







思路一:
看到这个题目的第一反应是:循环随机产生1-100的随机数,判断数组中是否已经有该数,若已存在,则重新生成随机数;若不存在,则放入数组中。
实现代码如下所示:
public void setData(int[] array){
Random rd = new Random();
boolean isExit;
int len = array.length;
for(int i = 0; i < array.length; i++){
isExit = false;
//生成一个1-100之间的随机数
int num = rd.nextInt(len)+1;
//检验数组中是否已有该数
for(int j = 0; j < i; j++){
if(array[j] == num){
isExit = true;
i--;
break;
}
}
if(!isExit){
array[i] = num;
}
}
}运行查看结果,发现该方法可行,但是,当我们要随机产生的数变大时,这种方法所体现出的效率就会变得非常低。
我们可以利用System.currentTimeMillis()方法来计算该算法所用的时间。
测试:将产生的随机数改成1-10000,运行该程序:
结果如下图所示(结果的一部分):
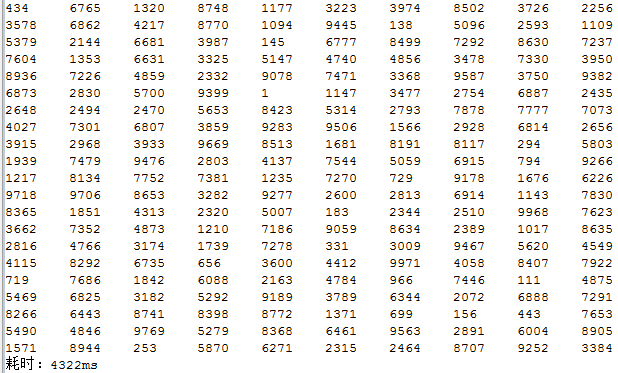
我们可以看到,用这种算法效率很差,所以我们要想办法改进这个算法。我们先来想想这个算法的运行时间主要消耗在哪里?这应该是显而易见的,每生成一个随机数,程序就需要遍历整个数组来判断其中是否存在该数,这是很耗时的。能不能想办法不用每次都去遍历查找呢?有什么办法可以保证每次生成的数不会重复呢?
思路二:
我们不妨来逆向思考,事先将1-100这间的数顺序存入数组sorce中,随机产生一个位置,然后将该索引对应的数组元素依次放入数组array中,每次放入一个数后,都要将该数从source数组中删除,而下一次产生的随机数的范围也将所缩小。由于已生成的数已经被删除,所以每次产生的数就不会再重复。
实现代码如下所示:
public void setNum(int[] source,int[] array){
Random rd = new Random();
int range = array.length;
int index = 0;
for(int i = 0; i <array.length; i++){
//随机产生一个位置
int pos = rd.nextInt(range);
//获取该位置的值
array[i] = source[pos];
//删除该索引在数组中的位置
for(int j = pos; j < array.length-1; j++){
source[j] = source[j+1];
}
//缩小随机数产生的范围
range--;
}
}在运行之前我们也将范围改成10000,来看看它的运行效率如何,运行结果如下图所示:
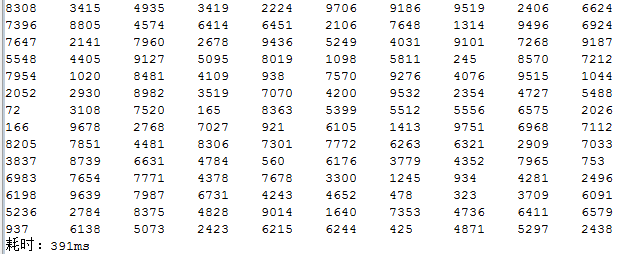
由上图可以看出,由于省去了生成无效随机数的时间,效率提高了100多倍!
思路三:
不过这个算法也不是效率最高的方法,该算法还是存在弊端的,因为在生成了随机数之后,对整个数组进行了删除操作,其实也就是进行了一系列数据的交换,这也是比较耗时的,所以我们可以考虑的是:在保证不进行删除操作,但也能将产生的数从数组中剔除的方法。
第一反应想到的应该会给这个数覆盖上其他的值,那应该赋什么值呢?0?如果赋0的话,那接下来生成随机数的范围就无法再是递减1的缩小了,那么有没有其他的方法呢?可不可以给它赋一个数组中还需要存在的数呢?我们不妨将数组中最后一个数赋给它,那么下次随机数的产生也还能采用思路二中的方法,主要思路如下所示:
假设数组中的数为:1,2,3,4,5,6
第一次随机产生的索引为3,即对应的是4,将4写入array数组中后,将6赋到array[3]中,则数组更新为:1,2,3,6,5,6(有效的数其实只有1,2,3,6,5)
第二次随机产生的索引为4,即对应的是6,将6写入array数组中后,将5赋给array[4]中,则数组更新为:1,2,3,5,5,6(有效的数其实只有1,2,3,5)
第三次随机产生的索引为1,即对应的是2,将2写入array数组中后,将5赋给array[1]中,则数组更新为:1,5,3,5,5,6(有效的数其实只有1,5,3)
以此类推......
采用这个方法,就不需要再对source数组中数进行删除(多次数据交换),而每一次产生随机数后,只需要执行一次数据交换即可,又在一定程度上提高了程序运行的效率。
实现代码如下所示:
public void setNum(int[] source,int[] array){
Random rd = new Random();
int range = array.length;
int index = 0;
for(int i = 0; i <array.length; i++){
//随机产生一个位置
int pos = rd.nextInt(range);
//获取该位置的值
array[i] = source[pos];
//改良:将最后一个数赋给被删除的索引所对应的值
source[pos] = source[range-1];
缩小随机数产生的范围
range--;
}
}
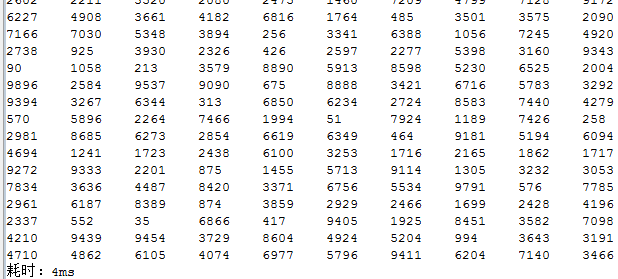
可见,该算法的耗时又比思路二的提高了近100倍!而比思路一快了1000多倍!
所以,我们可以发现算法对一个程序的执行效率有着关键性的作用,我们在解决问题的时候应该逐步思考,在运行正确的情况下也应该多考虑程序的性能问题,找到程序中比较耗时的部分,然后再去思考是否有方法对其进行优化。















 7133
7133

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









