






背景
最近优化了一条join sql,搞了一天半,把查询时间从50s,降到0.04s,发现了很神奇的事情,join的主表居然是会变的,同时对mysql有了更深的了解,记录一下
sql语句如下
SELECT
`A_filed_*`,
`B_filed_*`,
`C_filed_*`
FROM
`A`
LEFT JOIN `B` ON `A_id` = `B_id`
LEFT JOIN `C` ON `A_id` = `C_id`
WHERE
`A_filed_1` = "1"
AND `A_filed_2` IN (X,X,X)
ORDER BY
`B_id` DESC
limit 10 offset 0
就这样的一条三表join的sql语句,根据A_filed_2的不同,数据量会有差异,我们假定有两个不同的A_filed_2条件差生了不同的结果。
X条件,数据量为350628,执行时间为50s+
Y条件,数据量为1804221,执行时间为0.05s
查看过程
然后我就奇了个大怪,数据量上没差多少,对于mysql来说,几千万的数据量才会有瓶颈问题,这种几十上百万的量,不应该有什么问题。
索引问题?查询条件的字段、排序的字段都有索引,排除。
看不出问题,上explain吧,如下图(方便看,去掉了不重要的内容)
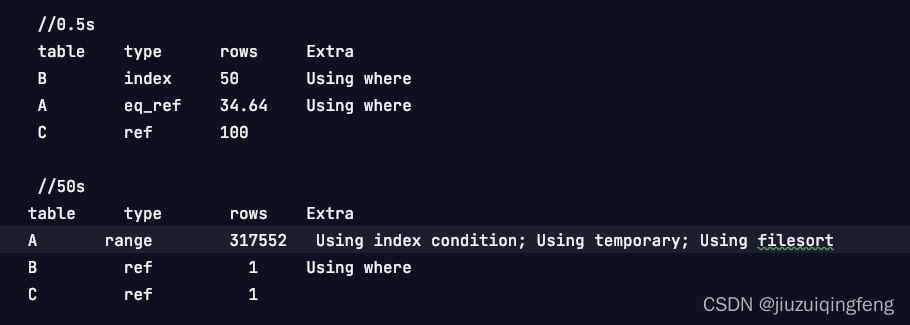
从type上看不出区别,但是rows、以及EXTRA上有明显的区别,原因是什么呢?
(中间查过很多东西,改写sql,各种尝试就略过了,直接跳到答案)
在一次排查中,我把50s的sql的order by 改成了A_id,时间瞬间降下来了,变成了0.4s
顺着这里,我发现,主要是50s sql,使用了filesort,这个东西很费时间。产生的原因是,主表是A,但是使用的是B表的字段排序,这就让mysql要把关联的表一次次的读写来排序,数据量怕是个恐怖数字。
那么为什么Y条件没有这个问题呢?看上面的explain就能知道,在这里的主表是B表,直接就排序了,没有排序的问题。
所以最终的问题就来了,为什么我明明是A表主表,怎么就变成了B表主表了呢?
最后发现是因为,mysql的结构中,有个查询优化的步骤,在这个步骤中会计算查询成本,效果等价的情况下选择成本低的那个。因为left join是个笛卡尔积,但也会因为查询条件等原因使得查询量减少。简而言之,有一个规则是,mysql会选择小表作为主表,因为这样是最省事的,数据量最小。这在大部分情况下都是没有问题的,执行的是最优的。
可在这里,遇上了order by,排序字段偏偏使得整个计算量变大n倍,这就是mysql没有考虑到的了。
解决方法
解决方法是要么改业务逻辑,改写sql
另一种方法是使用straight_join,强制让右表成为主表
分享到这里,希望对你有帮助。















 9746
9746











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









