







目录
本周我所做的工作:
1.寻找人脸识别数据集,并对数据进行预处理。
数据集格式如上,数据集由约三万张图片组成,主要为1040人的头部图像,每个子文件夹下的名称即为该人的编号。
按类别分为:

Accessory:佩戴各种帽子、眼镜、墨镜等装饰品的照片。

Aging:不同年龄的人物照片。

Background:不同人物背景下的图片。

Distance:不同拍摄距离下的图片。

Expression:不同人物表情下的图片。

Lighting:不同光线照射下的图片。

Normal:正常拍摄的图片。



Pose:不同拍摄角度的图片。
由于签到人脸识别功能需要适应多种情况,为了增强模型的鲁棒性和识别能力,我将以上所有任务的图片合并并重新划分数据集,以同时解决模型对穿戴饰品遮挡面部、不同背景色调、不同光线照射角度、不同拍摄角度、不同表情、不同拍摄距离等多种复杂情况下的人脸识别。
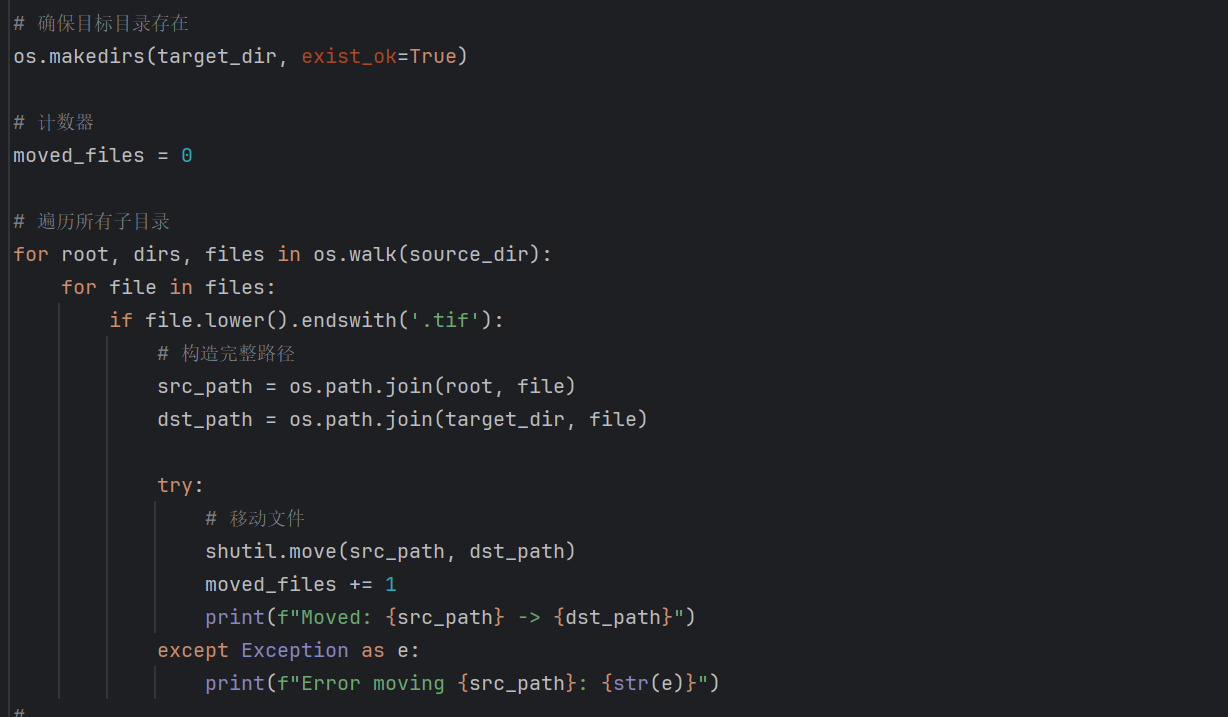
首先撰写代码将所有图片移至同一文件夹下:
其次将文件按照拍摄人的编号进行子文件夹划分
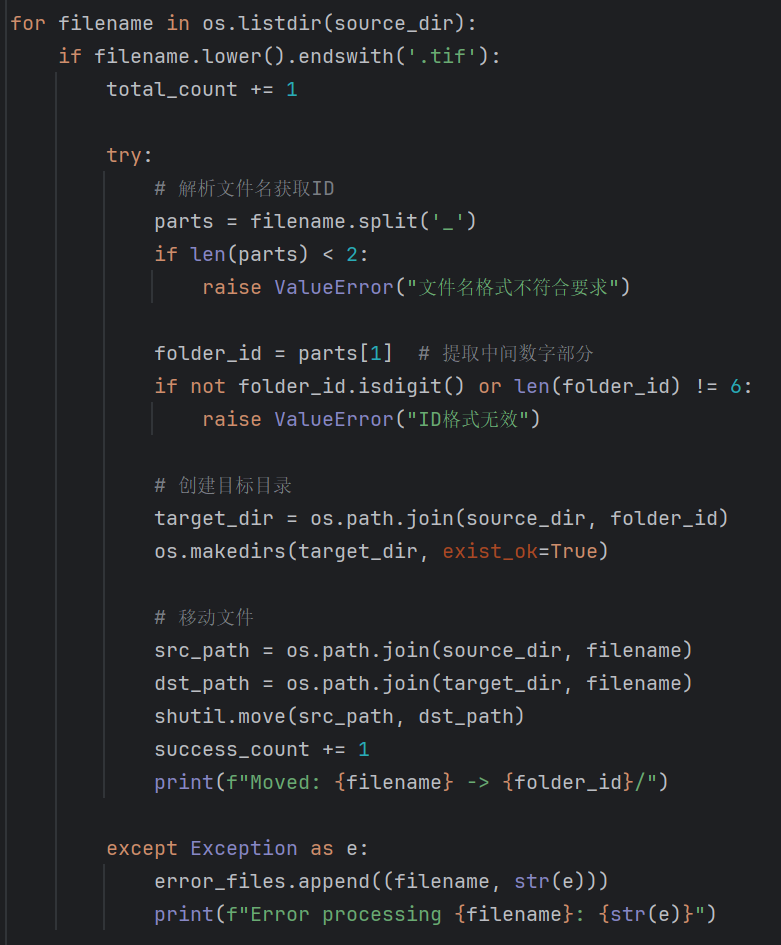
划分结果如下所示:
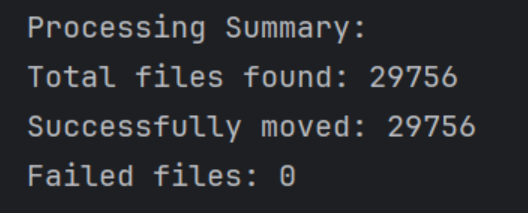
最后将每个拍摄人的图片按照8:2划分训练集与测试集
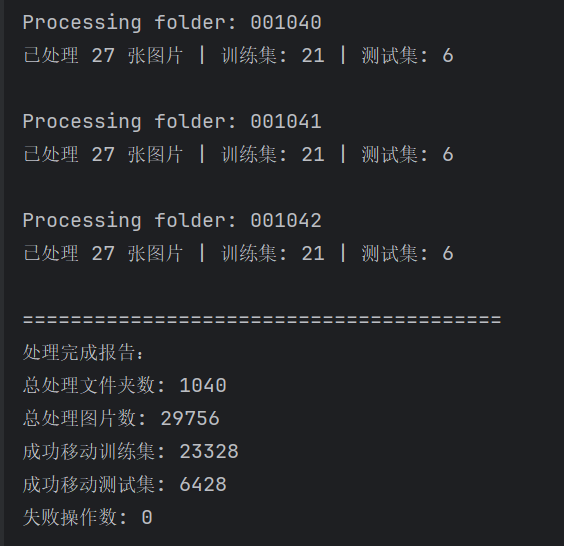
划分结果如下所示:
2.构建人脸识别模型,并对模型进行微调。
采用FaceNet,通过MTCNN和InceptionResNet构建人脸识别模型,并在vggface2的基础上进行微调。
改进设计:
①冻结部分模型架构,只更新剩余参数。

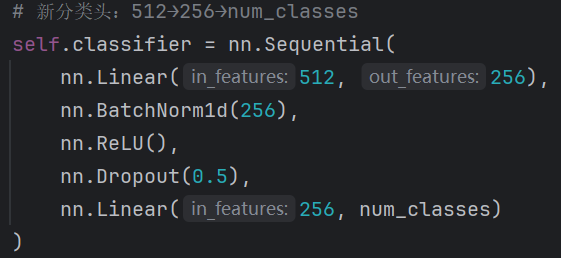
②添加新的分类头,自行设计classifier架构,使用batchnorm以及dropout技术。
③数据增强处理。

④灵活调整优化器,为不同参数设置不同的学习率。

⑤优化学习器,设置早停,梯度截断,梯度衰减等参数。
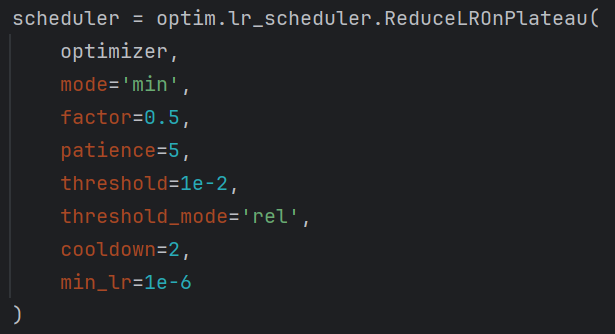
导入数据并进行训练:
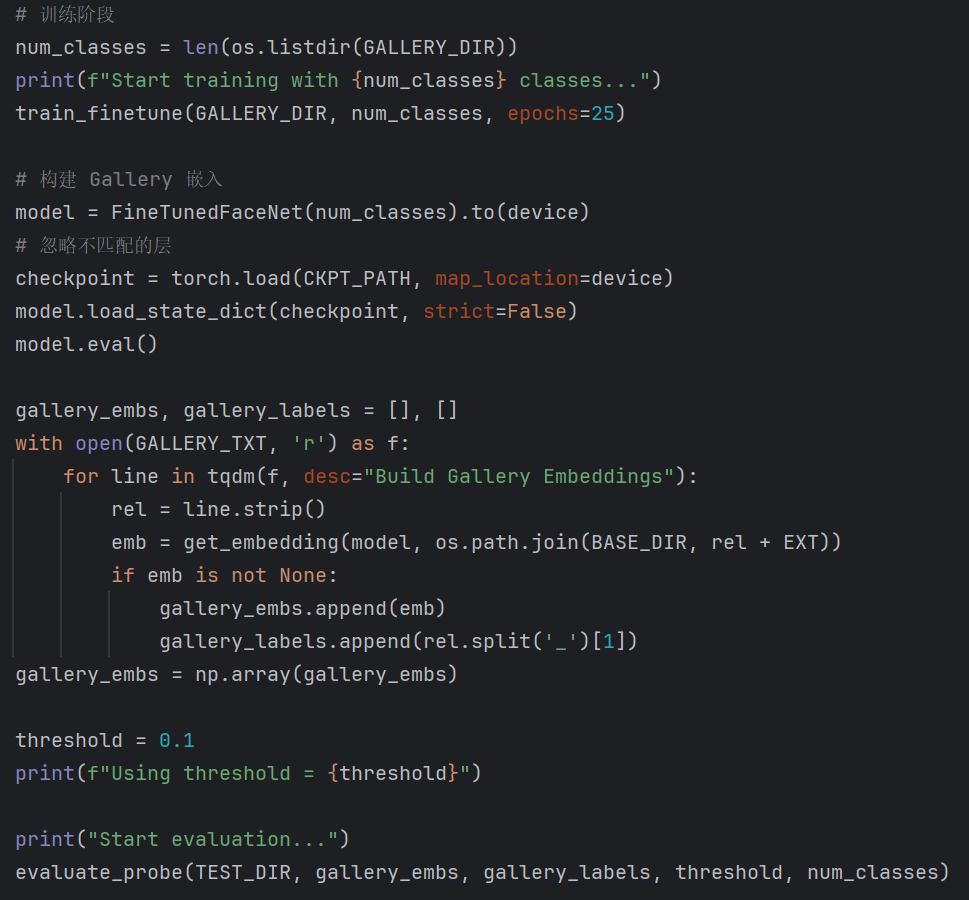
训练结果:
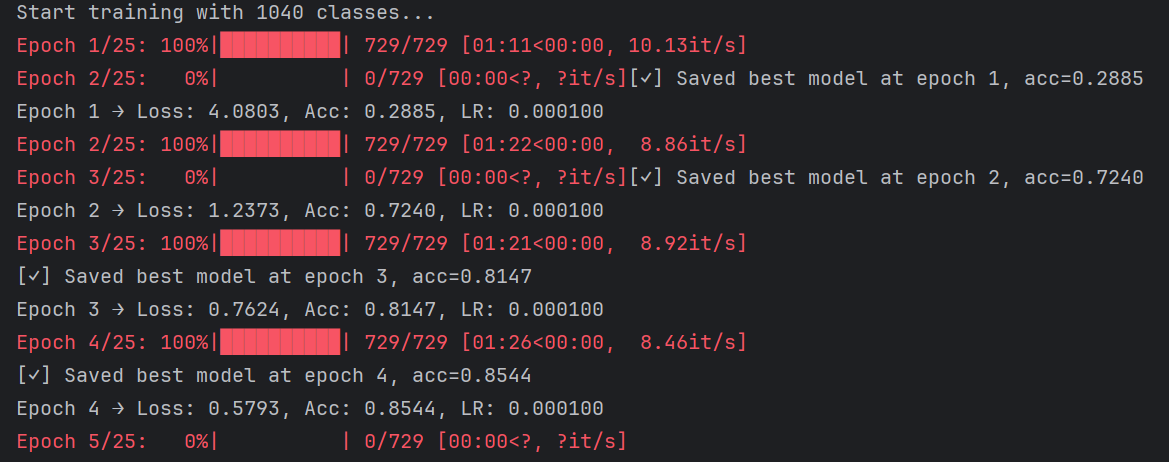
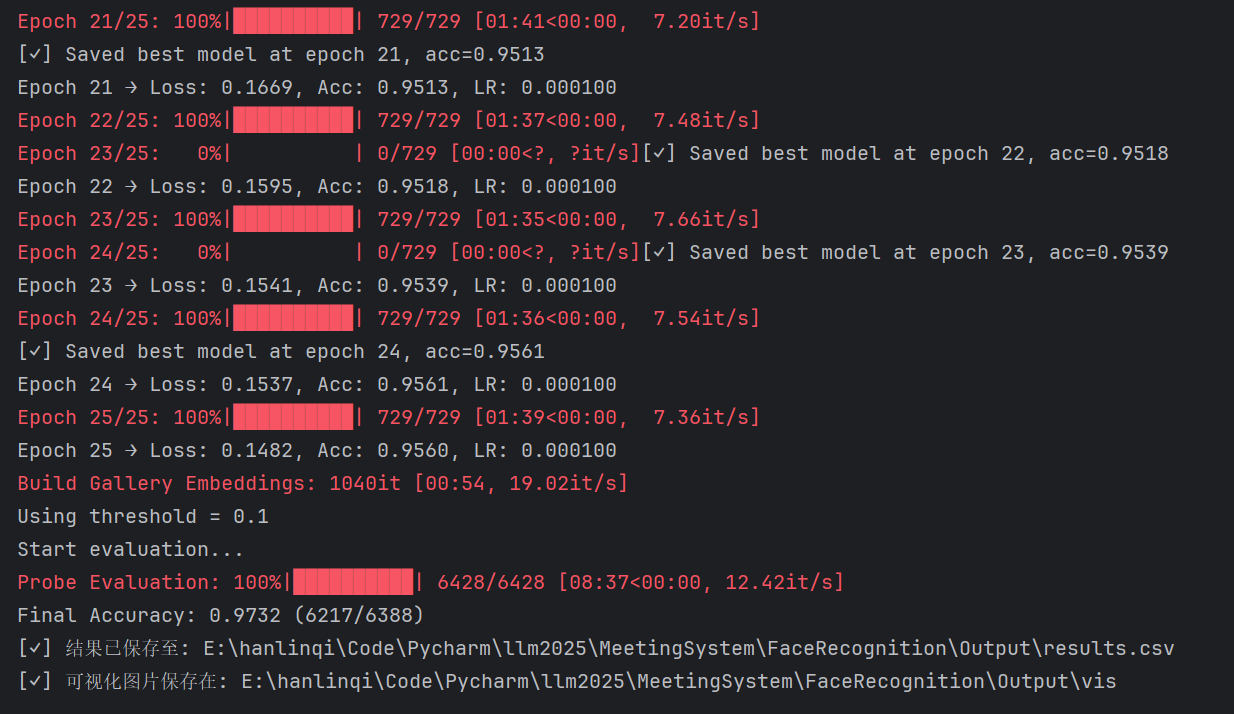
准确率由最初的28.85%上升至95.61%,并在测试集中达到了97.32%的准确率!
![]()
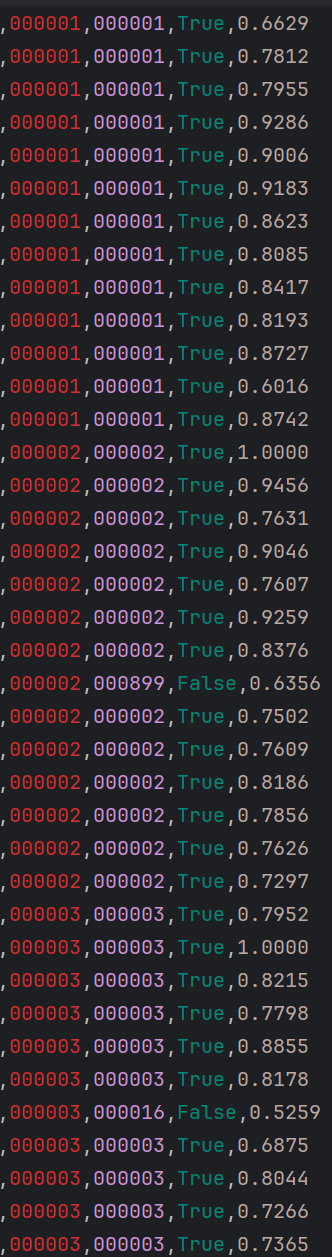
3.利用训练好的模型参数进行人脸识别,实现会议签到功能。
构建MongoDB数据库,保存注册人的人脸特征识别数据
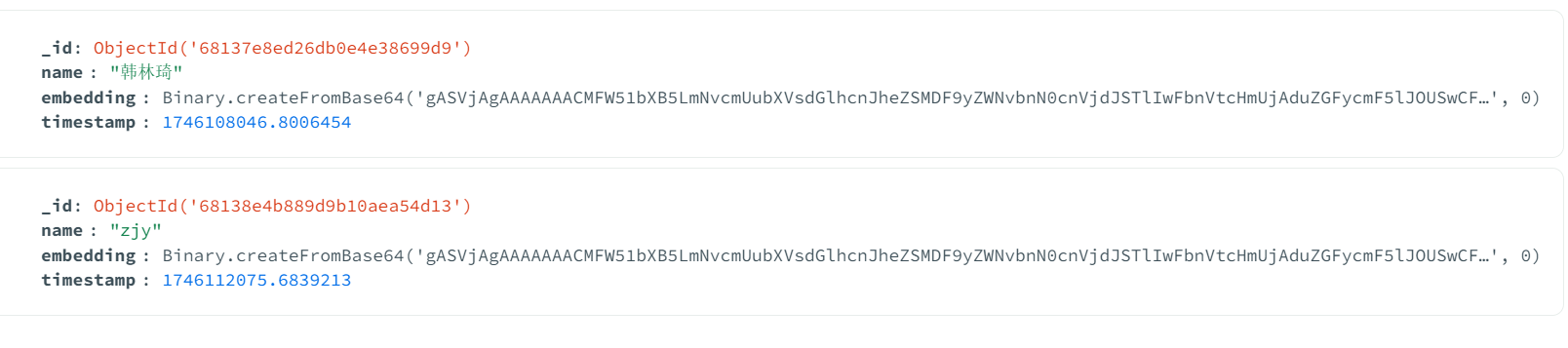
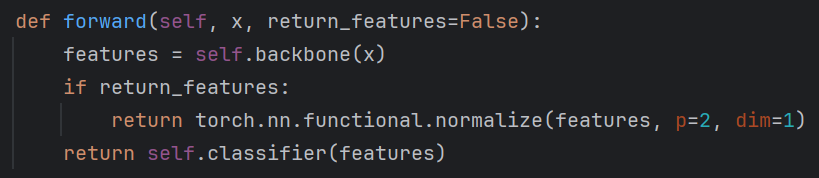
修改模型架构,通过模型返回输入图像的embedding,而不是类别,便于通过embedding的相似度匹配来从人脸注册库中识别对应name。
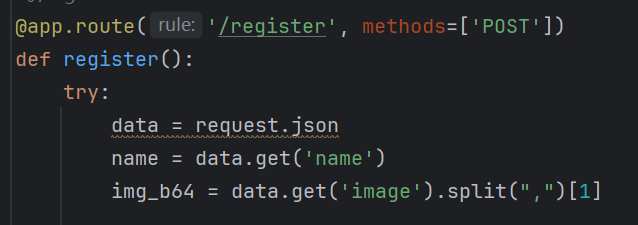
构造人脸注册与人脸识别方法:
在前端构建页面进行人脸注册与识别:
人脸注册功能:
人脸识别功能:

识别失败
识别成功
进一步学习的知识:
1.语音转录模型
语音转录模型(Speech Transcription Model)是一类能够将语音信号自动转换为文字的系统,也称为自动语音识别(ASR)或语音到文本(STT)系统。它融合了计算机科学、计算语言学和信号处理等多学科技术,可广泛应用于字幕生成、会议记录、语音助理和辅助听障人士等场景。
定义
-
语音转录模型旨在“听懂”人类的口语,并输出对应的文字表示,属于计算机科学与计算语言学的交叉领域。
-
在技术实现上,它通常包含音频预处理、声学模型、语言模型与解码后处理等关键模块。
基本组成
1. 预处理
对输入的原始音频进行降噪、端点检测以及特征提取(如梅尔频谱图、MFCC等),为后续模型输入提供稳定、高信息量的特征表示。
2. 声学模型
将音频特征映射到声学单元(音素、音标)或帧级别概率分布。传统方法多采用隐马尔可夫模型(HMM)结合高斯混合模型(GMM),而现代系统则普遍应用深度神经网络(DNN)、卷积网络或循环网络进行端到端建模。
3. 语言模型
借助统计(如 n-gram)或神经网络(如基于 Transformer)方法,对词序列进行建模,以提高识别结果的流畅度和正确率。
4. 解码与后处理
将声学模型和语言模型的输出结合,通过束搜索(Beam Search)等解码算法生成最终文本,并可进行标点符号插入、大小写恢复等后处理步骤。
主流模型架构
DeepSpeech
Mozilla 开源的端到端实时离线语音转录引擎,基于百度 Deep Speech 研究,支持在从树莓派到 GPU 服务器的多种设备上运行。
wav2vec 2.0
Meta AI 提出的自监督学习框架,通过对原始音频的遮掩和对比学习,显著减少对标注数据的依赖,并在多语言与多领域场景中取得优异性能。
Whisper
OpenAI 发布的多任务、多语言自动语音识别系统,训练使用了 680,000 小时的多语种监督数据,对口音和噪声具有较强鲁棒性,并支持多语种翻译功能。
Transformer 端到端模型
采用 Transformer 架构的端到端 ASR,利用自注意力机制并行处理长序列,常与 CTC(连接时序分类)或注意力机制结合,兼具速度与精度优势。
应用场景
-
媒体字幕与视频转写:自动为影视剧、新闻、纪录片等生成字幕,大幅提高制作效率。
-
会议记录与转写:在远程会议、法庭记录和访谈等场合,将口头发言实时转写为文字,方便归档与检索。
-
语音助理与智能家居:为 Siri、Alexa、Google Assistant 等提供语音输入接口,使设备能准确执行用户指令。
-
辅助听障人士:利用实时转录工具(如 Google Live Transcribe、TranscribeGlass)帮助听障者更好地参与对话与社交场景。
-
医疗与法律转写:在医院或法院中,将医患对话、庭审过程自动转写成文本,提高记录效率和准确性。
挑战与发展趋势
主要挑战
-
噪声干扰:背景噪声、多路讲话和信号失真等因素会显著降低识别准确率。
-
口音与方言:不同地域、不同个体的口音差异大,模型在泛化能力上仍存在瓶颈。
-
低资源语言:很多语言的数据稀缺,难以构建高质量的转录模型。
未来趋势
-
多模态融合:结合视觉唇动、手势等多模态信息,提升在嘈杂环境下的识别鲁棒性。
-
自监督与少样本学习:以 wav2vec 2.0 为代表的自监督方法,降低对标注数据的依赖,使低资源语言得到快速支持。
-
模型自适应与在线学习:通过在线微调和用户反馈,持续优化模型性能,适应个体化发音和新环境。
-
端到端轻量化部署:面向移动端和嵌入式设备的模型压缩与加速,实现离线转录和隐私保护。
2.如何强化大模型生成指定格式的文件
(一)、核心实现步骤
1. 定义文档规范
-
模板示例:
# [会议主题] - YYYY/MM/DD ## 参会人员 - 主持人:张三 - 参与人:李四、王五、赵六 ## 会议议程 1. 议题一:项目进度汇报 2. 议题二:风险讨论 3. 议题三:下一步计划 ## 讨论要点 ### 议题一 - 开发进度:已完成80% - 存在问题:测试环境不稳定 ## 决策事项 - 决议:增加测试服务器预算 - 负责人:李四(2023/12/31前完成)
-
格式要求:
-
层级标题使用Markdown语法
-
时间自动填充当前日期
-
责任人标注使用特定标识符
-
2. 构建结构化输入系统
-
数据采集界面:
-
语音实时转写(集成ASR接口)
-
手动补充关键信息输入框:
<input type="text" placeholder="决策事项"> <select id="priority"> <option>普通</option> <option>重要</option> </select>
-
3. 设计大模型提示词
prompt_template = """
根据以下会议记录,生成符合公司标准的会议纪要:
记录内容:"{meeting_text}"
要求格式:
{format_example}
特别注意:
1. 使用二级标题"##"分隔主要议题
2. 决策事项需标注负责人和截止日期
3. 风险项用红色字体标记(HTML格式)
"""
4. 实现模板引擎
-
动态渲染逻辑:
5. 集成大模型API
6. 增加验证层
-
格式检查
(二)、进阶优化方案
1. 智能内容提取
-
使用NER(命名实体识别)自动识别:
-
责任人(标注为
<span class="responsible">) -
时间节点(自动转换为标准日期格式)
-
关键数据(用表格形式呈现)
-
2. 多格式输出支持
(三)、技术选型建议
| 组件 | 推荐方案 | 说明 |
|---|---|---|
| 语音识别 | Azure Cognitive Services | 支持实时流式识别 |
| 大模型平台 | OpenAI GPT-4 | 或本地部署LLM如Llama2 |
| 文档渲染引擎 | Python-docx + Pandoc | 支持Markdown/Word/PDF转换 |
| 前端框架 | Vue3 + Element Plus | 提供丰富表单组件 |
| 存储系统 | MongoDB | 方便存储半结构化数据 |
(四)、实施路线及优化方向
-
基础版
-
实现文本输入生成Markdown文档
-
完成基础模板配置
-
-
增强版
-
集成语音识别
-
添加Word/PDF导出
-
实现自动邮件发送
-
-
智能版
-
部署本地化大模型
-
增加内容审核功能
-
实现多语言支持
-


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









