







一直都想看一下底层的实现,每次拿起LInux内核的书都被吓到了,工作上面也没有做相关的东东,所以一直也没有什么进展。看了田园的都江堰的代码,觉得刚起步,代码还算比较清晰,最主要几乎所有的代码都有很多的注释,决定花几天时间好好,看一个操作系统应该怎么写的,下面的一些小节,自己边上网查资料边看书,所以有点乱。
比较一下44b0和2410之间的不同之处,希望对大家有所帮助。
首先是CPU的初始化:
在44b0中,在rominit目录下主要有这样的几个文件:
Initcpu.s
Int.s 中断的一些控制
Memcfg.a : 储存器相关的设置,主要是访问时钟始终
Preload.c
Memcfg.a :44b0 CPU使用一组专用的特殊功能寄存器来控制外部存储器的读/写操作,通过对该组特殊功能寄存器编程,可以设定外部数据总线宽度,访问周期,定时的控制信号(例如RAS和CAS)等参数。这主要通过设置13 个从1c80000(BWSCON)开始的特殊寄存器来设置。0x1c80000 为特殊寄存器的首地址。
BWSCON(0x1c80000): 配置总线宽度 data
Bus Width :8-bit,16-bit, 32-bit
是否使用UB/LB及确定WAIT状态,都是针对SRAM。
BANKCON0-7(0x1c80004-0x1c80020):
访问周期[10:8] Access cycle
存储器的类型[16:15](Bank6,Bank7)
定时Trcd的控制信号
Trcd: RAS to CAS delay
这是用来设定从RAS信号到CAS信号所需的时间周期(Clock)。当CPU 要从内存读取或写入数据时,必须送出一个正确的地址信号,而地址是由行、列交错而成,所以又分为RAS(列地址信号)和CAS(行地址信号),由于是先寻 址RAS、再寻址CAS,因此中间就有延迟时间,建议先设成2个Clock(2T),让SDRAM 能快点将地址寻址完毕,这样可以将内存性能提高;
Tcas: CAS pulse width
Tcp: CAS pre-charge
CAS 表示列地址寻址(Column Address Strobe orColumn Address Select),
RAS 表示行地址寻址(Row Address Strobe )
REFRESH(0x01C80024):DRAM/SDRAM刷新配置:Trp[21:20]: DRAM/SDRAM RAS pre-charge Time设定当RAS(列地址信号)需要重新寻址时,要隔多久时间才能开始下次的寻址动作,通常被视为RAS 的充电时间,理论上是越短越好。其选项值与上面讲到的一样,所以建议将其设定为2T(2 个Clock 周期),这样可以将内存性能提高;若发现系统运行不稳定,再将其改回3T。
Trc [19:18] SDRAM RC minimum Time
这个参数用来控制内存的行周期时间。tRC 决定了完成一个完整的循环所需的最小周期数,也就是从行激活到行充电的时间。
在Memcfg.a,就主要说的是这个存储器相关的一些参数的设置。
Int.s
这里的代码主要是中断的控制,这个,里面主要是M_vector_int这个宏的定义。下面简单的谈谈arm下面的中断处理:
首先ARM芯片要进行中断设置要使能中断向量,然后当有IRQ中断来之后,CPU自动的到0x18地址处取指。0x18处的指令呢是CPU根据中断源算好的(比如:中断EINT4567来了,那么0x18处的指令就是跳转到地址0x30处)。然后就执行“ldr pc,=HandlerEINT4567”这条指令。这条指令的执行结果就是跳转到 “HandlerEINT4567 HANDLER HandleEINT4567”处执行。这条是宏指令,你可以看一下宏定义。执行结果就是跳转到HandleEINT4567处执行。
44B0中断系统中有两张中断转移表,经过二重转移才跳到中断处理程序。第一张中断向量表由硬件决定,所在区域为 ROM(flash),地址空间从 0X00开始,其中0X00-0X1C为异常向量入口地址,0X20-0XC0为中断向量入口地址。另一张中断向量表在RAM中,可以随便改,其位置在程序连接后才定。(这个地方注意subs pc lr #4)
中断也是一种特殊的异常。
如何从第一张中断向量表跳到第二张中断向量表?
由于RAM放在地址空间的高端(距离中断向量超过了32M),故在第一张中断向量表对应位置上写上
ldr PC,# interrupt_service
如:ldr PC,=HandlerEINT4567
其实异常向量就是中断向量,ARM7的内核实际上只有8个(1个保留)异常向量,对于众多的中断源,ARM7的内核是通过IRQ、FRQ的软件查询中断状态寄存器的位来获得ISR的起始地址。而44B0为了克服这种方式所带来的中断延迟,就加入了更多的中断向量表(0x20到0xc0),要使用这种方式,必须在中断控制寄存器中设置每个中断源的方式为IRQ方式,且使用向量中断。我是这样理解的,当中断产生饿之后,首先是跳到0x18处,执行完之后,然后硬件会查询中断的向量表,自动的跳到对应的地方执行。在0x18处,如果不想做什么处理的话,就直接写subs pc,lr,#4,有的时候这里也可以做一些处理的,例如:IsrIRQ程序的作用是检查I_ISPR的各位,判断是何种中断发生,然后根据中断的种类跳转到相应的中断服务程序去执行。
这里我们可以看看M_vector_int是如何定义的,看之前复习一下Arm的中断处理:
Arm处理器有两种中断类型,一个是由外设引起的,即IRQ和FIQ,另外是一条引发中断的指令——SWI指令。两种中断都会挂起正常的执行程序。
系统设计的时候就可决定那些外设可以产生哪种中断请求,我们在编程的时候,我们只需要知道我的外设产生这种中断的的时候,会自动的跳到我所想要的处理程序的地方执行。这里,有一个中断控制器的概念,中断控制器负责连接多个外部中断到ARM两个中断请求。复杂的控制器可以编程来选择外部中断源是IRQ还是FIQ。有一些惯例:首先软件中断通常被保留,用来调用特权操作系统的例程。例如,可以改变在用户模式下运行的程序到特权模式下。IRQ一般分配给通用的中断。FIQ一般给要求快速相应的单个中断源保留。
为了减少中断的延时,中断源得到服务后,尽快的重新允许中断,而不是等到中断处理全部完成。另外中断还有优先级,通过操作中断控制器,忽略同级的或更低优先级的中断。
只有当CPSR中相应的中断屏蔽被清除的时候,才能发生IRQ和FIQ。处理中断之前,继续执行流水线上处于“执行“阶段的指令,有的时候执行可能需要很多周期,过程如下:
1、 处理器切换到对应的模式,表明产生中断
2、 前一个模式的cpsr保存到当前中断模式下的spsr
3、 Pc被保存到当前模式下的lr
4、 关中断 ——在cpsr中禁止IRQhuozheIRQyuFIQ同时禁止
5、 处理器跳转到向量表中的一个特定的入口。
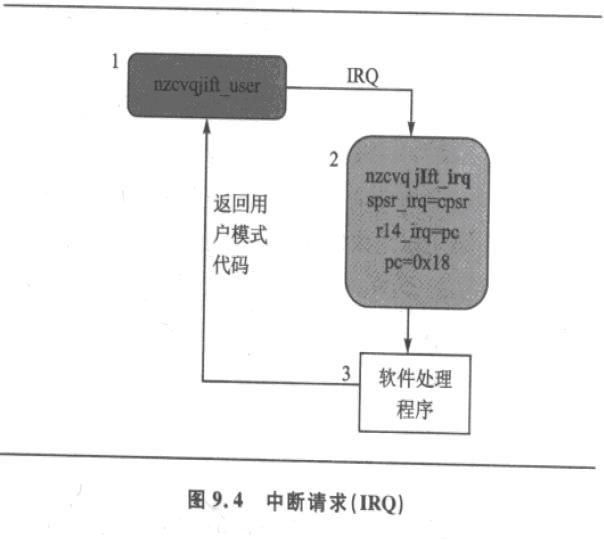
从上图可以看出处理完之后pc=0x18,注意这些处理都是芯片自己做的,不需要代码实现,跳到软件处理程序后,注意返回就行了。
当IRQ产生后,处理器进入状态2,自动的将IRQ置1,关闭其他的IRQ异常。大师,FIQ任然允许。当然你可以手工的修改,让他还可以允许IRQ异常。
与中断相关的还有一个,就是中断堆栈。每一个模式都有专门的寄存器来保存堆栈指针。堆栈设计有两点:位置和大小。这个我们都可以在后面的代码中可以看到。
中断的处理:
对于非嵌套的中断处理,没有必要报讯spsr,因为它不会被其他的东东破坏。一旦进入中断程序,保护上下文之后,处理程序就必须确定中断源,什么产生的中断?因为中断源直接决定我们的处理程序。
如果在一个中断模式下面允许了中断,并且这个中断使用BL调用一个处理程序,,那么这个子程序的返回地址就会被设置到寄存器r14_irq中,如果这个时候这个模式下又产生了一个中断,那么这个值就会被破坏,为了避免这个情况,中断例程应该切换到SVC或者系统模式,那么BL指令可以使用r14_svc来保存子程序的返回地址。我们来看代码;
.macro M_vector_int int_no @中断宏调用
stmfd sp!,{r0-r12,lr} @保护寄存器,以及返回地址,保护返回地址为嵌套
@LR_irq包含中断返回地址
@SP_sys是独立寄存器,无需保护
@r0-r12是被中断的上下文寄存器,如果不是
@嵌套中断,就是用户态上下文
mov r0,#/int_no @r0用于记录中断号,'/'是取宏参数的语法
b start_int
.endm
上面的代码,保护了寄存器和返回地址,并且在ro中放入了中断号,也就是什么样的中断。然后跳入start_int,
@中断相关的栈安排:
@1、IRQ_stack放被中断的上下文,顺序:lr,r12-r0,cpsr,共14字
@2、SVC_stack运行中断服务函数,包括用户编写的中断服务函数。
@3、SYS_stack,除非要在中断里切换上下文,否则无关
start_int:
ldr r9,=I_ISPR @44b0x中断控制器bug
ldr r9,[r9]
cmp r9, #0x0 @I_ISPR=0,说明44b0x 的bug发作.
beq error_int
//首先是看一下有没有bug产生。
//然后备份我们的spsr
mrs r1,spsr
stmfd sp!,{r1} @保护SPSR_irq,以支持中断嵌套
//现在我们的IRQ——STACK中就是:lr,r12-r0,cpsr,
msr cpsr_c,#SVCMODE|NOIRQ @进入SVCMODE,以便允许中断嵌套
//上面的代码实现两个功能,首先是进入svc模式,然后允许新的中断
//进入之后,首先的一点是保护现场
stmfd sp!,{r0-r3,lr} @保存lr_svc,
ldr r2,=user_irq @取异步信号地址
mov lr,pc @这两条指令函数调用(4G空间),调用用户中断处理函数,
ldr pc,[r2] @int_isr_real和int_isr_asyn_signal分别是实时中断和异步
@事件处理函数的入口地址,该函数原型为
@void int_isr_asyn_signal(ucpu_t intn);intn为中断号,
@根据atpcs,intn用r0传递
//把PC保存带lr之后,跳转带user_irq。
//子程序执行完了之后
ldmfd sp!,{r0-r3,lr} @恢复lr_svc,
msr cpsr_c,#IRQMODE|NOINT @更新cpsr,进入IRQ模式并禁止中断
//从svn模式回到IRQ模式。
ldmfd sp!,{r0} @spsr->r0
//把备份的spsr取出来回复
msr spsr_cxsf,r0 @恢复spsr
ldmfd sp!,{r0-r12,lr}
subs pc,lr,#4 @此后,中断被重新打开
//回复寄存器,并且跳转
//当出现bug的时候就执行下面的语句
error_int:
ldr r8,=I_PMST @44b0x中断控制器bug
ldr r9,[r8]
str r9,[r8]
ldmfd sp!,{r0-r12,lr}
subs pc,lr,#4 @此后,中断被重新打开
.ltorg
然后这个文件的下面就是几个中断入口的定义
HandlerADC: M_vector_int CN_irq_line_ADC
HandlerRTC: M_vector_int CN_irq_line_RTC
HandlerUTXD1: M_vector_int CN_irq_line_UTXD1
HandlerUTXD0: M_vector_int CN_irq_line_UTXD0
HandlerSIO: M_vector_int CN_irq_line_SIO
HandlerIIC: M_vector_int CN_irq_line_IIC
HandlerURXD1: M_vector_int CN_irq_line_URXD1
HandlerURXD0: M_vector_int CN_irq_line_URXD0
HandlerTIMER5: M_vector_int CN_irq_line_TIMER5
HandlerTIMER4: M_vector_int CN_irq_line_TIMER4
HandlerTIMER3: M_vector_int CN_irq_line_TIMER3
HandlerTIMER2: M_vector_int CN_irq_line_TIMER2
HandlerTIMER1: M_vector_int CN_irq_line_TIMER1
HandlerTIMER0: M_vector_int CN_irq_line_TIMER0
HandlerUERR01: M_vector_int CN_irq_line_UERR01
HandlerWDT: M_vector_int CN_irq_line_WDT
HandlerBDMA1: M_vector_int CN_irq_line_BDMA1
HandlerBDMA0: M_vector_int CN_irq_line_BDMA0
HandlerZDMA1: M_vector_int CN_irq_line_ZDMA1
HandlerZDMA0: M_vector_int CN_irq_line_ZDMA0
HandlerTICK: M_vector_int CN_irq_line_TICK
HandlerEINT4567:M_vector_int CN_irq_line_EINT4567
HandlerEINT3: M_vector_int CN_irq_line_EINT3
HandlerEINT2: M_vector_int CN_irq_line_EINT2
HandlerEINT1: M_vector_int CN_irq_line_EINT1
HandlerEINT0: M_vector_int CN_irq_line_EINT0
Initcpu.s
Initcpu.s就是我们整个操作系统的入口,前面的两个文件都是为它做准备的。
开始就是几个宏的定义,然后在0x00开始写我们的程序,首先是异常向量表,然后是IRQ和FIQ,这两个地址上面填写的是subs pc,lr,#4,然后从0x20开始就是我们的中断向量表。
到reset_start:,才是我们复位程序的开始;
切换到管理模式,禁止中断,禁止看门狗,设置时钟,然后就是调用memcfg.a中的总线参数的配置。
然后就是一个catch的配置。
然后就是各个模式下面的堆栈地址的制定。
注意这里配置总线的时候:
SMRDATA:
@#*****************************************************************
@#* Memory configuration has to be optimized for best performance *
@#* The following parameter is not optimized. *
@#*****************************************************************
@#*** memory access cycle parameter strategy ***
@# 1) Even FP-DRAM, EDO setting has more late fetch point by half-clock
@# 2) The memory settings,here, are made the safe parameters even at 66Mhz.
@# 3) FP-DRAM Parameters:tRCD=3 for tRAC, tcas=2 for pad delay, tcp=2 for bus load.
@# 4) DRAM refresh rate is for 40Mhz.
@#bank0 16bit BOOT ROM
@#bank1 8bit NandFlash
@#bank2 16bit IDE
@#bank3 8bit UDB
@#bank4 rtl8019
@#bank5 ext
@#bank6 16bit SDRAM
@#bank7 16bit SDRAM
.long 0x11444440
.long ((B0_Tacs<<13)+(B0_Tcos<<11)+(B0_Tacc<<8)+(B0_Tcoh<<6)+(B0_Tah<<4)+(B0_Tacp<<2)+(B0_PMC)) @ GCS0
.long ((B1_Tacs<<13)+(B1_Tcos<<11)+(B1_Tacc<<8)+(B1_Tcoh<<6)+(B1_Tah<<4)+(B1_Tacp<<2)+(B1_PMC)) @ GCS1
.long ((B2_Tacs<<13)+(B2_Tcos<<11)+(B2_Tacc<<8)+(B2_Tcoh<<6)+(B2_Tah<<4)+(B2_Tacp<<2)+(B2_PMC)) @ GCS2
.long ((B3_Tacs<<13)+(B3_Tcos<<11)+(B3_Tacc<<8)+(B3_Tcoh<<6)+(B3_Tah<<4)+(B3_Tacp<<2)+(B3_PMC)) @ GCS3
.long ((B4_Tacs<<13)+(B4_Tcos<<11)+(B4_Tacc<<8)+(B4_Tcoh<<6)+(B4_Tah<<4)+(B4_Tacp<<2)+(B4_PMC)) @ GCS4
.long ((B5_Tacs<<13)+(B5_Tcos<<11)+(B5_Tacc<<8)+(B5_Tcoh<<6)+(B5_Tah<<4)+(B5_Tacp<<2)+(B5_PMC)) @ GCS5
.ifc "DRAM",BDRAMTYPE
.long ((B6_MT<<15)+(B6_Trcd<<4)+(B6_Tcas<<3)+(B6_Tcp<<2)+(B6_CAN)) @ GCS6 check the MT value in parameter.a
.long ((B7_MT<<15)+(B7_Trcd<<4)+(B7_Tcas<<3)+(B7_Tcp<<2)+(B7_CAN)) @ GCS7
.else
.long ((B6_MT<<15)+(B6_Trcd<<2)+(B6_SCAN)) @ GCS6
.long ((B7_MT<<15)+(B7_Trcd<<2)+(B7_SCAN)) @ GCS7
.endif
.long ((REFEN<<23)+(TREFMD<<22)+(Trp<<20)+(Trc<<18)+(Tchr<<16)+REFCNT) @ REFRESH RFEN=1, TREFMD=0, trp=3clk, trc=5clk, tchr=3clk,count=1019
.long 0x10 @ SCLK power down mode, BANKSIZE 32M/32M
.long 0x20 @ MRSR6 CL=2clk
.long 0x20 @ MRSR7
.end
连续十三个寄存器的配置,可以参考datasheet。堆栈配置完成之后就跳转到:
load_preload,这个函数是C语言实现的。
上面是都江堰操作系统在44b0上面启动时候的代码。
下面我们来看一下2410是如何做的:
在rominit目录下面有这样的几个文件:
2410addr.s 2410上面以及特殊寄存器的地址。
initcpu.s
int.s
Option.a //主要是一个时钟的设置和两个宏的定义,考虑到thumb下面的跳转。
2410addr.s:这个就是2410上面一些特殊寄存器的地址。有些我们在44b0上面看不到的东东。DMA的控制寄存器,LCD CONTROLLER,NAND flash,UART,PWM TIMER,USB DEVICE,IIC,IIS,I/O PORT,RTC,ADC,SPI,SD Interface,ISR,PENDING BIT基本上2410片内的一些基本的寄存器都有了。我们对其中的几项简单的说明一下:
DMA的含义:Direct Memory Acess ,可以不通过CPU而在DMA控制器的控制下,高速地和I/O设备和存储器之间交换数 据。
虽然,我们的启动代码中并没有对DMA进行初始化工作,但是这里我们还是简单的介绍一下。
S3C2410A支持4通道DMA,在以下四种情况可运行
① 源设备和目标都在系统总线AHB上
② 源设备和目标都在外围总线APB上
③ 源设备在系统总线,而目标设备位于外围总线
④ 源设备在外围总线,而目标设备位于系统总线
3. 传输协议
① 单步模式:一次DMA传输有两个DMA应答周期(产生两个应答信号nXDACK)指示DMA读和写周期,主要用与测试和调试模式,在读写周期之前,总线控制权可以让给其他总线控制器
② 连续模式:一次DMA请求将产生连续的的DMA传输,直到规定的DMA传输数据传输完,在DMA传输周期间,nXDACK一直有效。DMA请求信号被释放。并且每次传输一个数据单元后,释放一次总线控制权,以让其他总线控制器有机会可以占有总线。
2410共有四条DMA通道,每条通道5个请求源。
Ch0:nXDREQ0,UART0,SDI,Timer,USB EP1
Ch1: nXDREQ1,UART1,I2SSDI,SPI0,USB EP2
Ch2:I2SSDO,I2SSDI,SDI,Timer, USB EP3
Ch3:UART1,SDI,SPI1,Timer, USB EP4
软件模式: 由firmware直接设置所有的dma寄存器进行配置,一般会在设定某个channel的enbale bit后就开始运行。 硬件模式(流模式) 首先也需要使用firmware对dma寄存器进行一定的设置,但是此时在设定channel的enable bit后不会立即启动,一般要等到带有dmareq的slave请求后,才会开始传输。而且按照你先前的配置,dma进行完一次传输(指从source读 到fifo再从fifo写到destination后),发出ack信号,表示一次传输完成。然后,即使总的数据仍然没有传输完成,dma也不会对主动进 行下一次传输,而仍然需要source slave重新提出dmareq,反复多次,直到所有的数据传输完毕,dma在最后一次除了会产生ack信号,同时还assert tc信号,表示总的传输完毕。在这种模式下,又分source,destination or dma作为flow controller,然后因为flow controller的不同,传输的数据总量由slave,或是dma来设定。这些情况中,他们的握手信号有些不一样。 另外,还有一个链接表方式可用。
S3c44b0x采用ARM7TDMI核,具有4 通道的DMA控制器,并且对应有4个中断。其中两个DMA通道称做ZDMA(通用DMA),连接在SSB(系统总线)上,另外两个DMA通道称做 BDMA(桥DMA),连接于SSB和SPB(外设总线)之间的接口层。连接于SSB上的ZDMA控制器可以用于从存储器到存储器,从存储器到固定目标的 I/O存储器,和从I/O 设备到存储器之间的数据传输。另外的两个BDMA 控制器主要作用是在外部存储器和内部外设之间传输数据,这里的I内部外设包括SIO,IIS,TIMER和UART等。BDMA与ZDMA可以通过软件启 动,也可以通过硬件启动。此设计中我们使用UART0,与其对应的DMA通道为BDMA0。
关于DMA这一块和我们的驱动相关,这里先不多说,因为和我们的系统移植没有直接的联系。
后面还有一些特殊的功能模块,这里先放一下,以后见到了在仔细的看看。
Option.a:关于时钟,我这里有2440的datasheet,可以知道
S3C2440有三个时钟FLCK、HCLK和PCLK,
FLCK:内核的时钟。
HCLK is used for AHB bus, which is used by the ARM920T, the memory controller, the interrupt controller, the LCD controller, the DMA and USB host block. 总线时钟,DMA等包含USB。
PCLK is used for APB bus, which is used by the peripherals such as WDT, IIS, I2C, PWM timer, MMC interface,ADC, UART, GPIO, RTC and SPI
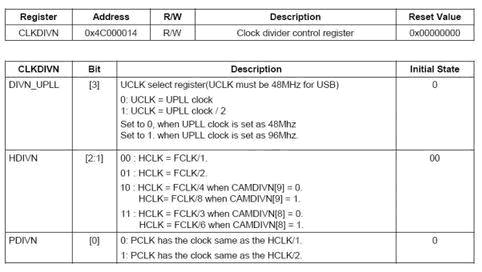
这三个时钟通常设置为1:4:8,1:3:6的分频关系,也就说如果主频FLCK是400MHz,按照1:4:8的设置,那么HLCK是100MHz,PLCK是50MHz
寄存器CLKDIVN表明并设置了这三个时钟的关系
输入时钟FIN与主频FCLK的关系:
现代的CPU基本上都使用了比主频低的多的时钟输入,在CPU内部使用锁相环进行倍频。对于S3C2440,常用的输入时钟FIN有两种:12MHz和16.9344MHz,那么CPU是如何将FIN倍频为FCLK的呢?
S3C2440使用了三个倍频因子MDIV、PDIV和SDIV来设置将FIN倍频为MPLL,也就是FCLK
MPLL=(2*m*FIN)/(p*2^s) where m=(MDIV+8), p=(PDIV+2), s=SDIV
寄存器MPLLCON就是用来设置倍频因子的
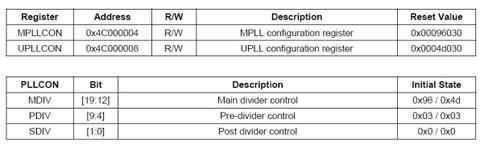
理论上,你可以通过设置该寄存器来实现不同的频率,然而,由于实际存在的各种约束关系,设置一个适当的频率并不容易,手册上列出了一些常用频率的表格,

例如,假设输入时钟FIN=16.9344M,MDIV=110, PDIV=3, SDIV=1,
利用上面的公式,FCLK=2*16.9344*(110+8)/((2+3)*2)=399.65
关于USB时钟
S3C2440有两个锁相环,一个主锁相环MPLL提供给FCLK的,另外一个UPLL是提供给USB时钟(48MHz)的,与MPLL一样,UPLL的产生也是通过UPLLCON寄存器设置分频因子得到,计算公式稍有不同:
UPLL=(m*FIN)/(p*2^s) where m=(MDIV+8), p=(PDIV+2), s=SDIV,同样,可以通过查表得到一个合适的值。
最后值得一提的是,在CLKDIVN的第三位DIVN_UPLL用来设置USB时钟UCLK和UPLL的关系,如果UPLL已经是48Mhz了,那么这一位应该设置为0,表示1:1的关系,否则是1:2的关系
int.s:主要是中断的处理,我们可以参考44b0,看代码:
start_int:
stmfd sp!,{r0-r12,lr} @保护寄存器,以及返回地址
ldr r0,=INTOFFSET
ldr r0,[r0]
mrs r1,spsr
stmfd sp!,{r1} @保护SPSR_irq,以支持中断嵌套
msr cpsr_c,#SVCMODE|NOIRQ @进入SVCMODE,以便允许中断嵌套
stmfd sp!,{r0-r3,lr} @保存lr_svc,
ldr r2,=user_irq @取异步信号地址
mov lr,pc @这两条指令模拟函数调用(4G空间),调用用户中断处理函数,
ldr pc,[r2] @int_isr_real和int_isr_asyn_signal分别是实时中断和异步
@事件处理函数的入口地址,该函数原型为
@void int_isr_asyn_signal(ucpu_t intn);intn为中断号,
@根据atpcs,intn用r0传递
ldmfd sp!,{r0-r3,lr} @恢复lr_svc,
msr cpsr_c,#IRQMODE|NOINT @更新cpsr,进入IRQ模式并禁止中断
ldmfd sp!,{r0} @spsr->r0
msr spsr_cxsf,r0 @恢复spsr
ldmfd sp!,{r0-r12,lr}
subs pc,lr,#4 @此后,中断被重新打开
注释的已经很清楚了。下面就是我们的程序入口文件了。
Initcpu.s:
_start:
b reset_start @ handlerReset
b except_undef @ handlerUndef
b except_swi @ SWI interrupt handler
b except_pabort @ handlerPAbort
b except_dabort @ handlerDAbort
b . @ handlerReserved
b start_int @ handlerIRQ//可以看到这里与44b0的差别了。
b . @ fiq no use//没有使用快速中断
//44b0通过两级,并且自动查找中断向量表,自动跳转,因为44b0的速度没有2410块,这种处理可以提高cpu的效率。然而2410却完全没有这种概念。这里基本与44B0差不多,但是有一点区别,因为2410带有MMU,因而必须要对它进行初始化。
在看代码之前,先简单的了解一下MMU。
MMU,全称Memory Manage Unit, 中文名——存储器管理单元。
首先要搞清楚为什么要出现MMU。
MMU产生的原因就是程序变大了,内存不够。应用程序太大以至于内存容纳不下该程序,通常解决的办法是把程序分割成许多称为覆盖块(overlay)的片段。覆盖块0首先运行,结束时他将调用另一个覆盖块。虽然覆盖块的交换是由OS完成的,但是必须先由程序员把程序先进行分割,这是一个费时费力的工作,而且相当枯燥。人们必须找到更好的办法从根本上解决这个问题。不久人们找到了一个办法,这就是虚拟存储器(virtual memory).虚拟存储器的基本思想是程序,数据,堆栈的总的大小可以超过物理存储器的大小,操作系统把当前使用的部分保留在内存中,而把其他未被使用 的部分保存在磁盘上。比如对一个16MB的程序和一个内存只有4MB的机器,OS通过选择,可以决定各个时刻将哪4M的内容保留在内存中,并在需要时在内存和磁盘间交换程序片 段,这样就可以把这个16M的程序运行在一个只具有4M内存机器上了。而这个16M的程序在运行前不必由程序员进行分割。
任何时候,计算机上都存在一个程序能够产生的地址集合,我们称之为地址范围。这个范围的大小由CPU的位数决定,例如一个32位的CPU,它的地址范围是 0~0xFFFFFFFF (4G),而对于一个64位的CPU,它的地址范围为0~0xFFFFFFFFFFFFFFFF (64T).这个范围就是我们的程序能够产生的地址范围,我们把这个地址范围称为虚拟地址空间,该空间中的某一个地址我们称之为虚拟地址。与虚拟地址空间 和虚拟地址相对应的则是物理地址空间和物理地址,大多数时候我们的系统所具备的物理地址空间只是虚拟地址空间的一个子集,这里举一个最简单的例子直观地说 明这两者,对于一台内存为256MB的32bit x86主机来说,它的虚拟地址空间范围是0~0xFFFFFFFF(4G),而物理地址空间范围是 0x000000000~0x0FFFFFFF(256MB)。
在没有使用虚拟存储器的机器上,虚拟地址被直接送到内存总线上,使具有相同地址的物理存储器被读写。而在使用了虚拟存储器的情况下,虚拟地址不是被直接送 到内存地址总线上,而是送到内存管理单元——MMU(主角终于出现了:])。他由一个或一组芯片组成,一般存在与协处理器中,其功能是把虚拟地址映射为物 理地址。
大多数使用虚拟存储器的系统都使用一种称为分页(paging)。虚拟地址空间划分成称为页(page)的单位,而相应的物理地址空间也被进行划分,单位 是页框(frame).页和页框的大小必须相同。接下来配合图片我以一个例子说明页与页框之间在MMU的调度下是如何进行映射的
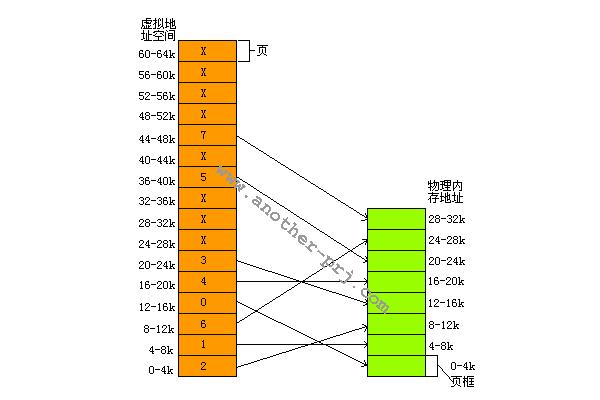
在这个例子中我们有一台可以生成16位地址的机器,它的虚拟地址范围从0x0000~0xFFFF(64K),而这台机器只有32K的物理地址,因此他可 以运行64K的程序,但该程序不能一次性调入内存运行。这台机器必须有一个达到可以存放64K程序的外部存储器(例如磁盘或是FLASH),以保证程序片 段在需要时可以被调用。在这个例子中,页的大小为4K,页框大小与页相同(这点是必须保证的,内存和外围存储器之间的传输总是以页为单位的),对应64K 的虚拟地址和32K的物理存储器,他们分别包含了16个页和8个页框。
我们先根据上图解释一下分页后要用到的几个术语,在上面我们已经接触了页和页框,上图中绿色部分是物理空间,其中每一格表示一个物理页框。橘黄色部分是虚 拟空间,每一格表示一个页,它由两部分组成,分别是Frame Index(页框索引)和位p(present 存在位),Frame Index的意义很明显,它指出本页是往哪个物理页框进行映射的,位p的意义则是指出本页的映射是否有效,如上图,当某个页并没有被映射时(或称“映射无 效”,Frame Index部分为X),该位为0,映射有效则该位为1。
我们执行下面这些指令(本例子的指令不针对任何特定机型,都是伪指令)
例1:
MOVE REG,0 //将0号地址的值传递进寄存器REG.
虚拟地址0将被送往MMU,MMU看到该虚地址落在页0范围内(页0范围是0到4095),从上图我们看到页0所对应(映射)的页框为2(页框2的地址范 围是8192到12287),因此MMU将该虚拟地址转化为物理地址8192,并把地址8192送到地址总线上。内存对MMU的映射一无所知,它只看到一 个对地址8192的读请求并执行它。MMU从而把0到4096的虚拟地址映射到8192到12287的物理地址。
例2:
MOVE REG,8192
被转换为
MOVE REG,24576
因为虚拟地址8192在页2中,而页2被映射到页框6(物理地址从24576到28671)
例3:
MOVE REG,20500
被转换为
MOVE REG,12308
虚拟地址20500在虚页5(虚拟地址范围是20480到24575)距开头20个字节处,虚页5映射到页框3(页框3的地址范围是 12288到16383),于是被映射到物理地址12288+20=12308。
通过适当的设置MMU,可以把16个虚页隐射到8个页框中的任何一个,但是这个方法并没有有效的解决虚拟地址空间比物理地址空间大的问题。从上图中我们可 以看到,我们只有8个页框(物理地址),但我们有16个页(虚拟地址),所以我们只能把16个页中的8个进行有效的映射。我们看看例4会发生什么情况
MOV REG,32780
虚拟地址32780落在页8的范围内,从上图总我们看到页8没有被有效的进行映射(该页被打上X),这是又会发生什么?MMU注意到这个页没有被映射,于 是通知CPU发生一个缺页故障(page fault).这种情况下操作系统必须处理这个页故障,它必须从8个物理页框中找到1个当前很少被使用的页框并把该页框的内容写入外围存储器(这个动作被 称为page copy),随后把需要引用的页(例4中是页8)映射到刚才释放的页框中(这个动作称为修改映射关系),然后从新执行产生故障的指令(MOV REG,32780)。假设操作系统决定释放页框1,那么它将把虚页8装入物理地址的4-8K,并做两处修改:首先把标记虚页1未被映射(原来虚页1是被 影射到页框1的),以使以后任何对虚拟地址4K到8K的访问都引起页故障而使操作系统做出适当的动作(这个动作正是我们现在在讨论的),其次他把虚页8对 应的页框号由X变为1,因此重新执行MOV REG,32780时,MMU将把32780映射为4108。
我们大致了解了MMU在我们的机器中扮演了什么角色以及它基本的工作内容是什么,下面我们将举例子说明它究竟是如何工作的(注意,本例中的MMU并无针对某种特定的机型,它是所有MMU工作的一个抽象)。
首先明确一点,MMU的主要工作只有一个,就是把虚拟地址映射到物理地址。
我们已经知道,大多数使用虚拟存储器的系统都使用一种称为分页(paging)的技术,就象我们刚才所举的例子,虚拟地址空间被分成大小相同的一组 页,每个页有一个用来标示它的页号(这个页号一般是它在该组中的索引,这点和C/C++中的数组相似)。在上面的例子中0~4K的页号为0,4~8K的页 号为1,8~12K的页号为2,以此类推。而虚拟地址(注意:是一个确定的地址,不是一个空间)被MMU分为2个部分,第一部分是页号索引(page Index),第二部分则是相对该页首地址的偏移量(offset). 。我们还是以刚才那个16位机器结合下图进行一个实例说明,该实例中,虚拟地址8196被送进MMU,MMU把它映射成物理地址。16位的CPU总共能产 生的地址范围是0~64K,按每页4K的大小计算,该空间必须被分成16个页。而我们的虚拟地址第一部分所能够表达的范围也必须等于16(这样才能索引到 该页组中的每一个页),也就是说这个部分至少需要4个bit。一个页的大小是4K(4096),也就是说偏移部分必须使用12个bit来表示 (2^12=4096,这样才能访问到一个页中的所有地址),8196的二进制码如下图所示:
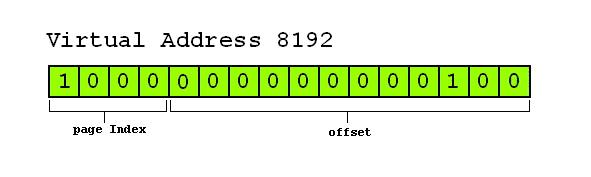
(上图的page index有误,应该是0010)
该地址的页号索引为0010(二进制码),既索引的页为页2,第二部分为000000000100(二进制),偏移量为4。页2中的页框号为6(页2映射 在页框6,见上图),我们看到页框6的物理地址是24~28K。于是MMU计算出虚拟地址8196应该被映射成物理地址24580(页框首地址+偏移 量=24576+4=24580)。同样的,若我们对虚拟地址1026进行读取,1026的二进制码为0000010000000010,page index=0000=0,offset=010000000010=1026。页号为0,该页映射的页框号为2,页框2的物理地址范围是 8192~12287,故MMU将虚拟地址1026映射为物理地址9218(页框首地址+偏移量=8192+1026=9218)
首先,得到虚拟地址的page index,然后如果这一页已经映射,找到映射的页框,然后实际的物理地址就是:页框号*页大小+偏移;但是如果,这一页没有映射,首先看我的内存还有没有一页的空闲空间,如果有直接映射,如果没有,就把当前内存中使用最不频繁的一页踢出来,把我的页映射进去,然后重新的设置页和页框之间的对应关系,然后重新执行我们的指令。
下面我们针对s3c2410的MMU(注1)进行讲解。
S3c2410总共有4种内存映射方式,分别是:
1.Fault (无映射)
2.Coarse Page (粗表)
3.Section (段)
4.Fine Page (细表)
我们以Section(段)进行说明。
ARM920T是一个32bit的CPU,它的虚拟地址空间为2^32=4G。而在Section模式,这4G的虚拟空间被分成一个一个称为段 (Section)的单位(与我们上面讲的页在本质上其实是一致的),每个段的长度是1M (而我们之前所使用的页的长度是4K)。4G的虚拟内存总共可以被分成4096个段(1M*4096=4G),因此我们必须用4096个描述符来对这组段 进行描述,每个描述符占用4个Byte,故这组描述符的大小为16KB (4*4096),这4096个描述符构为一个表格,我们称其为Tralaton Table.
![]()
上图是描述符的结构
Section base address:段基地址(相当于页框号首地址),因为有4096个段2^12=4096,所以占12位。
AP: 访问控制位Access Permission
Domain: 访问控制寄存器的索引。Domain与AP配合使用,对访问权限进行检查
C:当C被置1时为write-through (WT)模式
B: 当B被置1时为write-back (WB)模式
(C,B两个位在同一时刻只能有一个被置1)
下面是s3c2410内存映射后的一个示意图:
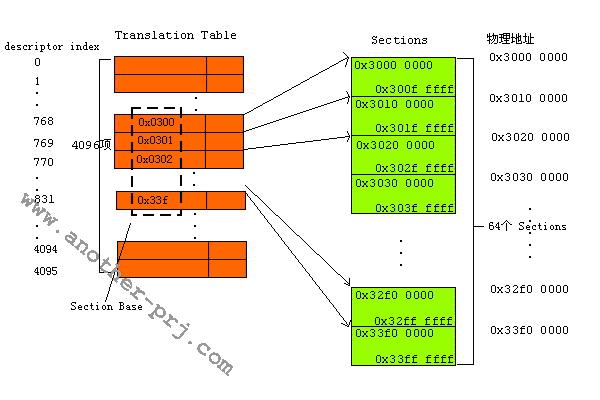
我的s3c2410上配置的SDRSAM大小为64M,该SDRAM的物理地址范围是0x3000 0000~0x33FF FFFF(属于Bank 6),由于1个Section的大小是1M,所以该物理空间可以被分成64个物理段(页框).
0x33f-0x300 = 64;
在Section模式下,送进MMU的虚拟地址(注1)被分为两部分(这点和我们上面举的例子是一样的),这两部分为 Descriptor Index(相当于上面例子的Page Index)和 Offset,descript index长度为12bit(2^12=4096,从这个关系式你能看出什么?:) ),Offset长度为20bit(2^20=1M,你又能看出什么?:)).观察一下一个描述符(Descriptor)中的Section Base Address部分,它长度为12 bit,里面的值是该虚拟段(页)映射成的物理段(页框)的物理地址前12bit,由于每一个物理段的长度都是1M,所以物理段首地址的后20bit总是 为0x00000(每个Section都是以1M对齐),确定一个物理地址的方法是 物理页框基地址+虚拟地址中的偏移部分=Section Base Address<<20+Offset ,呵呵,可能你有点糊涂了,还是举一个实际例子说明吧。假设现在执行指令
MOV REG, 0x30000012
虚拟地址的二进制码为00110000 00000000 00000000 00010010
前12位是Descriptor Index= 00110000 0000=768,故在Translation Table里面找到第768号描述符,该描述的Section Base Address=0x0300,也就是说描述符所描述的虚拟段(页)所映射的物理段(页框)的首地址为0x3000 0000(物理段(页框)的基地址=Section Base Address左移20bit=0x0300<<20=0x3000 0000),而Offset=000000 00000000 00010010=0x12,故虚拟地址0x30000012映射成的物理地址=0x3000 0000+0x12=0x3000 0012(物理页框基地址+虚拟地址中的偏移)。你可能会问怎么这个虚拟地址和映射后的物理地址一样?这是由我们定义的映射规则所决定的。在这个例子中我 们定义的映射规则是把虚拟地址映射成和他相等的物理地址。我们这样书写映射关系的代码:
void mem_mapping_linear(void)
{
unsigned long descriptor_index, section_base, sdram_base, sdram_size;
sdram_base=0x30000000;
sdram_size=0x 4000000;
for (section _base= sdram_base,descriptor_index = section _base>>20;
section _base < sdram_base+ sdram_size;
descriptor_index+=1;section _base +=0x100000)
{
*(mmu_tlb_base + (descriptor_index)) = (section _base>>20) | MMU_OTHER_SECDESC;
}
}
上面的这段段代码把虚拟空间0x3000 0000~0x33FF FFFF映射到物理空间0x3000 0000~0x33FF FFFF,由于虚拟空间与物理空间空间相吻合,所以虚拟地址与他们各自对应的物理地址在值上是一致的。当初始完Translation Table之后,记得要把Translation Table的首地址(第0号描述符的地址)加载进协处理器CP15的Control Register2(2号控制寄存器)中,该控制寄存器的名称叫做Translation table base (TTB) register。
以上讨论的是descriptor中的Section Base Address以及虚拟地址和物理地址的映射关系,然而MMU还有一个重要的功能,那就是访问控制机制(Access Permission )。
简单说访问控制机制就是CPU通过某种方法判断当前程序对内存的访问是否合法(是否有权限对该内存进行访问),如果当前的程序并没有权限对即将访问的内存 区域进行操作,则CPU将引发一个异常,s3c2410称该异常为Permission fault,x86架构则把这种异常称之为通用保护异常(General Protection),什么情况会引起Permission fault呢?比如处于User级别的程序要对一个System级别的内存区域进行写操作,这种操作是越权的,应该引起一个Permission fault,搞过x86架构的朋友应该听过保护模式(Protection Mode),保护模式就是基于这种思想进行工作的,于是我们也可以这么说:s3c2410的访问控制机制其实就是一种保护机制。那s3c2410的访问控 制机制到底是由什么元素去参与完成的呢?它们间是怎么协调工作的呢?这些元素总共有:
1.协处理器CP15中Control Register3:DOMAIN ACCESS CONTROL REGISTER
2.段描述符中的AP位和Domain位
3.协处理器CP15中Control Register1(控制寄存器1)中的S bit和R bit
4.协处理器CP15中Control Register5(控制寄存器5)
5.协处理器CP15中Control Register6(控制寄存器6)
DOMAIN ACCESS CONTROL REGISTER 是访问控制寄存器,该寄存器有效位为32,被分成16个区域,每个区域由两个位组成,他们说明了当前内存的访问权限检查的级别,如下图所示:
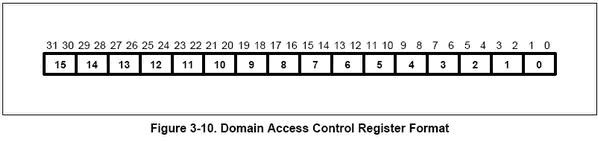
每区域可以填写的值有4个,分别为00,01,10,11(二进制),他们的意义如下所示:
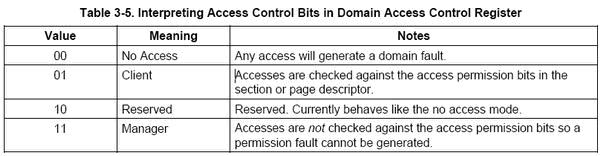
00:当前级别下,该内存区域不允许被访问,任何的访问都会引起一个domain fault
01:当前级别下,该内存区域的访问必须配合该内存区域的段描述符中AP位进行权检查
10:保留状态(我们最好不要填写该值,以免引起不能确定的问题)
11:当前级别下,对该内存区域的访问都不进行权限检查。
我们再来看看discriptor中的Domain区域,该区域总共有4个bit,里面的值是对DOMAIN ACCESS CONTROL REGISTER中16个区域的索引.而AP位配合S bit和A bit对当前描述符描述的内存区域被访问权限的说明,他们的配合关系如下图所示:
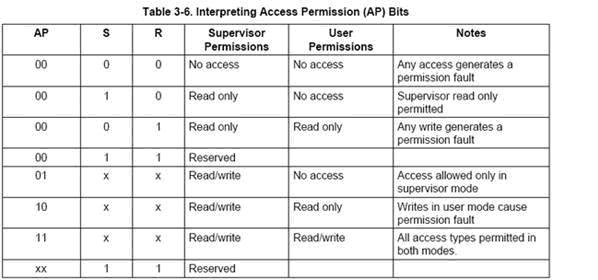
AP位也是有四个值,我结合实例对其进行说明.
在下面的例子中,我们的DOMAIN ACCESS CONTROL REGISTER都被初始化成0xFFFF BDCF,如下图所示:
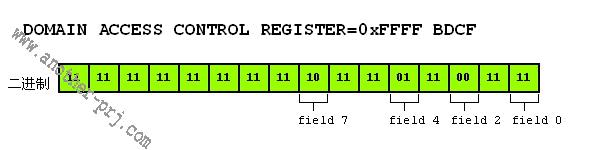
例1:
Discriptor 中的domain=4,AP=10(这种情况下S bit ,A bit 被忽略)
假设现在我要对该描述符描述的内存区域进行访问:
由于domain=4,而DOMAIN ACCESS CONTROL REGISTER中field 4的值是01,系统会对该访问进行访问权限的检查。
假设当前CPU处于Supervisor模式下,则程序可以对该描述符描述的内存区域进行读写操作。
假设当前CPU处于User模式下,则程序可以对该描述符描述的内存进行读访问,若对其进行写操作则引起一个permission fault.
例2:
Discriptor 中的domain=0,AP=10(这种情况下S bit ,A bit 被忽略)
domain=0,而DOMAIN ACCESS CONTROL REGISTER中field 0的值是11,系统对任何内存区域的访问都不进行访问权限的检查。
由于统对任何内存区域的访问都不进行访问权限的检查,所以无论CPU处于合种模式下(Supervisor模式或是User模式),程序对该描述符描述的内存都可以顺利地进行读写操作
例3:Discriptor 中的domain=4,AP=11(这种情况下S bit ,A bit 被忽略)
由于domain=4,而DOMAIN ACCESS CONTROL REGISTER中field 4的值是01,系统会对该访问进行访问权限的检查。
由于AP=11,所以无论CPU处于合种模式下(Supervisor模式或是User模式),程序对该描述符描述的内存都可以顺利地进行读写操作
例4:
Discriptor 中的domain=4,AP=00, S bit=0,A bit=0
由于domain=4,而DOMAIN ACCESS CONTROL REGISTER中field 4的值是01,系统会对该访问进行访问权限的检查。
由于AP=00,S bit=0,A bit=0,所以无论CPU处于合种模式下(Supervisor模式或是User模式),程序对该描述符描述的内存都只能进行读操作,否则引起permission fault.
通过以上4个例子我们得出两个结论:
1.对某个内存区域的访问是否需要进行权限检查是由该内存区域的描述符中的Domain域决定的。
2.某个内存区域的访问权限是由该内存区域的描述符中的AP位和协处理器CP15中Control Register1(控制寄存器1)中的S bit和R bit所决定的。
关于访问控制机制我们就讲到这里.
注1:对于s3c2410来说,MMU是以Modify Visual Address(MVA)进行寻址的,这个地址是Virtual Address的一个变换,我将在以后谈论到进程切换的时候中向大家介绍MVA















 2092
2092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









