







The Python Challenge 0-2
第0关

看到一幅图,上面是 238 ,通过Python计算 238 , 238=274877906944 ,将结果替换页面url的0并回车,进入下一关。
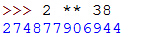
第1关

看到一幅图,上面是字符的移位,图片下方给出一段字符:
g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp. bmgle gr gl zw fylb gq glcddgagclr ylb rfyr’q ufw rfgq rcvr gq qm jmle. sqgle qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj.
可知每个字符位移两次,把上面那些提示用这个方法的处理,告诉我们用同样的方法处理url,得到ocr;进入下一关。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
'''
BY:jixiangrurui
DATE:2015.08.26
Python:3.4.3
Nothing Replaces Hard Work
'''
import string
text = '''
g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amknsrcpq ypc dmp. bmgle gr gl zw fylb gq glcddgagclr ylb rfyr'q ufw rfgq rcvr gq qm jmle. sqgle qrpgle.kyicrpylq() gq pcamkkclbcb. lmu ynnjw ml rfc spj.
'''
text_1 = 'map'
def mytraslate(text):
'''( str ) -> str
Return the string consist of the new ASCII char,new ASCII = old ASCII + 2。
>>> text = 'copyright'
>>> mytraslate(text)
'eqratkijv'
'''
out = ""
for each in text:
if ord(each) >= ord('a') and ord(each) <= ord('z'):
out += chr(((ord(each) - ord('a') + 2) % 26) + ord('a'))
else:
out += each
return out
# 标准解决方式
def std_solution(text):
'''( str ) -> str
Return the string consist of the new ASCII char,new ASCII = old ASCII + 2。
>>> text = 'copyright'
>>> mytraslate(text)
'eqratkijv'
'''
table = str.maketrans(
string.ascii_lowercase,
string.ascii_lowercase[2:] + string.ascii_lowercase[:2])
out = text.translate(table)
return out
if __name__ == '__main__':
print(std_solution(text_1))
print(mytraslate(text_1))学习:
1. str.maketrans()函数和str.translate()函数
intab = "aeiou"
outtab = "12345"
tran = str.maketrans(intab, outtab)
strs = "this is string example....wow!!!";
print(strs.translate(tran));- ord(char):返回一个字符的ascii码值
- 导入string模块,string.ascii_lowercase 可得到所有小写英文字母字符串,同样string.ascii_uppercase可得到所有大写英文字母字符串,string.ascii_letters 可得所有英文字母字符串包括小写和大写。
第2关

根据提示:识别出字符串,它们可能在书里面,也可能在源码里面。因此需要查看此时的页面HTML源代码,仔细寻找会发现一堆混乱的字符。并提示寻找稀有字符。
把得到的稀有字符更换url进入下一关。
#! /usr/bin/env python
# -*- coding:utf-8 -*-
'''
BY:jixiangrurui
DATE:2015.08.26
Python:3.4.3
Nothing Replaces Hard Work
'''
import string
def mysolution(filename):
'''( str of filename ) -> str
Return the set of char in string.ascii_letters
>>> mysolution("E:\\python_practice\\trunk\\Python Chanlenge\\Python Challenge _02.txt")
'equality'
'''
out = ""
lib = string.ascii_letters
f = open(filename,"r")
line = f.readline()
while line != "":
for each in line:
if each in lib:
out += each
# print(line,end="")
line = f.readline()
return out
def mysolution_1(filename):
''' ( str of filename ) -> str
Return the set of char in string.ascii_letters
>>> mysolution_1("E:\\python_practice\\trunk\\Python Chanlenge\\Python Challenge _02.txt")
equality
'''
text = open(filename).read()
s = filter(lambda x: x in string.ascii_letters, text) # 从text中挑选出属于英文字母的字符
while 1:
try:
print(s.__next__(),end = "")
except StopIteration:
break;
# 标准解决方式:
def std_solution(filename):
''' ( str of filename ) -> str
1、读取文本内容;
2、定义一个字典,里面存储每个字符以及对应出现的频数;
3、计算出字符平均稀有情况(所有字符数量/字符数量);
4、循环输出稀有性低于平均水平的的字符。
>>> std_solution("E:\\python_practice\\trunk\\Python Chanlenge\\Python Challenge _02.txt")
equality
'''
s = "".join([line.rstrip() for line in open(filename)]) # 列表包含 --> 读取文件的内容
occ = {} # 定义一个字典,里面存储每个字符以及对应出现的频数;
for c in s:
occ[c] = occ.get(c,0) + 1 # 相同的字符,字典值加1
avgOC = len(s) // len(occ) # 计算出字符平均稀有情况(所有字符数量/字符数量);
print(''.join([c for c in s if occ[c] < avgOC])) # 循环输出稀有性低于平均水平的的字符。
if __name__ == "__main__":
print(mysolution("E:\\python_practice\\trunk\\Python Chanlenge\\Python Challenge _02.txt"))
mysolution_1("E:\\python_practice\\trunk\\Python Chanlenge\\Python Challenge _02.txt")
std_solution("E:\\python_practice\\trunk\\Python Chanlenge\\Python Challenge _02.txt")
学习:
1. 列表推导运算符,并创建一个新的列表。列表推到的运算符:
[ expression for item1 in iterable1 if condition1
for item2 in iterable2 if condition2
for item3 in iterable3 if condition3
...
for itemN in iterableN if conditionN ]2.filter()函数生成一个迭代器。
3.文件的读取操作。















 2437
2437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









