







包含min函数的栈
题目:定义栈的数据结构,要求添加一个min函数,能够得到栈的最小元素。要求函数min、push以及pop的时间复杂度都是O(1)。
思路:
仅仅只添加一个成员变量存放最小元素(或最小元素的位置)是不够的。我们需要一个辅助栈,用来存放每次栈操作时(包括入栈和出栈)栈中最小元素。每次push一个新元素的时候,同时将最小元素push到辅助栈中(如果最小元素没有变化,就把它本身push进去);每次pop一个元素出栈的时候,同时pop辅助栈。
这样一来,就能保证每次栈操作后,辅助栈的栈顶元素都是当前数据栈中的最小值。
class Solution {
public:
stack<int> st, minSt;//st表示存储元素的栈,minSt保存每次栈操作时,保存栈中最小元素
void push(int value) {
st.push(value);
if(minSt.empty()) {
minSt.push(value);
}
else {//如果栈minSt不为空,将value的值与minStrel栈的栈顶元素比较。因为minSt栈的栈顶元素此时为栈中所有元素的最小值
if (value < minSt.top()){
minSt.push(value);
}
else {
minSt.push(minSt.top());
}
}
return;
}
void pop() {//出栈时,需要对两个栈st和minSt同时操作
if (!st.empty()) {
st.pop();
minSt.pop();
}
return;
}
int top() {
if (!st.empty()){
return st.top();
}
return 0;
}
int min() {
if (!minSt.empty()) {
return minSt.top();
}
return 0;
}
};复杂链表的复制
实现函数ComplexListNode* Clone(ComplexListNode* pHead),复制一个复杂链表。
在复杂链表中,每个结点除了有一个pNext指针指向下一个结点之外,还有一个pSibling指向链表中的任意结点或者NULL。
以下图为5个结点的复杂链表,实线表示m_pNext指针的指向,虚线表示m_pSibling指针的指向。
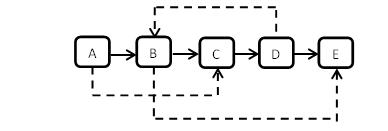
思路:
方法一:哈希表
通过空间换取时间,将原始链表和复制链表的结点通过哈希表对应起来,这样查找的时间就从O(N)变为O(1)。具体如下:
- 复制原始链表上的每个结点N,创建N’;
- 把创建出来的结点用pNext连接起来,同时把
<N,N'>的配对信息存入一个哈希表中; - 设置新链表每个结点的pSibling指针,如果原始链表中结点N的pSibling指向结点S,那么在复制链表中,对应的N’应该指向S’。
时间复杂度:O(N)
struct ComplexListNode{
int val;
ComplexListNode* pNext;
ComplexListNode* pSibling;
ComplexListNode():val(0),pNext(NULL),pSibling(NULL){};
};
//用map定义一个哈希表
typedef std::map<ComplexListNode*,ComplexListNode*> MAP;
ComplexListNode* CloneNodes(ComplexListNode* pHead,MAP &hashNode){
ComplexListNode* pNode=new ComplexListNode();//指向新链表表头的结点
ComplexListNode* p=pNode;
ComplexListNode* tmp;
while(pHead!=NULL){
tmp=new ComplexListNode();
tmp->val=pHead->val;
p->pNext=tmp;
hashNode[pHead]=tmp;
pHead=pHead->pNext;
p=p->pNext;
}
return pNode->pNext;//返回新链表的表头元素
}
//遍历原链表和新链表,在遍历的过程中为新链表的复杂指针赋值
void SetSiblings(ComplexListNode* pHead,ComplexListNode* pCopy,MAP &hashNode){
while(pCopy!=NULL){
pCopy->pSibling=hashNode[pHead->pSibling];
pCopy=pCopy->pNext;
pHead=pHead->pNext;
}
}
ComplexListNode* ComplexListCopy(ComplexListNode* pHead){
ComplexListNode* pCopy;
MAP hashNode;
pCopy=CloneNodes(pHead,hashNode);
SetSiblings(pHead,pCopy,hashNode);
return pCopy;
}方法二:巧妙的原地复制
在不使用辅助空间的情况下实现O(N)的时间效率。
- 根据原始链表的每个结点N创建对应的N’,然后将N’通过pNext接到N的后面;
- 设置复制出来的结点的pSibling。假设原始链表上的N的pSibling指向结点S,那么其对应复制出来的N’是N->pNext指向的结点,同样S’也是结点S->pNext指向的结点。
- 把长链表拆分成两个链表,把奇数位置的结点用pNext连接起来的就是原始链表,把偶数位置的结点通过pNext连接起来的就是复制链表。
struct ComplexListNode{
int val;
ComplexListNode* pNext;
ComplexListNode* pSibling;
ComplexListNode(int x):val(x),pNext(NULL),pSibling(NULL){};
};
void CloneNodes(ComplexListNode* pHead){
ComplexListNode* pNode=pHead;
ComplexListNode* pCloned;
while(pNode!=NULL){
//复制链表结点
pCloned=new ComplexListNode(pNode->val);
pCloned->pNext=pNode->pNext;
pNode->pNext=pCloned;
pNode=pCloned->pNext;
}
}
//复制原结点的pSibling指针到新结点
void ConnectSiblingNodes(ComplexListNode* pHead){
ComplexListNode* pNode=pHead;
ComplexListNode* pCloned;
while(pNode!=NULL){
pCloned=pNode->pNext;
if(pNode->pSibling!=NULL){
pCloned->pSibling=pNode->pSibling->pNext;
}
pNode=pCloned->pNext;
}
}
//分离两个链表
ComplexListNode* ReconnectNodes(ComplexListNode* pHead){
ComplexListNode* pNode=pHead;
ComplexListNode* pClonedHead=NULL;
ComplexListNode* pClonedNode=NULL;
if(pNode!=NULL){
pClonedHead=pClonedNode=pNode->pNext;
pNode->pNext=pClonedNode->pNext;
pNode=pNode->pNext;
}
while(pNode!=NULL){
pClonedNode->pNext=pNode->pNext;
pClonedNode=pClonedNode->pNext;
pNode->pNext=pClonedNode->pNext;
pNode=pNode->pNext;
}
return pClonedHead;
}
ComplexListNode* Clone(ComplexListNode* pHead){
CloneNodes(pHead);
ConnectSiblingNodes(pHead);
return ReconnectNodes(pHead);
}最小的k个数
输入n个整数,找出其中最小的K个数。例如输入4,5,1,6,2,7,3,8这8个数字,则最小的4个数字是1,2,3,4。
思路:
方法一:快速排序
通过快排找到第k个数,然后比他的小的都在左边,比他大的都在右边。
当然这种方式会改变原数组的排列顺序。
//在low和high中随机选择一个数
int random(int low, int high) {
int size = high - low + 1;
return low + rand() % size;
}
//交换a和b
void swap(int *a, int *b) {
int temp;
temp = *a;
*a = *b;
*b = temp;
}
//快速排序
int partition(int *a, int left, int right) {
int index = random(left, right); //随机选择一个位置上的数
swap(&a[index], &a[right]); //将该数和最右边的元素交换
int key = a[right]; //key是随机选择的,作为中间数的元素
int small = left - 1;
for(index = left; index < right; index++) {
if(a[index] < key) {
small++;
if(small != index)
swap(&a[small], &a[index]);
}
}
small++;
swap(&a[small], &a[right]); //最后,将中间数移到中间
return i; //返回中间数所在的位置
}
//直到确定了最小的第k个数,这样它左边的数全比它小,于是就找到了最小的k个数
int randomized_select(int *a, int left, int right, int k) {
if(left < 0 || (right - left + 1) < k)
return -1;
int pos = partition(a, left, right);
int m = pos - left + 1;
if(k == m) {
return pos;
} else if(k < m) {
return randomized_select(a, left, pos - 1, k);
} else {
return randomized_select(a, pos + 1, right, k - m);
}
} 方法二:最大堆(适合海量数据)
数组中的逆序对
在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。
例如“7,5,6,4”,逆序对有“7 5”、“7 6”、“7 4”、“5 4”、“6 4”共5个。
思路:
基于归并排序,思路不变,只是在排序的过程中添加了求逆序对的代码。
public class MergeSort {
static int count = 0;
// 将两个有序数列:a[first...mid]和a[mid...last]合并。
static void mergearray(int a[], int first, int mid, int last, int temp[]) {
int i = first, j = mid + 1;
int m = mid, n = last;
int k = 0;
while (i <= m && j <= n) {
if (a[i] > a[j]) {
// 左数组比右数组大
temp[k++] = a[j++];
// 如果a[i]此时比右数组的当前元素a[j]大,那么左数组中a[i]后面的元素就都比a[j]大,由此更新逆序数的个数
count += mid - i + 1;
}
else
temp[k++] = a[i++];
}
while (i <= m) {
temp[k++] = a[i++];
}
while (j <= n) {
temp[k++] = a[j++];
}
for (i = 0; i < k; i++)
a[first + i] = temp[i];
}
//先将左右两部分分别排序,再归并
static void mergesort(int a[], int first, int last, int temp[]) {
if (first < last) {
int mid = (first + last) / 2;
mergesort(a, first, mid, temp); // 左边有序
mergesort(a, mid + 1, last, temp); // 右边有序
mergearray(a, first, mid, last, temp); // 再将二个有序数列合并
}
}
static void Sort(int a[]) {
int[] p = new int[a.length];
mergesort(a, 0, a.length - 1, p);
}
} n个骰子的点数
题目:把n个骰子扔在地上,所有骰子朝上一面的点数之和为S。输入n,打印出S的所有可能的值出现的概率。
思路:
变量有:骰子个数,点数和。当有k个骰子,点数和为n时,出现次数记为f(k,n)。那与k-1个骰子时的关系是怎样的?
当我有k-1个骰子时,再增加一个骰子,这个骰子的点数只可能为1、2、3、4、5或6。那k个骰子得到点数和为n的情况有:
(k-1,n-1):第k个骰子投了点数1
(k-1,n-2):第k个骰子投了点数2
(k-1,n-3):第k个骰子投了点数3
….
(k-1,n-6):第k个骰子投了点数6
在k-1个骰子的基础上,再增加一个骰子出现点数和为n的结果只有这6种情况!
所以:
f(k,n)=f(k-1,n-1)+f(k-1,n-2)+f(k-1,n-3)+f(k-1,n-4)+f(k-1,n-5)+f(k-1,n-6)最开始,有1个骰子,f(1,1)=f(1,2)=f(1,3)=f(1,4)=f(1,5)=f(1,6)=1。
//计算n个骰子某次投掷点数和为s的出现次数
int CN(int n, int s) {
//n个骰子点数之和范围在n到6n之间,否则数据不合法
if(s < n || s > 6*n)
return 0;
//当有一个骰子时,一次骰子点数为s(1 <= s <= 6)的次数当然是1
if(n == 1)
return 1;
else
return CN(n-1, s-6) + CN(n-1, s-5) + CN(n-1, s-4) + CN(n-1, s-3) + CN(n-1, s-2) + CN(n-1, s-1);
}
void listDiceProbability(int n) {
int i=0;
unsigned int nTotal = pow((double)6, n);//根据排列组合只是,S的所有可能
for(i = n; i <= 6 * n; i++) {
printf("P(s=%d) = %d/%d\n", i, CountNumber(n,i), nTotal);
}
}
约瑟夫环问题
N个人按顺时针围成一个圈,从1到N,然后报数,报到M的人就出去,然后剩余的人仍然围成一个圈,从出局的人下一个人开始重新报数,数到M的人出局,如此循环。问最后剩下的人的编号。
思路:
方法一:
最直观的循环链表,模拟游戏的过程,直到只剩下一个元素。
方法二:
数学规律。
第一个人(编号是m%n-1) 出列之后,剩下的n-1个人组成了一个新的约瑟夫环(以编号为k=m%n的人开始):
k k+1 k+2 … n-2, n-1, 0, 1, 2, … k-2并且从k开始报0。
现在我们把他们的编号做一下转换:
k –> 0
k+1 –> 1
k+2 –> 2
…
…
k-2 –> n-2
k-1 –> n-1
变换后就完全成为了(n-1)个人报数的子问题,假如我们知道这个子问题的解:例如x是最终的胜利者,那么根据上面这个表把这个x变回去,就刚好是原问题,即n个人情况的解吗。变回去的公式很简单:x'=(x+k)%n。
如何知道(n-1)个人报数的问题的解?对,只要知道(n-2)个人的解就行了。(n-2)个人的解呢?当然是先求(n-3)的情况……这显然就是一个倒推问题。
最终可以得到递推公式:
f[1]=0;
f[i]=(f[i-1]+m)%i; (i>1)不用加减乘除做加法
题目:写一个函数实现加法,要求不使用加减乘除四则运算符。
思路:
十进制加法可分三步:1,只做各位相加不进位;2,做进位;3,把前面两个结果相加;
我们可以将十进制的这三个步骤用二进制位运算来实现。
例如,5+17=22,5是101,17是10001。第一步各位相加,得到的结果为10100(不考虑进位),这就可以用异或实现;第二步记下进位,为10,可用&操作实现;第三步把前两步的结果相加,得到10110,转换成十进制正好为22。重复上述过程,直到不产生进位为止。
int Add(int num1, int num2)
{
int sum, carray;
do {
sum = num1 ^ num2;
carray = (num1 & num2) <<1;
num1 = sum;
num2 = carray;
} while (num2!=0);
return sum;
}蘑菇阵
现在有两个好友A和B,住在一片长有蘑菇的由n*m个方格组成的草地,A在(1,1),B在(n,m)。现在A想要拜访B,由于她只想去B的家,所以每次她只会走(i,j+1)或(i+1,j)这样的路线,在草地上有k个蘑菇种在格子里(多个蘑菇可能在同一方格),问:A如果每一步随机选择的话(若她在边界上,则只有一种选择),那么她不碰到蘑菇走到B的家的概率是多少?
思路:
动态规划,注意每个点的概率来源。第1行的点,如(1,3)的概率来源只有它左边点(1,2)的概率乘以0.5;第n行的点如(n,3),概率来源为(n,2)+(n-1,3)*0.5,因为(n,2)只能往右走,其概率为1。
#include <iostream>
#include <vector>
#include <string>
#include<stack>
#include<queue>
#include<set>
#include<map>
#include <numeric>
#include<limits.h>
#include <algorithm>
#include <cassert>
using namespace std;
int main() {
int n,m,k;
int x,y;
while(cin>>n>>m>>k) {
float P=0;
int count=0;
vector<vector<int>> map(n+1,vector<int>(m+1,0));
vector<vector<float>> dp(n+1,vector<float>(m+1,0));
for(int i=0;i<k;i++) {
cin>>x>>y;
map[x][y]=1;
}
for(int i=1;i<=n;i++)
for(int j=1;j<=m;j++) {
if(i==1 && j==1) {dp[i][j]=1;continue;}
if(map[i][j]==1) {dp[i][j]=0;continue;}//如果这一小格里有蘑菇
if(i == n && j == m) {dp[i][j] = dp[i-1][j] + dp[i][j-1]; continue;}
if(i == n) {dp[i][j] = dp[i-1][j]*0.5 + dp[i][j-1]; continue;}
if(j == m) {dp[i][j] = dp[i-1][j] + dp[i][j-1]*0.5; continue;}
if(i == 1) {dp[i][j] = dp[i][j-1]*0.5; continue;}
if(j == 1) {dp[i][j] = dp[i-1][j]*0.5; continue;}
dp[i][j] = dp[i][j-1]*0.5 + dp[i-1][j]*0.5;
}
printf("%.2f\n",dp[n][m]);
}
return 0;
}int的二进制逆序输出
思路:
从第0位到第31位,把a的二进制的每一位取出,然后移到相应的位置。
int reverse(int a)
{
int ans = 0;
for (int n = 31; n >= 0; n--)
{
ans |= (a&1)<<n;
a >>= 1;
}
return ans;
}数组中出现次数超过一半的数
数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。
例如输入一个长度为9的数组{1,2,3,2,2,2,5,4,2}。由于数字2在数组中出现了5次,超过数组长度的一半,因此输出2。
思路:
数组中有一个数字出现的次数超过数组长度的一半,也就是说它出现的次数比其他所有数字出现的次数的和还要多。因此我们可以考虑用两个变量:一个保存一个数字,一个保存次数。
开始时,保存数组中第一个元素,次数设置为1;
遍历数组:
- 如果下一个数字和之前保存的数字相同,则次数递增1;
- 如果下一个数字和之前保存的数字不同,则次数递减1;
- 如果次数为零,我们需要保存下一个数字,并把次数设为1。
由于我们要找的数字出现的次数比其他所有数字出现的次数之和还要多,那么要找的数字肯定是最后一次把次数设为1时对应的数字。
其实整个过程可以抽象成“虚拟栈”,如果某数等于栈顶元素,则入栈;否则,弹栈。
int morethanhalf2(int numbers[],int length)
{
int re=numbers[0];
int num=1;
for(int i=1;i<length;i++)
{
if(re==numbers[i])
num++;
else
num--;
if(num==0)
{
re=numbers[i];
num++;
}
}
return re;
}strcpy函数
char *strcpy(char *strDes,const char *strSrc)
{
assert(strSrc!=NULL);
char *p=strDes;
while((*p++=*strSrc++)!='\0');
return strDes;
}strcmp函数
比较两个字符串
设这两个字符串为str1,str2,
若str1==str2,则返回零;
若str1>str2,则返回正数;
若str1
int strcmp(const char *str1, const char *str2)
{
assert(NULL != str1 && NULL != str2);
/*不可用while(*str1++==*str2++)来比较,当不相等时仍会执行一次++,
return返回的比较值实际上是下一个字符。应将++放到循环体中进行。*/
while(*str1 && *str2 && *str1 == *str2)
{
str1++;
str2++;
}
return *str1 - *str2;
}strcat函数
char *strcat(char *dest,const char *src)
{
assert(NULL != dest && NULL != src);
char *temp = dest;
//先定位到dest的末尾
while ('\0' != *temp)
++temp;
while ((*temp++ = *src++) != '\0');
return dest;
}strlen函数
计算给定字符串的(unsigned int型)长度,不包括’\0’在内。
unsigned int strlen(const char *s)
{
assert(NULL != s);
unsigned int len = 0;
while (*s++ != '\0')
++len;
return len;
}memset函数
将s中前n个字节 (typedef unsigned int size_t )用 ch 替换并返回 s 。
memset:作用是在一段内存块中填充某个给定的值,它是对较大的结构体或数组进行清零操作的一种最快方法。
注意,memset是以【字节】为单位进行赋值的。
void *memset(void *s,int c,unsigned int n) //s指针类型未知,另外,n为字节数
{
assert(NULL != s);
void *temp = s;
while (n--)
{
*(char *temp) = (char)c; //转化为字符(1字节)
temp = (char *)temp + 1; //不能自增,因为不知道指针类型
}
return s;
}memcpy()
内存拷贝函数,memcpy函数的功能是从源src所指的内存地址的起始位置开始拷贝n个字节到目标dest所指的内存地址的起始位置中。
void *memcpy(void *dest, const void *src, size_t n)
{
assert(NULL != dest && NULL != src);
int i = 0;
void *temp = dest;
while (i < n)
{
*((char *)temp + i) = *((char *)src + i); //未知类型,不能自增
++i;
}
return dest;
}atoi和itoa函数
atoi:
字符串转整型,考察各种特殊情况:空指针、空串、正负号、非法字符、溢出等等。
int atoi(const char* str)
{
int result = 0;
int sign = 0;
assert(str != NULL);
if (*str=='-')
{
sign = 1;
++str;
}
else if (*str=='+')
{
++str;
}
while (*str>='0' && *str<='9')
{
result = result*10 + *str - '0';
++str;
}
// return result
if (sign==1)
return -result;
else
return result;
} itoa:
整型转字符串
//value:欲转换的数据。string:目标字符串的地址。radix:转换后的进制数,可以是10进制、16进制等
char *itoa(int val, char *buf, unsigned radix)
{
char *p;
char *firstdig;
char temp;
unsigned digval;
p = buf;
//如果val是负数
if(val <0)
{
*p++ = '-';
val = -val;
}
firstdig = p;
do{
digval = (unsigned)(val % radix);
val /= radix;
if (digval > 9)
*p++ = (char)(digval - 10 + 'a');
else
*p++ = (char)(digval + '0');
}while(val > 0);
*p-- = '\0 ';
//生成的数字是逆序的,所以要逆序输出
do{
temp = *p;
*p = *firstdig;
*firstdig = temp;
--p;
++firstdig;
}while(firstdig < p);
return buf;
}














 1739
1739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









