






光栅化全面解析
0 两种方法
图形学中渲染过程基本上可以分解为两个主要任务:可见性和着色。光栅化可以说是一种解决可见性问题的方法。可见性包括能够分辨三维物体的哪些部分对摄像机是可见的。这些物体的某些部分可以被禁止,因为它们要么在摄像机的可见区域之外,要么被其他物体隐藏。
解决这个问题基本上可以通过两种方式进行。你可以通过图像中的每个像素追踪一条射线,找出相机与该射线相交的任何物体(如果有的话)之间的距离。通过该像素可见的物体就是相交距离最小的物体(一般用 t 表示)。这就是光线追踪中使用的技术。请注意,在这种特殊情况下,你通过在图像中的所有像素上循环,为每个像素追踪一条光线,然后找出这些光线是否与场景中的任何物体相交来创建图像。换句话说,该算法需要两个主要循环。外循环遍历图像中的像素,内循环遍历场景中的物体。
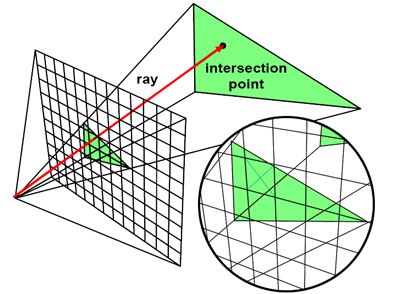
在光线追踪中,我们追踪一条穿过图像中每个像素中心的光线,然后测试这条光线是否与场景中的任何几何体相交。如果找到相交,我们将像素颜色设置为与光线相交的对象的颜色。因为一条射线可能与多个对象相交,所以我们需要跟踪最近的相交距离。
for (each pixel in image) {
Ray R = computeRayPassingThroughPixel(x,y);
float tclosest = INFINITY;
Triangle triangleClosest = NULL;
for (each triangle in scene) {
float thit;
if (intersect(R, object, thit)) {
if (thit < closest) {
triangleClosest = triangle;
}
}
}
if (triangleClosest) {
imageAtPixel(x,y) = triangleColorAtHitPoint(triangle, tclosest);
}
}
请注意,在这个例子中,对象实际上被认为是由三角形组成的(而且只是三角形)。我们没有迭代其他对象,而是把对象看作是一个三角形池子,然后迭代其他三角形。三角形经常被用作光线追踪和光栅化的基本渲染基元(GPU 需要对几何体进行三角化)。
光线追踪是解决可见性问题的第一个可能的方法。我们说这种技术是以图像为中心的,因为我们将光线从摄像机射入场景(我们从图像开始),而不是反过来,这是我们将在光栅化中使用的方法。
光栅化采取的是相反的方法。为了解决可见性问题,它实际上是将三角形 "投射 "到屏幕上,换句话说,我们使用透视投影,将三角形的三维表示变成二维表示。这可以通过将构成三角形的顶点投射到屏幕上(使用我们刚才解释的透视投影)来轻松实现。算法的下一步是使用一些技术来填满该二维三角形所覆盖的图像的所有像素。这两个步骤如下图所示。从技术角度来看,它们的执行非常简单。投影步骤只需要进行透视分割,并将所得到的坐标从图像空间重新映射到光栅空间。找出所产生的三角形覆盖了图像中的哪些像素,也非常简单。
与光线追踪方法相比,该算法是什么样子的呢?首先,请注意,在光栅化中,我们不是先迭代图像中的所有像素,而是在外循环中迭代场景中的所有三角形。然后,在内循环中,我们迭代图像中的所有像素,并找出当前像素是否 "包含 "在当前三角形的 "投影图像 "中。换句话说,这两个算法的内循环和外循环是对调的。
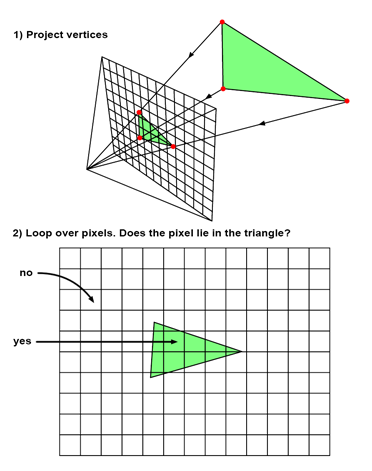
光栅化可以被粗略地分解为两个步骤。我们首先使用透视投影法将构成三角形的三维顶点投射到屏幕上。然后,我们对图像中的所有像素进行循环,测试它们是否位于所产生的 2D 三角形内。如果是的话,我们就用三角形的颜色来填充这个像素。
// rasterization algorithm
for (each triangle in scene) {
// STEP 1: project vertices of the triangle using perspective projection
Vec2f v0 = perspectiveProject(triangle[i].v0);
Vec2f v1 = perspectiveProject(triangle[i].v1);
Vec2f v2 = perspectiveProject(triangle[i].v2);
for (each pixel in image) {
// STEP 2: is this pixel contained in the projected image of the triangle?
if (pixelContainedIn2DTriangle(v0, v1, v2, x, y)) {
image(x,y) = triangle[i].color;
}
}
}
下文将全面介绍光栅化的实现细节。【本文有较多公式,可添加 jinjun2050 获取 pdf 版本】
1 光栅化简介
渲染管道的最后一个主要阶段称为光栅化。光栅化是采用屏幕空间几何图形、片段着色器和该着色器的输入并将几何图形实际绘制到低级二维 (2D) 显示设备的操作。 再一次,我们将专注于绘制三角形集,因为它们是三维 (3D) 图形系统中最常见的图元。事实上,在本文的大部分时间里,我们将专注于绘制一个单独的三角形。对于 几乎所有现代显示设备,这种低级“绘图”操作涉及为显示设备上的每个点或像素分配颜色值。
在概念层面,光栅化的整个主题只是一个实现细节。之所以需要光栅化,是因为我们今天使用的显示设备是基于密集的矩形发光元件或像素 pixels(术语 picture elements 图片元素的缩写)网格,每个像素的颜色和强度在每一帧中都可以单独调整。由于与基于显像管的电视工作方式有关的历史原因,这些显示器被称 为光栅显示器( raster displays)。
就其本质而言,与渲染管道其他阶段相比,光栅化非常耗时。管道的其他阶段通常需要按对象、按三角形或逐顶点计算,而光栅化本质上需要对每个像素进行某种计算。
1,600 像素宽 x1,200 像素高的显示器(屏 幕上大约有 200 万像素)非常流行。除此之外,光栅化实际上通常需要对每个像素进行多次计算,我们意识到必须计算的像素数量通常比给定帧中的三角形数量多 10 倍,20 或更多。
从历史上看,在纯粹的软件 3D 管道中,多达 80%到 90%的渲染时间花在光栅化上是很常见的。这种级别的计算需求导致了一个事实,即光栅化是第一个通过专门的消费硬件加速的图形化阶段。事实上,到 2000 年代初,大多数 3D 电 脑游戏开始需要某种形式的 3D 硬件。本文不会详细介绍编写软件 3D 光栅化器所需 的方法和代码,因为大多数游戏开发人员不再需要编写它们。关于如何编写一组光栅器的细节,请看 Hecker 在《Game Developer Magazine》中关于透视纹理映射的优秀系列文章 [76]。
尽管很少有游戏开发者需要在现代游戏中自己实现哪怕是光栅化管道的一个子集,但光栅化的话题仍然非常重要,即使在今天也是如此。光 栅化的基本概念引发了对整个渲染管道中一些最有趣和最微妙的数学和几何问题的 讨论。此外,对这些基本概念的理解可以让游戏开发人员更好地理解为什么以及如何进行巧夺天工的渲染和性能瓶颈的出现,即使光栅化实现是在专用硬件中实现的。许多这些基本概念和低级细节几乎可以在任何 3D 游戏中产生视觉相关的结果。本文将重点介绍光栅化的一些基本概念,这些概念对于更深入地理解使用基于图形处理单元 (GPU) 或计算机处理单元 (CPU) 的渲染系统的过程至关重要。
2 显示和帧缓冲区
每件显示设备硬件,无论是计算机显示器、电视还是其他类似设备,都需要图像数 据源。对于计算机图形系统,这种图像数据源称为帧缓冲区(之所以这么称呼,是 因为它是一个数据缓冲区,用于保存帧的图像信息,或屏幕的图像价值)。基本而言,帧缓冲区是 2D 数字图像:一块内存,其中包含表示屏幕上每个点的颜色的数值。每个颜色值代表屏幕在给定点的颜色——一个像素。每个像素都有红色、绿色 和蓝色分量。放在一起,这个帧缓冲区代表要在屏幕上绘制的图像。每次需要更新 屏幕上的图像时,显示硬件都会从内存中读取这些颜色,通常每秒至少 30 次,通常每秒 60 次或更多次。
正如我们将看到的,帧缓冲区通常包含的不仅仅是每个像素的单一颜色。虽然实际用于设置显示器上每个点发出的光的颜色和强度的是最终的逐像素颜色, 但其他逐像素值在光栅化过程中内部使用。从某种意义上说,这些其他值类似于每 个顶点法线和每个三角形的材质颜色。虽然它们从不直接显示,但它们对最终颜色的计算方式有重大影响。
3 概念化光栅化管道
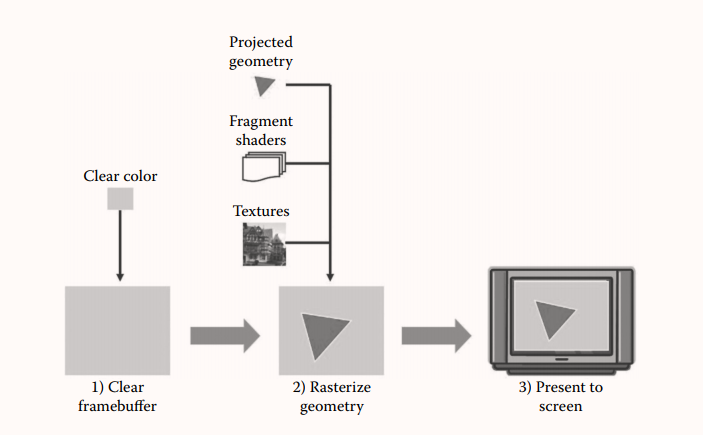
光栅化整个帧所需的步骤如图 1 所示。第一步是从帧缓冲区中清除任何以前的图像。这在某些情况下可以跳过;例如,如果已知场景几何图形覆盖整个屏幕,则无需清除屏幕。在这种情况下,旧图像将被新图像完全覆盖。但对于大多数应用程序 ,此步骤涉及使用渲染应用程序编程接口 (API) 将帧缓冲区中的所有像素(在单个函数调用中)设置为固定颜色。
第二步是将几何光栅化到帧缓冲区。我们将在本文的其余部分详细介绍这个阶段,因为它是三个步骤中最复杂的步骤(到目前为止)。
第三步是将帧缓冲图像呈现 (present) 给物理显示器。这个阶段通常称为交换或缓冲区交换(swapping or buffer swapping),因为从历史上看,它经常涉及(并且在许多情况下仍然涉及)两个缓冲区之间的切换——在显示另一个时绘制到一个,然后在每一帧之后交换两个缓冲区。这是为了避免在渲染期间出现闪烁或其他伪影(特别是为了避 免让用户看到部分渲染的帧)。然而,本文后面描述的其他技术将需要在呈现步骤(presentation step)中完成额外的工作。因此,我们将使用更通用的术语 present 来指代这一步。
3.1 光栅化阶段
即使是一个简单的光栅化管道也有几个阶段。应该注意的是,虽然这些阶段往往存在于光栅化硬件实现中,但硬件几乎从不遵循以下列表中概念阶段的顺序(甚至结构)。这个简单的管道光栅化单个三角形如下:
-
确定三角形覆盖的可见像素。 -
计算每个像素处可见三角形的颜色。 -
确定每个像素的最终颜色并写入帧缓冲区。
第一阶段进一步分解为两个独立的步骤:
-
确定三角形覆盖的像素 -
确定在每个像素处可见的三角形
本文的其余部分将详细讨论每个流水线阶段。
4 确定片段(Fragments):三角形覆盖的像素
4.1 片段
为了在渲染的光栅化阶段取得进一步进展,我们必须将屏幕空间中的三角形(或更一般地,几何体)分解成更直接匹配帧缓冲区中像素的片段。这涉及确定像素矩形或像素中心点与三角形的交点。在光照和阴影中,我们使用术语片段来表示多边形表面上给定点周围的无限小表面积。片段着色器被描述为在这些微小的表面上进行求值。
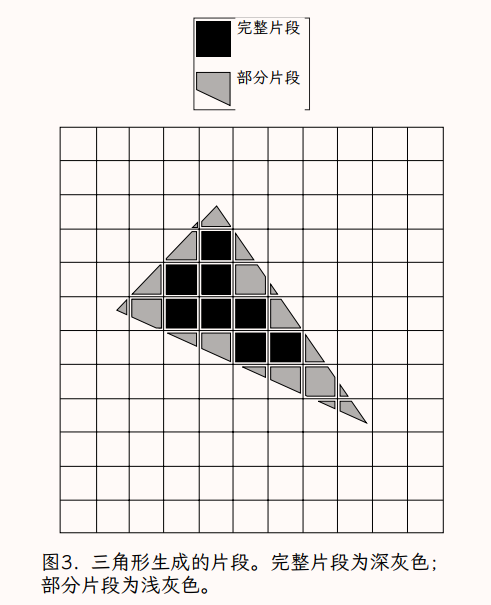
在光栅化级别,片段具有更明确但相关的定义。它们是上述分解屏幕空间三角形以匹配像素的过程的结果。这些片段可以被认为是屏幕空间中像素大小的三角形碎片(pieces)。这些可以被可视化为一个三角形,通过沿着像素边界切割成小块(pieces)。许多这些片段(三角形的内部)将是正方形的,即像素正方形的完整大小。我们称这些像素大小的片段为完整片段。然而,沿着三角形的边缘,这些片段可能是放置在像素正方形内部的被分为多个边的多边形,因此小于像素。我们称这些较小的片段为部分片段。在实践中,这些片段可能实际上是在像素中心拍摄的三角形的点样本(类似于我们在光照和阴影中对片段的概念),但基本的想法是,片段代表了一个三角形的碎片(pieces),这些碎片影响到了一个给定的像素。我们将把像素看作是目的地或箱子,我们把覆盖该像素区域的所有碎片放入其中。因此,它不是一个一对一的映射。一个像素可能包含来自不同(甚至是相同)对象的多个片段, 或者一个像素可能不包含场景的当前视图中的任何片段。
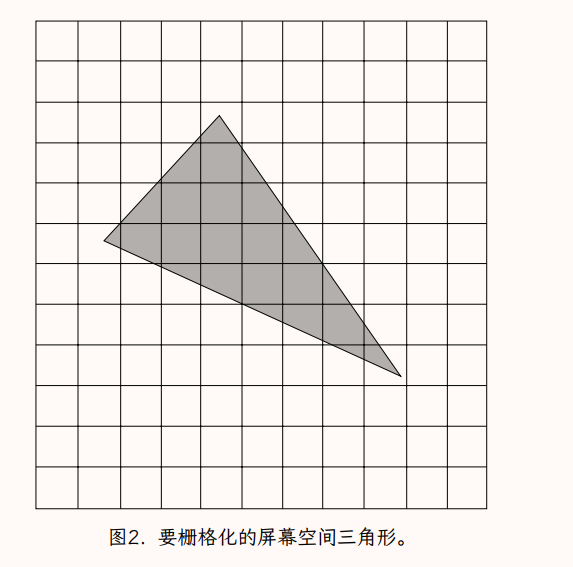
本文的其余部分将使用这个更具体的片段定义。图 2 显示了一个覆盖有像素矩形边界的三角形。图 3 显示相同的配置被分解成片段,包括完整的和部分的。图中将片段稍微分开,以更好地展示部分片段的形状。
4.2 深度复杂度
整个场景中的片段数量可以比屏幕上的像素数量少得多,也可以多得多。如果几何图形仅覆盖屏幕的一个子集,则可能有许多像素不包含场景中的片段。另一方面,如果许多三角形在屏幕空间中相互重叠,那么屏幕上的许多像素可能包含多个片段。给定帧中场景中的片段数与屏幕上像素数的比率称为深度复杂度或过度绘制,因为该比率表示有多少全屏几何体构成场景。通常,具有更高深度复杂度的场景光栅化成本更高。请注意,这是整个视图的总体比率;即使几何图形仅覆盖屏幕的一半,场景的深度复杂度也可能为 2。如果平均而言,被覆盖的一半屏幕上的几何图形是四个三角形深度,那么深度复杂度将是每个像素两个片段在整个屏幕上摊销。
4.3 将三角形转换为片段
三角形是凸的,无论它们如何通过射影变换进行投影(在某些情况下,三角形可能显示为线或点,但它们仍然是凸对象)。这是一个非常有用的属性,因为它意味着任何三角形与水平的像素行相交(也称为扫描线,由于历史原因与基于 CRT 的电视显示器)最多在一个连续的片段中。因此,对于与三角形相交的任何扫描线, 我们可以仅用最小 x 值和最大 x 值表示交点,称为跨度(span)。因此,在光栅化期间三角形的表示由一组跨度组成,每条扫描线一个,三角形相交。此外,三角形的凸性还意味着与三角形相交的扫描线集合在 y 上是连续的;给定三角形有一个最小值和一个最大值 y,其中包含所有非空跨度。图 4 显示了三角形跨度集的示例。覆盖在三角形上的暗带代表将用于绘制三角形的相邻片段的跨度。
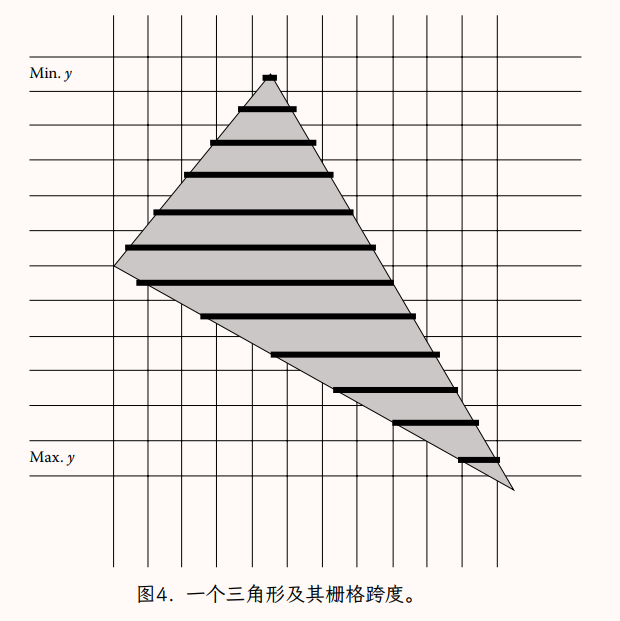
三角形的 y~min~ 即最小 y 像素坐标就是三个三角形顶点的最小 y 值。类似地,三角形的最大 y 像素坐标 y~max~就是三个顶点的最大 y 值。因此,三个顶点之间的简单 min/max 计算定义了必须为三角形生成的 (y~max~−y~min~+1) 的整个跨度范围。
每个跨度的最左边和最右边的片段可能是部分片段,因为三角形的边缘可能不会完全落在像素边界上。此外,出于同样的原因,最顶部和最底部的跨度可能包含部分片段。三角形的剩余片段将是完整的片段。
生成跨度本身只是涉及到将水平扫描线与三角形的边缘相交。由于三角形的凸性,除非扫描线与一个顶点相交,该扫描线将与三角形的两条边恰好相交: 一个从三角形外跨入三角形,一个再次离开三角形。这两个交点将定义跨度的最小和最大 x 值。
4.4 处理部分片段
完整的片段总是继续到光栅化过程的下一个阶段。然而,部分片段的命运取决于特定的渲染系统。在更高级的系统中,一个像素处的所有部分片段都作为部分片段传递,最终像素的可见性和颜色可能会受到所有这些部分的影响。然而,更简单的光栅化系统不处理部分片段,并且必须在生成部分片段时决定是丢弃该片段还是将其提升为完整片段。解决此问题的常用方法是当且仅当它们包含像素的中心点时才保留部分片段。这有时称为几何点采样,因为整个片段是基于每个像素内的单点样本生成或不生成的。图 5 显示了与图 3 相同的三角形,但部分片段被丢弃或提升为完整片段,具体取决于片段是否包含像素的中心点。

当一个三角形的顶点或边缘正好落在一个像素中心时,这样的图形系统的行为是由与系统相关的填充惯例决定的。它确保如果两个三角形共享一个顶点或一条边,只有一个三角形会为像素贡献一个片段。这一点非常重要,因为如果没有一个明确的填充约定,在三角形之间的共享边缘可能会出现空洞(两个三角形的部分碎片都被丢掉的像素)或重复绘制的像素(两个三角形的部分碎片都被提升为完整的碎片)。沿着共享三角形边缘的孔允许背景色透过本来是连续的、不透明的表面,使表面看起来有裂缝穿过。沿着共享边缘的双重绘制的像素会导致更微妙的伪影,通常只有在使用透明或其他形式的混合时才会看到(见第 8.1 节)。关于实现点取样填充约定的细节,见 Hecker 的《游戏开发者杂志》系列文章 [76]。
5 确定可见几何
渲染几何图形的总体目标是确保最终渲染的图像令人信服地代表给定场景。在最高级别上,这意味着物体必须看起来被更近的物体正确遮挡,并且不能被更远的物体遮挡。这个过程被称为可见表面测定 (VSD),并且有许多非常不同的方法来完成它。这些方法都涉及在一个或另一个粒度级别上比较表面的深度,并以给定像素处的最小深度对象(即最近的对象)是渲染到屏幕的对象的方式渲染它们。
历史上,有许多不同的方法被用于 VSD。许多早期的算法都是基于巧妙的排序技巧,包括在光栅化之前将几何体从后往前排序。这是一个昂贵的命题,通常在 CPU 上每帧计算一次。到目前为止,今天最常用的方法是基于光栅化的方法:深度缓冲区。光栅化器是图形管线中最早被加速的部分,有专门的硬件,这意味着基于光栅化器的可见表面确定系统可以实现高性能。深度缓冲器也被称为 Z 缓冲区(z-buffer)。它实际上是更普遍的深度缓冲的一个具体的、特殊的案例。
5.1 深度缓冲
深度缓冲是基于可见性应以输出为重点的概念。换句话说,由于像素是我们渲染管道的最终目的地,可见性应该在每个像素(或者更确切地说,每个片段)的基础上计算。如果在每个像素处看到的最终颜色是具有最小深度的片段的颜色(在绘制到该像素的所有片段中),则场景将显示为正确绘制。换句话说,在绘制到一个像素的所有片段中,具有最小深度的片段应该“赢得”该像素并选择该像素的颜色。出于讨论的目的,我们假设点采样几何(即,没有部分片段)。
由于常见的光栅化方法倾向于一次渲染一个三角形,一个给定的像素可能会在一帧的过程中被来自不同三角形的片段重绘几次。如果我们希望避免按深度对三角形进行排序(我们确实这样做了),那么应该获得给定像素的片段可能不是最后一个绘制到该像素的片段。我们必须有某种方法来存储当前最近片段在每个像素处的深度以及该片段的颜色。
存储了这些信息后,我们可以在每次将片段绘制到像素时计算一个简单的测试。如果新片段的深度比该像素当前存储的深度值更接近,则新片段赢得该像素。计算新片段的颜色,并将这个新片段颜色写入像素。片段的深度值替换该像素的现有深度值。如果新片段的深度大于为像素着色的当前片段,则忽略新片段的颜色和深度,因为片段表示当前像素处最近的已知表面后面的表面。在这种情况下,我们知道新片段将在该像素处被遮挡,因为我们已经在该像素处看到了比最新片段更近的片段。图 6 表示将片段从两个三角形渲染到一个小的深度缓冲区。请注意更接近的三角形的片段如何总是赢得像素(正确的结果),即使它是先绘制的。
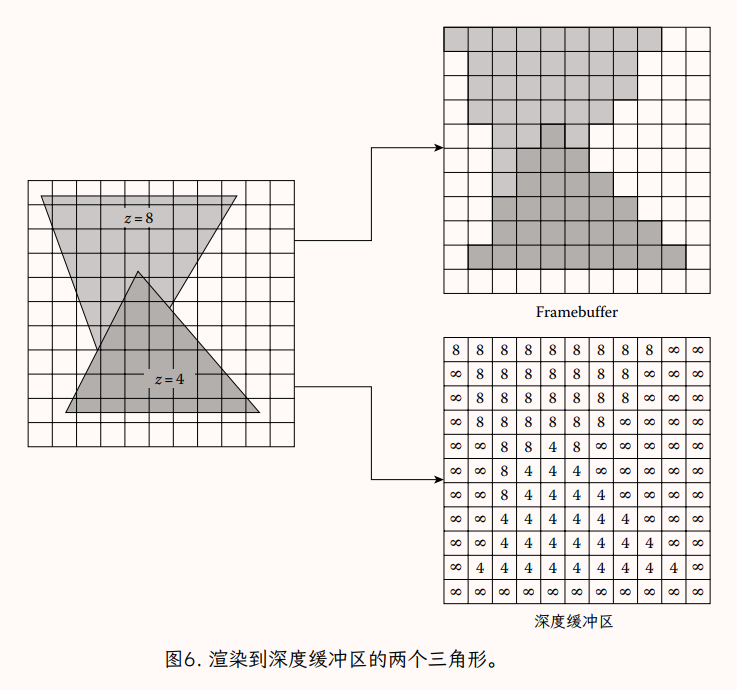
因为该方法是按像素计算的,因此是按片段计算的,因此每个三角形的深度是在每个片段的粒度上计算的,并且该值用于深度比较。由于这种更精细的子三角形粒度 ,深度缓冲区会自动处理无法使用逐三角形排序正确显示的三角形配置。几何图形可以以任何顺序传递到深度缓冲区。这种随机顺序可能有问题的情况是给定像素的两个片段具有相同的深度。在这种情况下,顺序很重要,具体取决于用于排序深度的确切比较(即<或≤)。然而,这种情况对于几乎任何可见表面方法都是有问题的。
深度缓冲区有几个缺点,尽管其中大多数在现代 PC 或游戏机上不再重要。深度缓冲方法的历史缺陷之一隐含在方法的名称中;它需要一个缓冲区或深度数组值,每个像素一个。这是一大块内存,通常需要与帧缓冲区本身一样多的内存。同样,正如帧缓冲区必须在每帧之前清除为背景颜色一样,深度缓冲区也必须清除为背景深度,通常是可表示的最大深度值。这些问题在 GPU 内存有限的手持和嵌入式 3D 系统上可能很严重。最后(仍然适用于 PC 和控制台),深度缓冲区需要以下工作:
-
计算片段的深度值 -
在深度缓冲区中查找现有像素深度 -
这两个值的比较 -
(仅适用于新的“获胜者”片段)将新深度写入深度缓冲区
在许多 GPU 上,深度缓冲区存储在分层的压缩数据结构中,允许使用大块像素进行快速拒绝测试。但是,对于基本实现,这是为每个片段计算的。对于大多数软件光栅器,这个额外的逐片段的工作会使深度缓冲不适合持续使用。全软件 3D 系统倾向于尽可能使用优化的几何排序,为真正需要它的少数对象保留深度缓冲。例如,早期的第三人称射击游戏渲染引擎将大量工作投入到环境的专门排序中,从而避免对它们进行任何深度缓冲测试。这留下了足够的 CPU 周期来使用软件深度缓冲渲染动画角色、怪物和小物体(覆盖的像素比风景少得多)。
此外,深度缓冲区并不能解决高深度复杂度场景的潜在性能问题。我们仍然必须计算每个片段的深度并将其与缓冲区进行比较。但是,在某些情况下,它可以减少过度绘制的问题,因为没有必要计算或写入任何未通过深度测试的片段的颜色。事实上,一些应用程序会尝试以大致从近到远的顺序渲染它们的深度缓冲场景(同时仍然避免在 CPU 上按三角形、按帧排序),这样后面的几何图形可能会使深度缓冲失败测试并且不需要颜色计算。
深度缓冲在硬件加速平台上运行的 3D 应用程序中非常流行,因为它易于使用,需要很少的应用程序代码或主机 CPU 计算,并且可以以高性能生成高质量的图像。
5.1.1 计算每个片段的深度值
使用深度缓冲区计算片段可见性的第一步是计算当前片段的深度值。正如我们将看到的, 将工作得很好。然而, 工作良好而视图空间值 不工作的原因是相当有趣的。
为了更好地理解深度值如何在屏幕空间中跨三角形变化的性质,我们必须能够将屏幕上的点映射到投影到它的三角形中的点。这与拾取非常相似,我们将使用几个概念。由于透视投影的非线性特性,我们会发现我们从屏幕空间像素到给定视图空间点的映射三角有点复杂。我们将通过几个较小的阶段来跟踪此映射。对于本文的讨论,我们将假设我们正在使用 OpenGL 样式的矩阵,我们在视图空间中向下看‑z 轴。
视图空间中的三角形只是视图空间中平面的凸子集。因此,我们可以通过平面的法向量 来定义视图空间中三角形的平面,并且一个常数 d,使得平面上的点 满足
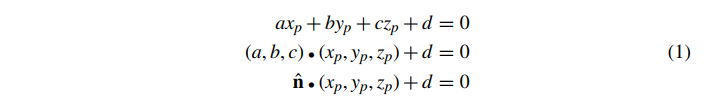
回顾拾取,2D 归一化设备坐标 中的一个点映射到视图空间射线 t**r **使得
其中 是投影距离(从视图空间原点到投影平面的距离)。投影到 处的像素的任何视点空间必须与这条射线相交。通常,我们不能反转投影变换,因为屏幕上的一个点映射到视图空间中的一条射线。但是,通过知道三角形的平面,我们可以将三角形与视线相交,如下所示。视图空间中落在三角形平面内的所有点 P 由公式 1 给出。此外,我们知道三角形上投影到 的点对于某些 t 必须等于 tr。用向量 tr 代替公式 1 中的点 并求解 t,
从这个 t 值,我们可以计算出沿投影射线的点 ,它是投影到 的三角形上的视图空间的点。这相当于发现
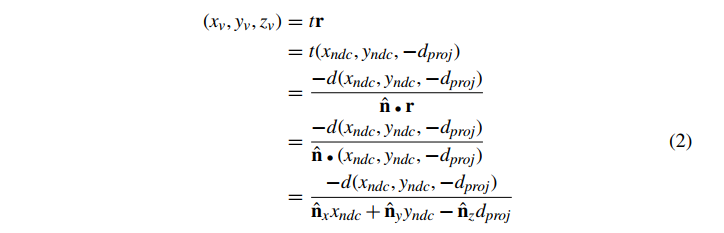
但是,我们现在只对 感兴趣,因为我们正在尝试计算深度缓冲的 perfragment 值。公式 2 的 分量是
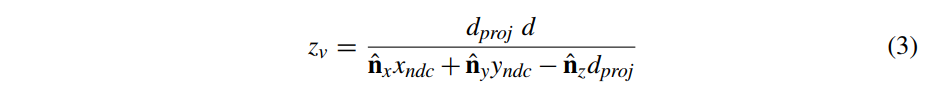
作为对已知结果的快速检查,请注意,在具有恒定深度 的三角形的特殊情况下,我们可以替换

代入公式 3,计算结果为预期常数 :
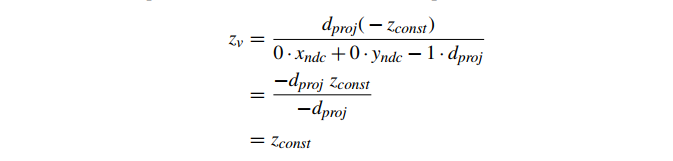
正如公式 3 中所定义的, 是一个计算每个片段的代价高昂的值(在一般的非常数深度情况下),因为它是具有非常数分母的分数。
这将需要按片段划分来计算 ,这比我们想要的要昂贵。然而,深度缓冲只需要能够相互比较深度值。如果我们比较 值,我们知道它们随着深度的增加而减小(因为视图方向是‑z),给出深度测试:
≥DepthBuffer→新片段可见
<DepthBuffer→新片段不可见
但是,如果我们计算并存储 zv 的倒数(乘法逆),那么类似的比较仍然以相同的方式工作。如果我们使用所有 zv 值的倒数,我们得到
≤DepthBuffer→新片段可见
>DepthBuffer→新片段不可见
如果我们对等式 3 进行倒数,我们可以看到每个片段的计算变得更简单:
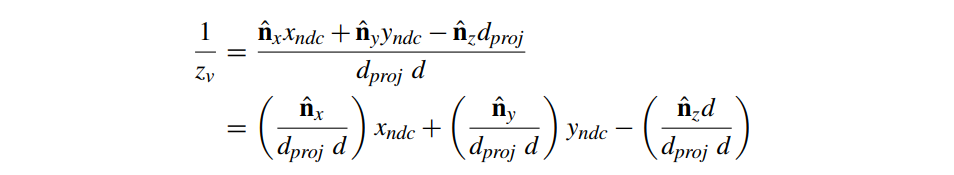
其中所有带括号的项在三角形中都是恒定的。事实上,这形成了 ND 坐标到 的仿射映射。由于我们知道存在从像素坐标 (xs,ys) 到 ND 坐标 (xndc,yndc) 的仿射映射(affine mapping),我们可以将这些仿射映射组合成从屏幕空间像素坐标到 的单个仿射映射。结果,对于给定的投影三角形,
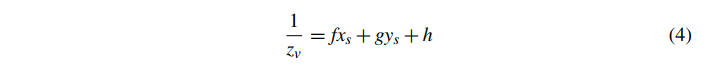
其中 f、g 和 h 是实数值并且是每个三角形的常数。我们将给定三角形的上述映射定义为
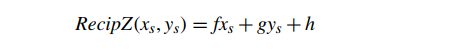
从推导中可以看出 (或任何仿射映射)的一个有趣性质
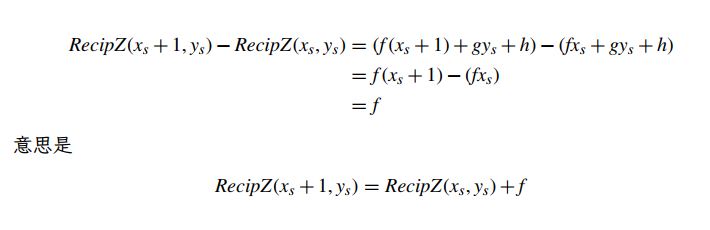
同样地
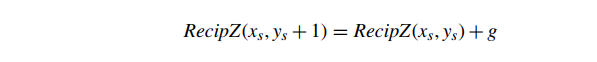
换句话说,一旦我们计算出任何起始片段的 RecipZ 深度缓冲区值,我们可以通过简单地添加 f 来计算跨度中下一个片段的深度缓冲区值。一旦我们计算了给定跨度的基本深度缓冲区值,当我们沿着扫描线前进,填充跨度时,我们需要做的就是将 f 添加到每个相邻片段之间的当前深度(图 7)。这使得深度值的每片段计算确实非常快。并且,一旦计算了第一个跨度的基础 RecipZ,我们可以将 g 添加到前一个跨度的基础深度以计算下一个跨度的基础深度。这种技术被称为前向差分,因为我们使用一个片段的值与下一个片段的值之间的差值(或增量)来逐步更新当前深度。此方法适用于任何存在来自屏幕空间的仿射映射的值。我们将这些值称为屏幕空间中的仿射或屏幕仿射(affine in screen space, or screen affine.)。
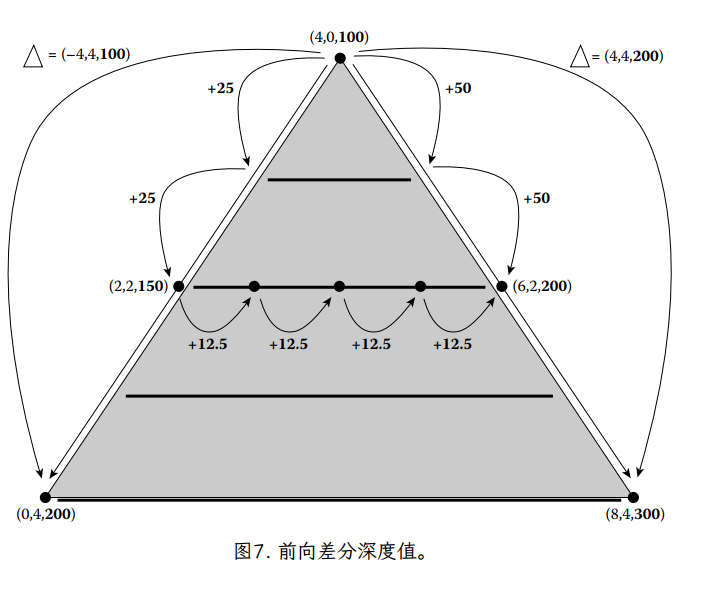
事实上,我们可以使用我们在投影期间计算的 值作为替代对于 RecipZ。在视图和投影中,我们计算了一个 zndc 值,它在近平面等于‑1,在远平面等于 1,其形式为
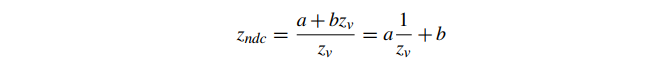
这是 RecipZ 的仿射映射。结果,我们发现我们现有的值 是屏幕仿射的,适合用作深度缓冲区值。这是我们前面提到的深度缓冲的特殊情况,通常称为 z 缓冲,因为它直接使用 。
5.5.2 数值精度和 z 缓冲
在实践中,屏幕空间中的深度缓冲有一些数值精度限制,可能会导致视觉伪影。正如前面讨论深度缓冲区时提到的,对象被绘制到深度缓冲系统的顺序(至少在不透明对象的情况下)只有在两个表面(两个片段)的深度值是在给定像素处相等。理论上,除非所讨论的几何对象真正共面,否则这不太可能发生。然而,由于计算机数字表示没有无限的精度,不共面的表面可以映射到相同的深度值。这可能导致以错误的顺序绘制对象。
如果我们的深度值被线性映射到视图空间,那么一个 16 位的定点数深度缓冲区将能够正确分类表面深度相差约 160,000 的近平面和远平面距离之差的任何对象。对于几乎任何应用程序来说,这似乎都绰绰有余。例如,对于 1 公里的视距,这将等于大约 1.5 厘米的分辨率。移动到更高分辨率的深度缓冲区会使这个值变得更小。
然而,在 z 缓冲的情况下,可表示的深度值不是均匀分布的在视图空间中。事实上,正如我们所见,存储到缓冲区的深度值基本上是 ,这绝对不是视图空间 z 的均匀分布。深度缓冲区值在视图空间 z 上的图表如图 8 所示。这是视图空间 z 到深度缓冲区值的双曲线映射——注意深度值随着 Z 向远处平面的变化而变化很小。
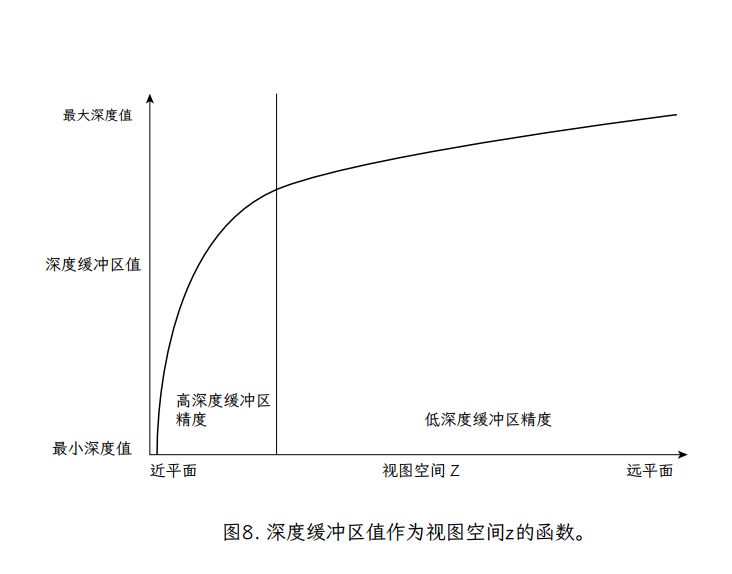
对此使用定点值会导致距离精度非常低,因为 z 的大间隔映射到逆 z 的相同定点值。事实上,一个常见的估计是 z 缓冲区将其 90%的精度集中在最近的 10%的视图空间 z 中。这意味着远处物体的碎片经常相对于彼此被错误地分类。
一种在 3D 硬件中流行的处理精度问题的方法称为 w‑buffer。w‑buffer 以高精度对深度(通常为 1/w)进行插值的屏幕仿射值,然后在每个像素处计算插值的倒数以产生在视图空间中线性的值(即 1/w)。然后将这个反转值存储在深度缓冲区中。通过量化(降低插值期间使用的额外精度)并在视图空间中存储一个线性值,可以在一定程度上避免 z 缓冲区的双曲线性质。但是,如前所述,不再支持 w‑buffers。它们还存在一个问题,即每个图元在屏幕空间中存储的值是非线性的,这不适用于某些后处理算法。
另一种解决方案使用浮点深度缓冲区,大多数平台都提供这种缓冲区。结合它们,我们翻转深度缓冲值,使得深度值在近平面映射到 1.0,在远平面映射到 0.0,并且一个>或≥的比较用于深度测试 [89]。通过这样做,浮点数的自然精度特性最终抵消了 z 缓冲区值的一些双曲线特性。接近 0 的浮点值增加的动态范围补偿了远距离 z 值范围的损失,其作用类似于旧的 w 缓冲区。也就是说,浮点深度缓冲区可能存在其他问题,过度校正并使最靠近相机的场景区域精度太低。这在渲染场景中尤其明显,因为最接近相机的几何图形对观看者来说是最明显的。
最后,避免这些问题的最简单方法是通过将近平面尽可能远地移动来最大化深度缓冲区的使用,从而不会浪费靠近近平面的精度。所有这些方法都有依赖于场景和应用程序的权衡。
5.2 实践中的深度缓冲
在大多数图形系统中使用深度缓冲需要在渲染代码中添加几个点:
-
创建帧缓冲区时创建深度缓冲区 -
每帧清除深度缓冲区 -
启用深度缓冲区测试和写入
第一步是确保使用深度缓冲区创建渲染窗口或设备。这因 API 不同而不同,Iv(IvGraphics 图形 API)在所有情况下都会自动分配深度缓冲区。请求创建深度缓冲区后(在大多数情况下,只是请求深度缓冲区,取决于硬件支持),必须在每帧开始时清除缓冲区。深度缓冲区的清除通常使用与帧缓冲区清除相同的功能。Iv 使用 IvRenderer 函数 ClearBuffers,但带有新参数 kDepthClear。虽然可以使用独立于帧缓冲区来清除深度缓冲区
renderer->ClearBuffers(kDepthClear);
如果您在帧开始时清除两个缓冲区,则在某些系统上通过一次调用清除它们可能会更快,这在 Iv 中如下完成:
renderer->ClearBuffers(kColorDepthClear);
要启用或禁用深度测试,我们只需使用 IvRenderer 函数 SetDepthTest。要禁用测试,请通过 kDisableDepthTest。要启用测试,请通过其他测试模式之一(例如 kLessDepthTest)。默认情况下,深度测试被禁用,因此应用程序应在渲染之前显式启用它。最常见的深度测试模式是 kLessDepthTest 和 kLessEqualDepthTest。如果其深度值小于或等于当前像素深度,则后一种模式会导致使用新片段。
深度值的写入也可以启用或禁用,与深度测试无关。正如我们将在本文后面看到的那样,在禁用深度缓冲区写入的同时启用深度测试会很有用。调用 IvRenderer 函数 SetDepthWrite 可以启用或禁用写入 z 缓冲区。
6 计算片段着色器输入
光栅化管道的下一个阶段是通过评估当前片段的当前活动片段着色器来计算片段的整体颜色(以及可能的其他着色器输出值)。这反过来又要求在当前片段位置
-
应用程序设置的每对象统一值(uniform) -
顶点着色器从源顶点生成或传递的逐顶点属性 -
每个片段的间接值,通常来自纹理
请注意,给定片段可能存在许多来源。作为着色器输入源生成的一部分,它们中的每一个都必须对每个片段进行独立评估。在计算了每个片段的源值之后,必须通过运行片段着色器来生成最终的片段颜色。在片段着色器中组合每个片段顶点颜色值、每个顶点光照值和纹理颜色有各种方法。着色器生成最终的片段颜色,该颜色将传递到光栅化管道的最后阶段,即混合(本文稍后将讨论)。
接下来的几节将讨论如何从我们列出的源中计算每个片段的着色器源值。虽然有许多可能的方法可以使用,我们将专注于在屏幕空间中快速计算并且非常适合大多数光栅化软件甚至一些光栅化硬件的以扫描线为中心的特性的方法。
6.1 统一值 Uniform Values
值与管道中的所有其他阶段一样,每个对象的值或颜色最容易光栅化。对于每个片段,恒定的统一值可以直接向下传递给着色器。不需要对每个片段进行评估或计算。因此,统一值对片段着色过程的性能影响最小。
6.2 每顶点属性 Per-Vertex Attributes
正如我们之前讨论过的,每个顶点的属性是从最后一个顶点处理阶段(在我们的例子中,从顶点着色器)传递给片段着色器的变量。这些值仅在每个三角形的三个顶点处定义,因此必须进行插值以确定三角形中每个片段中心的值。正如我们将看到的,在一般情况下,要正确计算三角形的每个片段,这可能是一项昂贵的操作。但是,我们将首先查看等深三角形的特殊情况。这种情况下的映射在计算上一点也不昂贵,即使在渲染非恒定深度的三角形时(尤其是在软件渲染器中),它也是一个诱人的近似值。
6.2.1 恒定深度插值 Constant Depth Interpolation
为了分析恒定深度的情况,我们将确定恒定深度三角形的映射本质,从像素空间,通过 NDC 空间,到视图空间,通过重心坐标,最后到逐顶点源属性。我们首先从从像素空间映射到视图空间的特殊情况开始。
整体投影方程(从视图空间映射到 NDC 空间到屏幕空间像素坐标)的所有形式
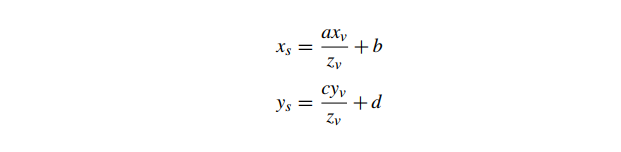
其中 a,c 不等于零。如果我们假设一个三角形的顶点都在相同的深度(即,视图空间 等于三角形中所有点的常数 ),那么一个点在三角形内部是

注意 a,c 不等于零意味着 a′,c′不等于零,所以我们可以重写这些使得
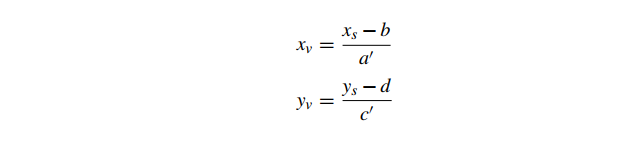
因此,对于恒定深度 的三角形,
投影在 平面上形成从屏幕顶点到视图空间顶点的仿射映射。
重心坐标是视图空间顶点的仿射映射。
顶点属性定义了从重心坐标到属性值的仿射映射(例如,Gouraud 着色)。
如果我们组合这些仿射映射,我们最终会得到一个从屏幕空间像素坐标到属性值的仿射映射。例如,我们可以将这个从像素坐标到颜色的仿射映射写为
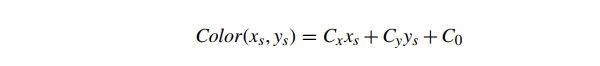
其中 、 和 都是颜色(每种颜色都可能为负数或大于 1.0)。有关将三个屏幕空间像素位置和相应的三重顶点颜色映射到三种颜色 、 和 的公式的推导,请参见 Eberly[35] 的第 126 页。从我们先前对屏幕空间中逆 z 属性的推导,我们注意到颜色 是常数 z 三角形的屏幕仿射:
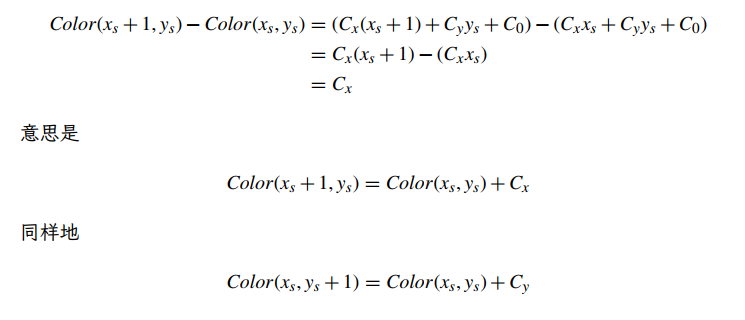
与 1/z 一样,我们可以简单地通过计算三角形中“基本片段”颜色的前向差异来计算常量三角形的每个顶点属性的每个片段值。
6.2.2 透视矫正插值 Perspective-Correct Interpolation
当使用透视投影投影在相机空间中没有恒定深度的三角形时,生成的映射不是屏幕仿射的。从我们对深度缓冲区值的讨论中,我们可以看到给定视图空间中的一般(不一定是恒定深度)三角形,从 NDC 空间到三角形上的视图空间点的映射具有以下形式
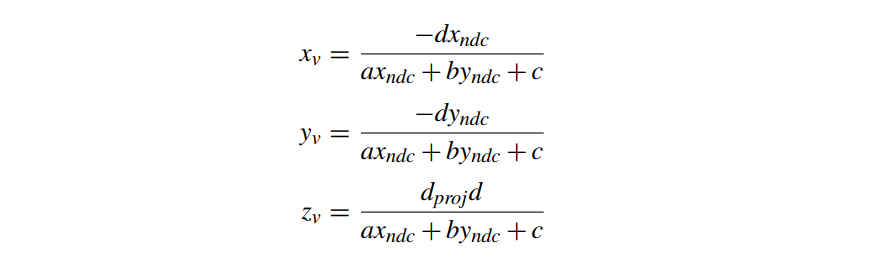
这些是射影映射(projective mappings),而不是我们在恒定深度情况下的仿射映射(affine mappings)。这意味着从屏幕空间到线性插值的每个顶点属性的整体映射也是投影的。为了在透视投影中正确插入三角形的顶点属性,我们必须使用这种更复杂的投影映射。
大多数硬件渲染系统现在以透视矫正的方式插入所有每个顶点的属性。然而,这并不总是通用的,而且对于在低功率平台上运行的旧软件渲染系统来说,它太昂贵了。如果被插值的每个顶点属性是来自每个顶点光照的颜色,例如在 Gouraud 着色的情况下,则可以在精度和速度之间进行权衡。请记住,Gouraud 着色首先是一种近似方法,在“正确性”的基础上使用投影映射的理由有所减少。此外,Gouraud 阴影颜色的插值往往非常平滑,以至于很难判断插值是否透视正确。事实上,Heckbert 和 Moreton[75] 提到纽约理工学院的离线渲染器在几年前就在透视中错误地插值了颜色,直到有人注意到!因此,软件图形系统通常避免了昂贵的、透视正确的 Gouraud 颜色投影插值,而仅使用仿射映射和前向差分。
也就是说,其他每个顶点的值,例如纹理坐标,并不能容忍透视矫正插值中的问题。对纹理进行光栅化的过程首先是对每个顶点的纹理坐标进行插值,以确定每个片段的正确值。实际上,在光栅化器中插值通常是纹理坐标(纹理坐标乘以纹理图像尺寸). 这个过程类似于对其他每个顶点属性进行插值。然而,由于纹理坐标的使用实际上与片段着色器中的顶点颜色有些不同,我们无法使用前面描述的屏幕仿射近似。纹理坐标需要正确的透视插值。纹理坐标的间接性质意味着虽然纹理坐标在三角形上平滑而微妙地变化,但生成的纹理颜色查找不会。
纹理坐标的问题与仿射和投影变换的属性有关。仿射变换将平行线映射到平行线,而射影变换只保证将直线映射到直线。任何曾经看过一条又长又直的道路的人都知道,形成道路边缘的两条线似乎在远处相遇,即使它们是平行的。透视,作为一种投影映射,不保留平行线。
仿射插值和投影插值之间差异的经典示例是纹理坐标是棋盘格,以透视图绘制。图 9 显示了作为图像的方格纹理,以及应用环绕到由两个三角形(两个三角形以轮廓或线框显示)形成的正方形的图像。当顶部在透视图中倾斜时,请注意,如果使用投影映射(图 10)映射纹理,则垂直线会按预期会聚到远处。
如果使用仿射映射对纹理坐标进行插值(图 11),我们看到两个不同的视觉伪影。首先,在每个三角形内,所有的平行线都保持平行,垂直线不会像我们预期的那样会聚。此外,请注意沿正方形对角线(共享三角形边缘)的线条中明显的“扭结”。这有可能乍一看似乎是插值代码的一个 bug,但稍微分析一下,它实际上是仿射变换的一个基本属性。仿射变换由三角形的三个点定义。结果,在定义了三角形的三个点及其纹理坐标后,变换就没有更多的自由度了。每个三角形独立于其他三角形定义其变换,结果是应该是一组穿过正方形的线的弯曲。
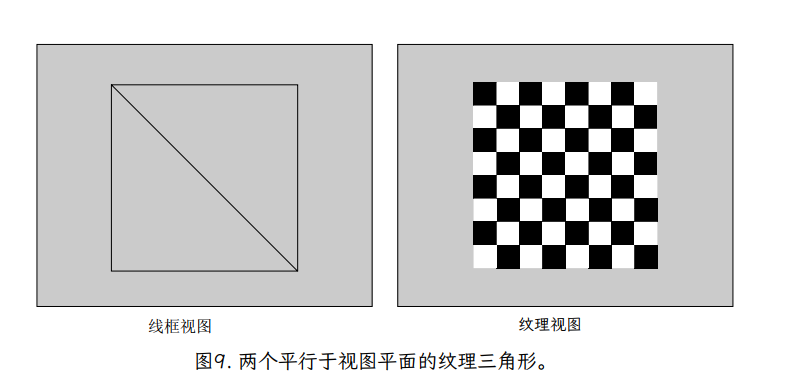
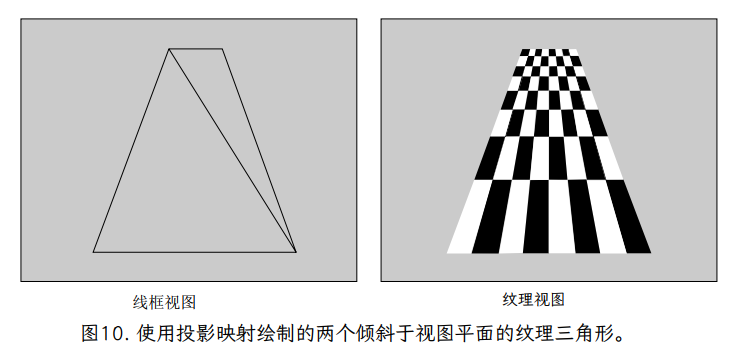

然而,投影变换具有额外的自由度,表示为与每个顶点关联的深度值。这些深度值改变了纹理坐标在三角形上插值的方式,并允许映射纹理图像中的直线在屏幕上保持笔直,即使跨越三角形边界。
幸运的是,这个解决方案相对简单,但成本很高。正如我们从公式 4 中看到的, 可以使用屏幕空间位置的仿射映射来计算。由于纹理坐标本身是仿射映射,我们可以将它们与 仿射映射组合起来,发现 和 是仿射映射。因此,这三个量( 、 和 )可以使用前向差分在三角形上进行插值。在每个片段中,最终 ( , ) 值可以通过将 取反得到 zv 来计算,然后将其乘以插值的 和 。
这种投射式映射的缺点是,它需要对每个片段进行正确的评估。
-
更新 的仿射前向差分操作 -
一个仿射前向差分操作来更新 -
一个仿射前向差分操作更新 -
从 恢复透视正确 的除法 5. 乘以 以恢复透视正确的 6. 乘以 以恢复透视正确的
1990 年代的许多 PC 游戏和一些视频游戏机使用较便宜(且不太正确)的真实透视纹理近似值。然而,如前所述,在现代硬件光栅化系统上,每个片段的透视矫正纹理被简单地假设。此外,可编程片段着色器基本上可以允许将任何逐顶点属性用作纹理坐标这一事实进一步影响了硬件供应商以正确的视角插入所有顶点属性。在实践中,许多 GPU 并未针对所有顶点属性遵循上述过程。相反,他们使用透视矫正插值计算一组重心坐标,然后使用这些重心坐标将每个属性映射到正确的值。
6.3 每个片段的间接值
每个顶点属性的插值只是每个片段值的一种可能来源。由于现代片段着色器的强大功能,纹理坐标和其他值不需要直接来自每个顶点的属性。作为涉及其他逐顶点属性的计算的结果,可以从片段着色器本身中生成的一组坐标评估纹理查找。
在片段着色器中生成的纹理坐标甚至可以是之前在同一个片段着色器中查找纹理的结果。在这种技术中,第一个纹理中的纹理图像值不是颜色,而是纹理坐标本身。这是一种非常强大的技术,称为间接纹理。第一个纹理查找形成一个表查找或间接查找,为第二个纹理查找生成一个新的纹理坐标。
间接纹理是更一般的纹理案例的示例,其中评估纹理样本会生成除颜色之外的“值”。显然,并非所有纹理查找都用作颜色。然而,为了在下面的讨论中易于理解,我们将假设纹理图像的值代表最常见的情况——颜色。
7 光栅化纹理 Rasterizing Textures
上一节描述了如何在片段着色器中插入通用的逐顶点属性,如果这些属性是我们所需要的,我们可以简单地评估或运行片段着色器并计算片段的颜色。但是,如果我们有纹理查找,这只是第一步。在计算或插值给定片段的纹理坐标后,必须将纹理坐标映射到纹理图像本身以产生颜色。
一些最早的着色语言要求纹理只能通过每个顶点的属性来处理,并且在某些情况下,甚至在调用片段着色器之前就实际计算了纹理查找。然而,如上所述,现代着色器允许在片段着色器本身中计算纹理坐标,甚至可能作为纹理查找的结果。此外,着色器中的条件和不同的循环迭代可能会导致某些片段的纹理查找被跳过。因此,我们将纹理的光栅化视为片段着色器本身的一部分。
事实上,虽然在片段着色器内部完成的数学计算很有趣,但孤立片段着色器评估中最(数学)复杂的部分是纹理查找的计算。正如我们将看到的,纹理查找不仅仅是抓取并返回最近的纹素到片段中心。将纹理映射到几何体,然后将几何体映射到片段的广泛映射需要一组更大的技术来避免明显的视觉伪影。
7.1 纹理坐标复习
在我们对光栅化纹理的讨论中,我们将使用多种不同形式的坐标。这包括应用程序级的、标准化的、与纹理无关的纹理坐标(u、v),以及与纹理大小相关的纹理坐标( 、 ),它们都被认为是实数值。我们在纹理介绍中使用了这些坐标。
纹理坐标的最终形式是整数纹素坐标,或纹素地址。这些代表对纹理图像数组的直接索引。与其他两种形式的坐标不同,它们(顾名思义)是整数值。从纹素坐标到整数纹素坐标的映射不是通用的,并且取决于纹理过滤模式,这将在下面讨论。
7.2 将坐标映射到纹素 Mapping a Coordinate to a Texe
在对纹理进行光栅化时,我们会发现——由于透视投影的性质、几何对象的形状以及纹理坐标的生成方式——片段很少直接和精确地对应于一对一映射中的纹素。任何支持纹理的光栅化器都需要处理各种纹素到片段的映射。在软纹理初始讨论中,我们注意到纹素坐标通常包括精度(通过浮点数或定点数),它比似乎需要的每纹素值更细粒度。正如我们将看到的,在某些情况下,我们将在称为纹理过滤的过程中使用这种所谓的子像素精度来提高渲染图像的质量。
纹理过滤(以其多种形式)通过混合纹理像素坐标映射和结果纹理像素值的组合,来执行从实值纹理像素坐标到最终纹理图像值或颜色的映射。我们将对纹理过滤的讨论分为两种主要情况:一种是单个纹素映射到一个具有多个片段大小(放大)的区域,另一种是多个纹素映射到单个片段(缩小)所覆盖的区域,因为它们的处理方式完全不同。
7.2.1 放大纹理 Magnifying a Texture
我们最初的纹理讨论指出,将这些子纹理精确坐标映射到纹理图像颜色的一个常见方法是简单地选择包含片段中心点的纹理,并直接使用它的颜色。这种方法称为最近邻纹理,计算起来非常简单。对于任何 (
,
) texel 坐标,整数 texel 坐标 (
,
) 是最近的整数 texel 中心,通过截断计算: 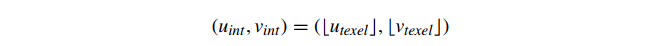
计算完这个整数纹素坐标后,我们只需使用函数 Image(),它将整数纹素坐标映射到纹素值,以查找纹素的值。返回的颜色被传递给当前片段的片段着色器。虽然这种方法计算简单快速,但当纹理以单个纹素覆盖超过 1 个像素的方式映射时,它有一个明显的缺点。在这种情况下,纹理被称为放大,因为屏幕上的多个片段的四边形块完全被纹理中的单个纹理像素覆盖,如图 12 所示。

使用最近邻纹理,正方形中的所有 ( , )texel 坐标
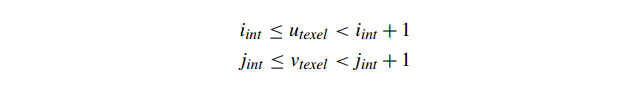
将映射到整数纹理坐标(iint,jint),从而产生一个恒定的片段着色器值。这是纹素空间中高度和宽度为 1 的正方形,以纹素中心为中心。这会产生明显的恒定颜色正方形,这往往会引起人们对低分辨率图像已映射到表面的事实的注意。请参阅图 12 以获取与片段着色器一起使用的最近邻过滤纹理的示例,该片段着色器直接将纹理作为最终输出颜色返回。在大多数情况下,这种块状结果不是所需的视觉印象。
问题在于最近邻纹理表示纹理图像作为 (u,v) 的分段常数函数。生成的片段着色器属性在三角形中的所有片段中保持不变,直到 或 发生变化。由于 floor 操作在整数值处是不连续的,这会导致由三角形表面上的纹理表示的函数中的尖锐边缘。
纹素边界不连续颜色问题的常见解决方案是将纹理图像值视为指定了不同类型的函数。我们不是从离散纹理图像值创建分段常数函数,而是创建分段平滑颜色函数。虽然有很多方法可以从一组离散值创建平滑函数,但光栅化硬件中最常见的方法是在二维中每个纹素中心的颜色之间进行线性插值。该方法首先计算小于 ( , ) 的最大纹素中心坐标 ( , ),即纹素坐标(即纹素坐标的下限减去半纹素偏移量):
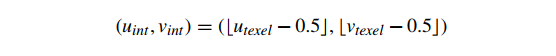
换句话说,(uint,vint) 定义了四个相邻 texel 中心的正方形的最小角(纹理图像空间的左下角),它们“约束(buond)”了 texel 坐标(图 13)。找到这个正方形后,我们还可以计算一个小数纹理坐标 0.0≤ , <1.0,它定义了 4 纹理正方形内的纹理坐标的位置。
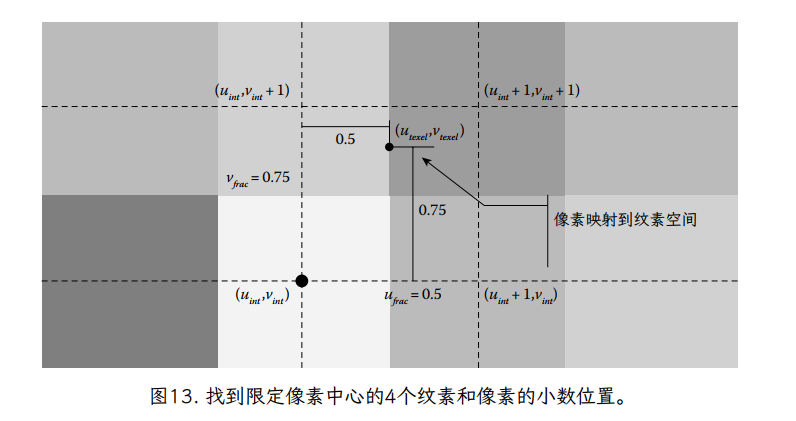
我们使用 Image() 来查找正方形四个角的纹素颜色。为了便于记号,我们为正方形四个角的纹理颜色定义了以下简写形式(图 14):
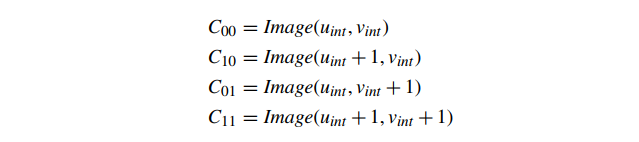
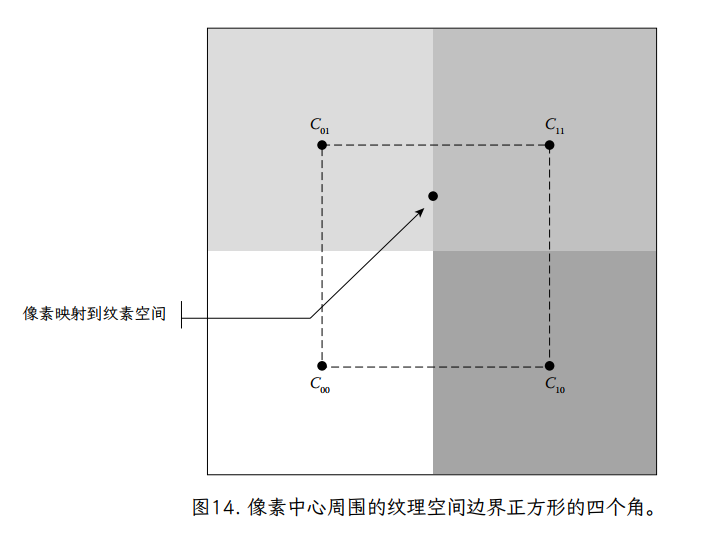
然后,我们定义了一个平滑的插值的 4 个纹素围绕纹素坐标。我们将平滑映射定义为两个阶段。首先,我们基于分数 u 坐标,沿着正方形的最小 v 边在颜色之间线性插值: 
并且类似地沿着最大 v 边:

最后,我们使用分数 v 坐标在这两个值之间进行线性插值
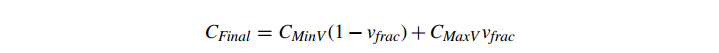
有关这两个步骤的图形表示,请参见图 15。将这些代入一个单一的直接公式,我们得到
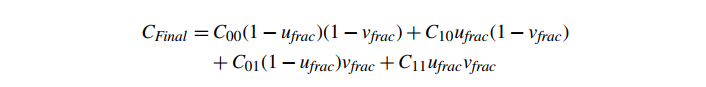
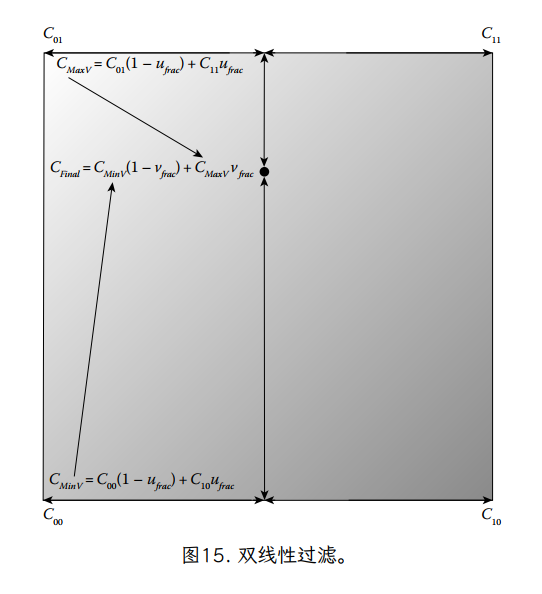
这被称为双线性纹理过滤(bilinear texture filtering),因为插值涉及到二维的线性插值,从四个相邻纹理图像值生成平滑函数。它在硬件 3D 图形系统中非常流行。我们先沿 u 插值,然后沿 v 插值的事实并不影响结果(除了潜在的精度问题)。快速替换表明,无论哪种方法,结果都是相同的。但是,请注意这不是仿射映射。二维仿射映射是由三个不同的点唯一定义的。我们的双线性纹理映射的第四个源点可能与其他三个点定义的映射不匹配。
使用双线性过滤,整个纹理域的颜色是连续的。一个最近邻过滤和双线性过滤之间视觉差异的示例如图 16 所示。虽然双线性滤波可以通过减少视觉块状来极大地提高放大纹理的图像质量,但它不会为纹理添加新的细节。如果将纹理放大很多(即 1 纹素映射到许多像素),由于缺乏细节,图像看起来会很模糊。图 16 所示的纹理被高度放大,导致左图 (a) 中出现明显的块状,右图 (b) 中出现模糊。

7.2.2 实践中的纹理放大
IvAPI 使用 IvTexture 函数 SetMagFiltering 来控制纹理放大率。Iv 支持双线性过滤和最近邻选择。它们分别设置如下:
IvTexture* texture;
// ...
{
// Nearest-neighbor
texture->SetMagFiltering(kNearestTexMagFilter);
// Bilinear interpolationc
texture->SetMagFiltering(kBilerpTexMagFilter);
// ...
7.2.3 纹理缩小
到目前为止,在我们讨论光栅化的过程中,我们主要通过中心来指代片段——位于正方形片段中心的无穷小点(现在继续假设只有完整的片段)。但是,片段具有非零区域。片段区域和代表它的点样本之间的这种差异在纹理的常见情况下变得非常明显。
举个例子,想象一个物体离相机很远。场景中的物体通常都具有高细节的纹理。这样做是为了避免模糊(比如我们在图 16b 中看到的模糊),当一个物体靠近相机时,它应用了一个低分辨率的纹理。当相同的物体和纹理被移动到远处时(这是动态场景中的常见情况),由于物体的视角缩放,同样的,详细的纹理将被映射到屏幕上越来越小的区域。这被称为纹理缩小,因为它是放大的反比。这导致相同的对象和纹理覆盖的碎片越来越少。
在一个极端(但实际上很常见)的情况下,整个高细节纹理可能是以这样一种方式映射,它只映射到几个片段。图 17 提供了这样一个例子;在这种情况下,请注意,如果对象稍微移动(甚至小于一个像素),覆盖片段中心点的确切纹素可能会发生巨大变化。事实上,这样的点采样在纹理中几乎是随机的,并且会导致用于片段的纹理的点采样颜色随着对象在屏幕上以微小的亚像素量移动而在帧与帧之间剧烈变化。随着时间的推移,这可能会导致闪烁,这是动画渲染图像中令人分心的伪影。
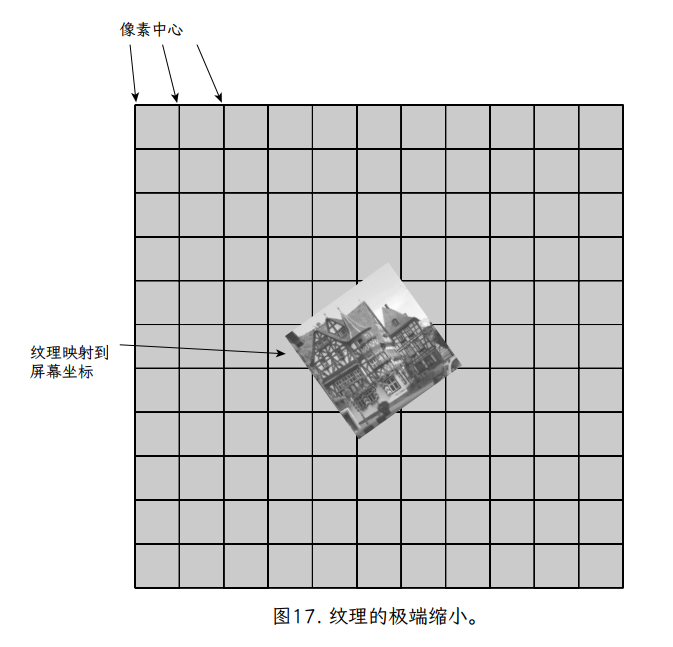
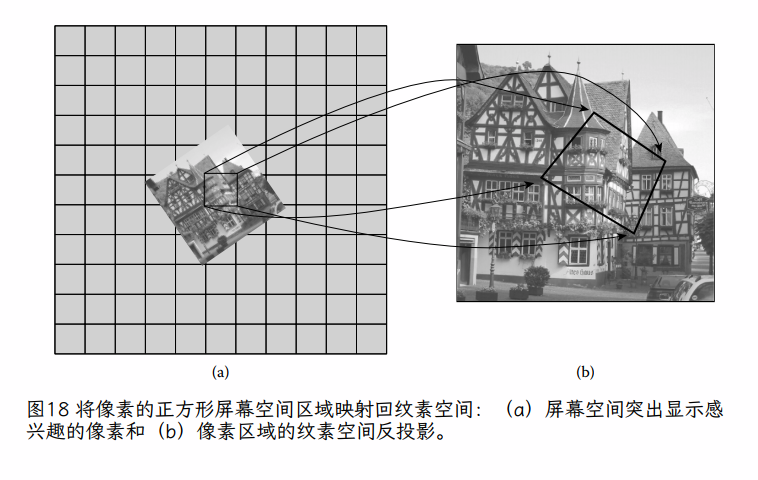
问题在于,纹理中的大多数纹素对片段几乎都有相同的“要求”,因为它们都投影在片段的矩形区域内。片段纹理样本的整体颜色应代表其内部的所有纹素。一种思考方法是将投影平面上完整片段的正方形映射到三角形平面上,得到一个(可能是倾斜的)四边形,如图 18 所示。为了公平地评估该片段的纹理颜色,我们需要根据每个纹素覆盖的四边形的相对面积,计算该四边形中所有纹素颜色的加权平均值。给定纹素覆盖的片段越多,该纹素的颜色对片段纹理样本的最终颜色的贡献就越大。
虽然精确的面积加权平均方法会给出正确的片段颜色和将避免点采样出现的问题,实际上这不是最适合实时光栅化的算法。根据纹理的映射方式,一个片段可以覆盖几乎无限数量的纹素。在每个片段的基础上查找和求和这些纹素将需要潜在的无限量的每个片段计算,这甚至远远超出了硬件光栅化系统的能力。需要一种更快(最好是恒定时间)的方法来逼近这种纹素平均算法。对于大多数现代图形系统,一种称为 mipmapping 的方法可以满足这些要求。
7.3 Mipmapping
Mipmapping[157] 是一种纹理过滤方法,可避免计算大量纹素的平均值。它通过预先计算和存储每个纹理的附加信息来实现这一点,这比标准纹理需要一些额外的内存。这是每个纹理样本的恒定时间操作,并且每个纹理需要固定数量的额外存储(实际上,它会将必须存储的纹素数量增加大约三分之一)。Mipmapping 是硬件和软件光栅化器中流行的过滤算法,并且在概念上相对简单。
要理解 mipmapping 背后的基本概念,请想象一个 2×2 纹素的纹理。如果我们看一下整个纹理映射到单个片段的情况,我们可以用 1×1 纹理(单一颜色)替换 2×2 纹理。一种合适的颜色是 2×2 纹理中 4 个纹素的平均值。我们可以直接使用这个新纹理。如果我们在应用程序加载时预先计算 1×1 纹素的纹理,我们可以根据需要简单地在两个纹理之间进行选择(图 19)。
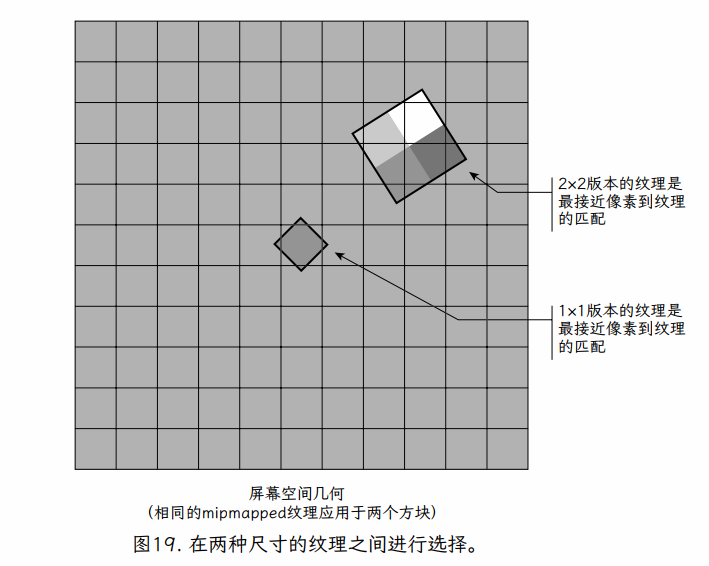
当给定的片段以这样一种方式映射,它只覆盖原始 2 × 2 纹素纹理中的 4 个纹素之一,我们简单地使用放大方法和原始 2 × 2 纹理来确定颜色。如果片段覆盖整个纹理,我们将直接使用 1×1 纹理,再次对其应用放大算法(尽管使用 1×1 纹理,这只是单个纹素颜色)。1×1 纹理充分代表了单个纹素中 2×2 纹理的整体颜色,但它不包括原始 2×2 纹素纹理的细节。这两个纹理版本都具有另一个版本没有的有用特性。
Mipmapping 采用这种方法,并将其推广到任何具有二维幂次的纹理。出于讨论的目的,我们假设纹理是正方形的(算法不需要这样做,我们稍后 将在实践中对 mipmapping 的讨论中看到)。
生成 mipmap 级别的一种方法是首先取初始纹理图像 Image0(缩写 I0) 的维数为 = = ,并通过将四个相邻纹素的每个方格平均为一个纹素来生成一个新版本的纹理。
这将生成大小为 Image1 的纹理图像
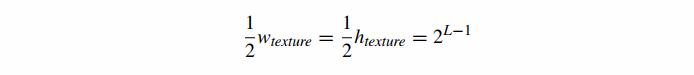
如下:
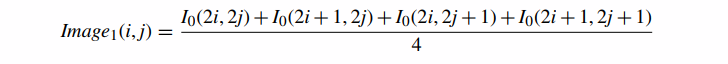
此时 0 ≤ i, j < 。Image1 中的每个纹素都代表了 Image0 中对应的 4 个纹素块的整体颜色(图 20)。请注意,如果我们对两个版本的纹理使用相同的原始纹理坐标,则图像 1 只是显示为图像 0 的模糊版本(具有图像 0 的一半细节)。如果图像 0 中大约四个相邻纹素的块覆盖了一个片段,那么我们可以在纹理时简单地使用图像 1。但是更极端的缩小情况呢?该算法可以递归地继续。对于每个尺寸大于 1 的图像 Imagei,我们可以定义 Imagei+1,其尺寸是 Imagei 的一半,并将 Imagei 的平均纹素定义为 Imagei+1。这会生成一整套原始纹理的 L+1 个版本,其中 Imagei 的尺寸等于
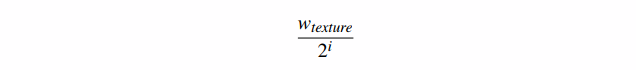
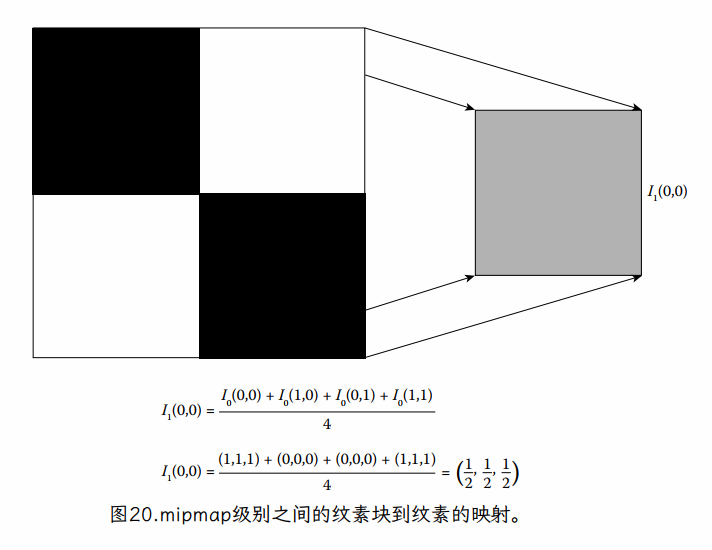

这形成了一个图像金字塔,每一个都是金字塔中前一个图像的一半尺寸(并包含四分之一的纹素)。图 21 提供了这样一个金字塔的例子。我们在加载时为场景中的每个纹理计算这个金字塔一次或作为离线预处理,并将每个整个金字塔存储在内存中。
这种计算 mipmap 图像的简单方法称为盒子过滤(正如我们将一个 2×2“盒子”的纹素平均为一个纹素)。盒子过滤不会产生非常高质量的 mipmap,因为它往往会使图像过于模糊,同时仍会产生伪影。其他更复杂的方法更常用于将每个 mipmap 级别过滤到下一个较低级别。一个很好的例子是 Lanczos 过滤器。参见 Turkowski[148] 或 Wohlberg[159] 了解其他图像过滤方法的详细信息。在生成每个级别时还必须小心,以确保对线性颜色进行计算;如果原始纹理颜色为 sRGB,则转换为线性,进行任何计算,然后转换回 sRGB 以存储 mipmap 值。
7.3.1 使用 Mipmap 对片段进行纹理处理
使用 mipmap 对片段进行纹理化的最简单、通用的算法可以总结如下:
-
通过确定片段角落处的纹理坐标,确定屏幕空间中的片段映射回纹理空间中的四边形。 -
将片段正方形映射到纹理空间中的四边形后,选择最接近将四边形精确映射到单个纹素的任何 mipmap 级别。 -
使用所需的放大算法,使用在上一步中选择的“最佳匹配”mipmap 级别对片段进行纹理处理。
确定最佳匹配 mipmap 级别的常用方法有很多,并且有多种方法可以将此 mipmap 级别过滤为最终的片段纹理值。我们希望避免必须将片段的角显式映射回纹理空间,因为这计算起来很昂贵。我们可以利用其他光栅化阶段已经计算的信息。正如我们在 5.1 和 6.2 节中看到的,在光栅化中通常计算给定片段中心的片段着色器输入值(例如,纹理坐标)与给定片段右侧和下方片段的值之间的差异,以用于前向差分。我们没有明确表示,这些差异可以表示为导数。下面的清单旨在为这四个偏导数中的每一个分配直观的值。对于不熟悉∂的人来说,它是偏导数的符号,是多元微积分的基本概念。∂运算符表示当您更改输入分量之一时,向量值函数的输出的一个分量会发生多少变化。

如果一个片段映射到大约 1 个 texel,那么
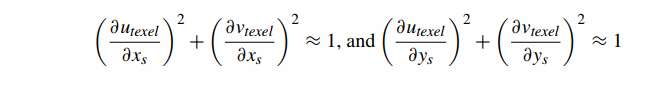
换句话说,即使纹理被旋转,如果片段与映射到它的纹素大小大致相同,那么单个片段上纹理坐标的整体变化长度约为 1 纹素。请注意,所有这四个差异都是独立的。这些部分取决于 utexel 和 vtexel,而这又取决于纹理大小。事实上,对于这些差异中的每一个,从 Image i 移动 Imagei+1 都会导致差异减半。正如我们将看到的,在计算 mipmapping 值时,这是一个有用的属性。
Heckbert[74] 中描述了一个用于将这些差异转化为像素‑纹素大小比度量的通用公式,该公式定义了一个映射回纹理空间的像素半径的公式。请注意,这实际上是两个半径中的最大值,utexel 中的像素半径和 vtexel 中的像素半径: 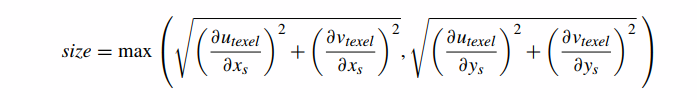
我们可以看到(通过替换∂)每次我们从 Imagei 移动到 Imagei+1 时,这个值都会减半(因为所有∂值都会减半)。因此,为了找到将 1 个纹素映射到完整片段的 mipmap 级别,我们必须计算 L 使得
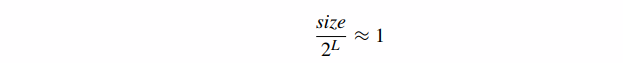
其中 size 是使用 Image0 的纹素坐标计算的。求解 L, 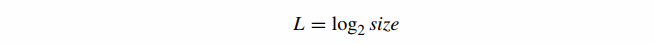
L 的这个值就是我们应该使用的 mipmap 级别的索引。请注意,如果我们插入对应于精确的一对一纹理到屏幕映射的部分,我们得到 size=1,这导致 L
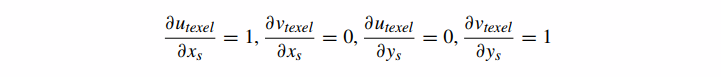
我们得到 size=1,这导致 L=0,这与预期的原始纹理图像相对应。这为我们提供了一种封闭形式的方法,可以将现有的部分(用于在扫描线上插入纹 理坐标)转换为特定的 mipmap 级别 L。最后的公式是
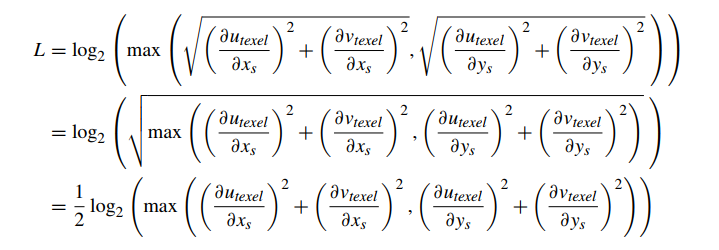
请注意,L 的值是实数,而不是整数(稍后我们将讨论将此值映射到离散 mipmap 金字塔的方法)。前面的功能只有一种可能用于计算 mipmap 级别 L 的选项。图形系统使用这个值的许多简化和近似值(它本身就是一个近似值)甚至其他函数来确定正确的 mipmap 级别。事实上,某些硬件设备使用的 L 的特定近似值是如此不同,以至于一些有经验的 3D 硬件用户实际上可以通过查看渲染的 mipmap 图像来识别特定的显示硬件。其他 3D 硬件允许开发人员(甚至最终用户)对使用的 L 值进行偏差,因为一些用户更喜欢“清晰”的图像(将 L 偏向负方向,选择更大、更详细的 mipmap 级别和每个片段),而其他人更喜欢“平滑”图像(将 L 偏向正方向,趋向于不太详细的 mipmap 级别和每个片段的纹素更少)。有关 mipmap 级别选择的一种情况的详细推导,请参阅 Eberly[35] 的第 106 页。
用于降低 mipmap 的每个片段开销的另一种方法是选择一个 L 值,因此在每帧中每个三角形的都有单个 mipmap 级别,并使用该 mipmap 级别光栅化整个三角形。虽然这种方法不需要对 L 进行任何每个片段的计算,但它可能会导致严重的视觉伪影,尤其是在三角形的边缘,其中 mipmap 级别可能会急剧变化。支持 mipmapping 的软件光栅化器经常使用这种方法,称为逐三角形 mipmapping (per‑triangle mipmapping)。
请注意,就其本质而言,mipmapping 倾向于在远处的物体上使用较小的纹理。这意味着 mipmapping 实际上可以提高软件光栅化器的性能,因为较小的 mipmap 级别比完整细节纹理更可能适合处理器的缓存。在大多数 GPU 上也是如此,因为小型片上纹理缓存存储器 (small, on-chip texture cache memories) 用于保存最近访问的纹理图像区域。由于 GPU 和软件光栅化器在某种程度上受到读取纹理的内存带宽的限制,因此将纹理保留在缓存中可以显着降低这些带宽需求。此外,如果点采样与未映射的纹理一起使用,则相邻像素可能需要读取纹理中相距较远的部分。通过纹理的这些大的每像素步幅可能会导致可怕的缓存行为,并可能严重阻碍非 mipmapped 光栅化器的性能。这些由缓存未命中引起的处理器管道“停止(stalls)”或等待使得计算 mipmapping 信息的成本(至少在每个三角形的基础上)是值得的,与视觉质量的显着提高无关。
7.3.2 纹理过滤和 Mipmap Texture Filtering and Mipmaps
上述方法的工作原理是,给定片段将有一个单一的“最佳”mipmap 级别。然而,由于每个 mipmap 级别是每个维度中下一个 mipmap 级别大小的两倍,因此最接近的 mipmap 级别可能不是精确的片段到纹理映射。线性 mipmap 过滤不是选择给定的 mipmap 级别作为最佳,而是使用类似于(双)线性纹理过滤的方法。基本上,mipmap 过滤使用实值 L 来查找限制给定片段与纹素比率的相邻 mipmap 级别对和 和 (地板和天花板符号)。剩余的小数部分 (L 到 ) 用于在两个 mipmap 级别中找到的纹理颜色之间进行混合。

放在一起,现在有两个独立的过滤轴,每个轴都有两种可能的过滤模式,导致四种可能的 mipmap 过滤模式,如表 1 所示。在这些方法中,最流行的是线性双线性,也称为三线性插值滤波或 trilerp,因为它是双线性插值的精确 3D 模拟。它是这些 mipmap 过滤操作中最昂贵的,需要每个片段查找 8 个纹素,以及 7 个线性插值(两个 mipmap 级别中的每一个级别三个,另外一个用于在级别之间进行插值),但它也产生了最平滑的结果。在 mipmap 级别之间进行过滤也会增加使用的纹理内存带宽量,因为每个样本都必须访问两个 mipmap 级别。因此,多级 mipmap 过滤通常会抵消前面提到的 mipmap 在硬件图形设备上的性能优势。
最后一种更新形式的 mipmap 过滤称为各向异性过滤。到目前为止讨论的 mipmap 过滤方法隐含地假设像素在映射到纹理空间时会产生一个与某个圆非常接近的四边形——换句话说,纹理空间中的四边形基本上是正方形的情况。在实践中,通常情况并非如此。对于极端透视下的多边形,一个完整的片段通常会映射到纹理空间中一个很长、很薄的四边形。标准的各向同性过滤模式可能看起来太模糊(根据四边形的长轴选择了 mipmap 级别)或太尖锐(根据四边形的短轴选择了 mipmap 级别)。各向异性纹理过滤在对 mipmap 进行采样时会考虑纹理空间四边形的纵横比,并且能够过滤 mipmap 中的非正方形区域以生成准确表示倾斜多边形纹理的结果。
7.3.3 实践中的 Mipmapping
的默认 CreateTexture 接口仅分配基本级别的纹理数据,而不分配其他 mipmap 级别。要使用 mipmaps 创建纹理,我们使用 CreateMipmappedTexture,如下所示:
IvResourceManager* manager;
// image data
const int numLevels = 5;
void* data[numLevels];
// ...
{
IvTexture* texture = manager->CreateMipmappedTexture(kRGBA32TexFmt,
width, height,
data, numLevels, kImmutableUsage);
}
请注意,我们现在传入了一个图像数据数组——每个数组条目都是一个 mipmap 级别。我们还必须指定级别数。如果使用动态或默认使用创建 mipmapped 纹理,我们还可以使用 IvTexture 函数 BeginLoadData 和 EndLoadData。但是,在 mipmap 的情况下,我们使用这些函数的参数 unsignedintlevel(以前默认为 0),它指定 mipmap 级别。最高分辨率图像的 mipmap 级别为 0。每个后续级别编号(1、2、3、...)表示 mipmap 金字塔图像,其尺寸为前一级别的一半。一些 API 要求指定一个“完整的”金字塔(一直到 1×1 纹素)才能使 mipmapping 正常工作。在实践中,为所有 mipmap 纹理提供完整的金字塔是一个好主意。完整金字塔中的 mipmap 层数等于
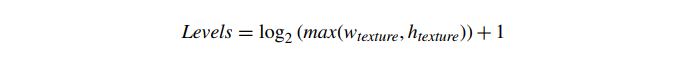
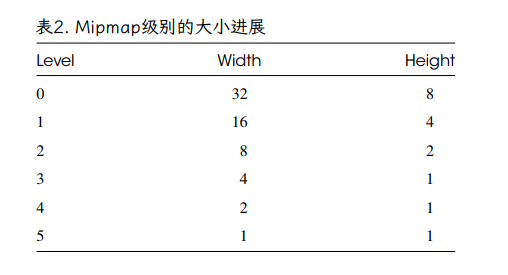
请注意,mipmap 级别的数量基于纹理的较大尺寸。一旦一个维度下降到 1 纹素,它就会保持在 1 纹素,而更大的维度继续减小。因此,对于 32×8‑纹素纹理,mipmap 级别如表 2 所示。
请注意,数组中提供的 mipmap 级别图像的纹素传递给 CreateMipmappedTexture 或 BeginLoadData 返回的数组中的设置必须由应用程序计算。Iv 只是接受这些图像作为 mipmap 级别并直接使用它们。一旦指定了纹理的所有 mipmap 级别,就可以通过将纹理采样器附加为着色器统一变量,将纹理用于 mipmap 渲染。指定整个金字塔的示例如下:
IvTexture* texture;
// ...
{
for (unsigned int level = 0; level < texture->GetLevels(); level++) {
unsigned int width = texture->GetWidth(level);
unsigned int height = texture->GetHeight(level);
IvTexColorRGBA* texels
= (IvTexColorRGBA*)texture->BeginLoadData(level);
for (unsigned int y = 0; y < height; y++) {
for (unsigned int x = 0; x < width; x++) {
IvTexColorRGBA& texel = texels[x+y* width];
// Set the texel color, based on
// filtering the previous level...
}
}
texture->EndLoadData(level);
}
为了设置缩小过滤器,使用了 IvTexture 函数 SetMinFiltering。Iv 支持非 mipmapped 模式(双线性过滤和最近邻选择)和所有四种 mipmapped 模式。质量最好的 mipmapped 模式(如前所述)是三线性过滤,使用
IvTexture* texture;
// ...
texture->SetMinFiltering(kBilerpMipmapLerpTexMinFilter);
// ...
8 从片段到像素 From Fragments to Pixels
到目前为止,本章已经讨论了生成片段,计算片段着色器的每个片段源值,以及评估片段着色器(纹理查找)的更复杂方面的一些细节。然而,本章的前几节概述了所有这些每片段工作的真正目标:在场景的渲染视图中生成像素的最终颜色。回想一下,像素是构成矩形网格屏幕(或帧缓冲区)的目标值。像素是“箱”,我们在其中放置对该像素区域有影响的的表面碎片。片段代表这些像素大小的表面碎片。最后,我们必须将所有落入给定像素的箱子中的片段转换为该像素的单一颜色和深度。到目前为止,我们在本章中做了两个重要的简化假设:
-
所有片段都是不透明的;也就是说,近处的片段会掩盖更远的片段。 -
所有片段都是完整的;也就是说,一个片段覆盖了整个像素。
综上所述,这两个假设导致了一个重要的整体简化:给定像素处最近的片段完全决定了该像素的颜色。在这样的系统中,我们需要做的就是在一个像素处找到最近的片段,对该片段进行着色,然后将结果写入帧缓冲区。在讨论可见表面确定和纹理时,这是一个有用的简化假设。但是,它限制了表示某些常见类型的表面材料的能力。它还可能导致屏幕上对象边缘出现锯齿状的视觉伪影。因此,现代图形系统中的两个附加功能消除了这些简化假设:像素混合允许片段部分透明,抗锯齿处理包含多个部分片段的像素。我们将通过对两者讨论来结束本章。
8.1 像素混合 Pixel Blending
像素混合是一个以片段为单位的非几何函数,它的输入是当前片段的着色颜色(我们称之为 Csrc),片段的 alpha 值(它是片段颜色的一个适当的组成部分,但为了方便,我们将其称为 Asrc),帧缓冲区中像素的当前颜色(Cdst),以及有时帧缓冲区中该像素的现有 alpha 值(Adst)。 这些输入,加上一对混合函数 Fsrc 和 Fdst,定义了将被写入帧缓冲器中的像素的结果颜色(以及可能的 alpha 值),即 CP。请注意,CP 一旦写入,在以后涉及同一像素的混合操作中就会变成 Cdst。 混合的一般形式是
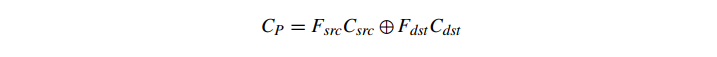
其中⊕可以表示+、−、min() 或 max()。我们还可以有第二对只影响 A 的函数。然而,在游戏中的大多数情况下,我们使用上面的公式并将⊕设置为+。
源和目标的 alpha 值通常被解释为不透明度(我们将在下面讨论 alpha 混合时了解原因)。但是,alpha 也可以解释为颜色对像素的部分覆盖——在这种情况下,alpha 是颜色覆盖的像素的百分比。一般来说,这种解释在游戏中很少使用,除非可能在界面(游戏面板)中。它在使用像素混合进行 2D 合成或图像分层(也称为 alpha 合成)时更常使用。我们将在 8.2 节中更详细地讨论像素覆盖。有关 alpha 作为覆盖率的更多信息,请参阅 [123]。
像素混合的最简单形式是完全禁用混合(“源替换”模式),其中片段替换现有像素。这相当于
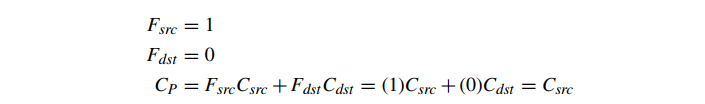
像素混合通常以其最常见的特殊情况的名称来指代:alpha 混合。Alpha 混合涉及使用源 Alpha 值 Asrc 作为新片段的不透明度,以在 Csrc 和 Cdst 之间进行线性插值:
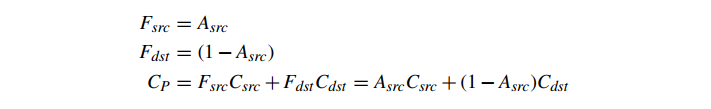
Alpha 混合需要 Cdst 作为操作数。因为 Cdst 是像素颜色(通常存储在帧缓冲区中),所以 alpha 混合可以(取决于硬件)要求从帧缓冲区中读取每个混合片段的像素颜色。这种增加的内存带宽意味着 alpha 混合会影响某些系统的性能(以类似于深度缓冲的方式)。此外,阿尔法混合还有其他几个特性,使其在实践中的使用有些挑战。
Alpha 混合旨在计算新的像素颜色,基于新的片段颜色表示可能半透明的表面,其不透明度由 Asrc 给出。
Alpha 混合仅使用片段 Alpha 值,而不是目标像素的 Alpha 值。假设现有像素颜色代表比当前片段更远的像素处的整个现有场景,半透明片段放置在该像素的前面。对于下面的讨论,我们将 alpha 混合表示为
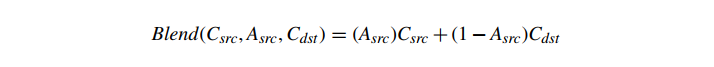
多个 alpha 混合操作的结果取决于顺序。每个 alpha 混合操作都假定 Cdst 表示比新片段更远的所有对象的最终颜色。如果我们将两个可能半透明的片段 (C1,A1) 和 (C2,A2) 混合到背景颜色 C0 上作为两个混合的序列,我们可以很快看到,一般来说,改变顺序混合改变结果。例如,如果我们比较两个可能的混合顺序,设置 A1=1.0,并展开函数,我们得到
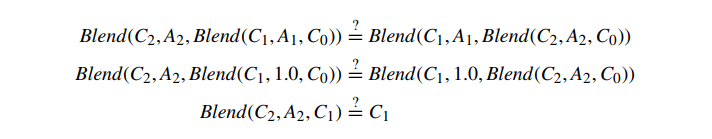
这两个方面几乎从来都不是平等的。两种混合顺序通常会产生不同的结果。在大多数情况下,两个表面与背景颜色的 alpha 混合取决于顺序。
8.1.1 像素混合和深度缓冲 Pixel Blending and Depth Buffering
在实践中,alpha 混合的这种顺序依赖性使深度缓冲复杂化。深度缓冲区基于这样的假设,即给定深度的片段将完全遮盖任何深度更大的片段,这仅适用于不透明对象。在存在 alpha 混合的情况下,我们必须以非常特定的顺序计算像素颜色。我们可以对所有三角形进行深度排序,但如上所述,这很昂贵,并且对许多数据集存在严重的正确性问题。相反,一种选择是假设对于大多数场景,半透明三角形的数量远小于不透明三角形的数量。给定一组三角形,尝试正确计算混合像素颜色的一种方法如下:
-
将场景中的不透明三角形收集到一个列表 O 中。 -
将场景中的半透明三角形收集到另一个列表 T 中。 -
使用深度缓冲正常渲染 O 中的三角形。 -
将 T 中的三角形按深度排序为从远到近的顺序。 -
使用深度缓冲,通过混合渲染排序列表 T。
这似乎可以解决问题。但是,在大多数情况下,每个三角形的深度排序仍然是一项昂贵的操作,必须在主机 CPU 上完成。此外,每个三角形排序无法解决所有差异,因为存在无法正确排序的三角形的常见配置。已经提出了其他方法来避免这两个问题。一种这样的方法是在每个对象级别进行深度排序以避免粗略的无序混合,然后使用更复杂的方法,例如深度剥离 [44],它使用高级可编程着色和对象的多次渲染来“剥离”更近的表面(使用深度缓冲区)并生成深度排序的颜色。虽然相当复杂,但该方法完全在 GPU 上运行,并专注于让最接近的图层正确,根据理论是越来越深的透明度获得递减的回报(因为它们对最终颜色的贡献越来越少)。
在某些特定应用的情况下,可以避免像素混合三角形的深度排序或深度剥离。另外两种常见的像素混合模式是可交换的,因此是顺序无关的。这两种混合模式称为 add 和 modulate。add 混合产生“发光”物体的效果,定义如下:
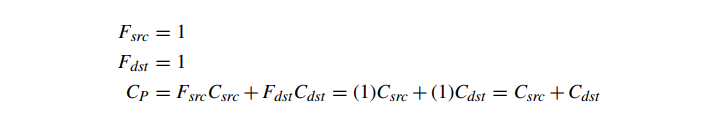
modulate 混合实现颜色过滤。它被定义为
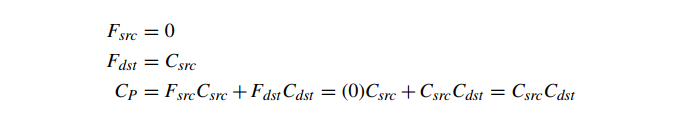
请注意,这些效果都不涉及源颜色或目标颜色的 alpha 分量。add 和 modulate 混合模式仍然需要先绘制不透明对象,然后是混合对象,但都不需要将混合对象分类为深度排序。因此,这些混合模式在粒子系统效果中非常流行,其中使用了数千个微小的混合三角形来模拟后期的烟雾、蒸汽、灰尘或水。其他更复杂的与顺序无关的透明度解决方案是可能的;一个例子见 [107]。
请注意,如果深度缓冲用于未排序的混合对象,则必须在禁用深度缓冲区写入的情况下绘制混合对象,否则两个混合对象的任何无序(从前到后)渲染将导致更多远处的物体没有被绘制。从某种意义上说,混合对象不存在于深度缓冲区中,因为它们不会遮挡其他对象。
8.1.2 预乘 Alpha Premultiplied Alpha
在上面的讨论中,我们假设我们的颜色与直接的 RGB 值和关联的 alpha 值一起存储。RGB 值代表我们的基色,alpha 代表它的透明度或覆盖率;例如,(1,0,0,12) 表示半透明红色。然而,更好的混合格式是我们将基本 RGB 值乘以 alpha 值 A,或者
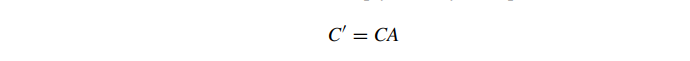
这称为预乘 alpha,现在我们的 RGB 值代表对最终结果的贡献。这里的假设是我们的 alpha 值位于 [0,1] 范围内。如果为每个通道使用 8 位值,则需要在乘法后除以 255。在使用 sRGB 时,请务必将线性到 sRGB 的转换应用于预乘颜色——不要将其应用于基色,然后乘以 alpha。使用这个公式,阿尔法混合变成
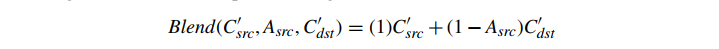
src 是 AsrcCsrc 这似乎并没有给我们带来太多好处,除了可能节省了一个乘法。但预乘 alpha 具有许多显着优势。首先,考虑我们使用带有双线性采样的纹理的情况。假设我们在透明 (A=0) 绿色纹素旁边有一个纯色 (A=1) 红色纹素。使用标准颜色,如果我们在它们之间进行中间处理,我们得到 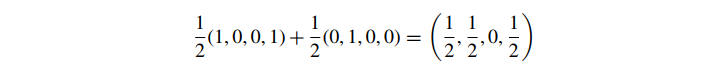
尽管我们从纯红色插值到完全透明的颜色,但不知何故我们最终得到了黄色的半透明颜色。如果我们改用预乘 alpha,透明色的颜色值全部变为 0,所以我们有 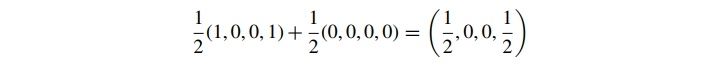
这是我们想要的半透明红色的预乘 alpha 版本。
即使我们不使用完全透明的颜色,我们仍然会得到奇怪的结果,比如说
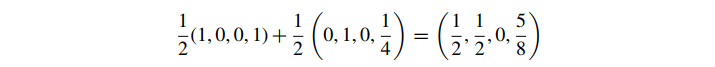
这又比我们预期的要黄得多。使用预乘的 alpha 颜色,我们得到:
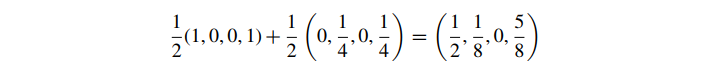
并适当降低了第二种颜色的贡献。因此,预乘 alpha 的第一个也是最重要的优点是它可以从纹理采样中得到正确的结果。
第二个优点是它允许我们将简单的混合方程扩展到更大的混合操作集,称为 Porter‑Duff 混合模式 [123]。这些不常用于渲染 3D 世界,但它们在混合 2D 元素中非常常见,因此了解如何为游戏内 UI 复制这些效果对于某些效果很有用。一个例子是“Src In”运算符,它将目的地的任何贡献替换为源的比例分数,或者:
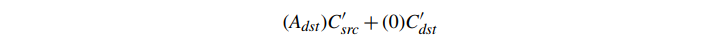
这最终成为:
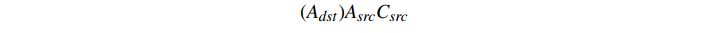
这是标准混合模式和纯色无法实现的。
第三个优点允许我们创建颜色值大于 1 的透明值,这对于创建照明效果很有用。例如,我们可以使用 (1,1,1,12) 的预乘 alpha 颜色,它具有 (2,2,2,12) 的直接颜色等价物。最终结果将对场景产生两倍的贡献,从而产生发射效果。Forsyth[49] 在粒子效果中提供了一个很好的用途。通常我们希望粒子以添加剂(即火花)开始,然后变成 alpha 混合(烟灰和烟雾)。通过使用预乘 Alpha,我们可以创建一个具有子区域的纹理,该子区域代表不同粒子类型的颜色,并将其与单一混合模式一起使用。火花粒子可以使用具有非零 RGB 值或 (R,G,B,0) 的零 alpha 颜色。烟雾粒子可以使用标准的预乘 alpha 颜色,或 (RA,GA,BA,A)。通过将这些与预乘 alpha 混合方程一起使用,火花区域被添加到场景中,烟雾区域将被 alpha 混合。对于单个粒子的生命周期,我们需要做的就是将其纹理坐标从纹理的不同区域映射到地图,其可见表示将从火花慢慢变为烟雾。并且所有粒子都将与单个纹理和单个绘制调用正确合成,而无需在 add 和 alpha 混合模式之间切换。
最后,当使用纯色时,混合图层不是关联的,因此为了获得混合图层 A‑D 的正确结果,您必须将 A 与 B 混合,然后将结果与 C 混合,然后将结果与 D 混合。但是,有有时您可能想先混合 B 和 C,例如某种基于屏幕的后处理效果。预乘 alpha 允许您这样做并稍后添加贡献 A 和 D。再次注意,为混合操作设置的顺序必须相同——您不能将 C 与 B 混合并期望得到与将 B 与 C 混合的相同结果。
预乘 Alpha 的唯一缺点是,当使用 8 位或更小的颜色通道时,最终会失去精度。如果您计划在某些可以放大它们的操作中仅使用 RGB 颜色,这只是一个问题。否则,为了获得最佳结果,强烈建议使用预乘 alpha。
8.1.3 在实践中混合
尽管在 Iv 支持的模式之外还有许多选项,但在大多数图形系统中都可以非常简单地启用和控制混合。通过 IvRenderer 函数 SetBlendFunc 设置混合模式,该函数在单个函数调用中设置 Fsrc、Fdst 和运算符⊕。要使用经典的 alpha 混合(没有预乘 alpha),函数调用是
renderer->SetBlendFunc(kSrcAlphaBlendFunc, kOneMinusSrcAlphaBlendFunc,
kAddBlendOp);
使用调用设置 Add 模式
renderer->SetBlendFunc(kOneBlendFunc, kOneBlendFunc, kAddBlendOp);
Modulate 混合可以通过调用使用
renderer->SetBlendFunc(kZeroBlendFunc, kSrcColorBlendFunc, kAddBlendOp);
还有更多的混合功能和操作可用;有关更多详细信息,请参阅源代码。
回想一下,在渲染混合对象时禁用 z 缓冲区写入通常很有用。这是通过深度缓冲屏蔽实现的,前面在深度缓冲部分中进行了描述。
8.2 抗锯齿 Antialiasing
我们之前提出的另一个简化光栅化假设,即部分片段被忽略或“提升”为完整片段的想法,引发了它自己的一系列问题。将所有片段转换为全有或全无情况的想法是允许我们假设单个片段将“赢得”一个像素并确定其颜色。我们使用这个假设将每个片段的计算减少到单点样本。
如果我们将像素视为纯点样本,没有区域,这是合理的。然而,在我们对片段的初步讨论和对 mipmapped 纹理的详细讨论中,我们发现情况并非如此;每个像素代表屏幕上一个具有非零面积的矩形区域。因此,在像素的矩形区域内可能会看到多个(部分)片段。图 22 提供了这种多片段像素的示例。
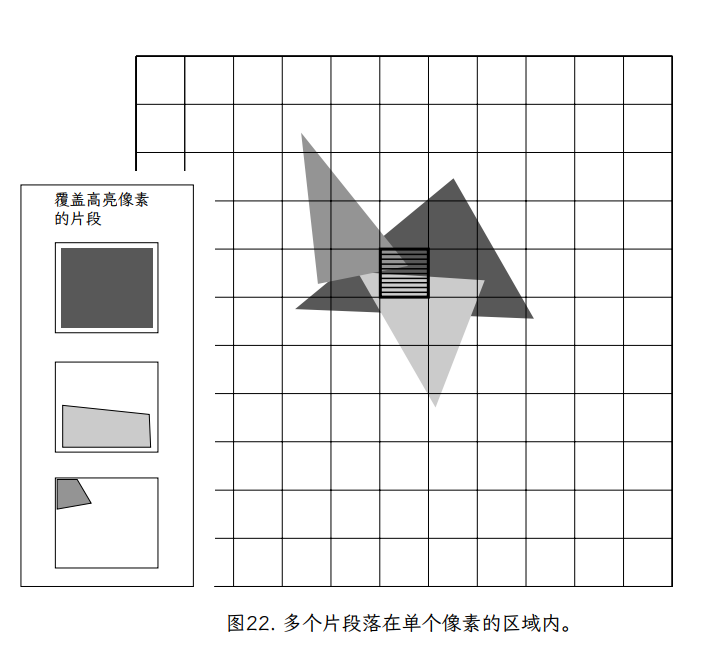
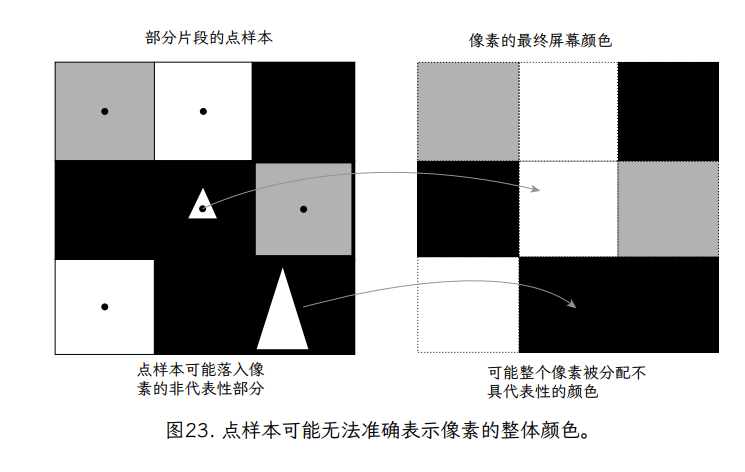
使用讨论的点采样方法,我们将选择单个片段的颜色来表示像素的整个区域。但是,如图 23 所示,这个像素中心点样本可能无法代表整个像素的颜色。在图中,我们看到像素的大部分区域是深灰色的,只有中心的一个很小的正方形是亮白色的。结果,选择亮白色的像素颜色并不能准确地表示整个像素矩形的颜色。我们对矩形颜色的感知与矩形中每种颜色的相对面积有关,这是单点采样方法无法表示的。
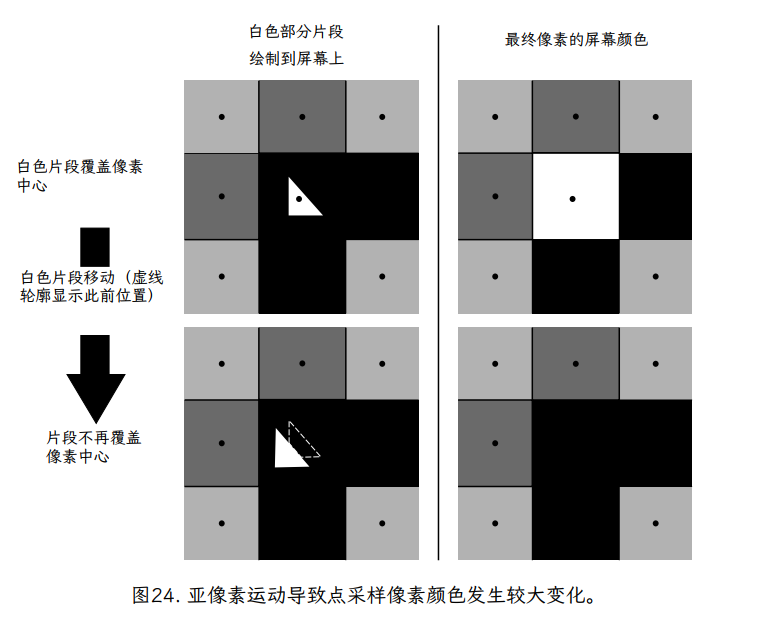
图 24 使这一点更加明显。在这种情况下,我们看到两个怪异像素的例子(每个 9 像素 3×3 网格中的中心像素)。在两种中心像素配置中(图左侧的顶部和底部),绝大多数表面区域都是深灰色。在这两种情况下,中心像素都包含一个小的白色片段。在这两种情况下,白色片段的大小相同,但在两种情况下,它们相对于中心像素的位置略有不同。在第一个(顶部)示例中,白色片段恰好包含像素中心,而在底部示例中,白色片段不包含像素中心。右列显示在每种情况下将分配给中心像素的颜色。尽管它们的几何配置几乎相同,但为这两个像素分配了非常不同的颜色。这证明了一个事实,即对像素颜色进行单点采样可能会导致一些随意的结果。事实上,如果我们想象白色碎片随着时间的推移在屏幕上移动,当白色碎片穿过每个像素的中心时,整行像素会在白色和灰色之间闪烁。
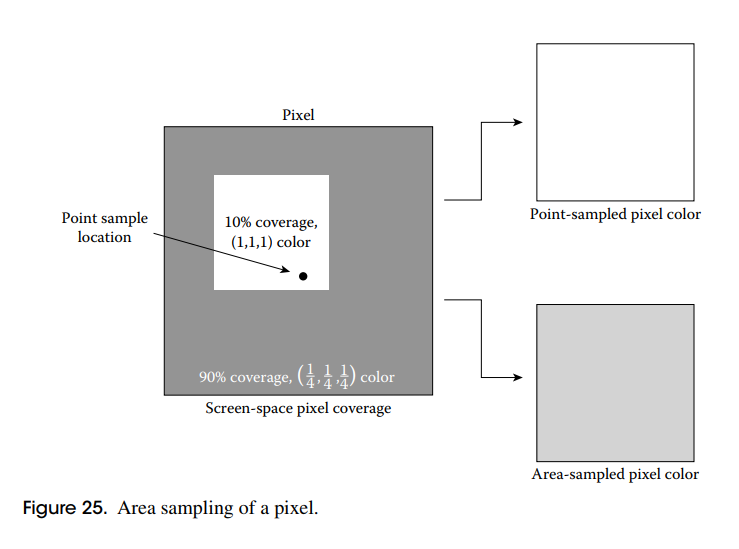
可以为图中的 2 个像素确定更准确的颜色。如果图形系统使用像素矩形内每个片段的相对面积来加权像素的颜色,结果会好得多。在图 25 中,我们可以看到白色片段覆盖了大约 10%的像素区域,留下了其余 90%为深灰色。通过相对区域加权颜色,我们得到一个像素颜色

请注意,此计算与白色片段在像素内的位置无关;只有碎片的大小和颜色很重要。这种基于区域的方法避免了我们看到的点采样错误。该系统可以扩展到给定像素内的任意数量的不同颜色的片段。给定一个面积为 a 的像素和一组 n 个不相交的片段,每个片段在像素内都有一个面积 ai 和颜色 Ci,则该像素的最终颜色为
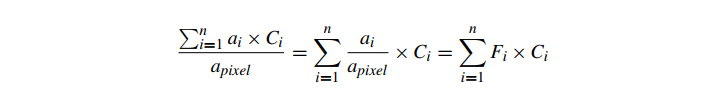
其中 Fi 是给定片段覆盖的像素的分数,或片段的覆盖范围。这种方法称为区域抽样。事实上,这确实是一个更一般的定积分的特例。如果我们想象我们有一个屏幕空间函数,它表示屏幕上每个位置的颜色(与像素或像素中心无关)C(x,y),那么像素的颜色定义为区域 l≤x≤r,t≤y≤b(像素的左、右、上、下屏幕坐标),使用这种区域采样方法,等价于
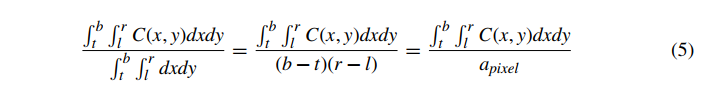
这是像素面积上颜色的积分,除以像素的总面积。公式 5 的求和版本是这个更一般的积分的简化,假设像素完全由分段恒定颜色的区域组成,即覆盖像素的片段。 作为对该方法的验证,我们将假设像素完全被一个颜色为 C(x,y)=CT 的完整片段覆盖,给出下式,这是我们在这种情况下所期望的颜色。
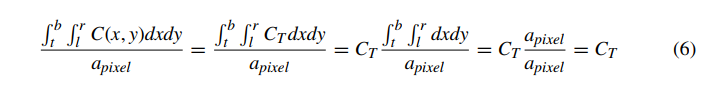
虽然区域采样确实避免了完全丢失或过分强调任何单个样本,但它不是唯一使用的方法,也不是代表显示设备现实的最佳方法(物理像素的强度实际上在像素矩形内可能不是恒定的))。公式 5 中显示的区域采样隐含地对像素的所有区域进行平均加权,使像素中心的权重等于边缘的权重。因此,它通常被称为未加权区域采样。另一方面,加权区域采样添加了一个加权函数,可以根据需要对像素的任何区域中颜色的重要性进行偏向。如果我们简化等式 5 原始像素边界和相关函数,使得像素的边界为 0≤x,y≤1,则等式 5 变为
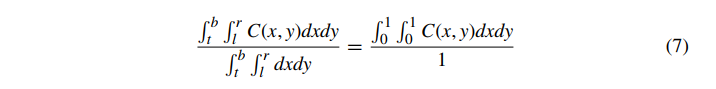
将等式 5 简化为等式 7,我们定义了一个加权函数 W(x,y),它允许根据需要对像素区域进行加权:
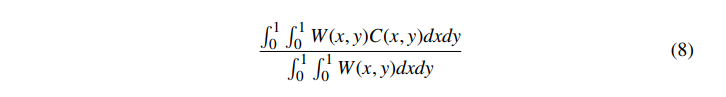
在这种情况下,分母被设计为根据加权面积进行归一化。对等式 6 的类似替换表明,像素上的恒定颜色映射到给定颜色。还要注意(与未加权区域采样不同)像素内图元的位置现在很重要。从公式 8 可以看出,未加权区域抽样只是加权区域抽样的一种特殊情况。对于未加权的区域采样,W(x,y)=1,给出:
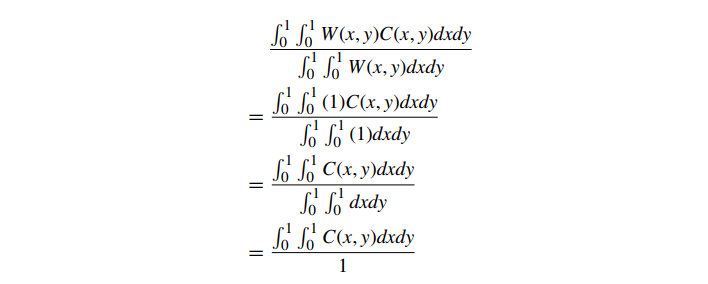
Hughes 等人对加权区域采样、其背后的理论以及许多常见的加权函数进行了全面讨论。[82]。对于那些希望获得更多深度的人,Glassner[54] 和 Wohlberg[159] 详细介绍了广泛的采样理论。
8.2.1 超采样抗锯齿 Supersampled Antialiasing
到目前为止讨论的方法显示了计算基于区域的像素颜色的理论方法。这些方法要求每个片段计算像素覆盖值。计算三角形的分析(精确)像素覆盖值可能既复杂又昂贵。在实践中,纯基于区域的方法不会直接导致简单、快速的硬件抗锯齿实现。
概念上最简单、最流行的抗锯齿方法称为过采样、超级采样或超采样抗锯齿 (SSAA)。在 SSAA 中,基于区域的采样通过在每个像素多个点对场景进行点采样来近似。在 SSAA 中,片段不是在每个像素级别生成,而是在每个样本级别生成。从某种意义上说,SSAA 在概念上只不过是将整个场景渲染为更大的(更高分辨率)帧缓冲区,然后将高分辨率帧缓冲区中的像素块过滤到最终帧缓冲区的分辨率。例如,超采样帧缓冲区的宽度和高度可能是屏幕上最终目标帧缓冲区的 N 倍。在这种情况下,超采样帧缓冲区中的每个 N×N 像素块将被过滤为屏幕帧缓冲区中的单个像素。
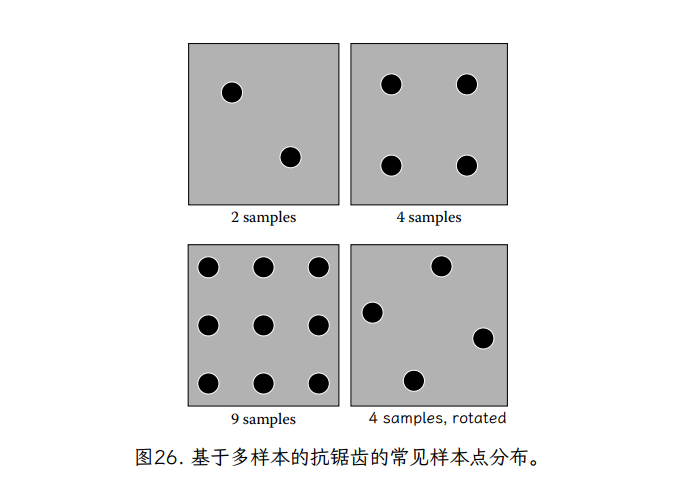
超级样本通过加权(或在某些案例未加权)平均值。这些采样模式的加权区域版本使用的位置和权重因制造商而异;示例位置的常见示例如图 26 所示。请注意,每个像素的超样本数量从少至 2 到多至 16 不等。M 样本 SSAA 将像素表示为 M 元素分段常数函数。部分片段将仅覆盖像素中的一些点样本,因此在结果像素中的权重会降低。
一些 N×N 样本网格也有旋转版本。这样做的原因是水平和垂直线的出现频率很高,并且也与像素布局本身相关。通过以正确的角度旋转样本,所有 N2 个样本都位于不同的水平和垂直位置。因此,通过像素从左到右或从上到下缓慢移动的水平或垂直边缘将分别与每个样本相交,因此将具有以 1/ 增量变化的覆盖率值。使用屏幕对齐的 N×N 样本模式,相同的移动水平和垂直边缘会同时与整行或整列样本相交,从而导致覆盖值以 1/N 的增量变化。旋转模式可以更好地利用可用样本的数量。
M-sample SSAA 每个像素生成 M 倍(如前所述,一般为 2-16 倍)的片段。每个这样的(较小的)片段都有自己的颜色,通过评估每个顶点的属性、纹理值和片段着色器本身,每帧的频率比正常渲染高 M 倍。每个样本的完整渲染管道非常强大,因为每个样本都真实地代表了该样本的几何颜色。它也非常昂贵,需要每个样本调用整个光栅化管道,从而将光栅化开销增加 2‑16 倍。即使是功能强大的 3D 硬件系统,这也太昂贵了。
8.2.2 多重采样抗锯齿 Multisampled Antialiasing
超级采样抗锯齿最昂贵的方面是为每个样本创建单独的片段以及每个样本产生的纹理和片段着色。另一种抗锯齿形式认识到,3D 渲染中锯齿最可能的原因是对象边缘的部分片段,其中像素将包含来自不同对象的多个部分片段,通常具有非常不同的颜色。多重采样抗锯齿 (MSAA) 试图在不像 SSAA 那样提高渲染成本的情况下解决这个问题。MSAA 的工作方式与正常渲染类似,因为它以最终像素大小生成片段(包括部分片段)。它只对每个片段评估一次片段着色器,因此与 SSAA 相比,片段着色器调用的数量显着减少。
MSAA 添加的信息是每个样本的片段覆盖率。当一个片段被渲染时,它的颜色会被评估一次,然后为片段覆盖的每个可见样本存储相同的颜色。样本中的现有颜色(来自较早的片段)可能会被新片段的颜色替换。但这是在每个样本级别完成的。在帧结束时,仍然需要“解析”来从多个样本中计算像素的最终颜色。然而,每个样本、每个片段仅计算一个覆盖值(一个简单的几何运算)和可能的一个深度值。计算片段颜色的昂贵步骤仍然为每个片段完成一次。与 SSAA 相比,这大大降低了 MSAA 的费用。
MSAA 有两个微妙之处值得一提。首先,由于 MSAA 是基于覆盖的,因此不会对完整片段计算抗锯齿。渲染完整的片段,就好像没有使用抗锯齿一样。另一方面,SSAA 通过在每个像素中多次调用片段的着色器来消除每个像素的锯齿。一个关键的观察结果是,在单采样完整片段中最有可能导致混叠(aliasing)的项目可能是纹理(因为它是片段中的最高频率值)。纹理已经应用了一种抗锯齿形式:mipmapping。因此,在大多数情况下,这对 MSAA 来说不是问题。
另一个问题是选择像素中的位置来评估部分片段上的着色器的问题。通常,我们在像素中心评估片段着色器。但是,部分片段甚至可能无法覆盖像素中心。如果我们在像素中心对片段着色器进行采样,我们实际上会将顶点属性外推到预期值之外。这在纹理中尤其明显,因为我们将在三角形中可能未映射的位置读取纹理。这会导致明显的视觉伪影。大多数 3DMSAA 硬件中的解决方案是选择片段覆盖的样本的重心。由于片段是凸的,因此重心将始终落在片段内部。这确实给系统增加了一些复杂性,但是不包括像素中心的片段的可能配置数量是有限的。凸性和中心样本未被触及的事实意味着可能存在一组非常有限的覆盖样本配置。甚至可以在构建硬件之前预先计算出一组可能的位置。但是,重心采样必须按逐个属性请求。否则,硬件将默认使用像素中心采样。
8.2.3 实践中的抗锯齿
对于大多数渲染 API,使用 MSAA 最重要的一步是创建与该技术兼容的渲染帧缓冲区。深度缓冲需要帧缓冲旁边的附加缓冲区来存储深度值,而 MSAA 需要特殊的帧缓冲格式,其中包括每个像素内每个样本的附加颜色、深度和覆盖值。不同的渲染 API 甚至相同 API 上的不同渲染硬件通常有不同的方法来显式请求 MSAA 兼容的帧缓冲区。一些呈现 API 允许应用程序以像素格式指定样本的数量和事件布局,而另一些则仅使用单个标志来启用单个(未指定)级别的 MSAA。
最后,在向屏幕呈现 MSAA 帧缓冲区时,某些呈现 API 可能需要特殊标志或限制。例如,有时必须使用特殊模式将 MSAA 帧缓冲区呈现给屏幕,该模式在呈现后将帧缓冲区的内容标记为无效。这考虑到帧缓冲区必须在呈现过程中从其每像素多样本格式“解析”为每像素单一颜色的事实,从而在此过程中破坏多样本信息。
9 总结
光栅化为我们提供了整个管道中一些最低级别但数学上最有趣的概念。我们已经讨论了数学概念(如投影变换)和渲染方法(如透视正确纹理)之间的联系。此外,我们在讨论深度缓冲区时解决了数学精度问题。最后,点采样与区域采样的概念出现了两次,与 mipmapping 和抗锯齿有关。无论是在硬件、软件还是两者的混合中实现,整个图形管道最终都被设计为只为光栅化器提供数据,这使得光栅化器成为最重要但最不为人知的渲染技术之一。
由于在各种平台上都可以使用高质量、低成本的 3D 硬件,因此必须实现自己的光栅化器的读者比例现在已经微乎其微了。然而,即使对于那些永远不需要编写光栅化器的人来说,了解光栅化器的功能也很重要。例如,即使是对深度缓冲系统的基本实际理解也可以帮助程序员构建一个场景,以避免在可见表面确定期间出现视觉伪影。了解光栅化器的内部工作原理可以帮助 3D 程序员快速调试几何管道中的问题。最后,这些知识可以指导程序员更好地优化他们的几何管道,为他们的光栅化器“提供”高性能数据集。
参考文献
[35] David H. Eberly. 3D Game Engine Design. Morgan Kaufmann Publishers, San Francisco, 2001.
[44] Cass Everitt. Interactive order-independent transparency. Technical report, NVIDIA, 2001.
[49] Tom Forsyth. Premultiplied alpha. http://home.comcast.net/∼tom_forsyth/blog.wiki.html.
[54] Andrew S. Glassner. Principles of Digital Image Synthesis. Morgan Kaufmann Publishers, San Francisco, 1994.
[74] Paul Heckbert. Texture mapping polygons in perspective. Technical report, New Institute of Technology, 1983.
[75] Paul Heckbert and Henry Moreton. Interpolation for polygon texture mapping and shading. In David Rogers and Rae Earnshaw, editors, State of the Art in Computer Graphics: Visualization and Modeling, pages 101–111. Springer-Verlag, Berlin,1991.
[76] Chris Hecker. Under the hood/behind the screen: Perspective texture mapping(series). Game Developer Magazine, 1995–1996.
[82] John F. Hughes, Andries van Dam, Morgan McGuire, David F. Sklar, James D. Foley, Steven K. Feiner, and Kurt Akeley. Computer Graphics: Principles and Practice. Addison-Wesley, Reading, MA, 3rd edition, 2013.
[89] Brano Kamen. Maximizing depth buffer range and precision. http://outerra.blogspot.com/2012/11/maximizing-depth-buffer-range-and.html.
[107] Morgan McGuire and Louis Bavoil. Weighted blended order-independent transparency. Journal of Computer Graphics Techniques (JCGT), 2(2):122 -141,2013.
[123] Thomas Porter and Tom Duff. Compositing digital images. In Proceedings of the 11th Annual Conference on Computer Graphics and Interactive Techniques (SIGGRAPH '84), pages 253–259, 1984.
[148] Ken Turkowski. Filters for common resampling tasks. In Andrew S. Glassner, editor,Graphics Gems, pages 147–165. Academic Press Professional, San Diego, 1990.
[157] Lance Williams. Pyramidal parametrics. In Computer Graphics (SIGGRAPH '83 Proceedings), 1983.
[159] George Wohlberg. Digital Image Warping. IEEE Computer Society Press, Los Alamitos, CA, 1990.
本文由 mdnice 多平台发布
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









