







Hadoop集群配置
1. 背景
在000002 - Hadoop环境安装,我们已经执行完了如下步骤。接下来就是将不同服务器上的Hadoop配置为一个整体的集群。
- 准备三台Linux服务器,服务器之间相互配置免密ssh登陆
- 在其中一台服务器上安装JDK
- 在其中一台服务器上安装HADOOP
- 本地运行模式-在一台服务器上运行HADOOP
- 将JDK和HADOOP分发给其他2台服务器
- 集群模式运行HADOOP
2. 实践
2.1 集群规划
| 组件\服务器 | node1 | node2 | node3 |
|---|---|---|---|
| HDFS | DateNode + NameNode | DateNode | DateNode + SecondaryNameNode |
| YARN | NodeManager | NodeManager + ResourceManager | NodeManager |
⚠️ NameNode , SecondaryNameNode, ResourceManager互互斥,三者的任意组合都不能配置在一台服务器上。
2.2 配置文件说明
Hadoop 配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认
配置值时,才需要修改自定义配置文件,更改相应属性值。
默认配置文件:
| 要获取的默认文件 | 文件存放在Hadoop 的 jar 包中的位置 |
|---|---|
| core-default.xml | hadoop-common-3.1.3.jar/core-default.xml |
| hdfs-default.xml | hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
| yarn-default.xml | hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
| mapred-default.xml | hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml 四个配置文件存放在
$HADOOP_HOME/etc/hadoop 这个路径上,用户可以根据项目需求重新进行修改配置。
2.3 配置
将集群配置文件分发至三台服务器的/home/ec2-user/software_installation/hadoop-3.1.3/etc/hadoop/目录。配置文件在这里.
2.4 格式化HDFS
- 远程至namenode节点,即node1
- 执行
hdfs namenode -format命令格式化HDFS - 格式化成功后,你会发现在namenode节点多了
/home/ec2-user/software_installation/hadoop-3.1.3/data和/home/ec2-user/software_installation/hadoop-3.1.3/logs目录。
2.5 启动Hadoop集群
- 远程至namenode节点,即node1
- 执行
start-dfs.sh
启动成功后,我们分别使用JPS查看三台服务器上的进程

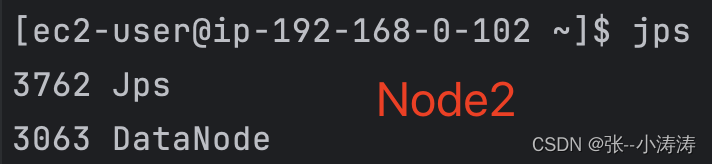
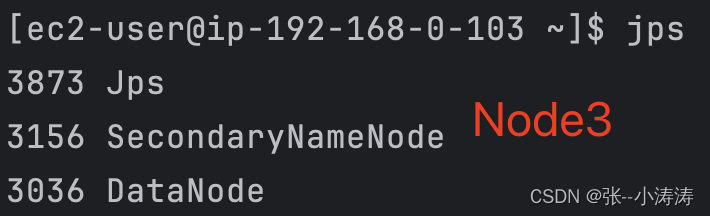
可以看到HDFS已经按照集群规划启动,现在可以访问http://node1_public_ip:9870前往HDFS控制台。
但是YARN还没有,下一步就是启动YARN
2.5 启动YARN集群
- 前往ResourceManager所载节点,即node2上
- 执行下面命令
start-yarn.shYARN
再次分别使用JPS查看三台服务器上的进程
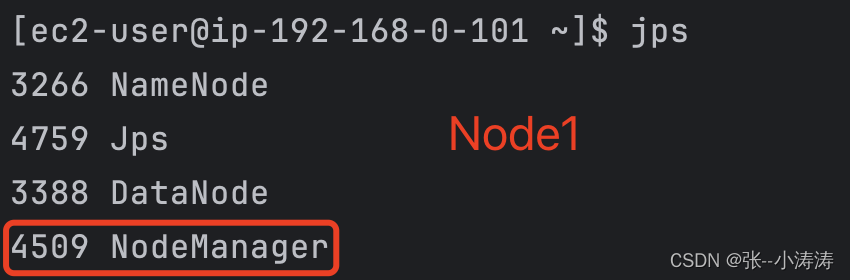
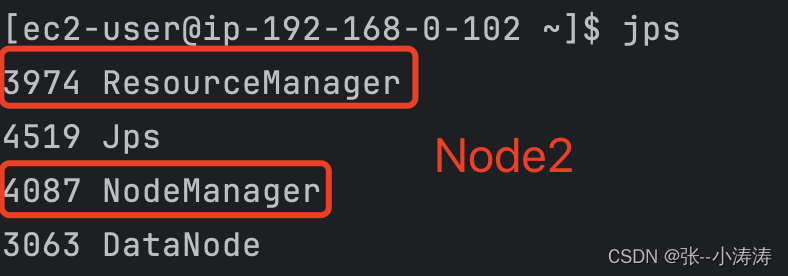
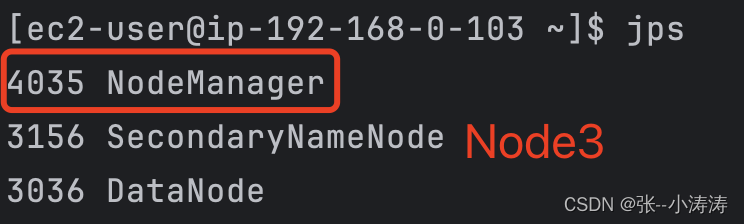
现在可以看到HDFS和YARN都按照集群规划启动了,现在可以访问http://node2_public_ip:8088前往YARN控制台。
3. 测试集群
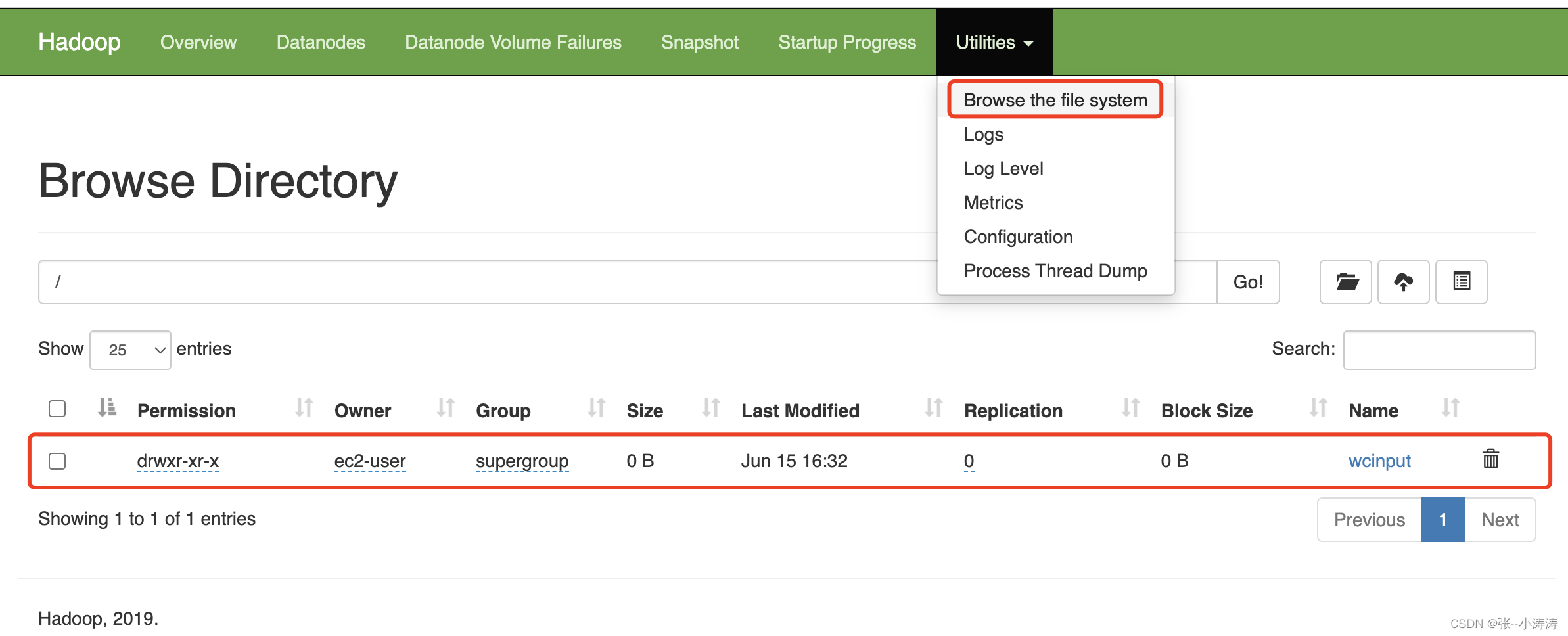
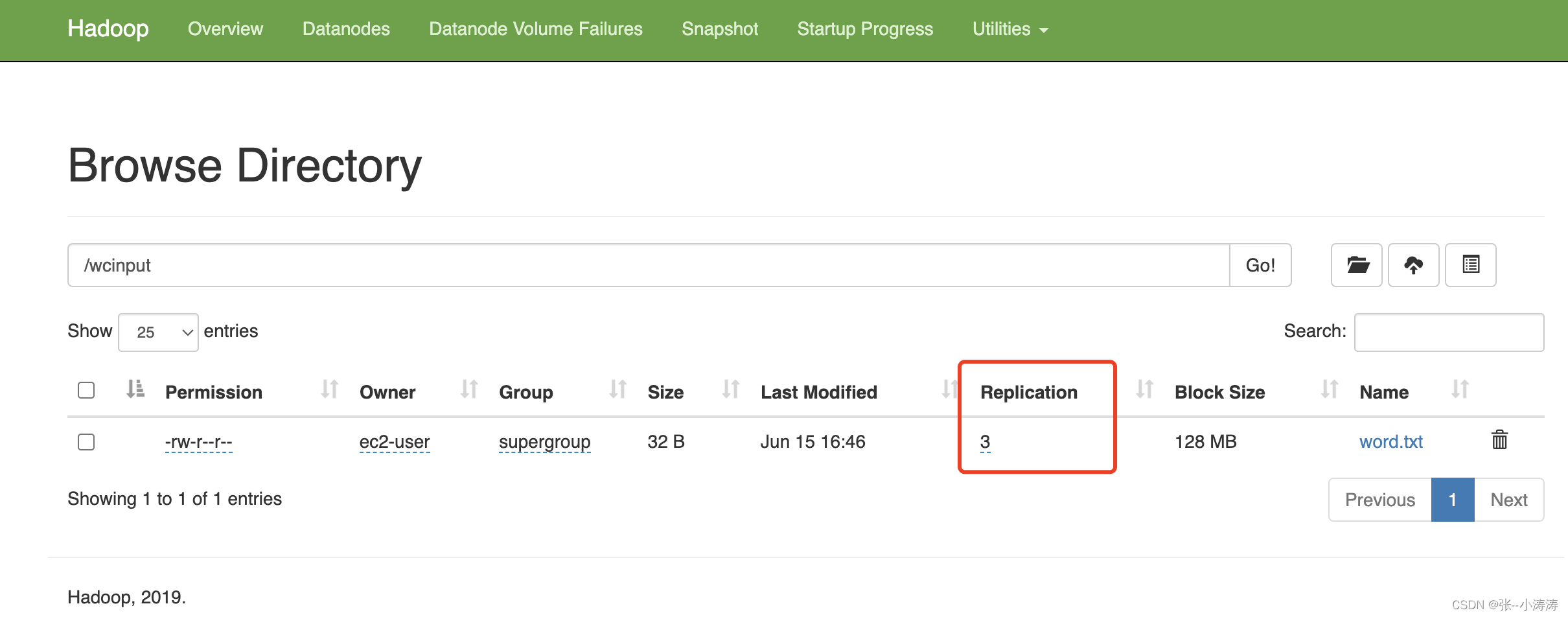
3.1 在任意一台服务器上执行如下命令,在HDFS上创建目录
hadoop fs -mkdir /wcinput
执行完毕后,前往HDFS控制台,便可以看到创建的目录
3.2 上传文件
在任意一台服务器上,准备一个文件word.txt,内容如下
sa sdf
sdfsd aa
aa aa fgfg
sdf
执行如下命令,将其上传至HDFS中
hadoop fs -put word.txt /wcinput
执行完毕后,前往HDFS控制台,便可以看到上传的文件。
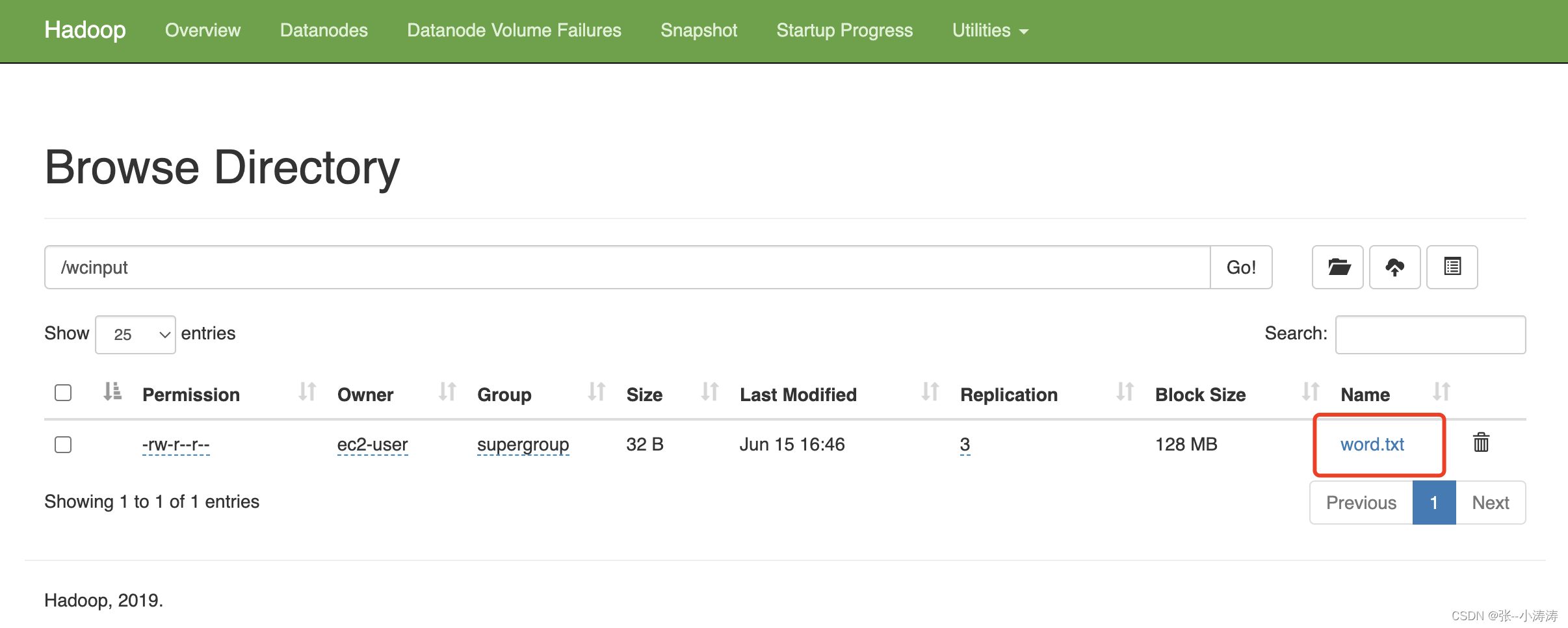
3.3 上传一个大文件
在任意一台服务器上,执行如下命令,将jdk-8u212-linux-x64.tar.gz上传至HDFS中
[ec2-user@ip-192-168-0-103 ~]$ hadoop fs -put /home/ec2-user/software_package/jdk-8u212-linux-x64.tar.gz /
执行完毕后,前往HDFS控制台,便可以看到上传的文件。
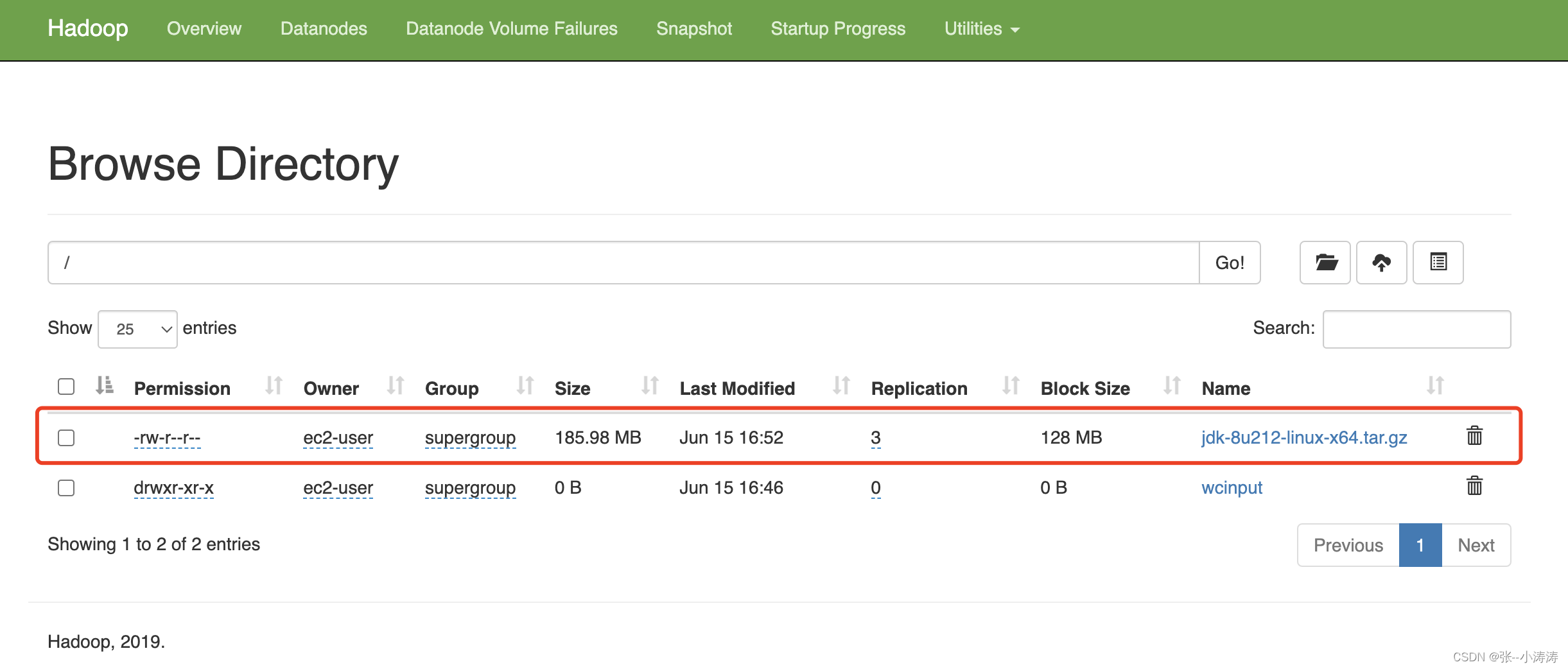
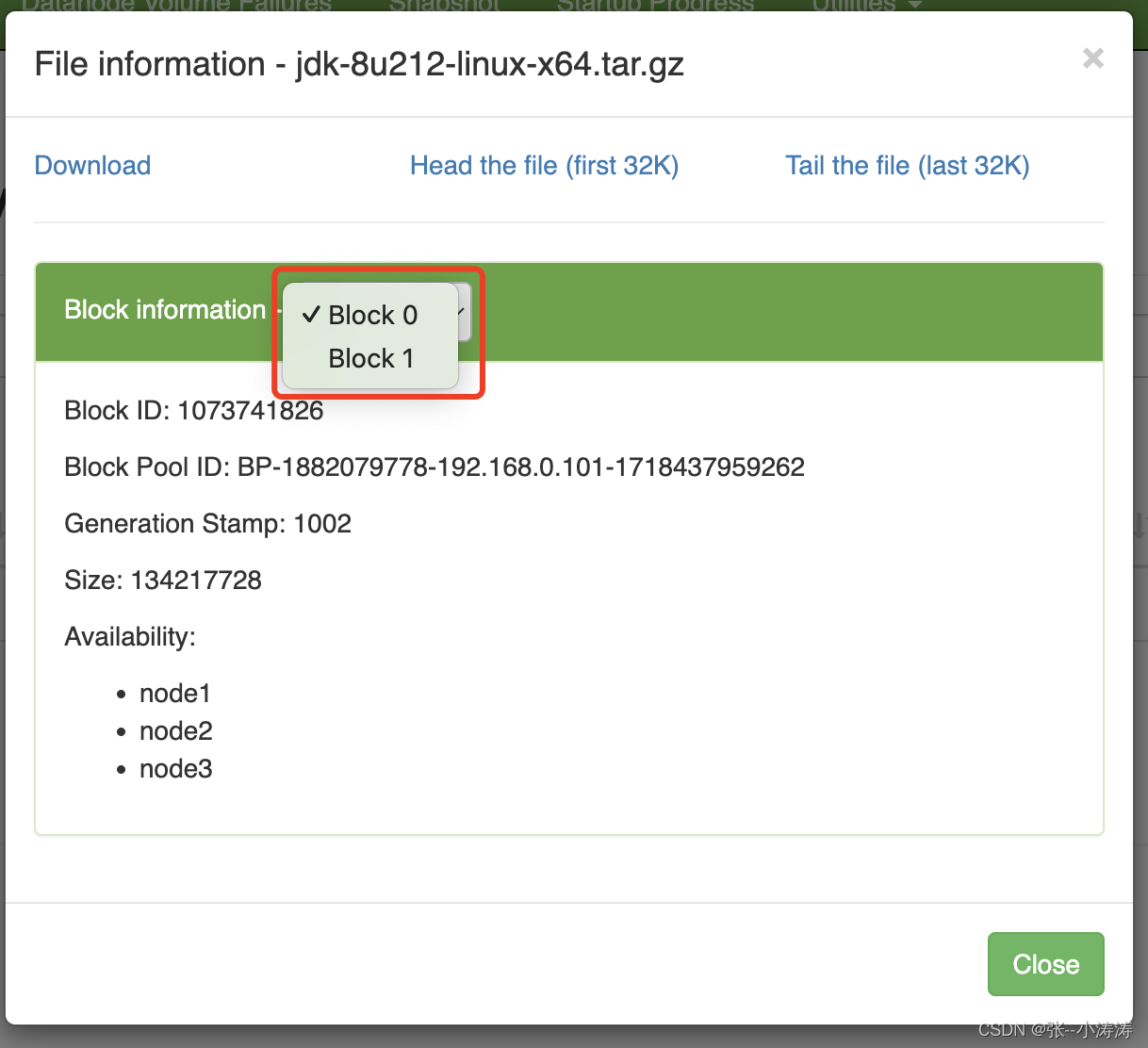
3.4 分析文件存储目录
前往任意一台服务器的/home/ec2-user/software_installation/hadoop-3.1.3/data/dfs/data目录,继续前往current/*/current/* 直至根目录,会看到如下信息
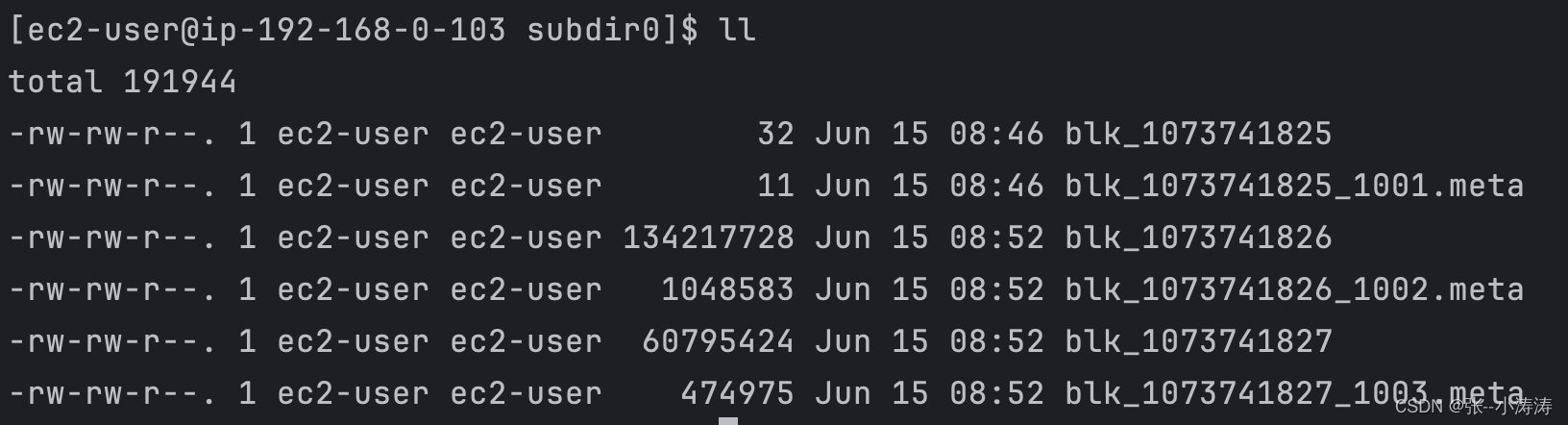
这就是我们上传的文件存储地址,我们先来看看上图中第一个较小的文件
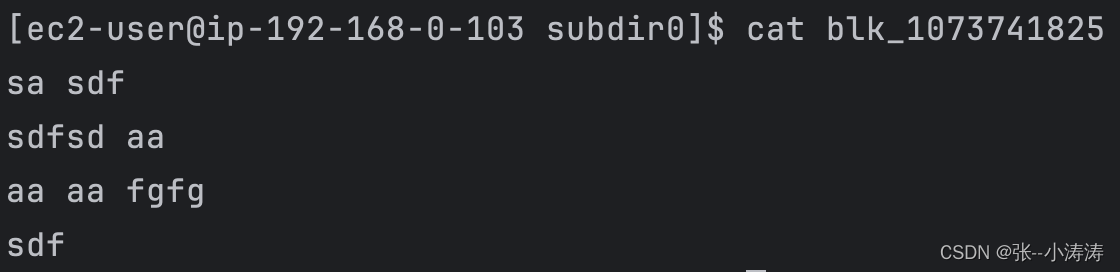
可以看到,文件内容正是我们上传的第一个word.txt,再看看后两个较大的文件,实际上那两个就是被HDFS拆分后的jdk-8u212-linux-x64.tar.gz。我们继续验证一下,执行下方命令将后两个拆分的文件合并后解压
cat blk_1073741826 >> tmp.tar.gz
cat blk_1073741827 >> tmp.tar.gz
tar -zxvf tmp.tar.gz
你会发现,解压出来的内容正是jdk-8u212-linux-x64.tar.gz的内容
3.5 HDFS文件的高可用
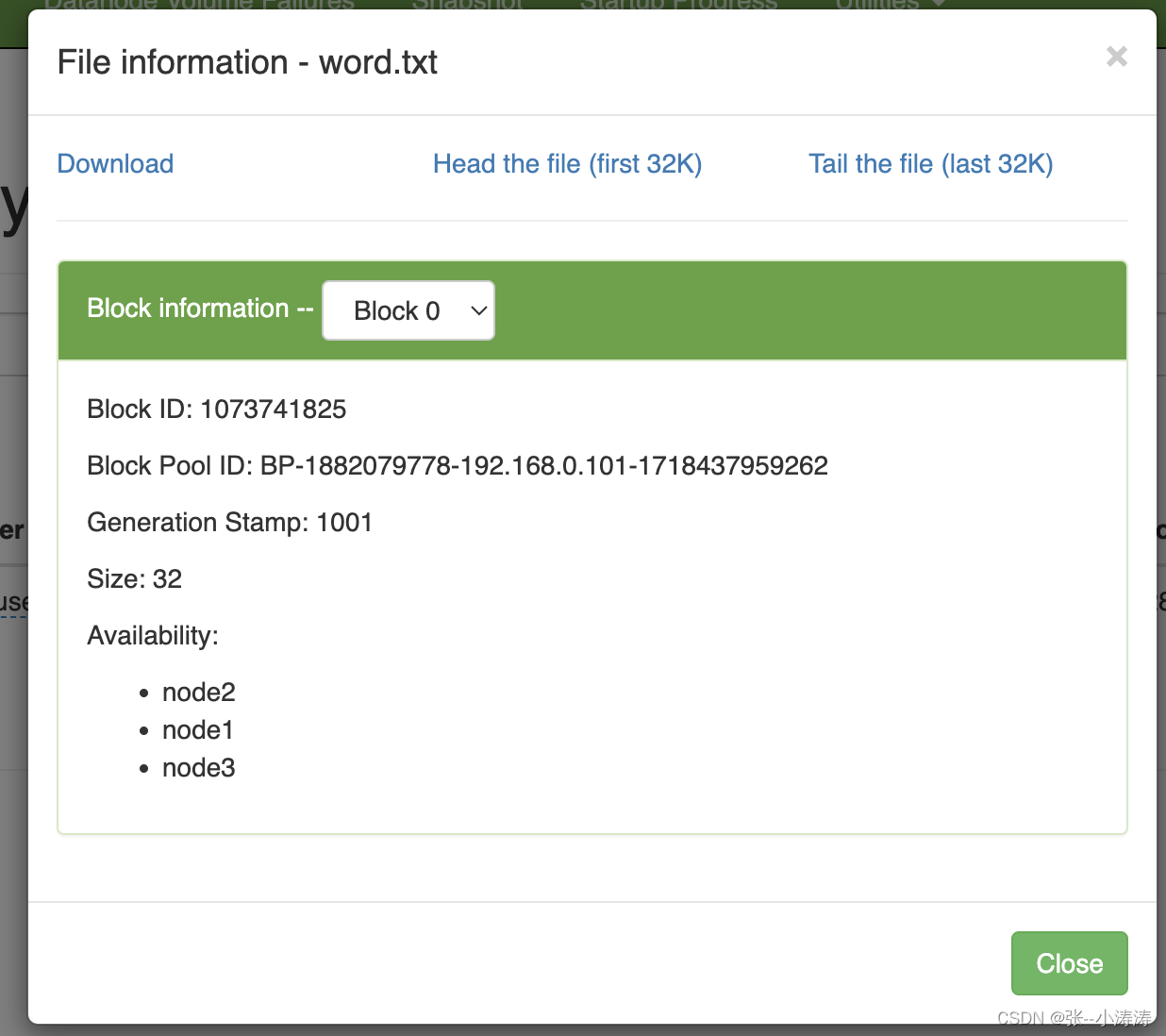
HDFS文件的高可用意味着任意一台服务器上的文件丢失都不会影响文件的访问,即不会导致集群中文件的丢失,这是因为HDFS会将每一份文件块默认存储在3台服务器上,从HDFS的控制台也可以看到
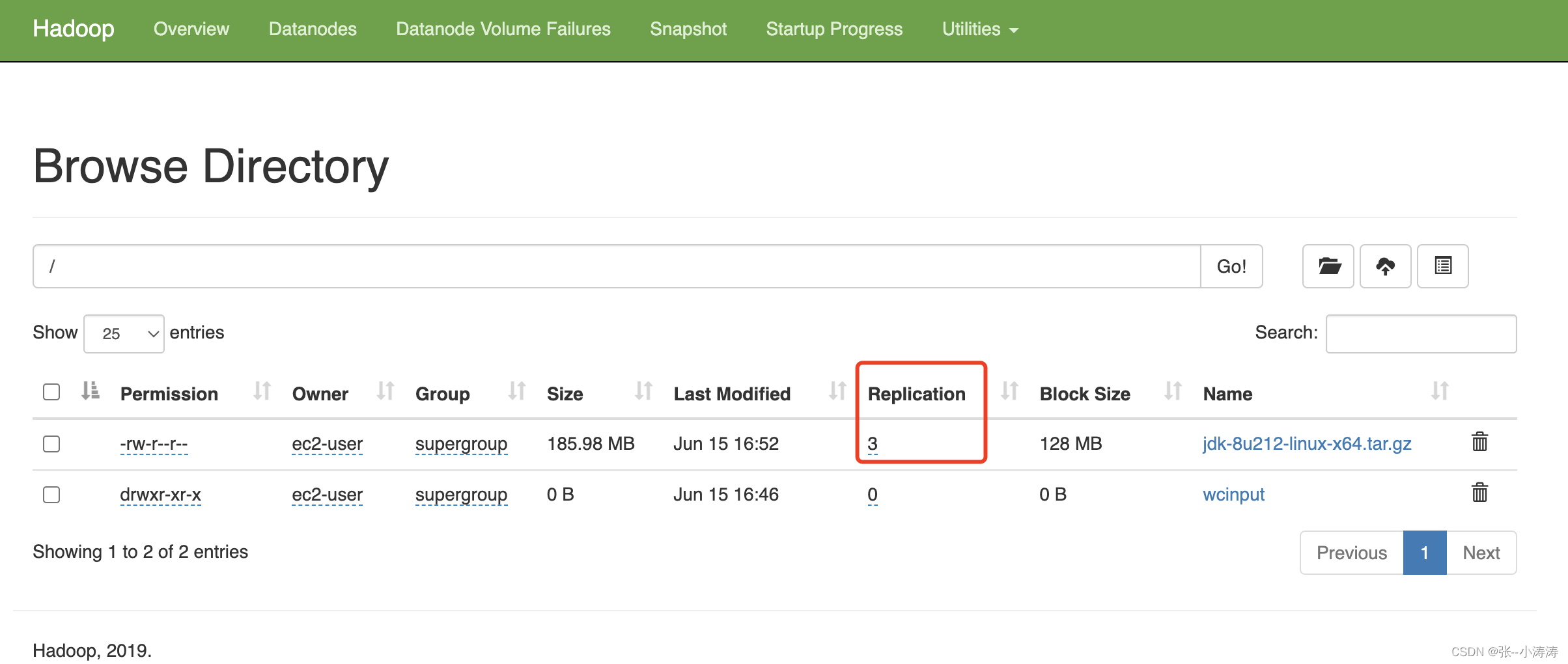
因为我们的集群只有3台服务器,因此我们可以前往3台服务器的data目录,会发现三台服务器的data目录一摸一样。
3.6 使用HDFS和YARN执行一个wordcount程序
前往node1节点,执行如下命令
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /wcoutput
执行开始后,前往YARN控制台,可以看到正在运行的任务
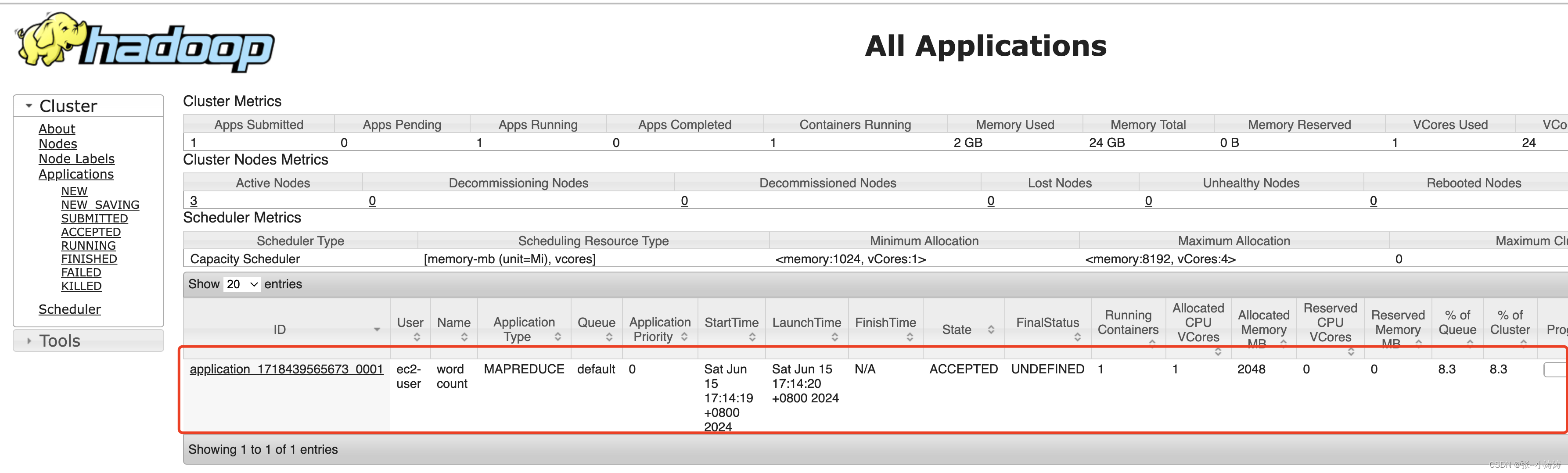
执行完毕后,前往HDFS控制台,可以看到计算结果如下
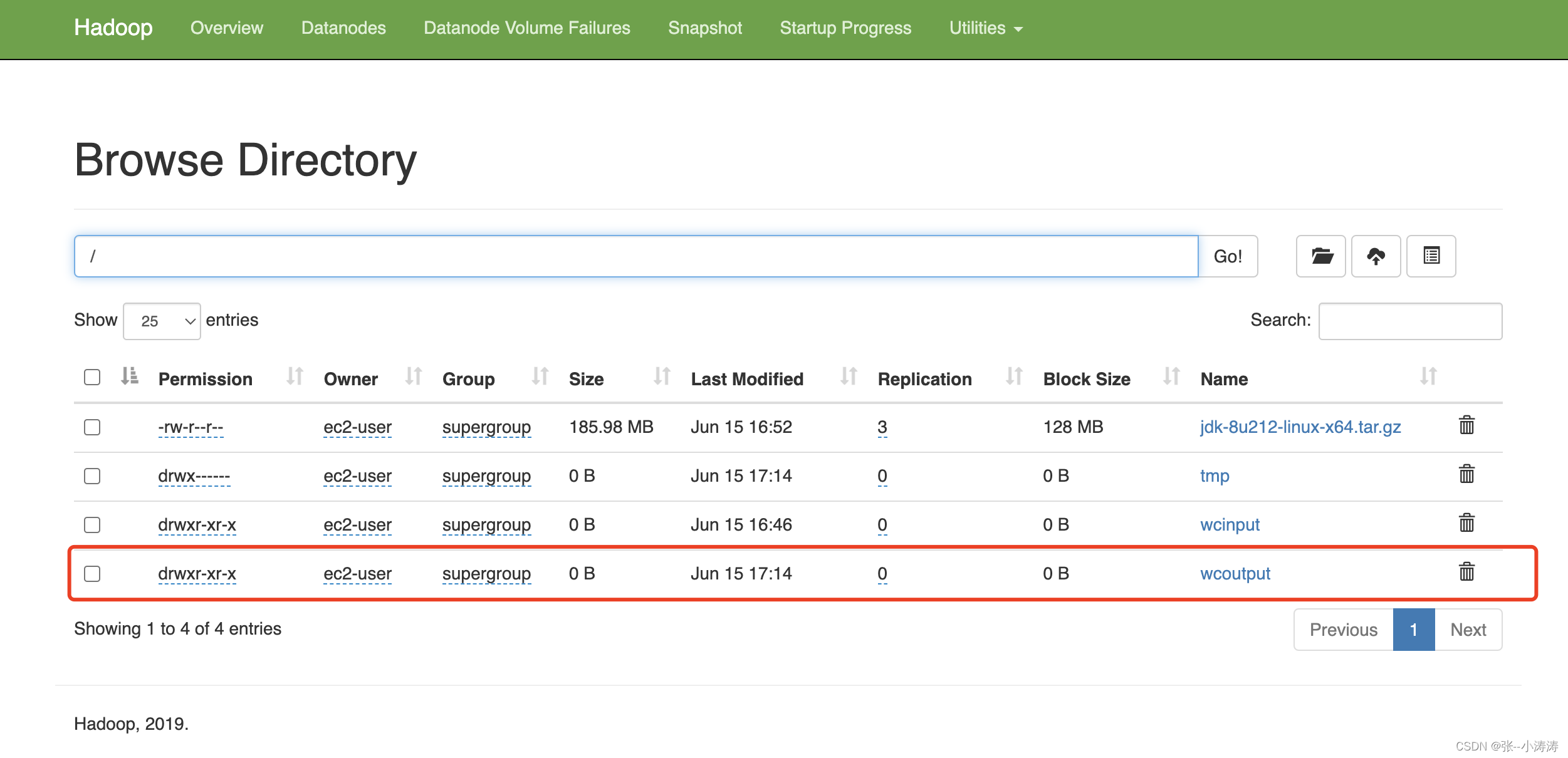
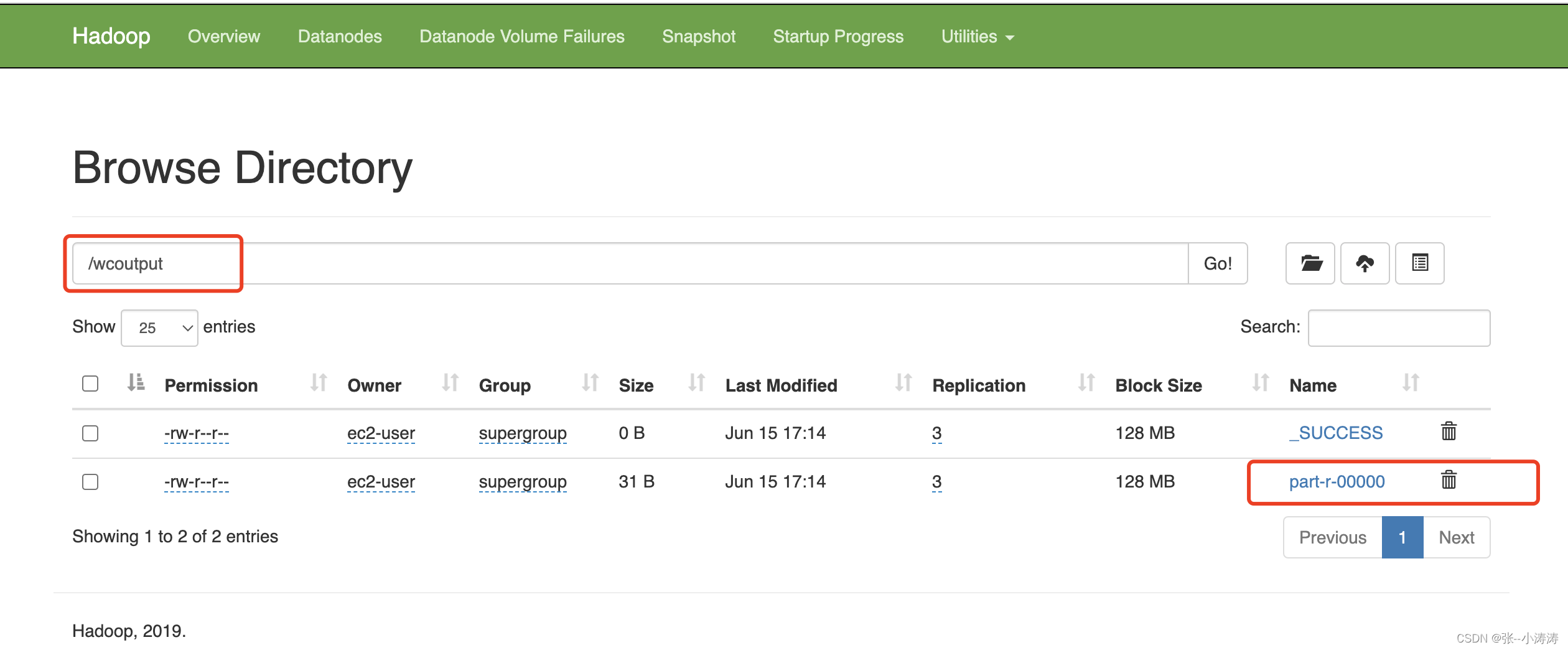
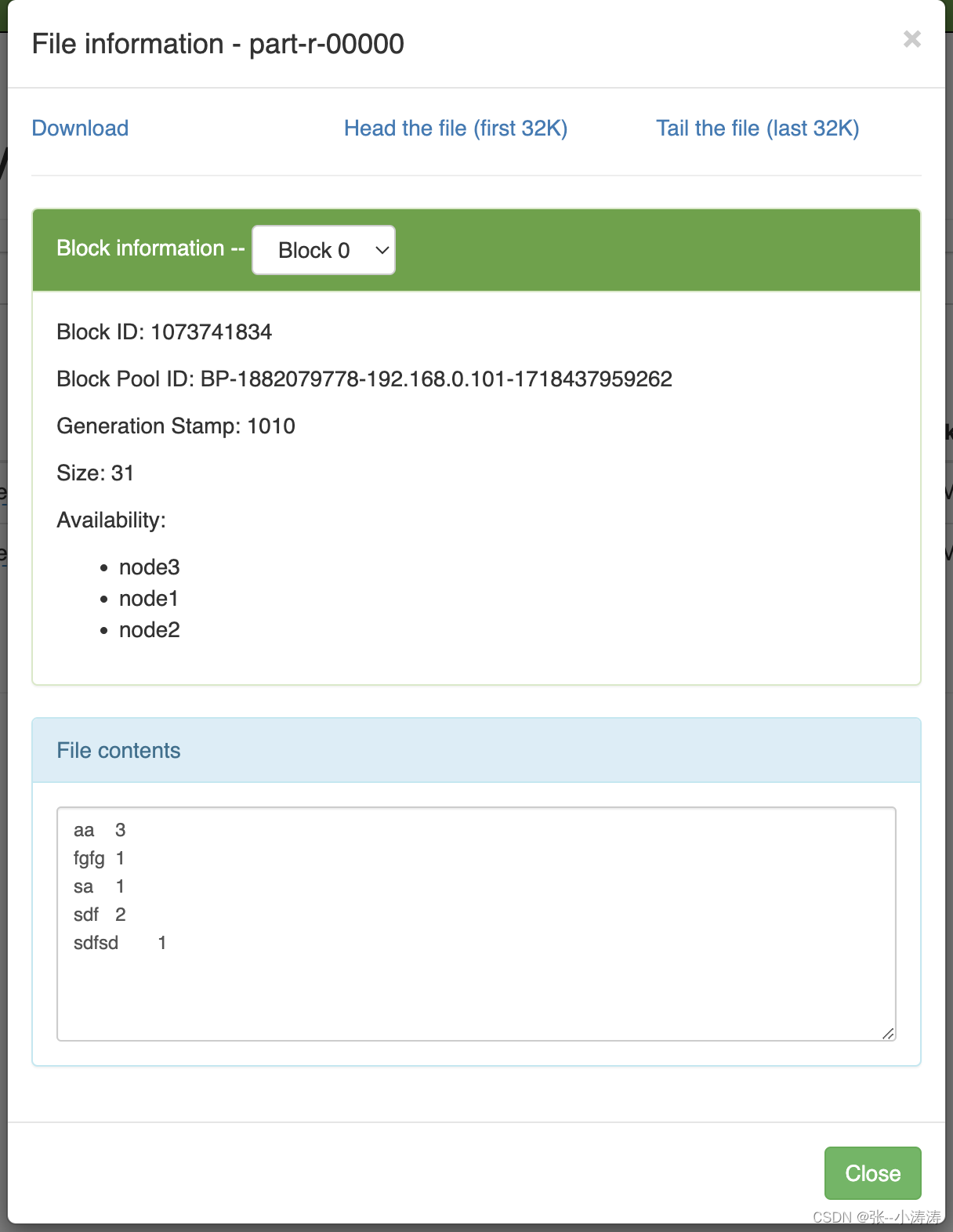
3.7 启动历史服务器
经过上一步,任务已经运行完毕,当我们想要在YARN控制台访问历史运行信息时会发现无法访问
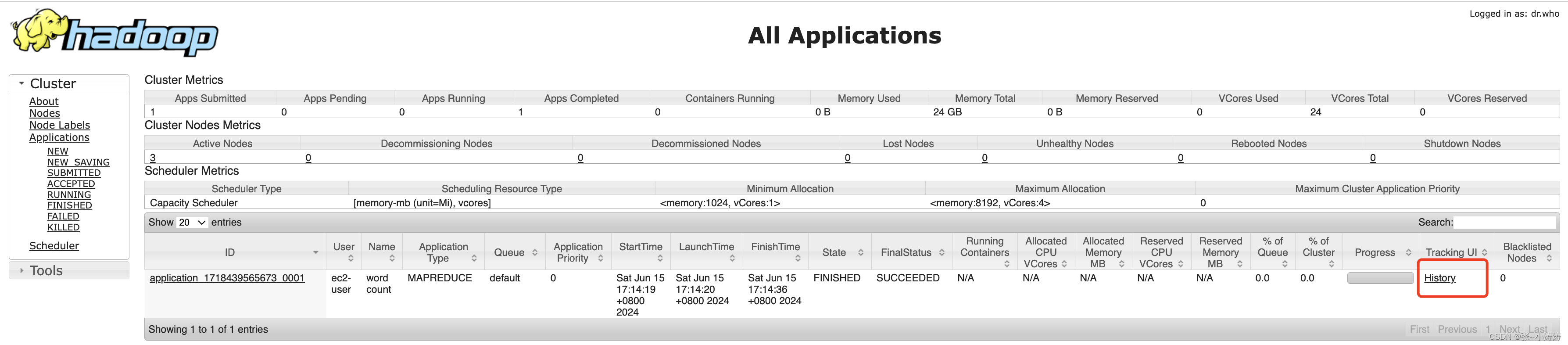
配置很简单,就是给三台服务器上的mapred-site.xml新增如下配置
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<!-- 历史服务器 web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
再在node1上执行下面命令启动历史服务器进程
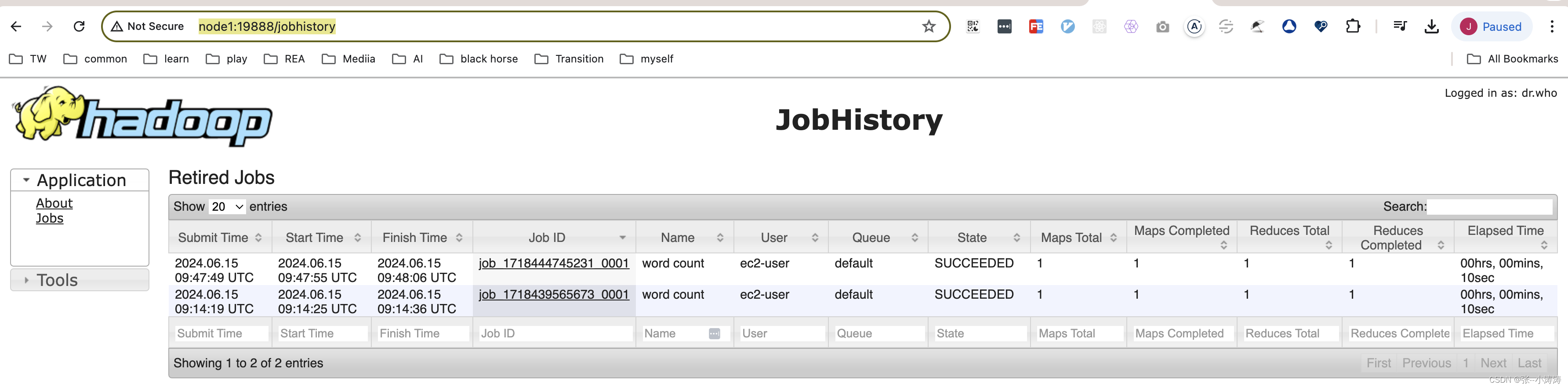
mapred --daemon start historyserver
之后就可以查看历史运行信息了
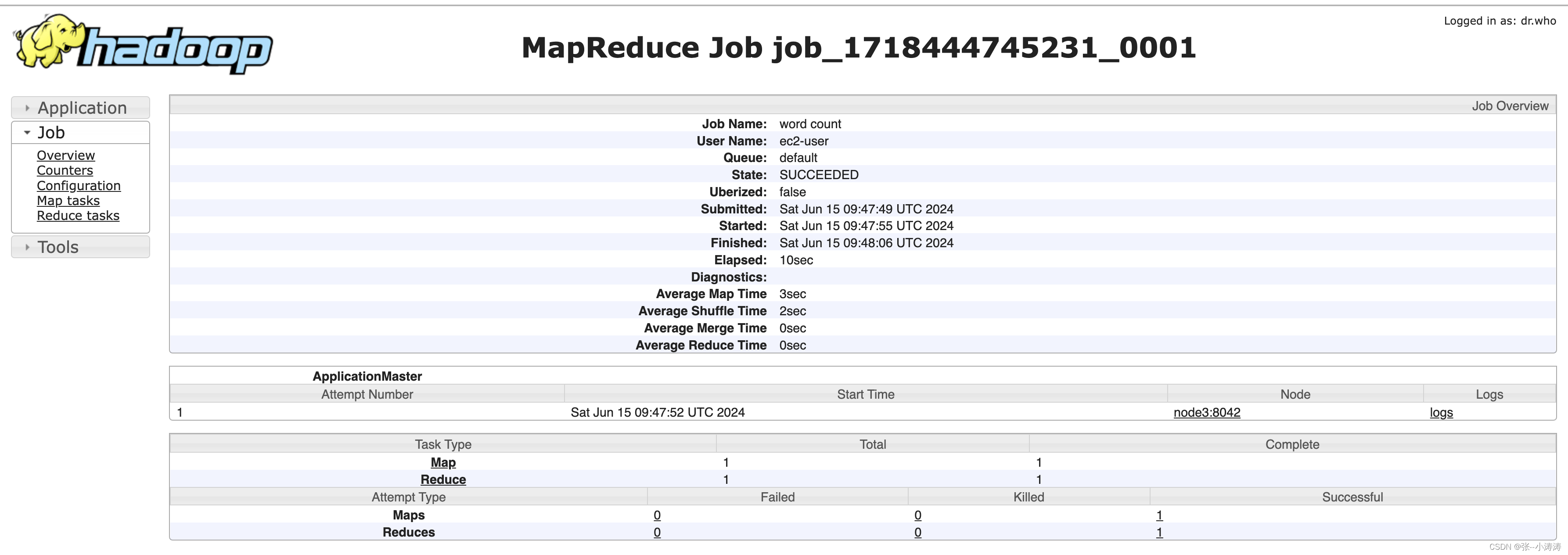
3.8 配置日志聚集功能
当问我们配置完了历史运行服务后,想要查看历史任务的log,如下图
会得到如下信息,提示我们需要开启日志聚合功能

日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS 系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
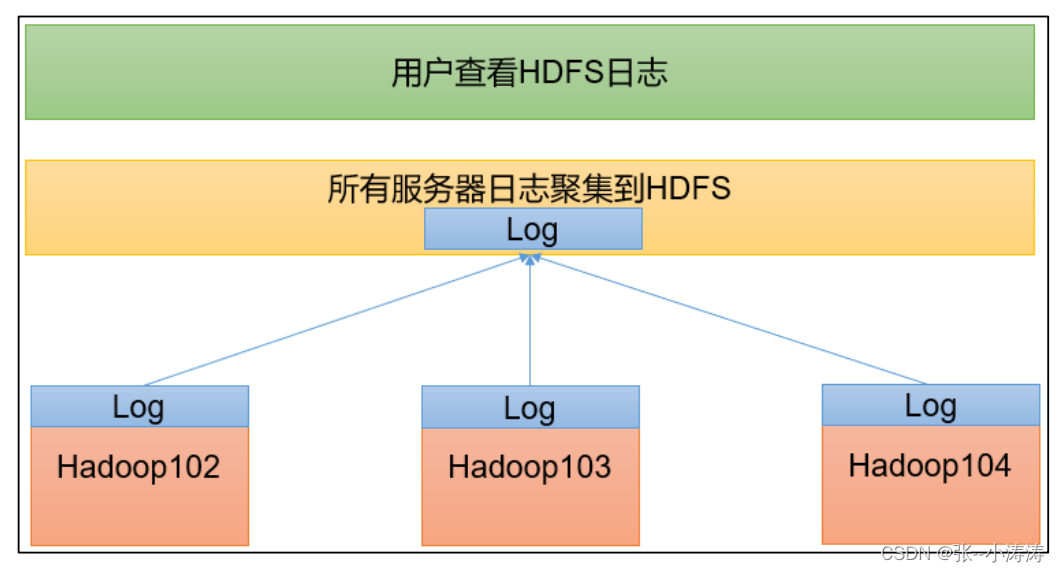
开启日志聚集步骤
1.给yarn-site.xml新增配置如下
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
2.分发至三台服务器
3.重启NodeManager 、ResourceManager 和HistoryServer。
4.然后就可以在控制台看到日志了
4. 自动化部署
当然,为了避免频繁手动操作,我已经使用脚本完成了上述集群配置相关步骤,参考这里
5. 总结
5.1 Hadoop常用端口号
| 端口名称 | Hadoop2.x | Hadoop3.x |
|---|---|---|
| NameNode 内部通信端口 | 8020 / 9000 | 8020 / 9000 / 9820 |
| NameNode HTTP UI | 50070 | 9870 |
| MapReduce 查看执行任务端口 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |
5.2 Hadoop常用配置文件
- 3.X
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
- workers
- 2.X
- core-site.xml
- hdfs-site.xml
- yarn-site.xml
- mapred-site.xml
- slaves















 1357
1357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









