







通过这几天的学习,对主成分分析(PCA)的基本原理有所了解,博文主成分分析(PCA)原理总结写得非常棒,大家可以去与博主一起交流学习。
可能是我基础薄弱,对于“PCA的推导:基于最大投影方差”这部分的理解并不那么直观。我们知道“基于最小投影距离”就是样本点到这个超平面的距离足够近,也就是尽可能保留原数据的信息;而“基于最大投影方差”就是让样本点在这个超平面上的投影能尽可能的分开,也就是尽可能保留原数据之间的差异性。
上述博文中没有提及这个差异性的衡量方式,即为啥W'XX'W可以度量样本的差异性。在另一篇博文向量表示,投影,协方差矩阵,PCA中,先介绍了向量内积的意义,基的概念等,然后推出了差异性的度量方式,最后得出结论:XX'就是X的协方差矩阵,其中对角线元素为各个字段的方差,而非对角线元素表示变量i和变量j两个字段的协方差(具体论述,请参阅原博文)。有了这个了解,下面的推导也就很容易理解了。
为了加深对PCA算法的理解,下面给出第一篇博文中总结的算法流程。
输入:n维样本集D=(x1,x2,...,xm)
输出:n'维样本集D'=(z1,z2,...,zm), 其中n'≤n
1. 对所有样本进行中心化(均值为0):
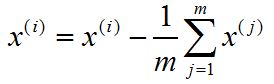
2. 计算样本的协方差矩阵XX'
3. 对协方差矩阵XX'进行特征分解
4. 取出最大的n'个特征值对应的特征向量(w1,w2,...,wn'),对其进行标准化,组成特征向量矩阵W
5. 对于训练集中的每一个样本,进行相应转换:
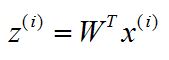
6. 得到输出样本集D'=(z1,z2,...,zm)
备注:有时候,我们不指定降维后的n'的值,而是换种方式,指定一个降维到的主成分比重阈值t。这个阈值t在(0,1]之间。假如我们的n个特征值为λ1≥λ2≥...≥λn,则n'可以通过下式得到:
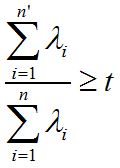















 510
510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









