






现在的验证码有很多形式,然而识别方式也有很多方式,本文就两种方式来进行讲解
(1)tesseract识别方式
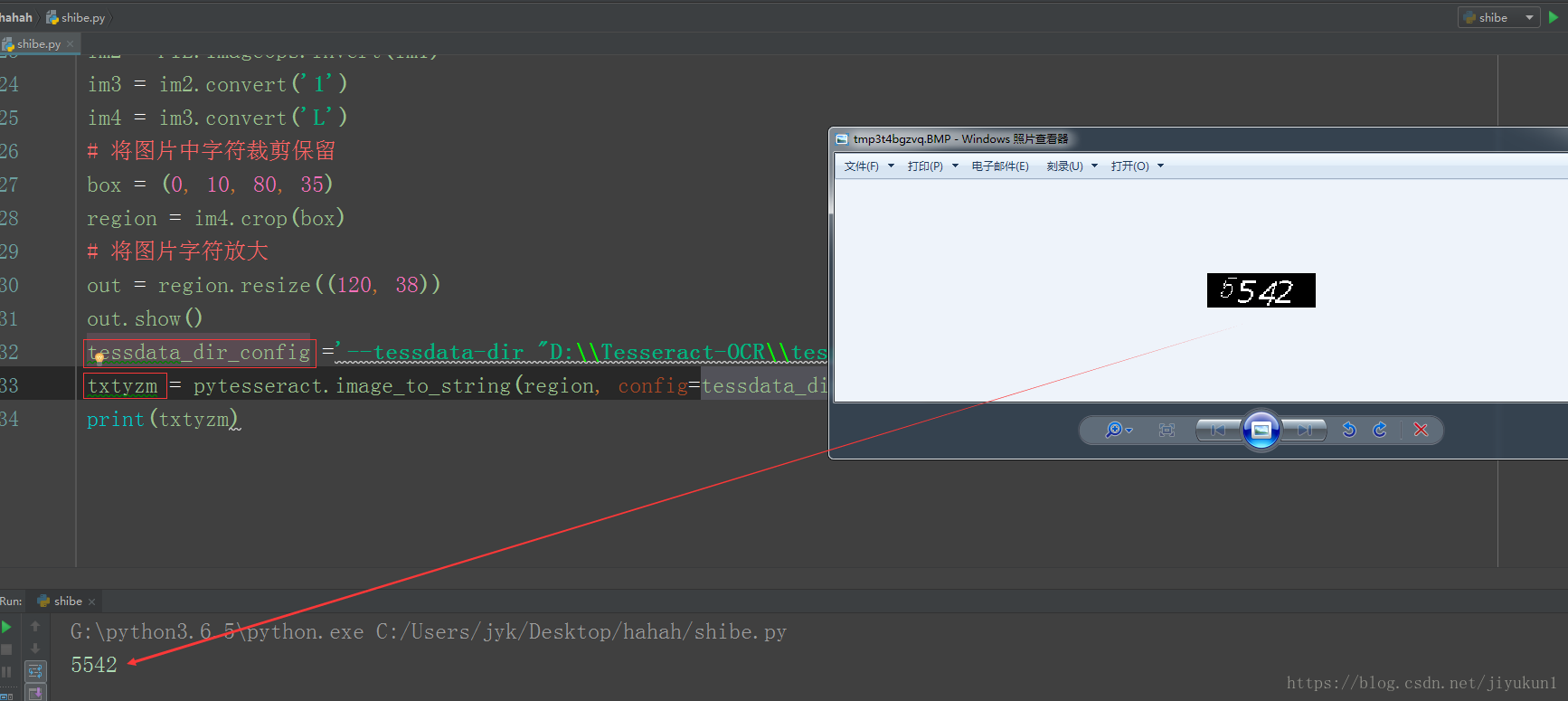
这图片已经是二值化的图片有的验证码有很多的反识别措施,例如知乎的验证码点击倒立的文字,还有12306的验证码是点击出现的东西等等。
首先是安装pytesseract库
from PIL import Image
from pytesseract import *
import PIL.ImageOps
def initTable(threshold=88):
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
return table
im = Image.open(r'C:\Users\jyk\Desktop\0.png')
# 图片的处理过程
im = im.convert('L')
binaryImage = im.point(initTable(), '1')
im1 = binaryImage.convert('L')#将图像二值化去除一些划痕
im2 = PIL.ImageOps.invert(im1)
im3 = im2.convert('1')
im4 = im3.convert('L')
# 将图片中字符裁剪保留
box = (0, 10, 80, 35)
region = im4.crop(box)
# 将图片字符放大
out = region.resize((120, 38))
out.show()
tessdata_dir_config ='--tessdata-dir "D:\\Tesseract-OCR\\tessdata"'
txtyzm = pytesseract.image_to_string(region, config=tessdata_dir_config)[:4]#识别图片
print(txtyzm)但是这种方式是和识别一些数字字母等干扰性比较小的验证码,而较为复杂的验证码,根本就不能有很好的识别效果,如果要想有很好的识别效果可以考虑百度自动识别api可以识别一些较为复杂的代码。
力图如图12306文字识别效果:
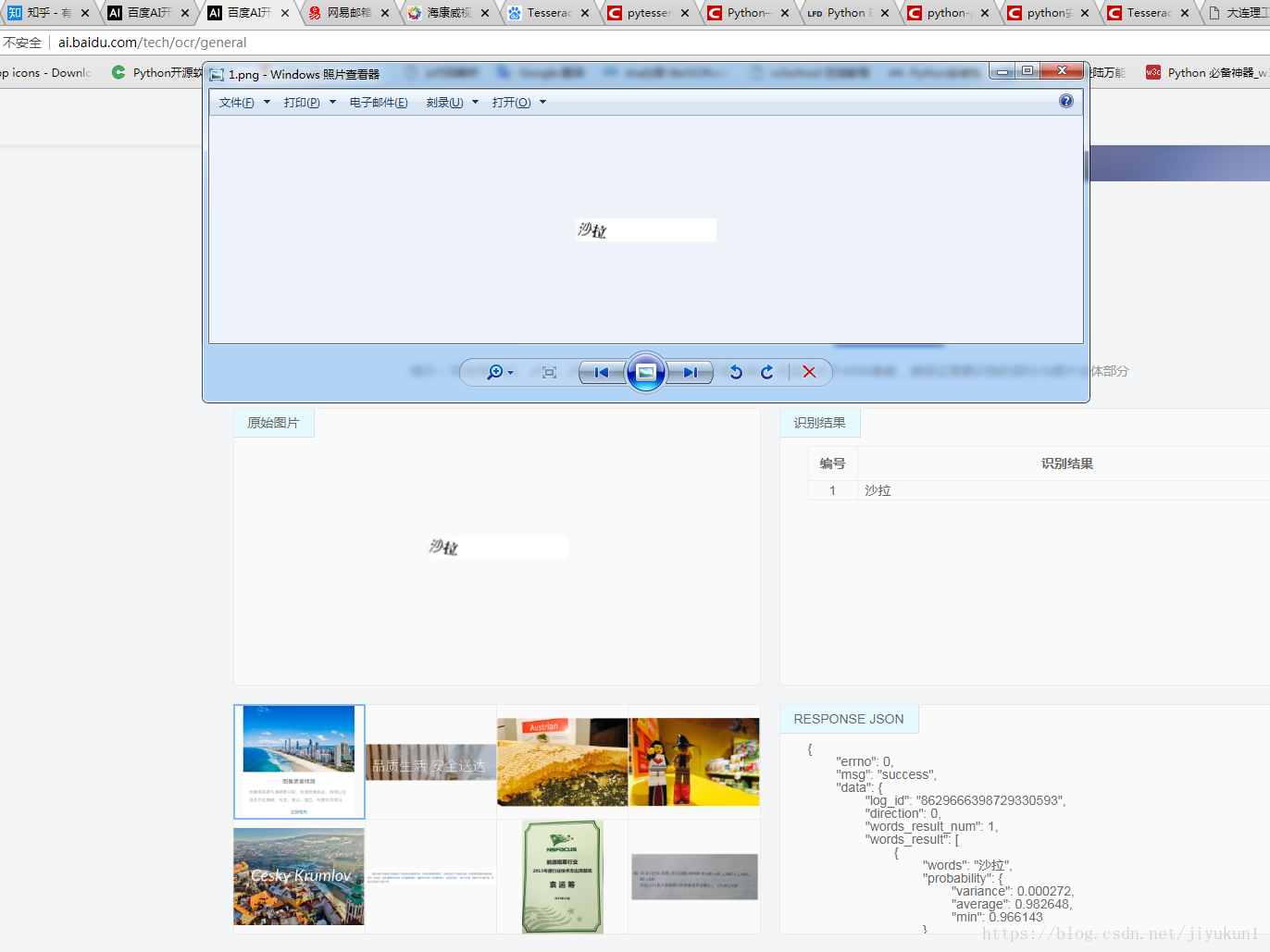
也就是说当识别思路打不开的时候可以换一种思路,让先进的技术为我们服务,达到想要的结果。
识别代码通过抓包得到,或者通过技术文档得到,本人通过抓包得到,可以练习自己的分析爬虫的能力。
代码如下:
headers = headers_raw_to_dict(b''' Accept:*/*
Accept-Encoding:gzip, deflate, br
Accept-Language:zh-CN,zh;q=0.9
Connection:keep-alive
Content-Length:1495
Content-Type:application/x-www-form-urlencoded; charset=UTF-8
Cookie:BAIDUID=F30AC2A6E103832BE391CFF2552C9029:FG=1; BIDUPSID=F30AC2A6E103832BE391CFF2552C9029; PSTM=1513385167; __cfduid=df6fb4a32ed34aa97ed9cf3679da274fd1515554420; BDUSS=9NMlpZbHdyYWVTUGtWYkhTOFZzMFpianNIM0lwckc2eHVOc0NvdUdJSnR5NFphQVFBQUFBJCQAAAAAAAAAAAEAAACWRVlR0MS6rtPvwrwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAG0-X1ptPl9aV0; H_PS_PSSID=1447_21115_18559_20928; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BDSFRCVID=l_4sJeC62REk0IQA1P5JK45LRjsXp3JTH6aojZX6fBSOOfihITWsEG0Pqx8g0KubKAM1ogKKQmOTHArP; H_BDCLCKID_SF=tJPjVC0ytKD3fP36q4vEbJ8thmT22-usQgntQhcH0KLKMpA4blokLj_ryp5itTQrLDItQ56gaMb1MRjvyU5BDPIEqfTRbJJCaDCjbq5TtUJUSDnTDMRh-xPFqH7yKMniLCj9-pnp-ft0hC-xejtBD6QM5pJfet7056R0WjrJabC3DMAmKU6qLT5X04oWJUcI0R6T_lccJI5dVRcRWb05yl0njxQyaqTvJDcGbh7v5JTsOfb5KUonDh8L2a7MJUntKe3C2CjO5hvvVJ6O3M7NKlOh-p52f60OJnuO3f; PSINO=1; Hm_lvt_28a17f66627d87f1d046eae152a1c93d=1523433838; FP_UID=5954e594dd5ea8e7be53aa34d7ebfe30; Hm_lpvt_28a17f66627d87f1d046eae152a1c93d=1523433848; BAIDU_CLOUD_TRACK_PATH=https://cloud.baidu.com/; BDRCVFR[X_XKQks0S63]=mk3SLVN4HKm; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm
Host:cloud.baidu.com
Origin:https://cloud.baidu.com
Referer:https://cloud.baidu.com/product/ocr/general
User-Agent:Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36
X-Requested-With:XMLHttpRequest''')
image_base64 = ''
with open('文件绝对路径', 'rb') as f:
image_base64 += str(base64.b64encode(f.read())).replace("b'", '').replace('\'', '')
data = {
'type': 'webimage',
'image': 'data:image/png;base64,{}'.format(image_base64),
'image_url': ''
}
message = requests.post(url='https://cloud.baidu.com/aidemo', headers=headers, data=data)
try:
basicName = message.json().get("data").get('words_result')[0]['words']
print(basicName)
except:
print('无返回值')总结:通过这两种方式来实现我想要的功能,本人倾向于第二种,因为他山之石可以攻玉,谢谢采纳。














 7199
7199











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









