







 本文介绍了如何在Python中使用Selenium和PhantomJS抓取依赖JavaScript动态加载的网页数据。由于原始代码可能无法稳定获取数据,通过引入Selenium的等待机制(Explicit Waits)来确保数据加载完成后再进行抓取,从而提高了稳定性。
本文介绍了如何在Python中使用Selenium和PhantomJS抓取依赖JavaScript动态加载的网页数据。由于原始代码可能无法稳定获取数据,通过引入Selenium的等待机制(Explicit Waits)来确保数据加载完成后再进行抓取,从而提高了稳定性。

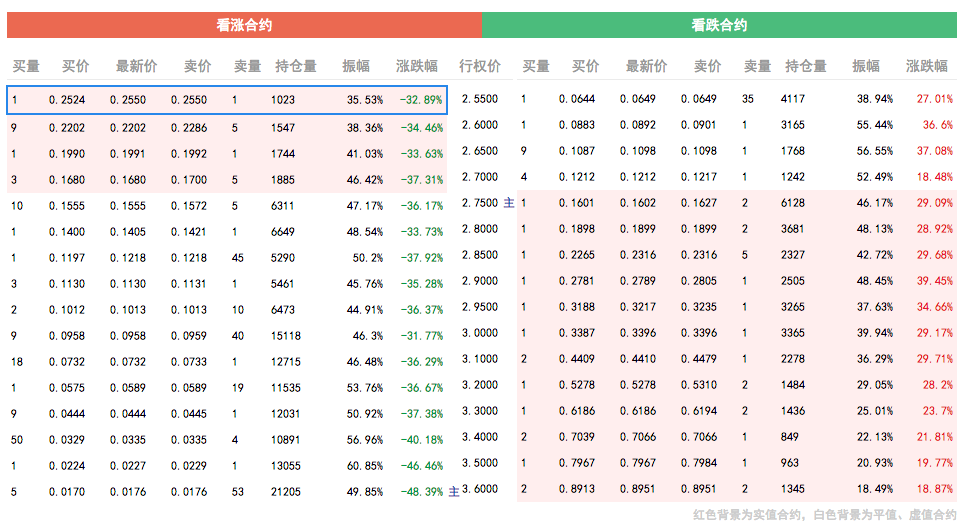
有些网页不是静态加载的,而是通过javascirpt函数动态加载网页,比如下面这个网页,表格中的看涨合约和看跌合约的数据都是通过javascirpt函数从后台加载。仅仅使用beautifulsoup并不能抓到这个表格中的数据。
查找资料,发现可以使用PhantomJS来抓取这类网页的数据。但PhantomJS主要用于Java,若要在python中使用,则要通过Selenium在python中调用PhantomJS。写代码时主要参考了这个网页:Is there a way to use PhantomJS in Python?
Selenium是一个浏览器虚拟器,可以通过Selenium在各种浏览器上模拟各种行为。python中通过Selenium使用PhantomJS抓取动态网页数据时需要安装以下库:
1. Beautifulsoup,用于解析网页内容
2. Node.js
3. 安装好Node.js之后通过Node.js安装PhantomJS。在Mac终端中输入npm -g install phantomjs即可(Windows下的cmd也是一样)
4. 安装Selenium
完成上述四个步骤后即可在python中使用PhantomJS。
代码如下:
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import urllib2
import time
baseUrl = "http://stock.finance.sina.com.cn/option/quotes.html"
csvPath = "FinanceData.csv"
csvFile = open(csvPath, 'w')
def is_chinese(uchar):
# 判断一个unicode是否是汉字
if uchar >= u'\u4e00' and uchar<=u'\u9fa5':
return True
else:
return False
def 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5004
5004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









