





 本文介绍了Cache的基本设计原则,包括时间与空间相关性,以及在SRAM、DRAM等不同层次的使用。详细讲解了L1Cache的分类,如指令Cache和数据Cache,并解释了Cache的组成结构,如tag和data部分、cacheline和cacheset的概念。文章还讨论了影响Cachemiss的因素(3C定理)及解决策略,如全相连、直接映射和组相联映射方式。此外,提到了写操作在Cache中的处理,包括写通、写回、写分配和写不分配策略。
本文介绍了Cache的基本设计原则,包括时间与空间相关性,以及在SRAM、DRAM等不同层次的使用。详细讲解了L1Cache的分类,如指令Cache和数据Cache,并解释了Cache的组成结构,如tag和data部分、cacheline和cacheset的概念。文章还讨论了影响Cachemiss的因素(3C定理)及解决策略,如全相连、直接映射和组相联映射方式。此外,提到了写操作在Cache中的处理,包括写通、写回、写分配和写不分配策略。
Cache的一般设计
时间相关性:如果一个数据被访问了,以后很有可能被访问
空间想关性:如果一个数据被访问了,那么它周围数据再以后也可能被访问
sram,dram,disk,flash都可以做cache
L1 cache----sram
指令cache(icache):一般都是读取
数据cache(dcache):读取和写入,支持每周期有多条load/store指令访问
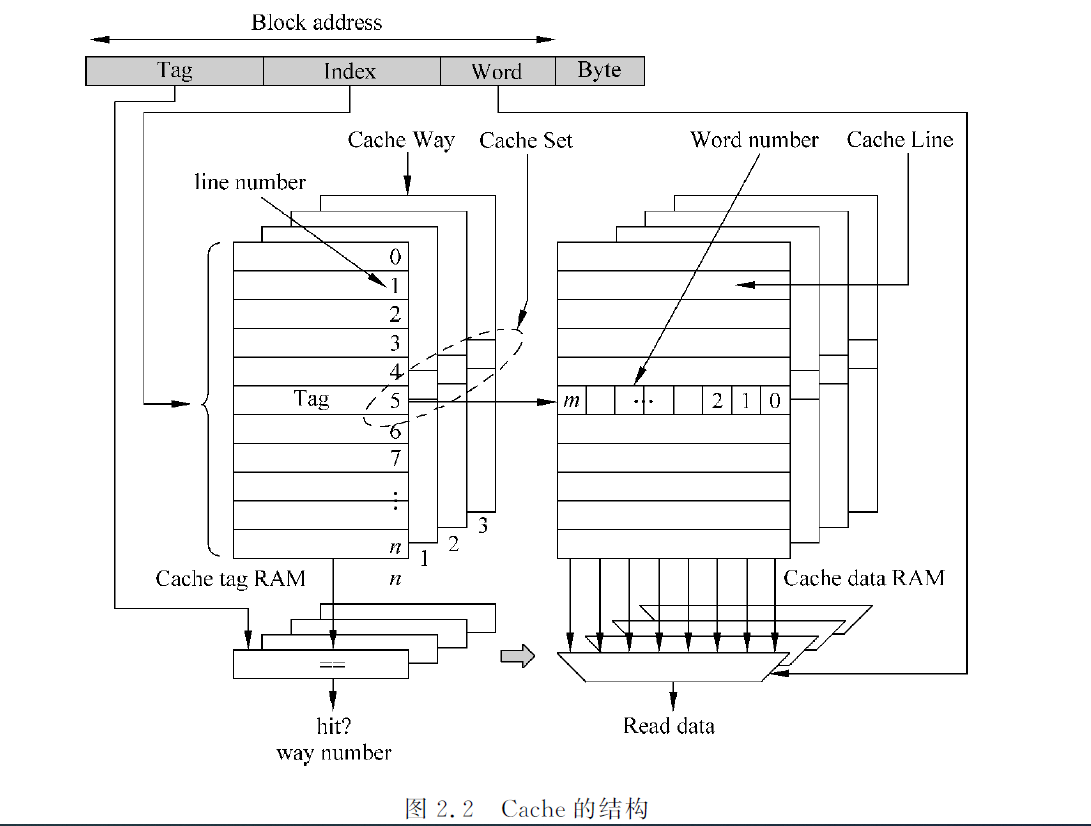
cache有tag和data两部分组成。tag是公共地址,data是一片连续地址的数据
chache line:一个tag和它对应的所有数据组成的一行称为一个cache line
cache set:一个数据可以存储在cache中多个地方,这些被同一个地址找到的多个cache line 称为cache set。
影响cache miss的三个条件,称为3C定理:
1,compulsory强制性,第一次访问肯定miss,可以用预取方法来降低
2,capcity容量,容量越大,命中率越高,但面积也会增加
3,conflict冲突:多个数据映射到cache中同一个位置。解决方式有组相联,victim cache
cache的组成方式:
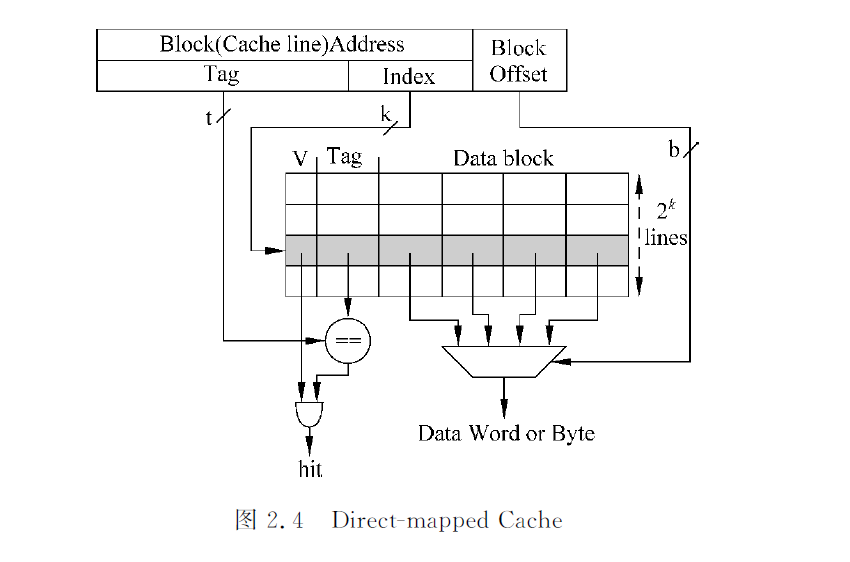
直接映射:易产生冲突,如两个index相同但是tag不同的地址交互访问,会一直miss
全相连:
数据可以放在任意一个cache line中,直接用整个cache中tag进行比较,没有index。直接用存储器内容来寻址,这就是内容寻址存储器(CAM),cam来存储tag值,普通的sram来存储数据。
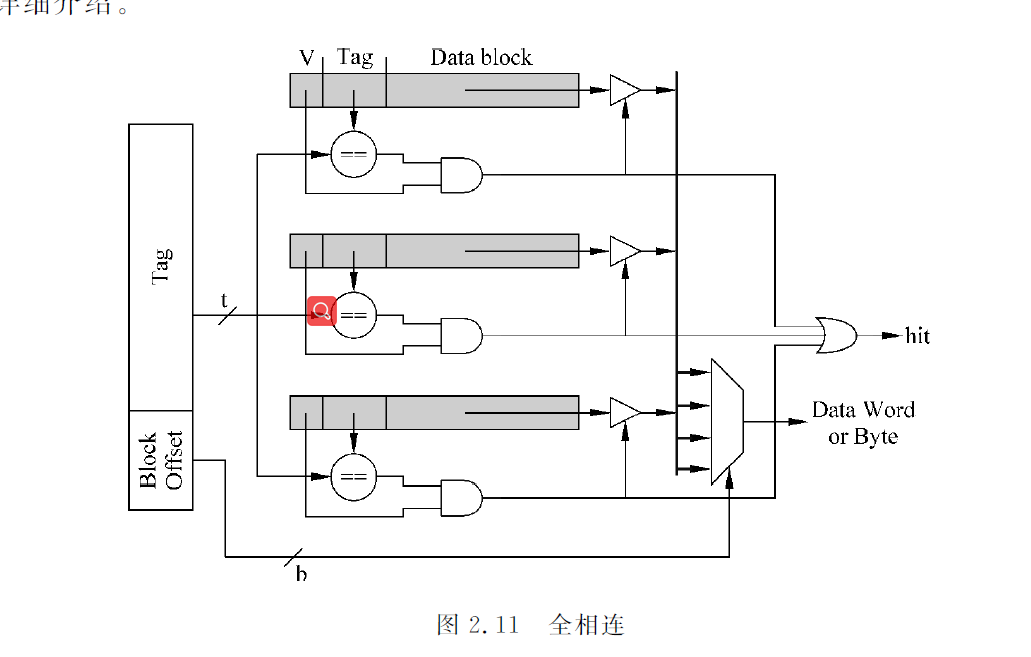
TLB和victim cache多采用全相连结构
组相连:如果一个数据可以放在n个位置,则称为n路组相连
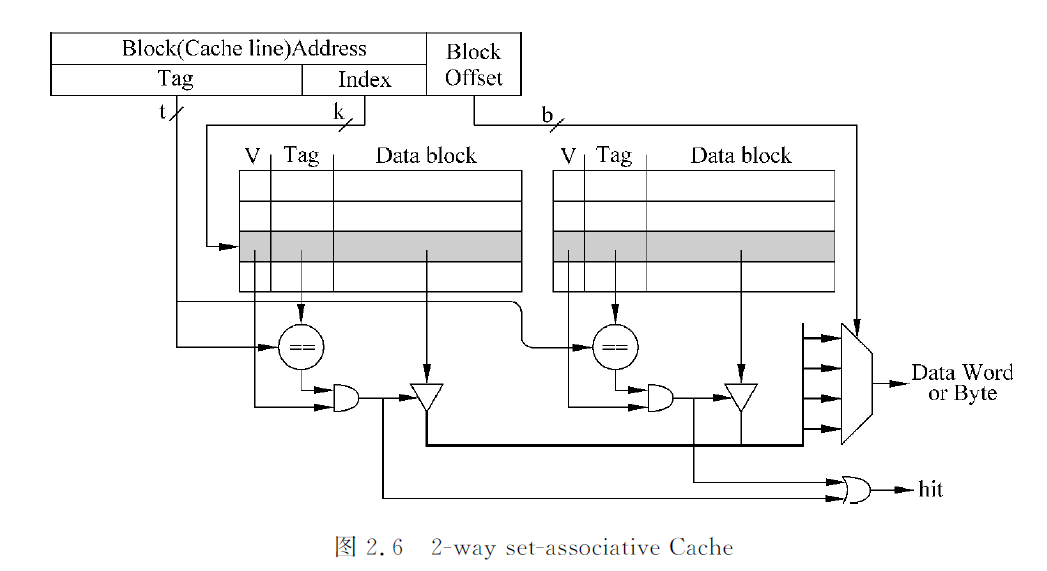
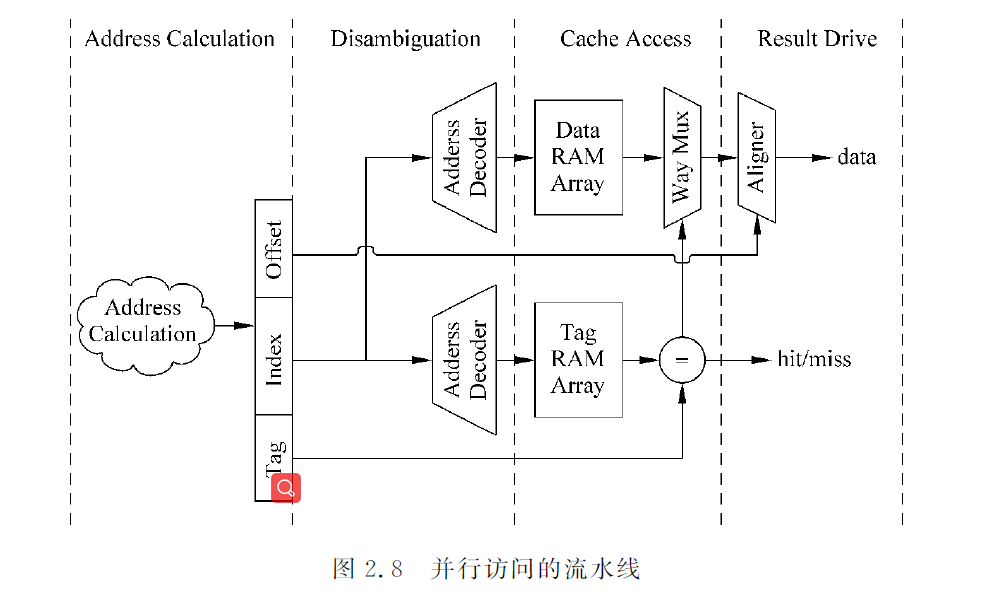
如上图:用index对chache进行寻址,可以得到两个cache line,这两个cache line称为一个cache set。根据tag比较结果才确定哪个cacheline。缺点是延迟会较直接映射大,有时会进行流水线,减少处理器周期时间影响,会导致load指令延迟增大。优点是显著减少了cache miss。
一般tag和data是分开放置的,tag sram和data sram,分两种访问方式:
1,串行访问,先访问tag,根据tag比较结果再去访问data sram
2,并行访问,tag部分的某个地址被读取同时,这个地址对应data也会被读取出来,送到多路选择器,根据tag比较结果,选出对应data block,根据block offset的值,选择出合适的字节。选择字节过程称为数据对齐。
Icache修改:将改写的指令作为数据写道dcache,然后将dcache中内容写入l2 cache(指令和数据共享),并将Icahce中所有内容置为无效,重新从l2 cache取指令到icache。
dcache写入
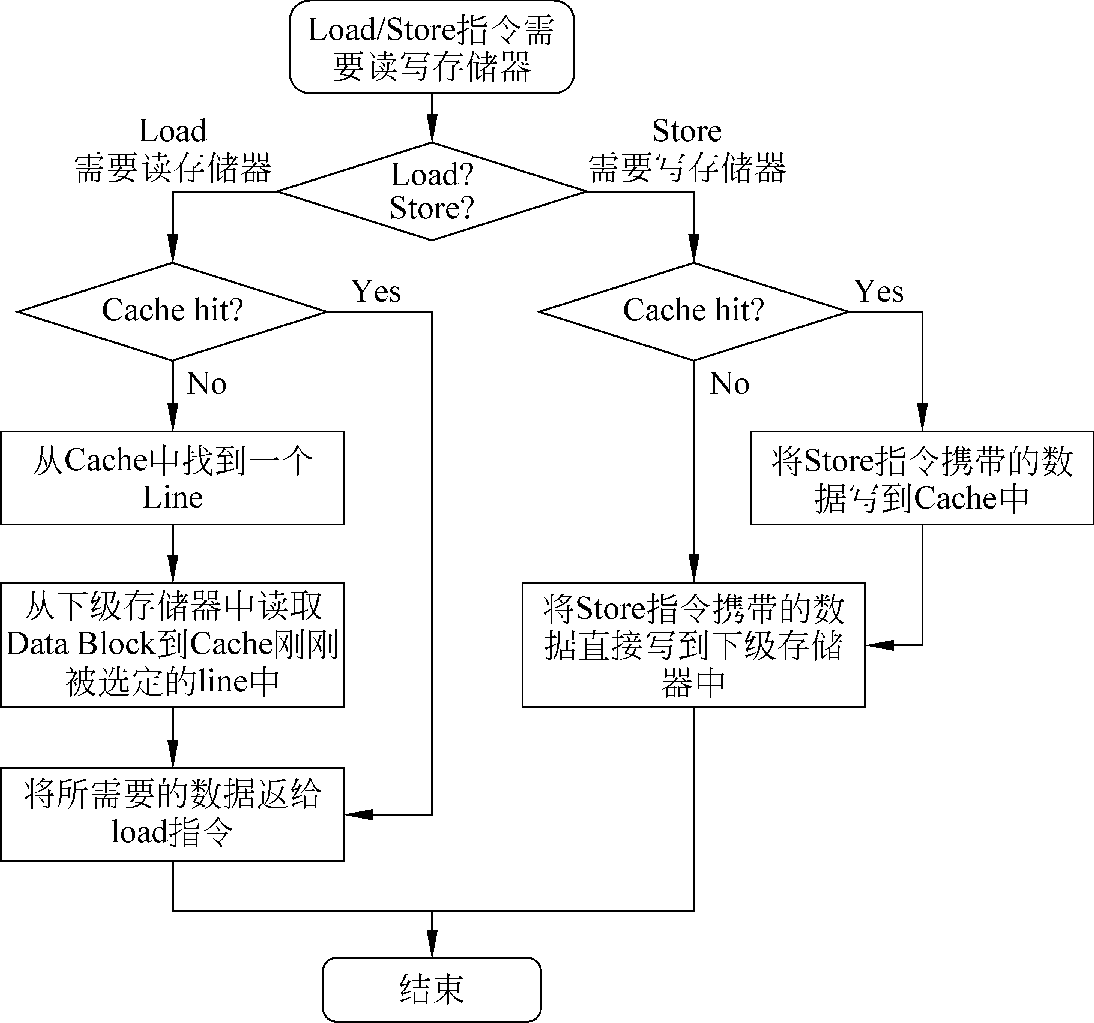
写通 write through:数据写到dcache,也写到下级存储器中
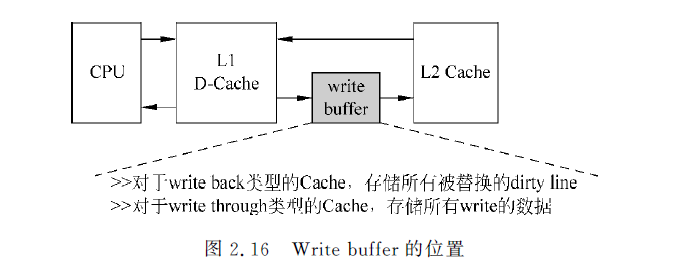
写回 write back:store指令,数据只写到dcache中,做dirty标记,只有当cache 中dirty line被替换时,才写到下级存储器中。优点是快,缺点是数据不一致
写分配 write allocate:如果发生write miss,会首先从下级存储器中将miss的地址对应的整个数据块data block 取出来,然后将要写入到d-cache中的数据合并到这个数据块中,最后将这个被修改过的数据块写到dcache中。
写不分配 Non-write allocate:当地址不在d-cache中,发生write miss,将数据直接写到下级存储器中,不写到d-cache中。
写通和写不分配的流程:
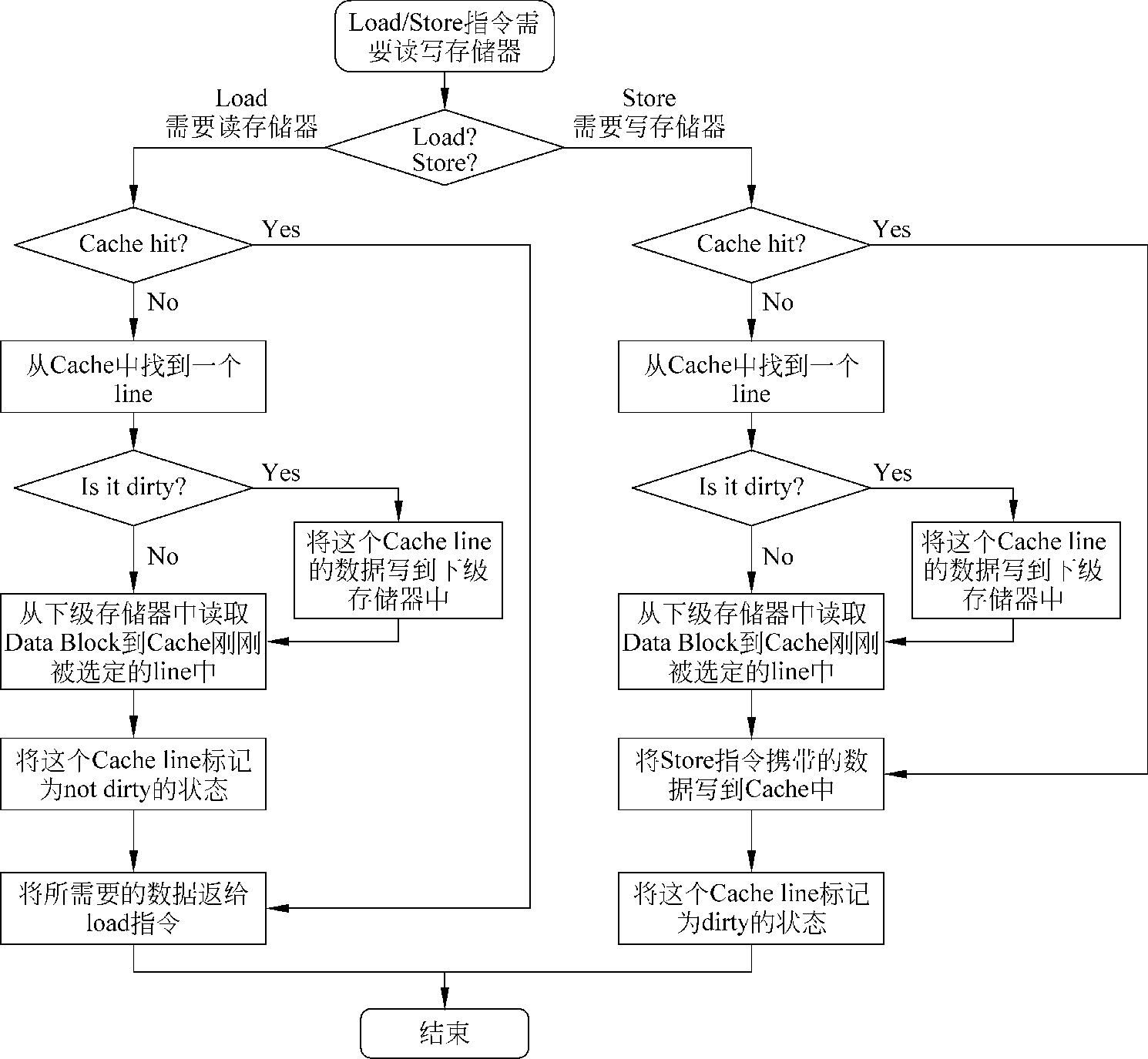
cache的替换策略:LRU和随机替换
提高cache的性能:
写缓存
流水线
多级结构
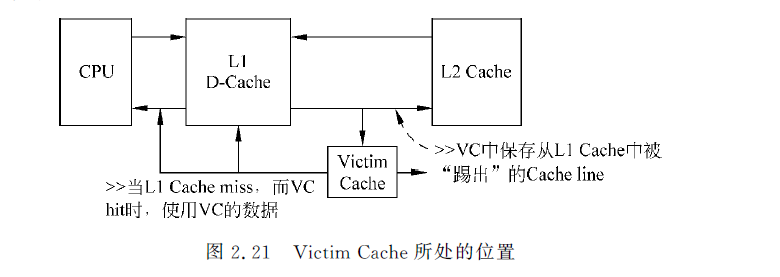
victim cache
全相联,容量比较小,与cache存在互斥的关系。
预取
一般采用多端口bank访问,会引起bank冲突,地址两个,但是数据不用两个。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









