






字符集与字符集编码
- 什么是是字符集
- 什么是字符集编码,为什么需要字符集编码
单字节字符集
ASCII
ASCII (American Standard Code for InformationI nterchange,美国信息交换标准代码) 由电报码发展而来。第一版标准发布于1963年,1967年经历了一次主要修订,最后一次更新则是在1986年,至今为止共定义了128个字符;其中33个字符无法显示(一些终端提供了扩展,使得这些字符可显示为诸如笑脸、扑克牌花式等8-bit符号),且这33个字符多数都已是陈废的控制字符。控制字符的用途主要是用来操控已经处理过的文字。在33个字符之外的是95个可显示的字符。用键盘敲下空白键所产生的空白字符也算1个可显示字符(显示为空白)。
ASCII - 维基百科
ASCII 表
ISO 8859
ISO 8859,全称ISO/IEC 8859,是国际标准化组织(ISO)及国际电工委员会(IEC)联合制定的一系列8位元字符集的标准,现时定义了15个字符集。
ISO/IEC 8859-1(Latin-1) - 西欧语言
- ISO/IEC 8859-2(Latin-2) - 中欧语言
- ISO/IEC 8859-3(Latin-3) - 南欧语言。世界语也可用此字符集显示。
- ISO/IEC 8859-4(Latin-4) - 北欧语言
- ISO/IEC 8859-5(Cyrillic) -斯拉夫语言
- ISO/IEC 8859-6(Arabic) -阿拉伯语
- ISO/IEC 8859-7(Greek) -希腊语
- ISO/IEC 8859-8(Hebrew) -希伯来语(视觉顺序)
- ISO 8859-8-I - 希伯来语(逻辑顺序)
- ISO/IEC 8859-9(Latin-5 或 Turkish)- 它把Latin-1的冰岛语字母换走,加入土耳其语字母。
- ISO/IEC 8859-10(Latin-6 或 Nordic)-北日耳曼语支,用来代替Latin-4。
- ISO/IEC 8859-11(Thai) -泰语,从泰国的 TIS620 标准字集演化而来。
- ISO/IEC 8859-13(Latin-7 或 Baltic Rim)-波罗的语族
- ISO/IEC 8859-14(Latin-8 或 Celtic)-凯尔特语族
- ISO/IEC 8859-15(Latin-9) - 西欧语言,加入Latin-1欠缺的芬兰语字母和大写法语重音字母,以及欧元(€)符号。
- ISO/IEC 8859-16(Latin-10) - 东南欧语言。主要供罗马尼亚语使用,并加入欧元符号。
常识补充
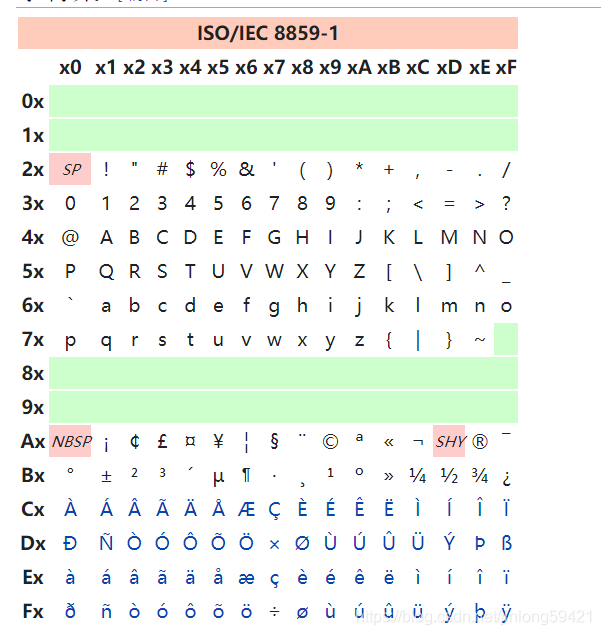
ISO 8859-1
又称Latin-1或“西欧语言”,是国际标准化组织内ISO/IEC 8859的第一个8位字符集。它以ASCII为基础,在空置的0xA0-0xFF的范围内,加入96个字母及符号,藉以供使用附加符号的拉丁字母语言使用。(原有的 ASCII 0-126 即最高位均为0 )
此字符集支持部分于欧洲使用的语言,包括阿尔巴尼亚语、巴斯克语、布列塔尼语、加泰罗尼亚语、丹麦语、荷兰语、法罗语、弗里西语、加利西亚语、德语、格陵兰语、冰岛语、爱尔兰盖尔语、意大利语、拉丁语、卢森堡语、挪威语、葡萄牙语、里托罗曼斯语、苏格兰盖尔语、西班牙语及瑞典语。
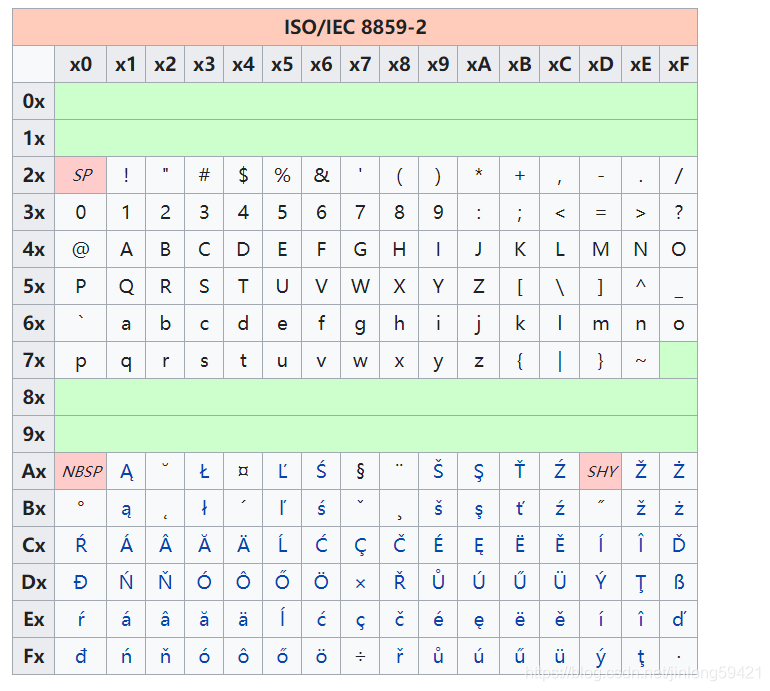
ISO 8859-2
又称Latin-2或“中欧语言” 此字符集主要支援以下文字:克罗地亚语、捷克语、匈牙利语、波兰语、斯洛伐克语、斯洛文尼亚语、上索布语、下索布语。而阿尔巴尼亚语、英语、德语、拉丁语也可用此字符集显示。
多字节字符集
国标码
GB 2312
又称GB0,由中国国家标准总局于1980年发布,1981年5月1日实施。GB/T 2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个字符。
GB/T 2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。但对于人名、古汉语等方面出现的罕用字和繁体字,GB/T 2312不能处理
字符集编码
在使用GB/T 2312的程序通常采用EUC(Extended Unix Code,它主要用于表示及储存汉语文字、日语文字及朝鲜文字)储存方法,以便兼容于ASCII。这种格式称为EUC-CN。浏览器编码表上的“GB2312”就是指这种表示法。
每个汉字及符号以两个字节来表示。第一个字节称为“高位字节”(区码),第二个字节称为“低位字节”(位码)。
“高位字节”使用了0xA1–0xF7(把01–87区的区号加上0xA0),“低位字节”使用了0xA1–0xFE(把01–94加上0xA0)。 由于一级汉字从16区起始,汉字区的“高位字节”的范围是0xB0–0xF7,“低位字节”的范围是0xA1–0xFE,占用的码位是72*94=6768。其中有5个空位是D7FA–D7FE。
例如“啊”字在大多数程序中,会以两个字节,0xB0(第一个字节)0xA1(第二个字节)储存。(与区位码对比:0xB0=0xA0+16,0xA1=0xA0+1)。
简单理解GB2312 的编码 字节数小于127 为ascill码,读取一个字节,大于者为两字节编码
常识补充
GB/T 12345
GB/T 12345,GB/T 12345–90或GB/T 12345–1990,全称《信息交换用汉字编码字符集 辅助集》(英文:Code of Chinese ideogram set for information interchange supplementary set),也就是“第一辅助集”,简称GB1,可以看成是GB/T 2312的繁体版本,共收录6,866个汉字,是中华人民共和国为了适应繁体汉字信息处理而制定的标准。
该标准是于1990年发布,原称GB/T 12345–90,T 是“推荐”汉语拼音首字母。1993年起该标准改为强制性,改称GB 12345。自2017年3月23日起,根据2017年第7号公告和强制性标准整合精简结论,该标准转化回推荐性标准,不再强制执行,也改称回GB/T 12345。
GBK
汉字内码扩展规范,称GBK,全名为《汉字内码扩展规范(GBK)》1.0版,由中华人民共和国全国信息技术标准化技术委员会1995年12月1日制订,国家技术监督局标准化司和电子工业部科技与质量监督司1995年12月15日联合以《技术标函[1995]229号》文件的形式公布。 GBK共收录21886个汉字和图形符号,其中汉字(包括部首和构件)21003个,图形符号883个。
GBK的K为“扩展”的汉语拼音(kuòzhǎn)第一个声母。英文全称Chinese Internal Code Extension Specification。
GBK 只为“技术规范指导性文件”,不属于国家标准。
GBK共收录21886个汉字和图形符号,其中汉字(包括部首和构件)21003个,图形符号883个。GBK 只为“技术规范指导性文件”,不属于国家标准。国家质量技术监督局于2000年3月17日推出了GB 18030-2000标准,以取代GBK。GB 18030-2000除保留全部GBK编码汉字,在第二字节把能使用范围再度进行扩展,增加了大约一百个汉字及四字节编码空间,但是将GBK作为子集全部保留
Unicode 字符集(万国码)
Unicode为解决传统字符编码方案的局限而产生,例如ISO 8859-1所定义的字符虽然在不同的国家中广泛地使用,可是在不同国家间却经常出现不兼容的情况。很多传统的编码方式都有共同的问题,即容许电脑处理双语环境(通常使用拉丁字母以及其本地语言),但却无法同时支持多语言环境(指可同时处理多种语言混合的情况)。其首256个字符保留给ISO 8859-1所定义的字符,使既有的西欧语系文字的转换不需特别考量;并且把大量相同的字符重复编到不同的字符码中去,使得旧有纷杂的编码方式得以和Unicode编码间互相直接转换,而不会丢失任何信息。
Unicode 的问题
需要注意的是,Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字严的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是,如何才能区别 Unicode 和 ASCII ?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:1)出现了 Unicode 的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示 Unicode。2)Unicode 在很长一段时间内无法推广,直到互联网的出现。
UTF-8 字符编码
UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
- 对于单字节的符号:字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的;
- 对于n字节的符号(n > 1):第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。

汉字的unicode编码最小值为:0x4e00(0100111000000000),最大值为0x952f(1001010100101111)中文的Utf8 单字使用三个字节,故这就常说的 相同数据量GBK 编码的数据体积较少
示例:
严的 Unicode 是4E25(100111000100101),
根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5。
UTF-16 字符编码
UTF-16 字符编码方案可能用2或4个字节表示一个unicode值。
Unicode的编码空间从U+0000到U+10FFFF,共有1,112,064个码位(code point)可用来映射字符。Unicode的编码空间可以划分为17个平面(plane),每个平面包含216(65,536)个码位。17个平面的码位可表示为从U+xx0000到U+xxFFFF,其中xx表示十六进制值从0016到1016,共计17个平面。第一个平面称为基本多语言平面(Basic Multilingual Plane,BMP),或称第零平面(Plane 0),其他平面称为辅助平面(Supplementary Planes)。
辅助平面(Supplementary Planes)中的码位,在UTF-16中被编码为一对16比特长的码元(即32位,4字节)
- 码位减去0x10000
- 高位的10比特的值(值的范围为0…0x3FF)被加上0xD800得到第一个码元或称作高位代理(high surrogate),值的范围是0xD800…0xDBFF。
- 低位的10比特的值(值的范围也是0…0x3FF)被加上0xDC00得到第二个码元或称作低位代理(low surrogate)
示例:
以U+10437编码(𐐷)为例: - 0x10437减去0x10000,结果为0x00437,二进制为0000 0000 0100 0011 0111
- 分割它的上10位值和下10位值(使用二进制):0000 0000 01和00 0011 0111
- 添加0xD800到上值,以形成高位:0xD800 + 0x0001 =0xD801
- 添加0xDC00到下值,以形成低位:0xDC00 + 0x0037 =0xDC37

UTF-32 定长编码
UTF-32是32位Unicode转换格式(Unicode Transformation Formats, 或UTF)的缩写。UTF-32是一种用于编码Unicode的协定,该协定使用32位比特对每个Unicode码位进行编码(但前导比特数必须为零,故仅能表示221个Unicode码位)。与其他可变长度的Unicode转换格式(UTF)相比,UTF-32编码长度是固定的,UTF-32中的每个32位值代表一个Unicode码位,并且与该码位的数值完全一致。
补充
- ANSI编码(仅存在windows PC 中),ANSI码仅在前126个与ASCII码相同。
在简体中文Windows操作系统中,ANSI 编码代表 GBK 编码;在英文Windows操作系统中,ANSI 编码代表 ASCII编码;在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码。 - BOM (字节顺序标记 byte-order mark)出现在文本文件头部,Unicode编码标准中用于标识文件是采用哪种格式的编码。(UTF8 一般不需要,也是文件读取的坑点,微软CSV 文件必须使用utf8 格式必须使用bom格式,不然乱码)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









