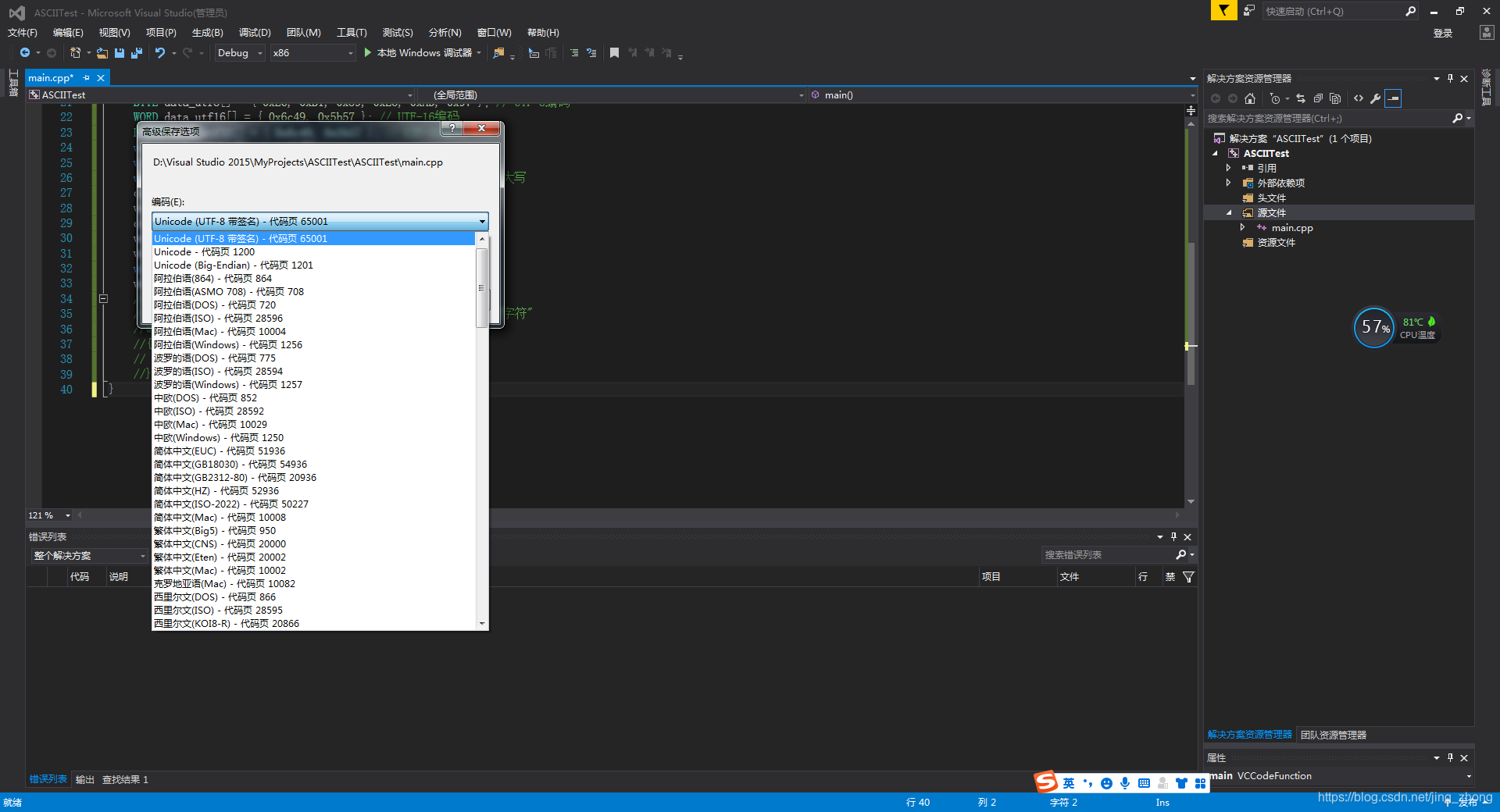
2、ASCII码简介
ASCII码 (American Standard Code for Information Interchange:美国信息交换标准代码)用于显示现代英语和其他西欧语言,是一套基于拉丁字母的电脑编码系统。由于计算机中所有的数据存储和表示都要用二进制数0和1来表示,但有些特殊的字符如a-z、#、@、%、&、*等需要进行编码,约定好在计算机中哪个字符对应的二进制数的大小,从而形成统一的规范化表示,采用统一的编码规则能够使得计算机之间的通信不受混乱。
ASCII 编码是最简单的西文编码方案 ,它由128个字符组成,包括大小写字母、数字0-9、标点符号、非打印字符(换行符、制表符等4个)以及控制字符(退格、响铃等)组成。由于计算机通常采用“字节”为单位存储和交换数据信息,因此很多计算机厂家对ASCII码进行了扩充,在原来的基础上又增加了128个附加字符,如ANSI、UNICODE等字符集。
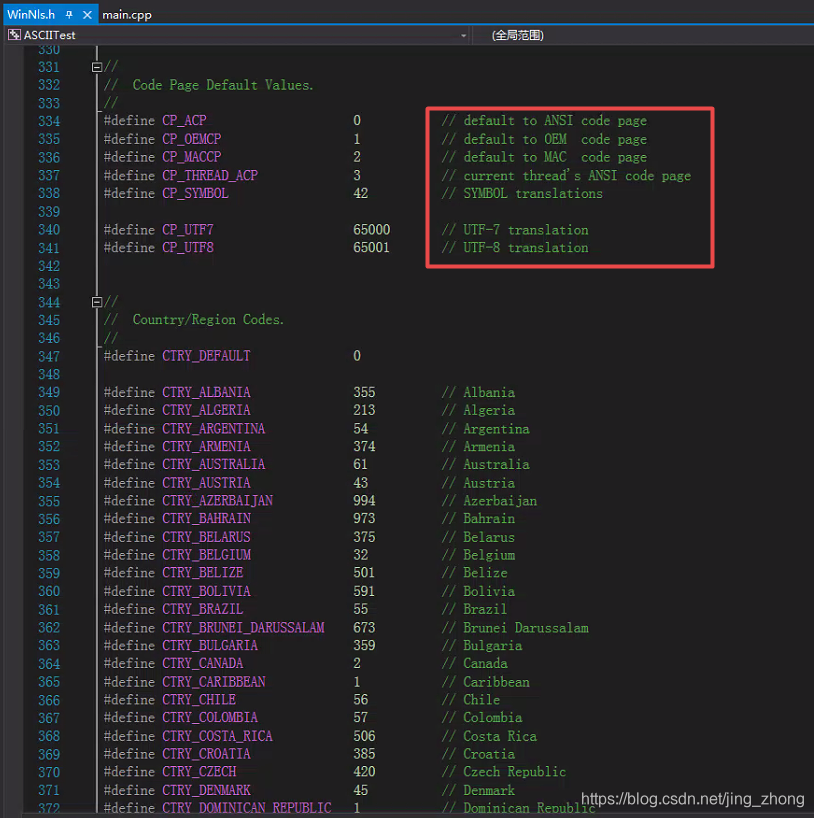
ANSI是一种字符代码,为使计算机支持更多语言,通常使用 0x00~0x7f 范围的1 个字节来表示 1 个英文字符。超出此范围的使用0x80~0xFFFF来编码,即扩展的ASCII编码。在简体中文Windows操作系统中,ANSI 编码代表 GB2312编码。以下两张图片来源于cplusplus官网中ascii的介绍,能够帮助用户更好地理解ASCII码。


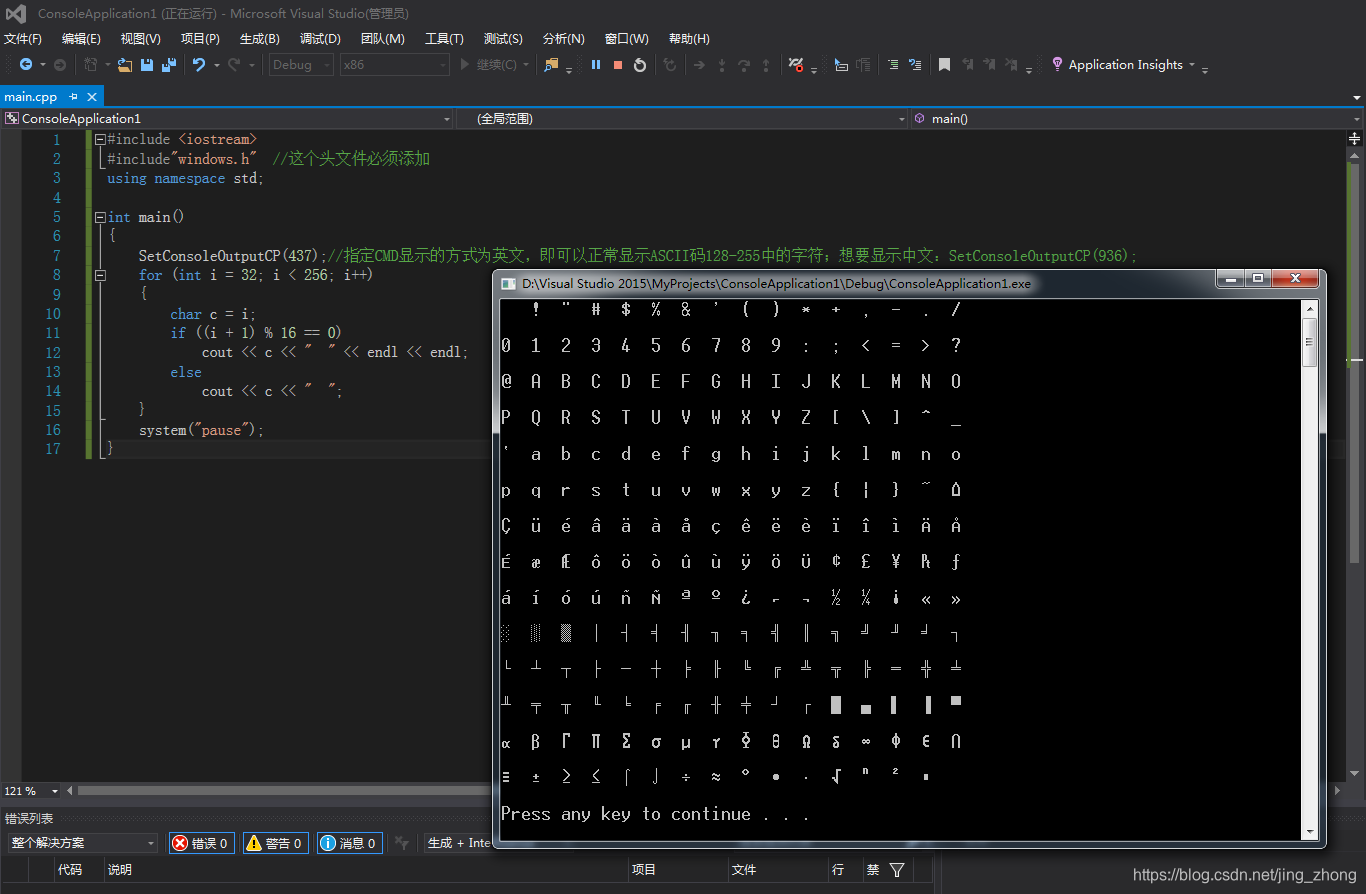
2.1 C++打印ASCII码中编号为32~127的可显示字符
#include <iostream>
#include"windows.h" //这个头文件必须添加
using namespace std;
int main()
{
SetConsoleOutputCP(437);//指定CMD显示的方式为英文,即可以正常显示ASCII码128-255中的字符;想要显示中文:SetConsoleOutputCP(936);
for (int i = 32; i < 128; i++)
{
char c = i;
if ((i + 1) % 16 == 0)
cout << c << " " << endl << endl;
else
cout << c << " ";
}
system("pause");
}

2.2 C++打印OEM码中编号为32~255的可显示字符
#include <iostream>
#include"windows.h" //这个头文件必须添加
using namespace std;
int main()
{
SetConsoleOutputCP(437);//指定CMD显示的方式为英文,即可以正常显示ASCII码128-255中的字符;想要显示中文:SetConsoleOutputCP(936);
for (int i = 32; i < 256; i++)
{
char c = i;
if ((i + 1) % 16 == 0)
cout << c << " " << endl<<endl;
else
cout << c << " ";
}
system("pause");
}
3、常用的文件编码方式
3.1 Unicode
统一码(Unicode)包含ASCII码,’\u0000’到’\u007F’对应全部128个ACSII字符。学名为Universal Multiple-Octet Coded Character Set,简称UCS。为了解决传统的字符编码方案的局限性,统一码Unicode为每种语言中的每个字符设定了统一并且唯一的二进制编码,从而满足跨语言、跨平台进行文本转换、处理的要求,由于包括字符集、编码方案等,最终成为了计算机科学领域里的一项业界标准。Download The Unicode Standard, Version 13.0 Code Charts 在Unode码表中可以查找各个国家语言的十六进制(hex)编码范围。
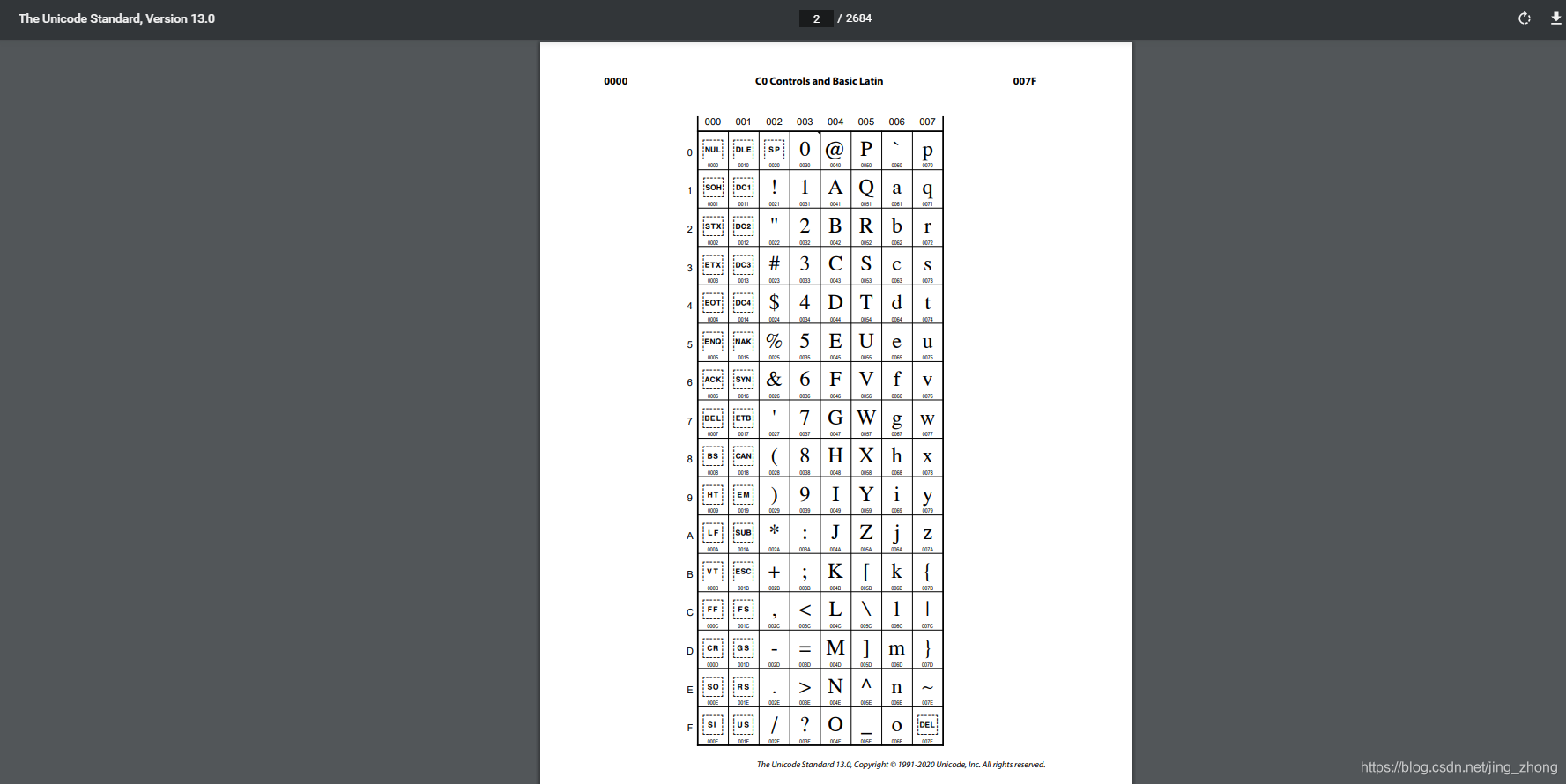


Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。Unicode用数字0 ~ 0x10FFFF(0 ~ 1114111)来对所有字符进行映射,最多可容纳1114112个字符,或者说有1114112个码位,其中UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。
UTF是“UCS Transformation Format”的缩写,意为Unicode字符集转换格式,即怎样将Unicode定义的数字转换成程序数据。比如说在Unicode编码中:汉字“字”对应的数字是23383,但是有很多方式将数字23383表示成程序中的数据,包括:UTF-8、UTF-16、UTF-32。unicode编码的字符一般以wchar_t宽字符类型存储。 其中UTF-8因可以兼容ASCII而被广泛使用。
locale loc("chs");//windows下ok,放在main上面
wchar_t han = L'汉',zi = L'字';
wchar_t* test = L"汉字";
cout <<han << " "<<zi<<" "<<endl;
cout << test << " "<<endl;
BYTE data_utf8[] = {0xE6, 0xB1, 0x89, 0xE5, 0xAD, 0x97}; // UTF-8编码
WORD data_utf16[] = {0x6c49, 0x5b57}; // UTF-16编码
DWORD data_utf32[] = {0x6c49, 0x5b57}; // UTF-32编码
wchar_t wc_array[] = L"破晓的博客";
wcout.imbue(loc);
wcout << wc_array << endl;
3.1.1 C++根据Unicode中文字符串输出各汉字对应的Unicode码值
#include <iostream>
#include<string>
#include <windows.h> //这个头文件必须添加
#include <iomanip>
#include <fstream>
using namespace std;
int main()
{
wcin.imbue(std::locale("chs"));//载入中文字符输入方式
wcout.imbue(std::locale("chs"));//载入中文字符输入方式
while (true)
{
cout << "请输入一个中文字符串:" << endl;
wstring s;
wcin >> s;
cout << "输入的中文字符串为:";
wcout << s;
cout << endl;
int len = 0;
while (s[len] != L'\0')
len++;
for (int i = 0; i < len; i++)
{
wcout << s[i] << " ";
cout << showbase << hex << s[i] << " " << showbase << dec << s[i] << " " << showbase << oct << s[i] << endl;
}
}
system("pause");
return 0;
}
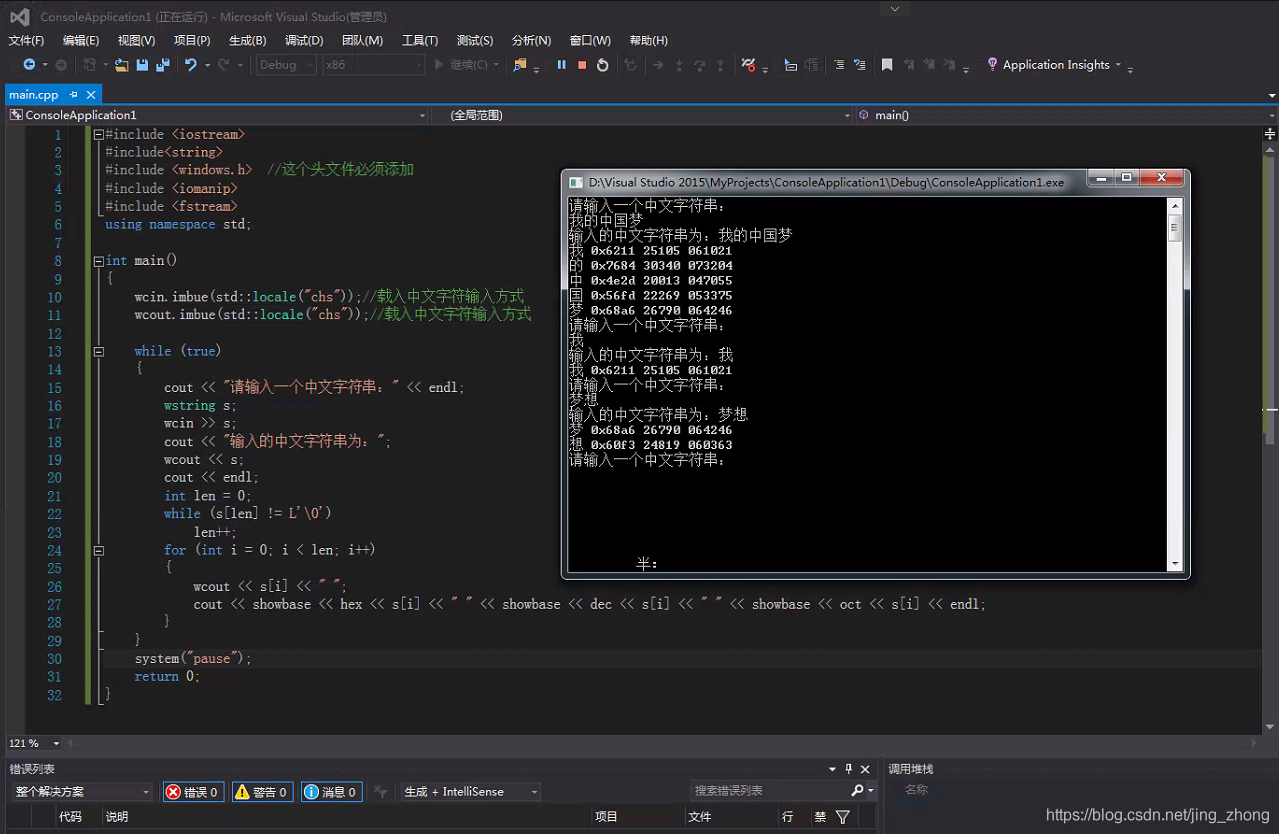
3.1.2 C++根据Unicode中文字符码值输出对应的汉字
#include <iostream>
#include<string>
#include <windows.h> //这个头文件必须添加
#include <iomanip>
#include <fstream>
using namespace std;
int main()
{
wcin.imbue(std::locale("chs"));//载入中文字符输入方式
wcout.imbue(std::locale("chs"));//载入中文字符输入方式
while (true)
{
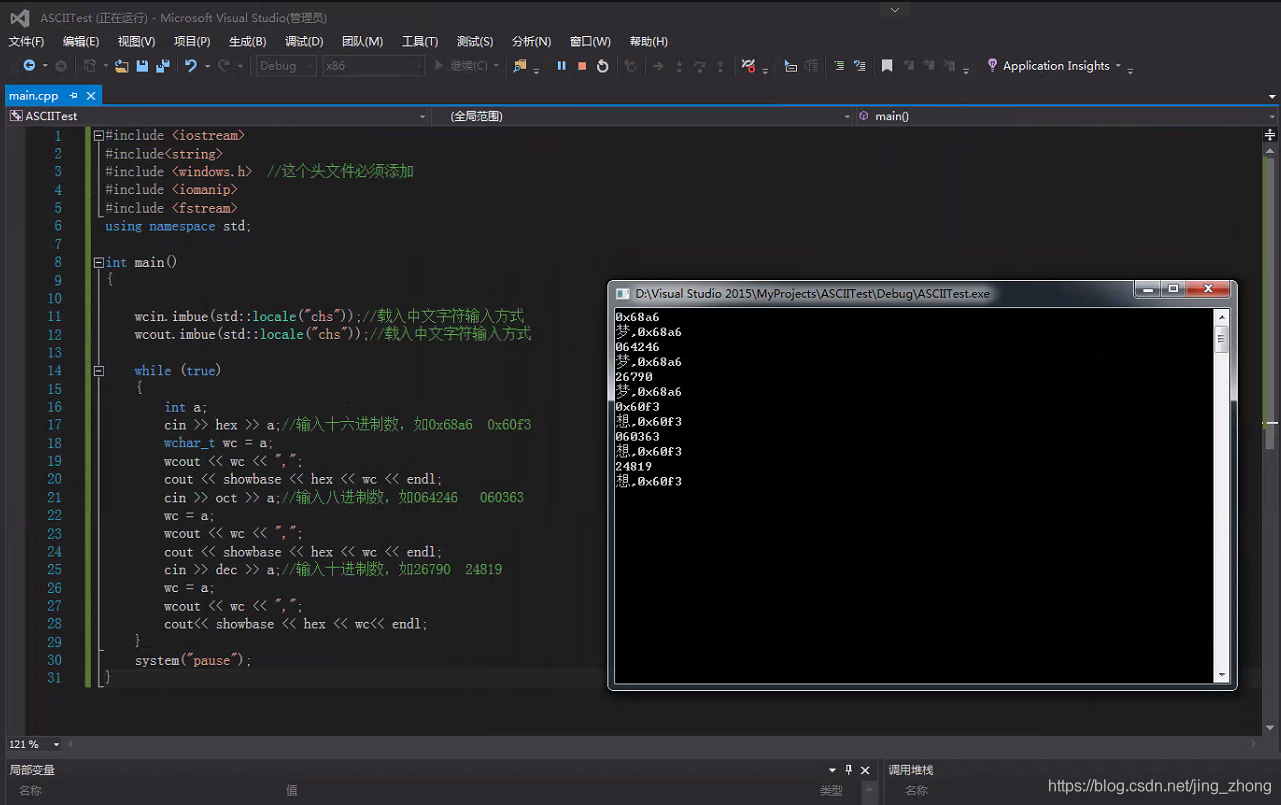
int a;
cin >> hex >> a;//输入十六进制数,如0x68a6 0x60f3
wchar_t wc = a;
wcout << wc << ",";
cout << showbase << hex << wc << endl;
cin >> oct >> a;//输入八进制数,如064246 060363
wc = a;
wcout << wc << ",";
cout << showbase << hex << wc << endl;
cin >> dec >> a;//输入十进制数,如26790 24819
wc = a;
wcout << wc << ",";
cout<< showbase << hex << wc<< endl;
}
system("pause");
}
3.1.3 C++打印Unicode中文(0x4E00~0x9FFC : CJK 统一表意符号 ->CJK Unified Ideographs)
#include <iostream>
#include<string>
#include <windows.h> //这个头文件必须添加
#include <iomanip>
#include <fstream>
using namespace std;
char* wideCharToMultiByte1(wchar_t pWCStrKey1)
{
wchar_t* pWCStrKey = &pWCStrKey1;
int pSize = WideCharToMultiByte(CP_OEMCP, 0, pWCStrKey, wcslen(pWCStrKey), NULL, 0, NULL, NULL); //第一次调用确认转换后单字节字符串的长度,用于开辟空间
char* pCStrKey = new char[pSize + 1];
WideCharToMultiByte(CP_OEMCP, 0, pWCStrKey, wcslen(pWCStrKey), pCStrKey, pSize, NULL, NULL); //第二次调用将双字节字符串转换成单字节字符串
pCStrKey[pSize] = '\0';
return pCStrKey;
}
int main()
{
wcin.imbue(std::locale("chs"));//载入中文字符输入方式
wcout.imbue(std::locale("chs"));//载入中文字符输入方式
cout << sizeof(wchar_t) << endl;
char* path = "E:\\UnicodeChineseall.txt";
ofstream fout(path, std::ofstream::app);//指定追加末尾的方式写入
fout << "Unicode中文字符" << " " << "十六进制" << " " << "十进制" << " " << "八进制" << endl;
cout << "Unicode中文字符" << " " << "十六进制" << " " << "十进制" << " " << "八进制" << endl;
for (int i = 0x4e00; i <= 0x9ffc; i++)//0x4E00-0x9FFC(hex十六进制) 31C0-31E3汉字笔画
{
wchar_t tempchar = i;
wcout << tempchar << ",";
cout << showbase << hex << tempchar << "," << showbase << dec << tempchar << "," << showbase << oct << tempchar << endl;
fout << wideCharToMultiByte1(tempchar) << ",";
fout << showbase << hex << tempchar << "," << showbase << dec << tempchar << ","<< showbase << oct << tempchar << endl;
}
fout.close();
system("pause");
}
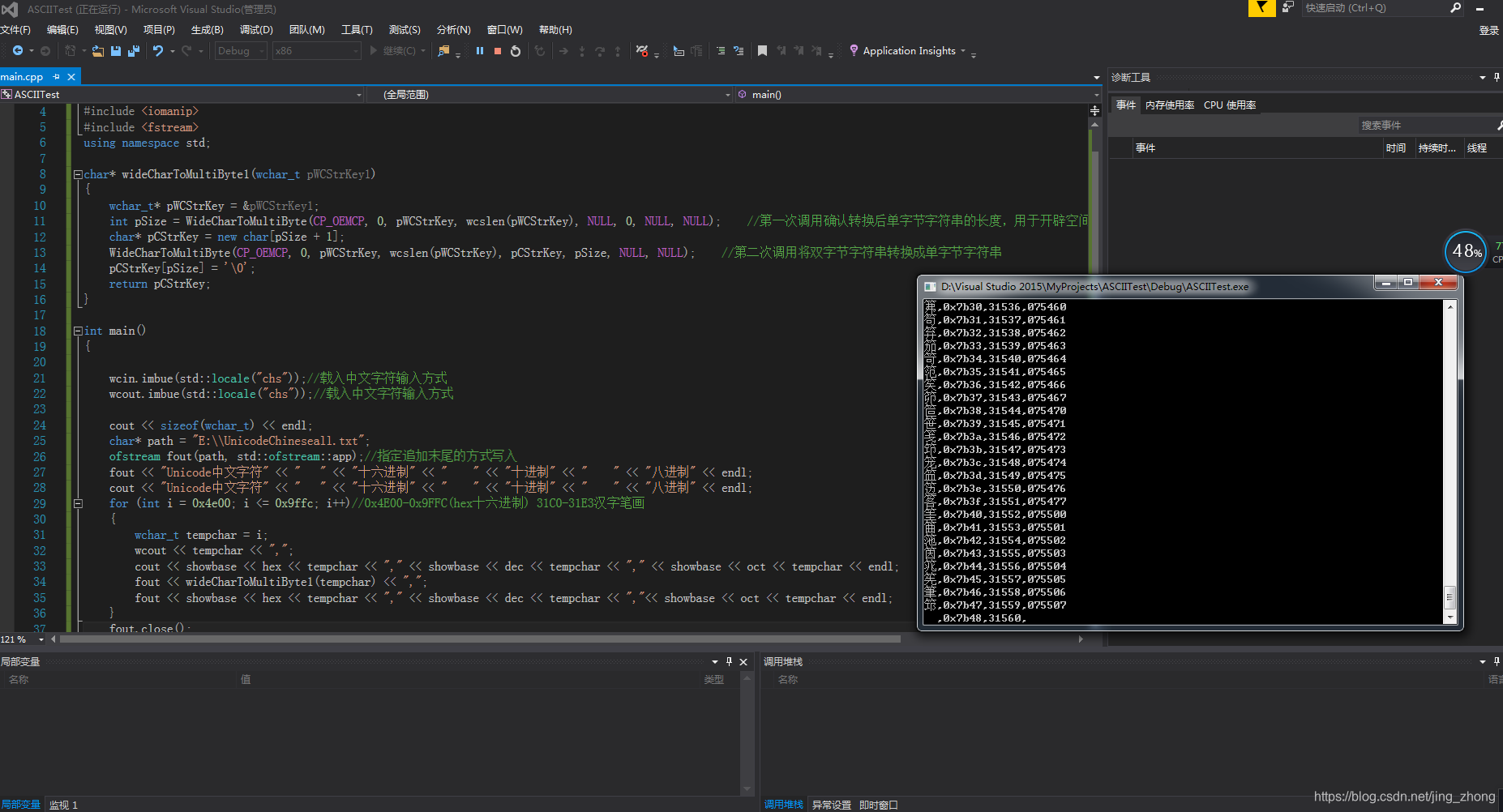

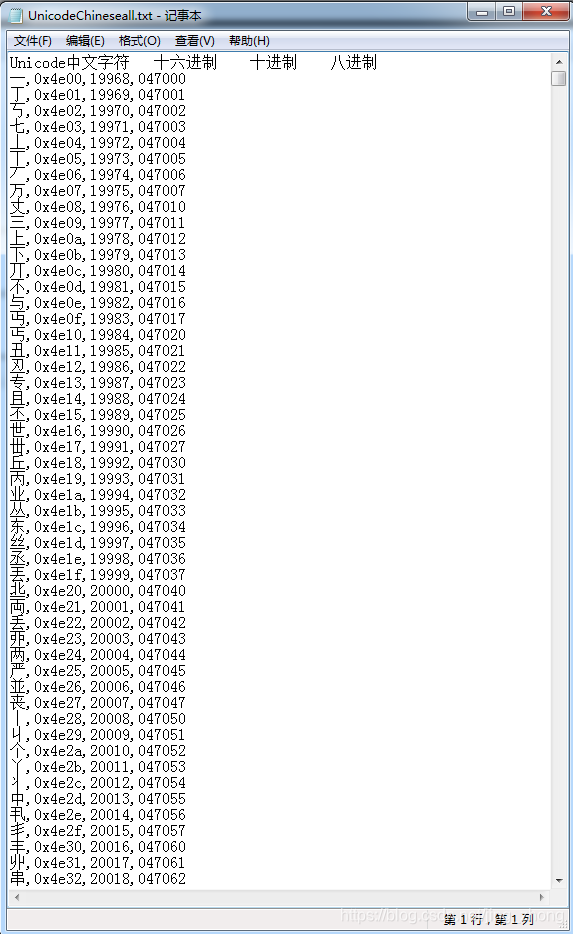
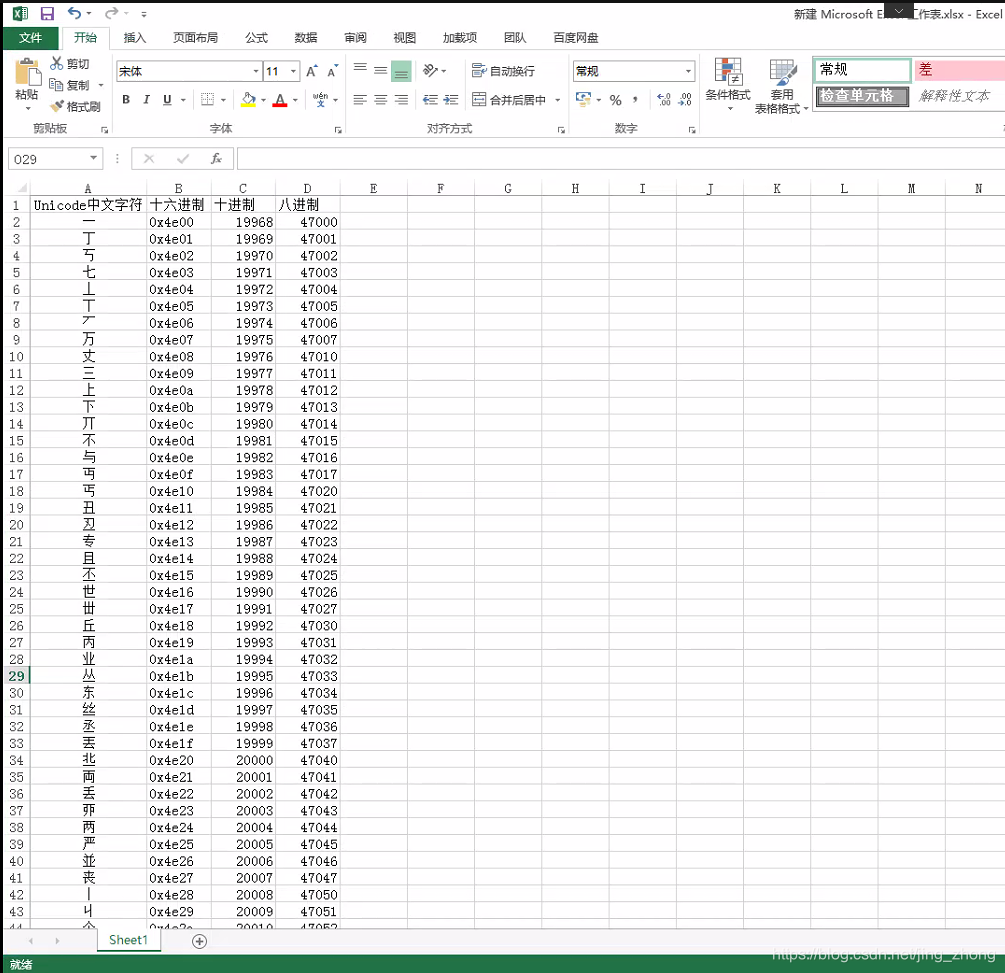
导入到Excel中后如下图所示,便于检索。
3.2 UTF-8
UTF-8 (8-bit Unicode Transformation Format),它是针对Unicode的可变长度字符编码,它在电子邮件、网页及其他存储或传送文字的应用中都被优先采用。UTF-8是UTF中最常用的转换格式,是Unicode的一种变长字符编码,UTF-8用1到6个字节编码Unicode字符。
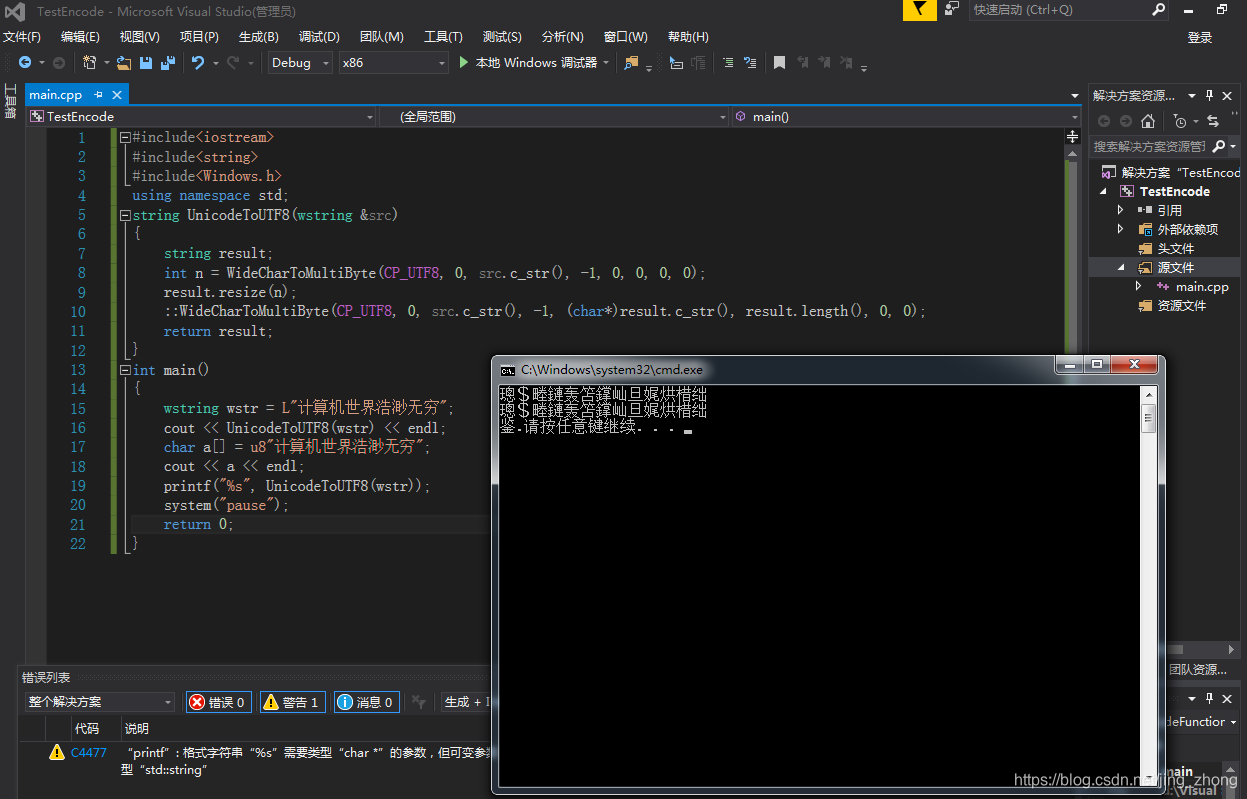
3.2.1 C++ unicodeToUTF-8
#include<iostream>
#include<string>
#include<Windows.h>
using namespace std;
string UnicodeToUTF8(wstring &src)
{
string result;
int n = WideCharToMultiByte(CP_UTF8, 0, src.c_str(), -1, 0, 0, 0, 0);
result.resize(n);
::WideCharToMultiByte(CP_UTF8, 0, src.c_str(), -1, (char*)result.c_str(), result.length(), 0, 0);
return result;
}
int main()
{
wstring wstr = L"计算机世界浩渺无穷";
cout << UnicodeToUTF8(wstr) << endl;
char a[] = u8"计算机世界浩渺无穷";
cout << a << endl;
printf("%s", UnicodeToUTF8(wstr));
system("pause");
return 0;
}
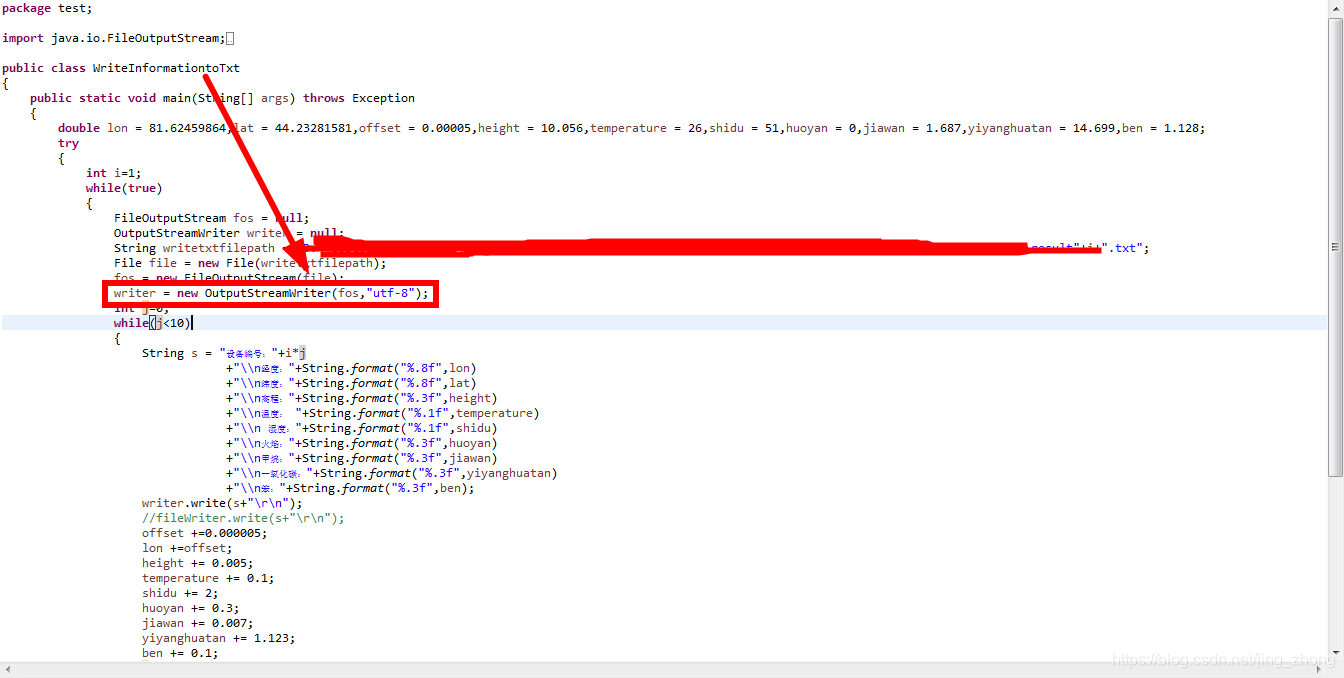
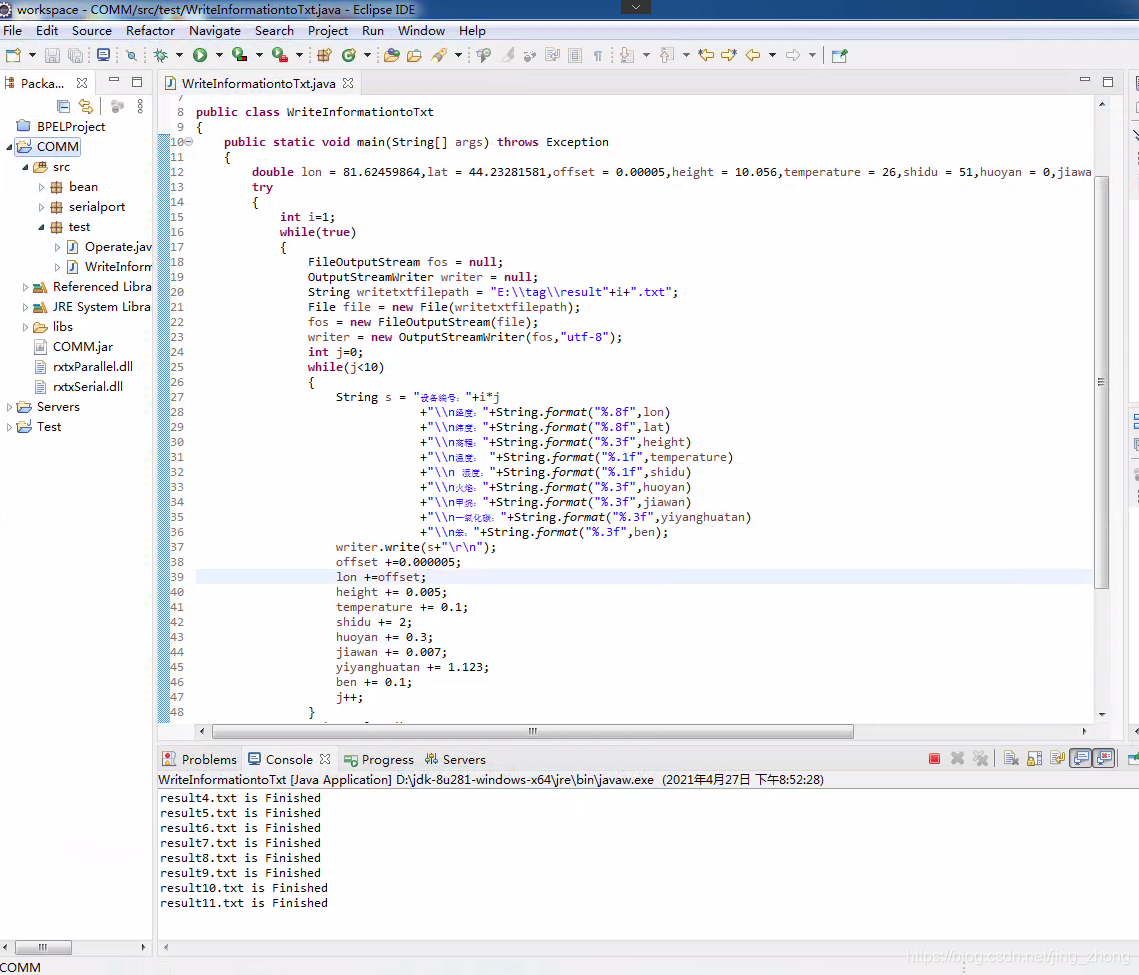
3.2.2 java 保存txt(以utf-8编码)
package test;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.io.File;
public class WriteInformationtoTxt
{
public static void main(String[] args) throws Exception
{
double lon = 81.62459864,lat = 44.23281581,offset = 0.00005,height = 10.056,temperature = 26,shidu = 51,huoyan = 0,jiawan = 1.687,yiyanghuatan = 14.699,ben = 1.128;
try
{
int i=1;
while(true)
{
FileOutputStream fos = null;
OutputStreamWriter writer = null;
String writetxtfilepath = "E:\\tag\\result"+i+".txt";
File file = new File(writetxtfilepath);
fos = new FileOutputStream(file);
writer = new OutputStreamWriter(fos,"utf-8");
int j=0;
while(j<10)
{
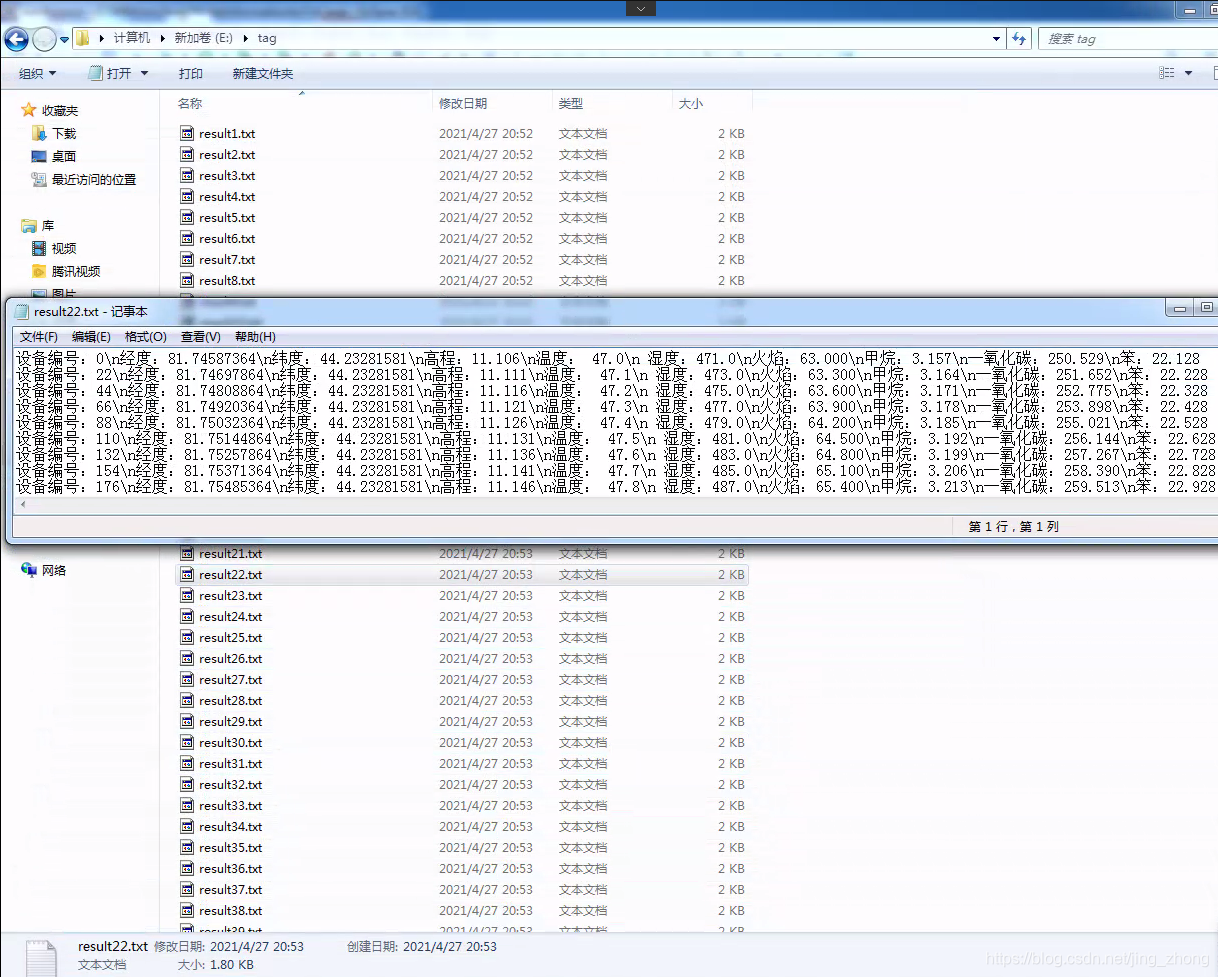
String s = "设备编号:"+i*j
+"\\n经度:"+String.format("%.8f",lon)
+"\\n纬度:"+String.format("%.8f",lat)
+"\\n高程:"+String.format("%.3f",height)
+"\\n温度: "+String.format("%.1f",temperature)
+"\\n 湿度:"+String.format("%.1f",shidu)
+"\\n火焰:"+String.format("%.3f",huoyan)
+"\\n甲烷:"+String.format("%.3f",jiawan)
+"\\n一氧化碳:"+String.format("%.3f",yiyanghuatan)
+"\\n笨:"+String.format("%.3f",ben);
writer.write(s+"\r\n");
offset +=0.000005;
lon +=offset;
height += 0.005;
temperature += 0.1;
shidu += 2;
huoyan += 0.3;
jiawan += 0.007;
yiyanghuatan += 1.123;
ben += 0.1;
j++;
}
writer.close();
fos.close();
System.out.println("result"+i+".txt is Finished");
Thread.sleep(2000);
i++;
}
}catch (IOException e)
{
e.printStackTrace();
}
}
}
3.2.3 C#向utf-8编码的txt追加内容
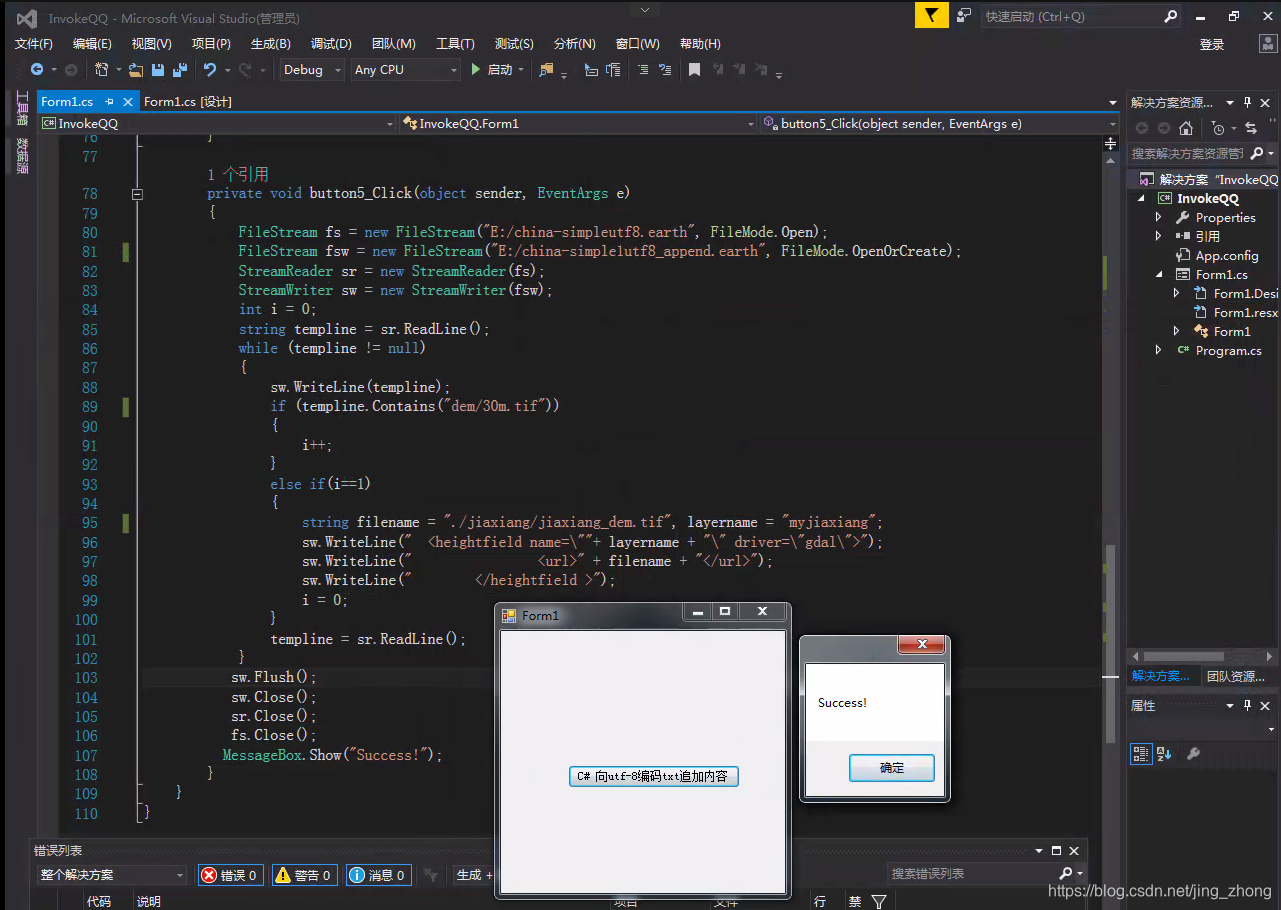
private void button5_Click(object sender, EventArgs e)
{
FileStream fs = new FileStream("E:/china-simpleutf8.earth", FileMode.Open);
FileStream fsw = new FileStream("E:/china-simple1utf8_append.earth", FileMode.OpenOrCreate);
StreamReader sr = new StreamReader(fs);
StreamWriter sw = new StreamWriter(fsw);
int i = 0;
string templine = sr.ReadLine();
while (templine != null)
{
sw.WriteLine(templine);
if (templine.Contains("dem/30m.tif"))
{
i++;
}
else if(i==1)
{
string filename = "./jiaxiang/jiaxiang_dem.tif", layername = "myjiaxiang";
sw.WriteLine(" <heightfield name=\""+ layername + "\" driver=\"gdal\">");
sw.WriteLine(" <url>" + filename + "</url>");
sw.WriteLine(" </heightfield >");
i = 0;
}
templine = sr.ReadLine();
}
sw.Flush();
sw.Close();
sr.Close();
fs.Close();
MessageBox.Show("Success!");
}

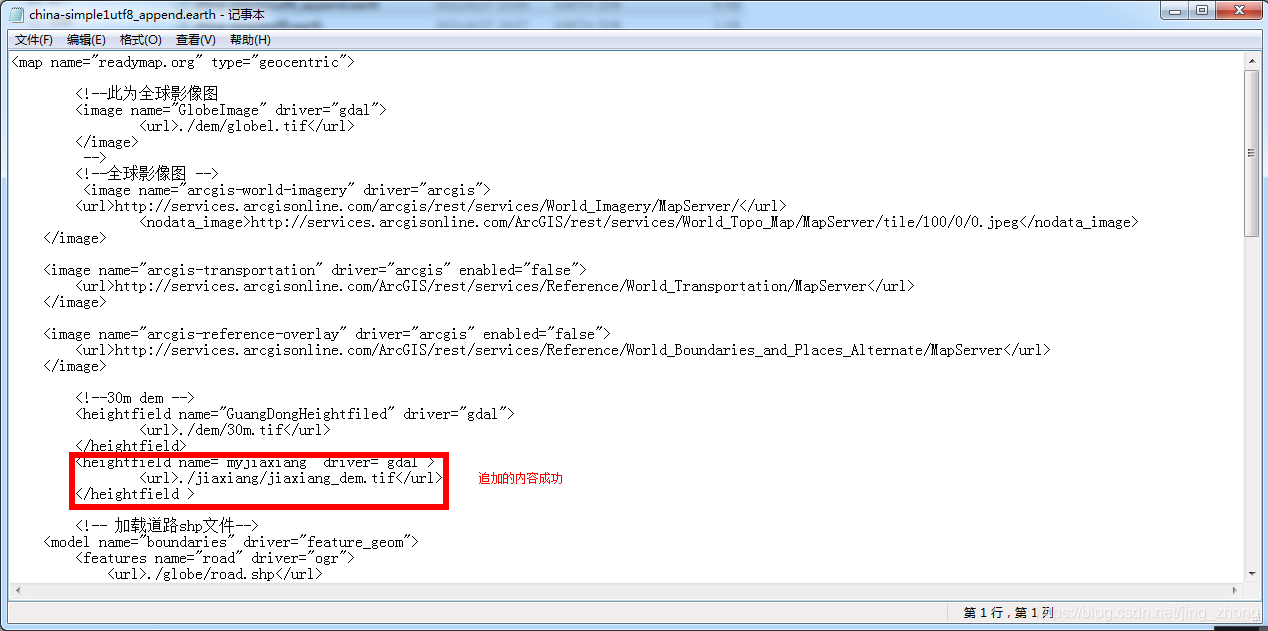
3.3 GBK
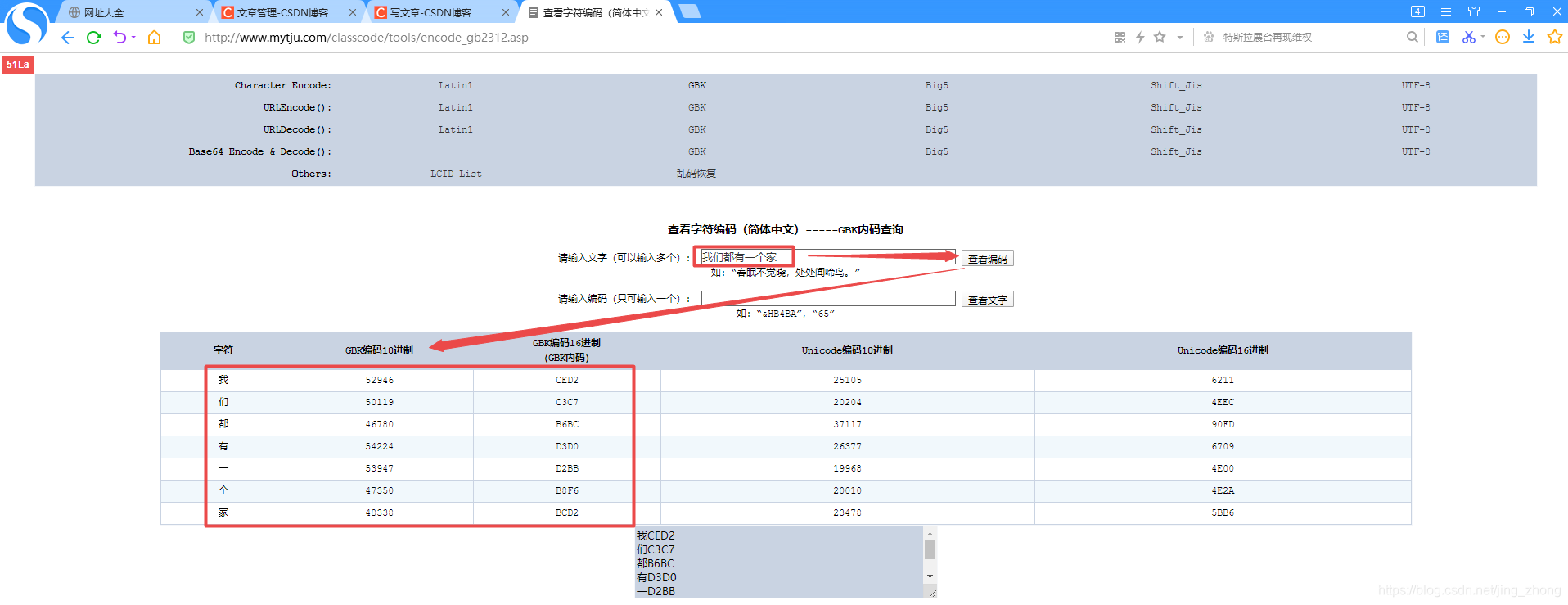
GBK的全称为《汉字内码扩展规范》(GBK即“国标”、“扩展”汉语拼音的第一个字母)英文名称为Chinese Internal Code Specification,GBK是采用单双字节变长编码,英文使用单字节编码,完全兼容ASCII字符编码,中文部分采用双字节编码。GBK 向下与 GB 2312 编码兼容,ISO 10646 是一个包括世界上各种语言的书面形式以及附加符号的编码体系。其中的汉字部分称为“CJK 统一汉字”(C 指中国,J 指日本,K 指朝鲜)。而其中的中国部分,包括了源自中国大陆的 GB 2312、GB 12345、《现代汉语通用字表》等法定标准的汉字和符号。GBK内码在线查询
3.3.1 C++查询汉字的GBK编码
#include<iostream>
#include<string>
#include<vector>
using namespace std;
//获取中文字段GBK编码的函数
vector<unsigned char> EncodeStringToGBK(string s)
{
vector<unsigned char> res;
res.resize(s.length());
memcpy(&res[0], s.c_str(), s.length());
return res;
}
//解码GBK值为中文字段的函数
string DecodeGBKToString(vector<unsigned char> buff)
{
vector<unsigned char> buf1 = buff;
buf1.resize(buff.size() + 1);
string str = (char *)&buf1[0];
return str;
}
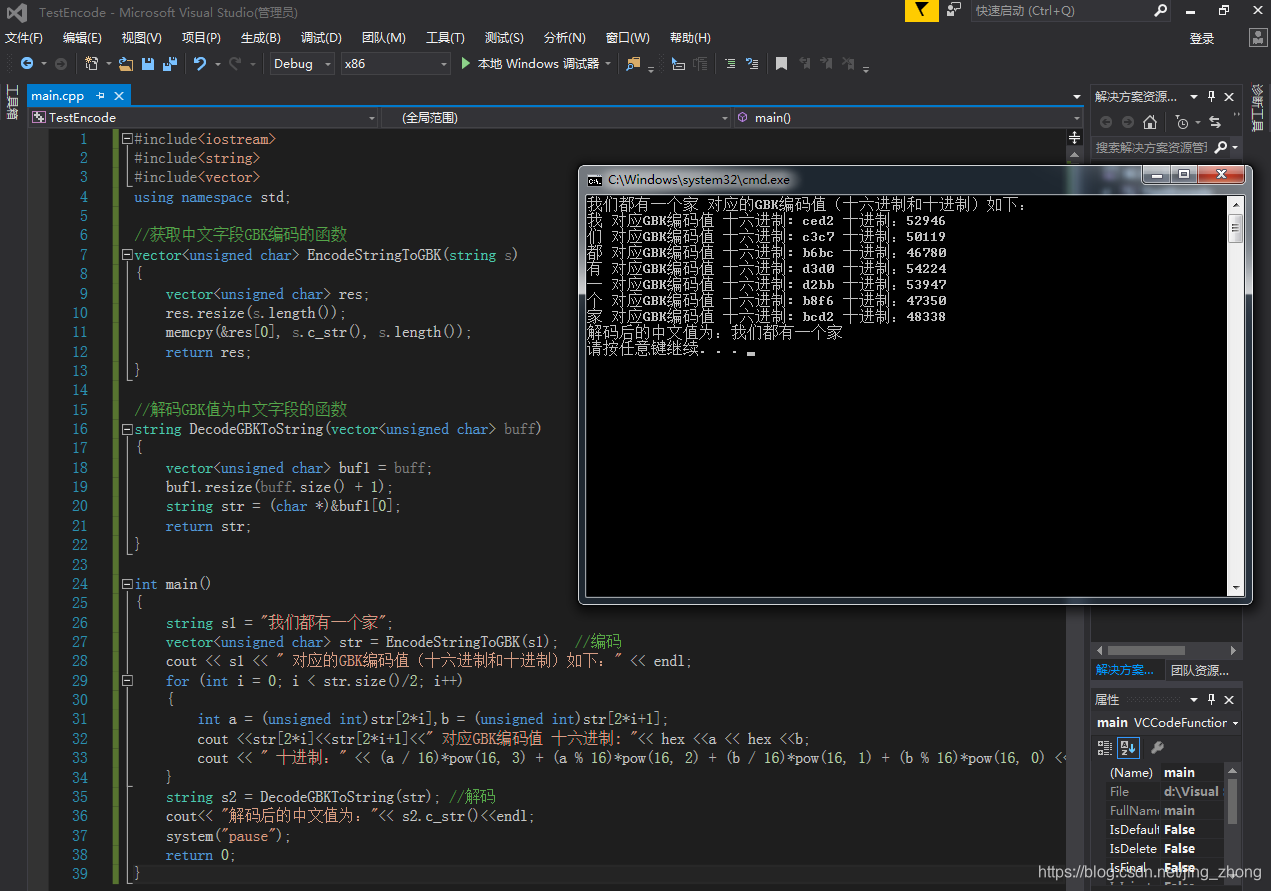
int main()
{
string s1 = "我们都有一个家";
vector<unsigned char> str = EncodeStringToGBK(s1); //编码
cout << s1 << " 对应的GBK编码值(十六进制和十进制)如下:" << endl;
for (int i = 0; i < str.size()/2; i++)
{
int a = (unsigned int)str[2*i],b = (unsigned int)str[2*i+1];
cout <<str[2*i]<<str[2*i+1]<<" 对应GBK编码值 十六进制: "<< hex <<a << hex <<b;
cout << " 十进制:" << (a / 16)*pow(16, 3) + (a % 16)*pow(16, 2) + (b / 16)*pow(16, 1) + (b % 16)*pow(16, 0) << endl;
}
string s2 = DecodeGBKToString(str); //解码
cout<< "解码后的中文值为:"<< s2.c_str()<<endl;
system("pause");
return 0;
}
4、C++操作txt
4.1 C++追加内容到txt文件末尾

#include<iostream>
#include<string>
#include <fstream>
using namespace std;
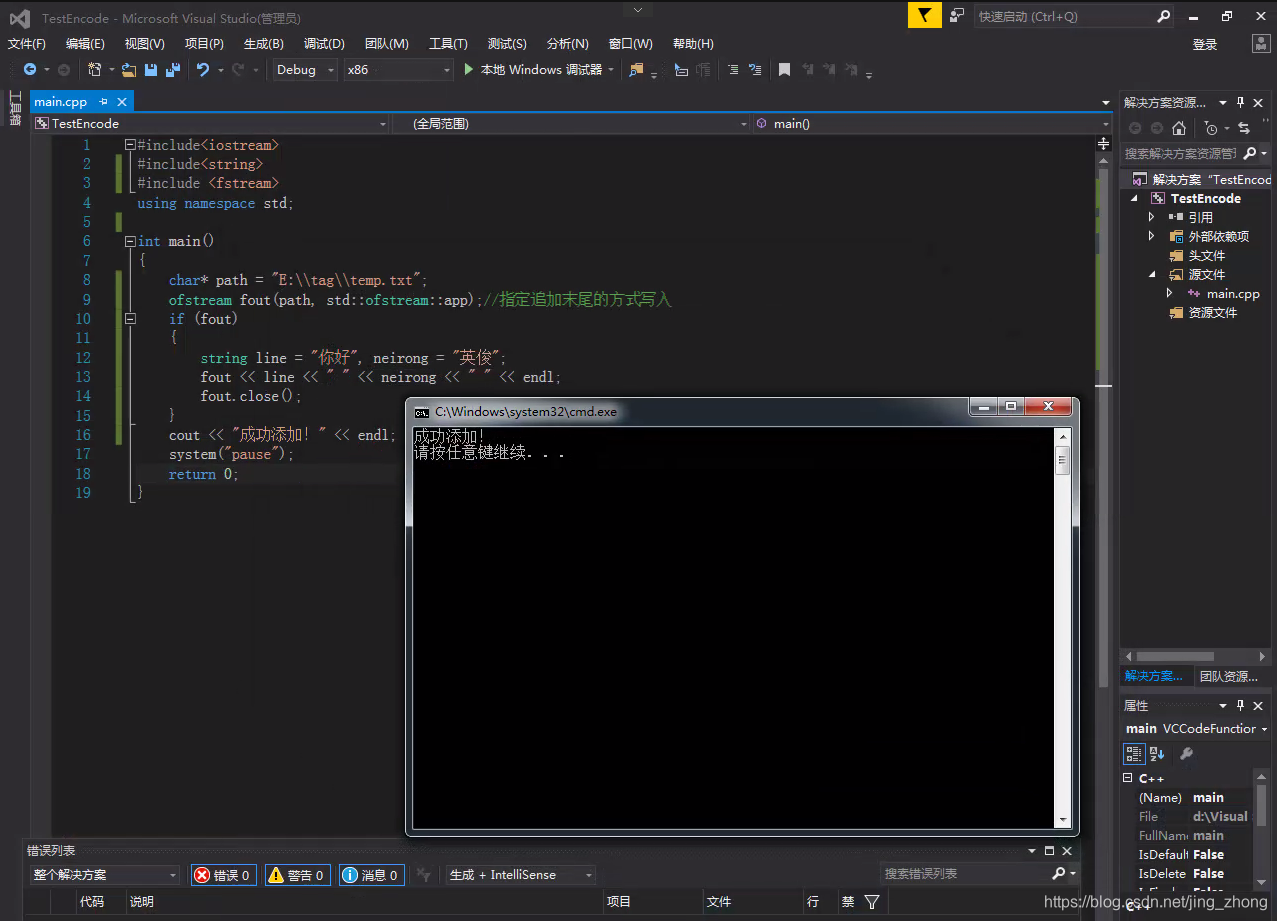
int main()
{
char* path = "E:\\tag\\temp.txt";
ofstream fout(path, std::ofstream::app);//指定追加末尾的方式写入
if (fout)
{
string line = "你好", neirong = "英俊";
fout << line << " " << neirong << " " << endl;
fout.close();
}
cout << "成功添加!" << endl;
system("pause");
return 0;
}

4.2 C++读取txt(空格分隔)

#include<iostream>
#include<string>
#include<vector>
#include <fstream>
using namespace std;
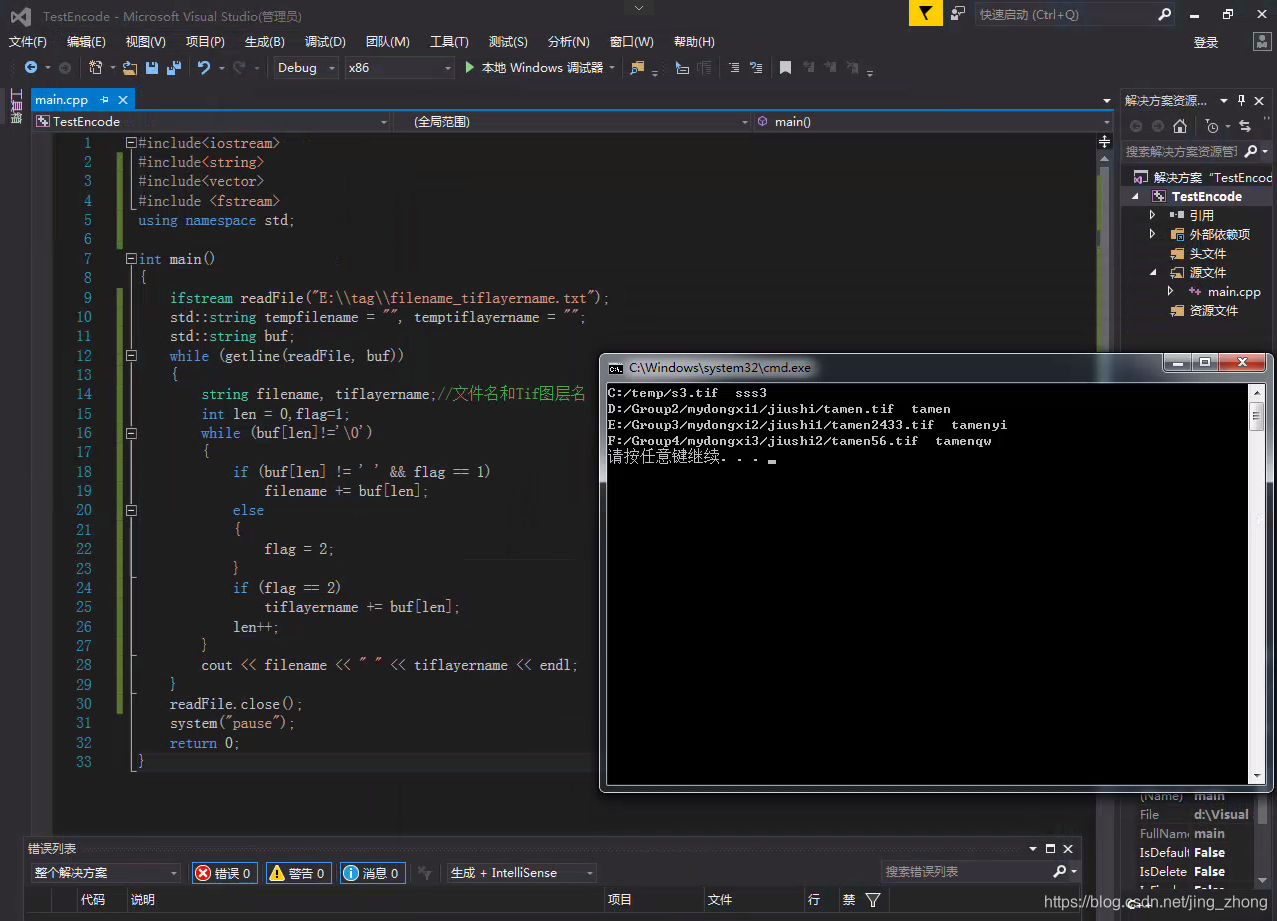
int main()
{
ifstream readFile("E:\\tag\\filename_tiflayername.txt");
std::string tempfilename = "", temptiflayername = "";
std::string buf;
while (getline(readFile, buf))
{
string filename, tiflayername;//文件名和Tif图层名
int len = 0,flag=1;
while (buf[len]!='\0')
{
if (buf[len] != ' ' && flag == 1)
filename += buf[len];
else
{
flag = 2;
}
if (flag == 2)
tiflayername += buf[len];
len++;
}
cout << filename << " " << tiflayername << endl;
}
readFile.close();
system("pause");
return 0;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









