






前言
本人写下这篇博客是帮助自己加深对SQL语句的理解,以及复习所学知识,加深印象,记录学习过程,起初是只想复习查询语句,但是后面想着写都写了,就继续加了增删改的基础语句复习
目录
数据表的建立
在学习之前,我们需要几张数据表来实现查询操作,就拿最平常的员工表来进行示范
创建员工表
create table employee(
enumber INT primary key comment'员工编号',
ename VARCHAR(10) comment'员工姓名',
dname VARCHAR(20) comment'所属部门',
job VARCHAR(20) comment'员工职位',
salary INT comment'员工工资',
dnumber INT comment'部门编号'
);创建部门表
CREATE TABLE department (
dnumber INT COMMENT '部门编号',
dname VARCHAR(20) COMMENT '部门名称',
addr VARCHAR(20) COMMENT '部门地址'
);数据插入
创建完表后,往里面插入数据
INSERT INTO department values ('01','研发部','上海');
INSERT INTO department values ('02','销售部','北京');
INSERT INTO department values ('03','财务部','深圳');
INSERT INTO employee values ('1101','赵一','研发部','后端','11000','01');
INSERT INTO employee VALUES (1102, '王二', '研发部', '后端', 12000, 01);
INSERT INTO employee VALUES (1103, '张三', '研发部', '前端', 13000, 01);
INSERT INTO employee VALUES (1104, '李四', '销售部', '前端', 9000, 02);
INSERT INTO employee VALUES (1105, '张三', '研发部', '运维', 10000, 01);
INSERT INTO employee VALUES (1106, '刘五', '财务部', '会计', 9500, 03);
INSERT INTO employee VALUES (1107, '陈六', '研发部', '测试', 10000, 01);
INSERT INTO employee VALUES (1108, '胡七', '财务部', '会计', 9000, 03);
INSERT INTO employee VALUES (1109, '何八', '销售部', '销售员', 9200, 02);好了,两张表已经建立好了,接下来看下两张表的内容
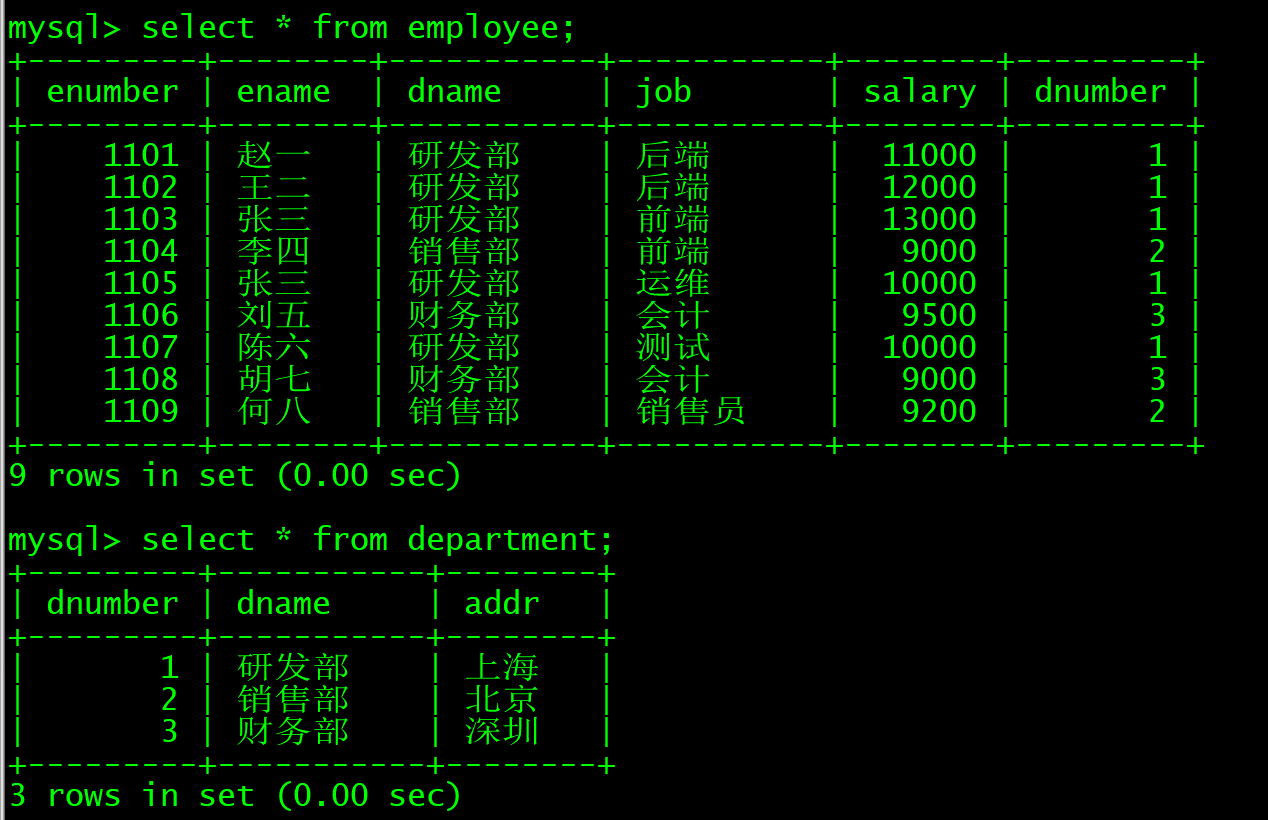
创建成功!
数据查询
数据查询之where条件查询
简单的查询
select * from employee;
--*代表全部,意思是查询employee表中的全部信息
select enumber,ename,job as ename_job from employee;
--as意为给job起个别名,叫ename_job
as会为表起个别名,还有一点要提的是,执行查询语句后并不会创建新的表,查询语句的本质是从现有表中查询数据,结果以临时结果集的形式返回(内存或临时表中),但不会持久化存储为新表。
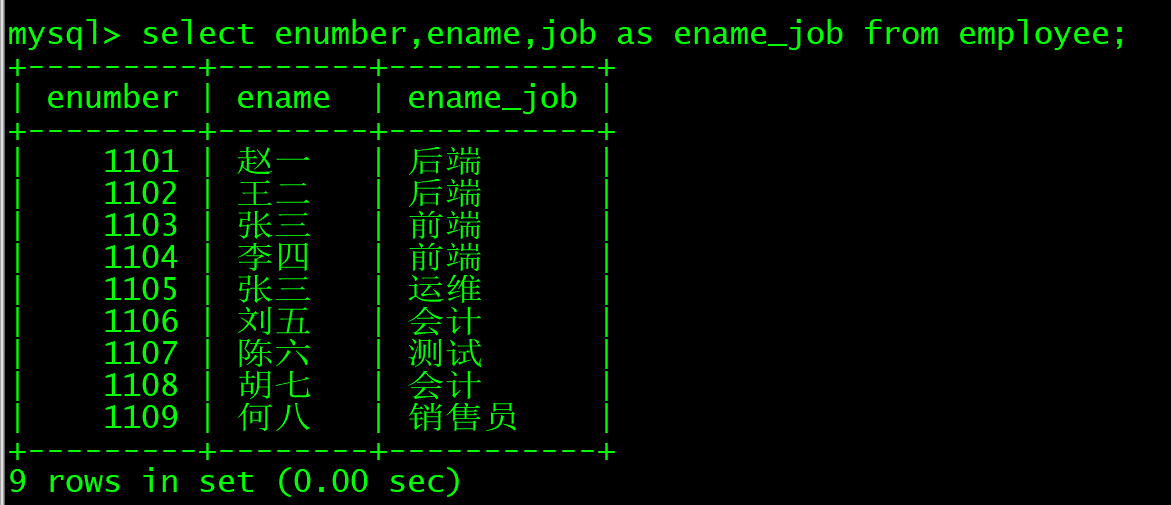
或者这样使用
select enumber,ename as 名字,job as ename_job from employee;
精确条件查询
select * from employee where ename='张三';
select * from employee where salary != 10000;
select * from employee where salary <> 10000;
select * from employee where salary > 10000;可以用where匹配条件,切记!语句中的匹配条件要与字符类型对应,ename的字符串类型为VARCHAR,salary的类型为INT。
!=:不等于; <>:不等于; >:大于; <:小于;用于INT类型的时候
其实根据英文一眼就能看出来所代表的意思
补充:数据修改
好吧,由于作者的疏忽,这里查询张三的时候,出现了两行。。。

我们修改下数据吧
update employee set ename='飞飞' where enumber=1105;这样编号为1105的那一行数据中,ename从张三改为了飞飞

关于修改语句,这里也一并补充一下
UPDATE 表名 SET 列1 = 值1, 列2 = 值2, ...
WHERE 条件; -- 筛选需要修改的记录,若省略则修改全量数据
比如我要修改飞飞的工资,工作之类的
update employee set salary=50000 where enumber=1105;
update employee set job='后端' where ename='飞飞';如果没有where条件,sql语句将会把所有人的工资和工作修改(后端要崛起了)
当然,也可以多行修改
update employee set department = '销售部', job = '销售经理' where ename = '飞飞';将飞飞的部门和职位都改变
批量修改
update employee set salary = 10000 where salary < 10000;将工资少于10000的人的工资改为10000(涨薪!)
补充:数据插入
语法很简单
insert into 表名(字段名) values(字段对应值);
insert into employee values (1110, '宇宇', '销售部', '销售大师', 11500, 2);还有一些其他的玩法,比如只插入一些
insert into employee (enumber,job) values (1111,'后端');那么显示出来的数据

切记,一定这些列的约束条件默认为空,也就是default null,在创建表的时候,不写约束条件就是默认为空,如果是not null,就会报错。一般插入条件是,只要将每一列的数据都填入进去,是可以省略字段名的,因为系统会一一对应,如果对应不上的话,就会报错 ,比如

只有一个values值1112导致无法对应,还有,字段名一定要加上括号。INT类型不要用'单引号'
插入还有一些其他的玩法
将表名2的数据复制到表名1中
insert into 表名1 select * from 表名2;
insert into 表名1(字段名1,字段名2) select 字段名1,字段名2 from 表名2;
insert into worker (enumber,ename) select enumber,ename from employee;
建表复制
create table 表名1 as select 字段名1,字段名2 from 表名2;
create table worker as select enumber ,ename from employee;
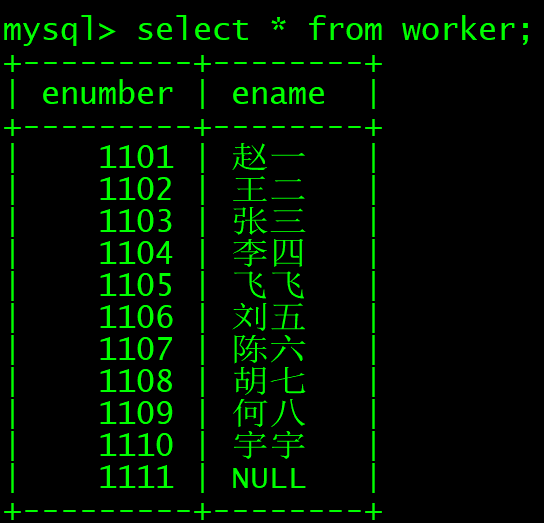
如果要复制整张表,就直接改为*(星号)
还有一次性插入多个数据
insert into 表名 (字段名) values (对应值1),(对应值2),(对应值3);
insert into worker values (1112,'一一'),(1113,'二二');
补充:数据删除
DELETE FROM 表名 WHERE 条件;
-- 示例:删除 worker 表中编号为 1102 的员工
DELETE FROM worker WHERE enumber = 02;
-- 注意:不带 WHERE 条件会删除全量数据!
DELETE FROM worker; -- 清空表,但保留表结构删除整张表
truncate table 表名;(也可以不写table)
delete from 表名;
drop table 表名;
这三个之间是有差别的
delete 会把删除的操作记录给记录起来,可以数据回退,不会释放空间,而且不会删除定义。
truncate不会记录删除操作,会把表占用的空间恢复到最初,不会删除定义
drop会删除整张表,释放表占用的空间。 不可恢复!
进行delete和truncate操作后,仍然可以往表里插入数据,但是使用drop后,无法再往表里插入数据,因为这张表不存在了,要重新建表,我们可以把worker表删了。
使用truncate
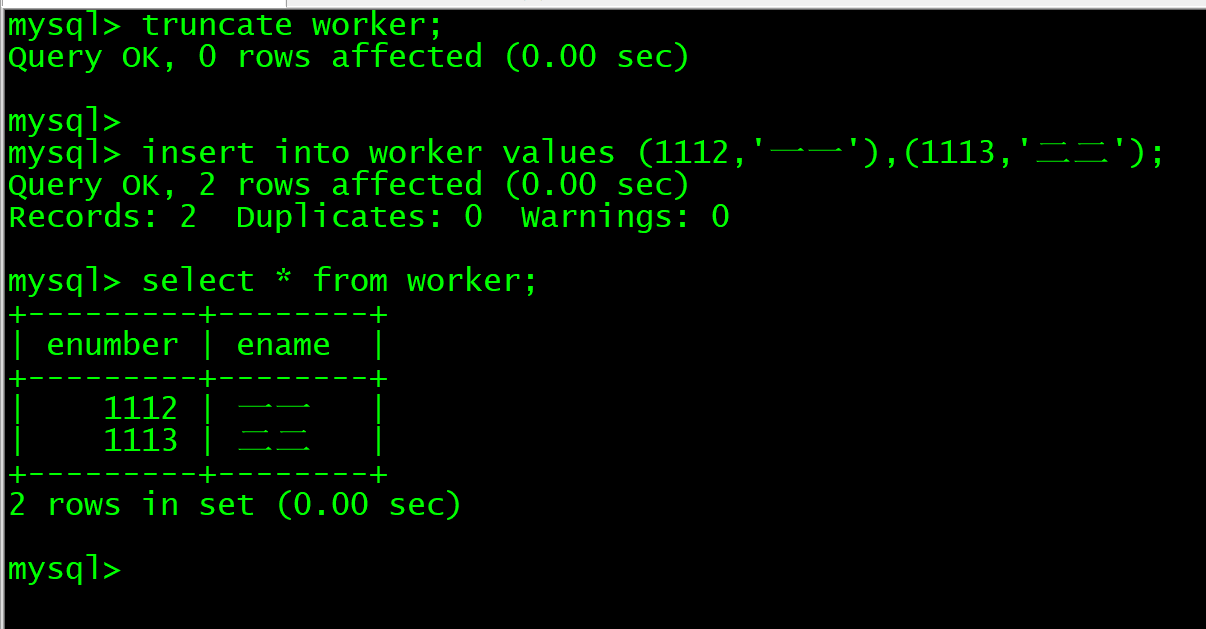
使用drop
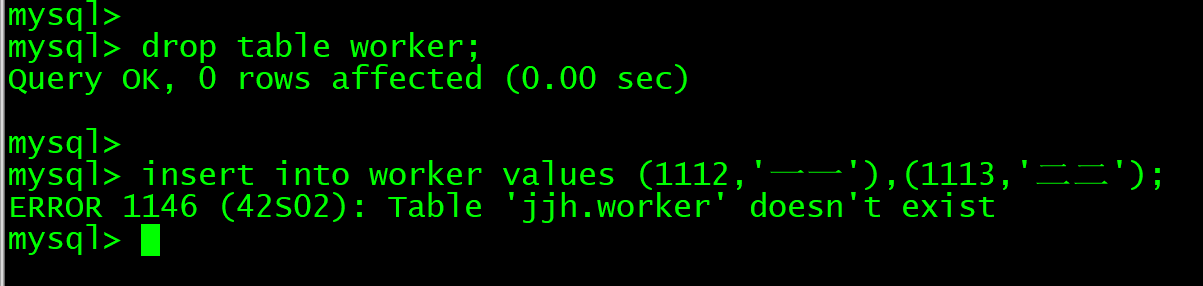 可以明显看到,使用drop后,无法再往worker中插入数据,因为这张表已经不存在了
可以明显看到,使用drop后,无法再往worker中插入数据,因为这张表已经不存在了
模糊条件查询
查询当前列表中姓王的人
select * from employee where ename like '王%';

这样的效果也是一样的,会显示王二;
select * from employee where enumber like '11%2';范围查询、离散查询、清楚重复值
范围查询主要用到between···and···(跟英语一样)
select * from employee where salary between 10000 and 20000;查询工资10000到20000的人
离散查询
select * from employee where ename in ('张三','李四','小红','小胡');
select * from employee where enumber in (1103,1104);在括号里面查询这些人,会查询到已有的人,两次查询结果是一样的

清楚重复值
select distinct(job) from employee;
select job from employee;
清楚job的重复值,两次输出结果不一样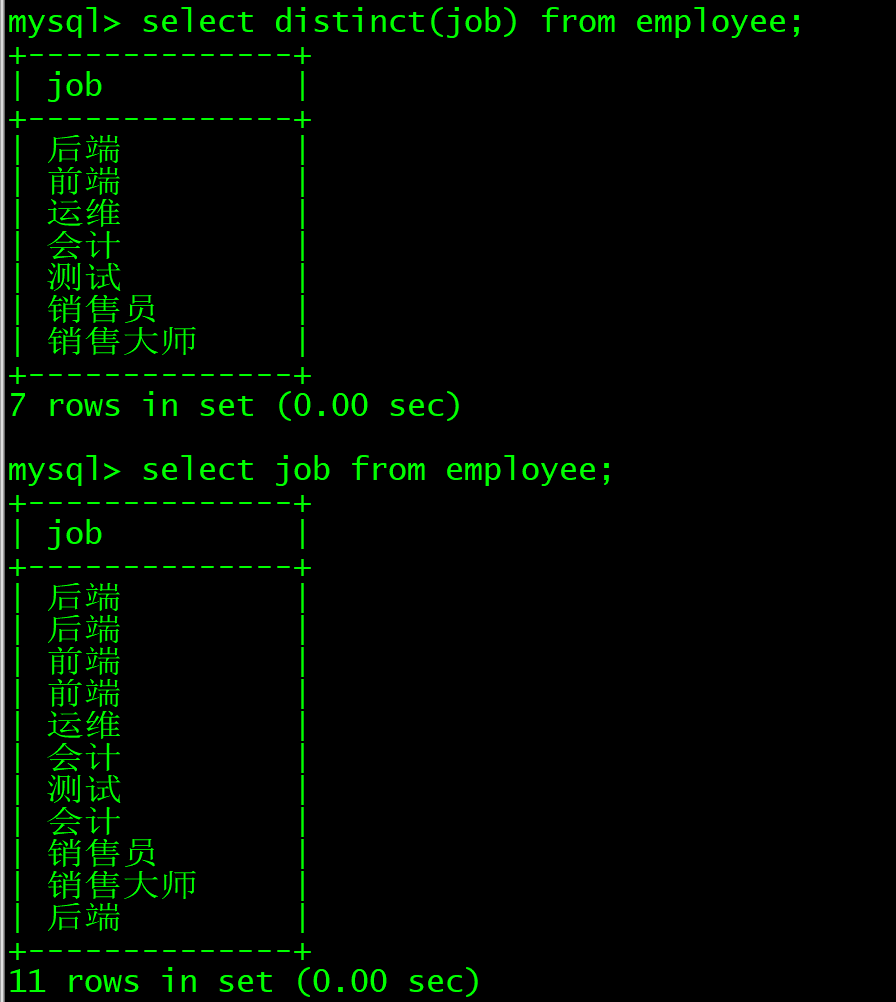
可以看到,上面清楚重复值后只有7行,而下面有14行
统计查询(聚合函数)
聚合查询是指使用聚合函数,像计算avg()、sum()、min()、sum()等等这些对数据进行分组统计的查询。聚合函数一般与group by一起使用!
count
select count(*) from employee;
select count(ename) from employee;
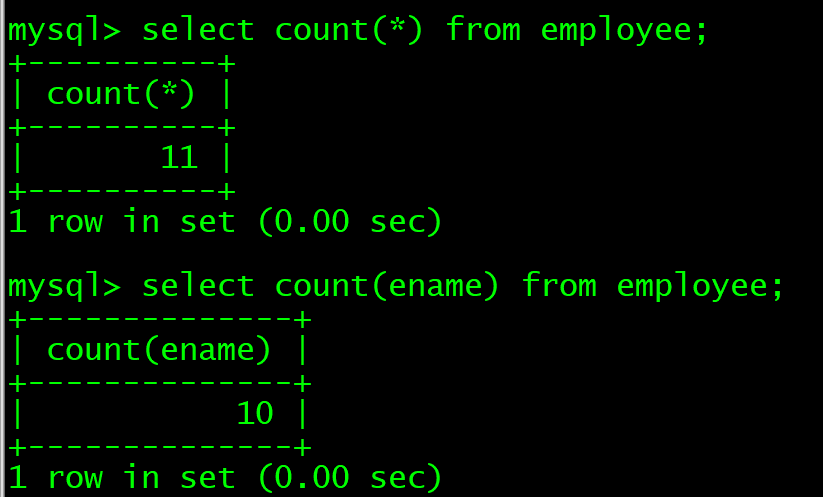
可能有人会疑问为什么ename会是10,因为我们之前还创造了一列ename为空值的员工,具体看数据插入的补充部分
计算总值和平均值
在此之前先把第十一行删了吧
DELETE FROM employee WHERE enumber = 1111;删完之后,我们来执行计算总值和平均值的sql语句
sum() 计算总和
select sum(salary) from employee;
avg() 计算平均值
select avg(salary) from employee;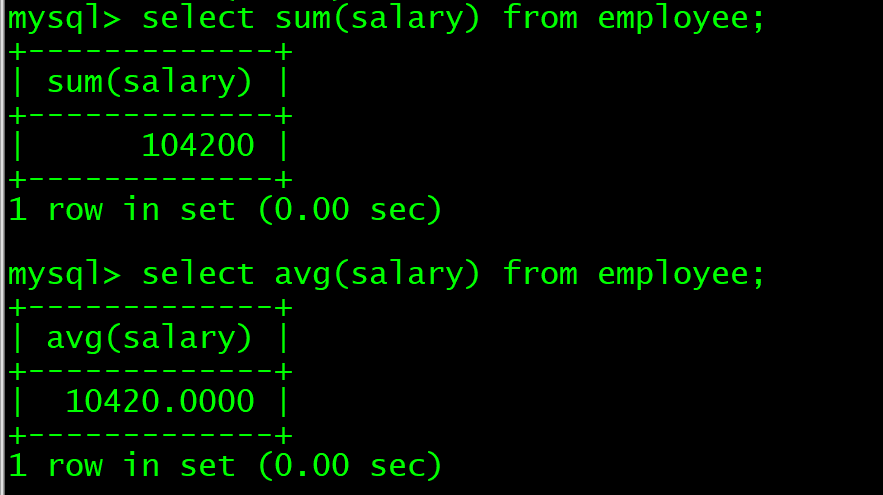
OK,非常完美,接下来是
查询数据的最大值与最小值
max() 查询最大值
select max(salary) as highest_salary from employee;
select * from employee where salary= (select max(salary) from employee);
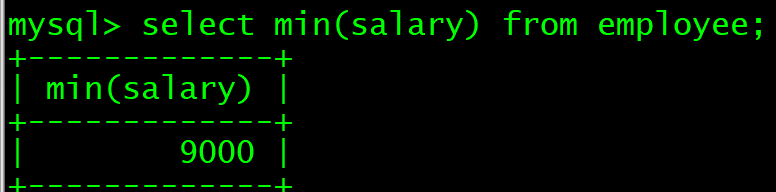
min() 查询最低值
select min(salary) as lowest_salary from employee;
select * from employee where salary= (select min(salary) from employee);第一种查询方式:

第二种查询

我们还是来讲解下第二种查询吧,第二种查询运用到了子查询,子查询仅返回单个值(一行或一列),这里子查询将(select min(salary) from employee)括号里的结果返回给where的过滤条件,如果单用子查询,只会有这个值,跟第一种一样,但是第一种用了as起了个别名。
concat连接
select concat(ename,' 是 ',job) as 员工 from employee;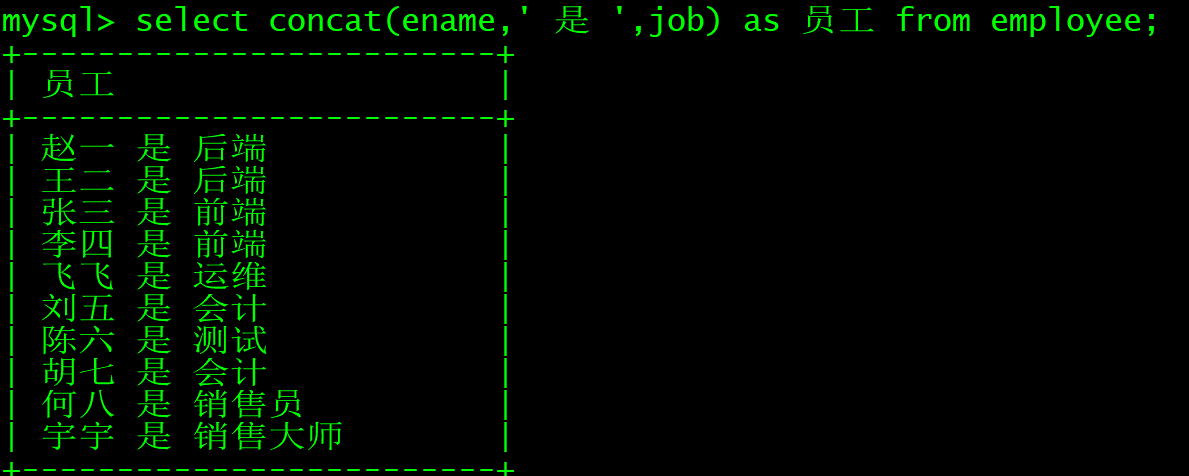
concat会将两列连接起来那么如果不用as会怎样呢

这样一看很不美观,所以concat还是与as一起用
数据查询之分组查询(group by)
作用:把行 按 字段 分组
语法:group by 列1,列2....列N
适用场合:常用于统计场合,一般和聚合函数连用
select dnumber from employee group by dnumber;
select dnumber,count(*) from employee group by dnumber;
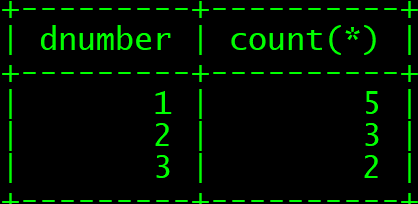
可以看到count(*)还将对应的数量显示出来的。还有group by的字句和select的字句必须一致!
select dnumber,job count(*) from employee group by dnumber,job;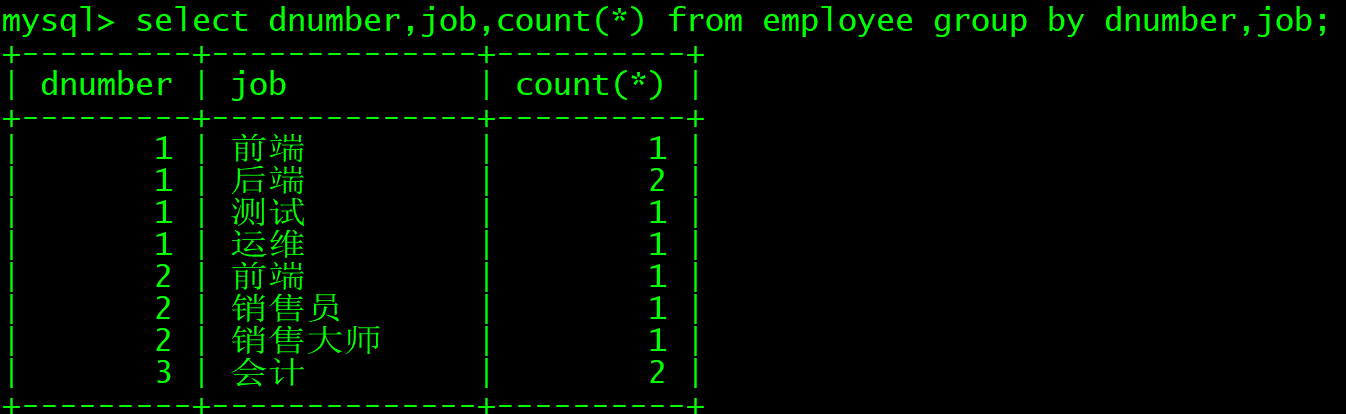
如果不一致就会报错

数据查询之having条件筛选查询
作用:对查询的结果进行筛选操作
语法:having 条件 或者 having 聚合函数 条件
适用场合:一般跟在group by之后
having子句只能引用:
分组字段
聚合函数
不能直接引用未分组的列
select job,count(*) from employee group by job having job ='后端';
select dnumber,job,count(*) from employee group by dnumber,job having count(*)>=2;
select dnumber,job,count(*) as 总数 from employee group by dnumber,job having 总数>=2;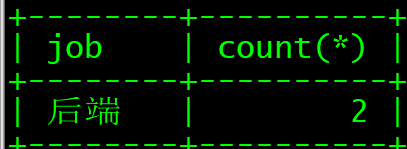


数据查询之order by排序查询
作用:对查询的结果进行排序操作
语法:order by 字段1,字段2 .....
适用场合:一般用在查询结果的排序
select * from employee order by salary;

当然,排序查询也支持布尔值、字符类型、时间类型的数据进行排序
排序查询也是支持升序降序的,升序asc,不写时默认为asc,降序desc
降序
select dnumber,job,count(*) as 总数 from employee group by dnumber,job having 总数>=2
order by dnumber desc;
升序
select dnumber,job,count(*) as 总数 from employee group by dnumber,job having 总数>=2
order by dnumber asc;


还有查询的顺序是:where ---- group by ----- having ------ order by
数据查询之limit限制查询
作用:对查询结果起到限制条数的作用
语法:limit n,m n:代表起始条数值,不写默认为0;m代表:取出的条数
适用场合:数据量过多时,可以起到限制作用
在之前的练习中,因为我们所创建的表比较小,所以可以用*,如果表的数据一旦多起来,用了*之后对性能的影响可想而知(好奇的可以去MySql自带表里select *一下,不过最好别)
select * from employee limit 5;
--limit(0,5)
select * from employee limit 5,5;第一个语句是取employee表中的前五行

第二个语句是从第四行开始,取五行,不包括第五行

数据查询之exits型子查询
exists型子查询后面是一个受限的select查询语句
exists子查询,如果exists后的内层查询能查出数据,则返回 TRUE 表示存在;为空则返回 FLASE则不存在。
分为exist和not exists两种类型
select * from department a
where exists (select 1 from employee b where a.dnumber=b.dnumber);
select * from department a
where not exists (select 1 from employee b where a.dnumber=b.dnumber);
先来看下两个语句的结果吧
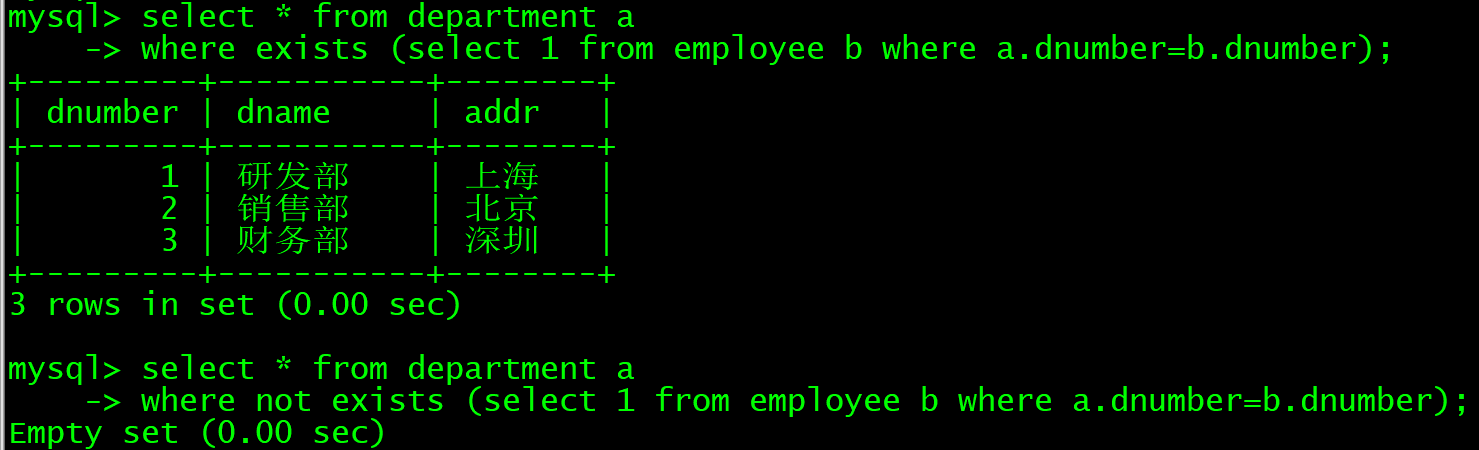
第一个语句的意思是使用exist子查询来检索在employee表中至少有一名员工的部门记录。
在department和employee中,主查询为select * from department a ,以a为department表的别名
子查询则为括号里的,以b为employee表的别名,它的作用是查看是否存在部门编号(dnumber)与department表中当前记录相同的员工。
至于select 1 ,在 SQL 查询中,子查询里的select 1 是一种常用的写法,这里的1并没有特殊的含义,你也可以把它替换成*或者其他常量,比如2、'x'等。其核心作用是检查子查询是否能返回结果集,而不是关注返回的具体内容。
exists操作符只在乎子查询是否有返回行,一旦子查询能返回至少一行数据,exists就会返回true;要是子查询没有返回任何行,则返回false。
select 1比select *更高效,这只是子查询的一个简化
数据查询之左连接查询和右连接查询、
左连接称之为左外连接 右连接称之为右外连接 这俩个连接都是属于外连接
左连接关键字:left join 表名 on 条件 / left outer 表名 join on 条件
右连接关键字:right join 表名 on 条件/ right outer 表名 join on 条件
左连接说明: left join 是left outer join的简写,左(外)连接,左表(a_table)的记录将会全部表示出来, 而右表 (b_table)只会显示符合搜索条件的记录。右表记录不足的地方均为NULL。
右连接说明:right join是right outer join的简写,与左(外)连接相反,右(外)连接,左表(a_table)只会显示符合 搜索条件的记录,而右表(b_table)的记录将会全部表示出来。左表记录不足的地方均为NULL。
左连接查询
select a.addr,b.* from department a left join employee b on a.dnumber=b.dnumber;
以department为主表
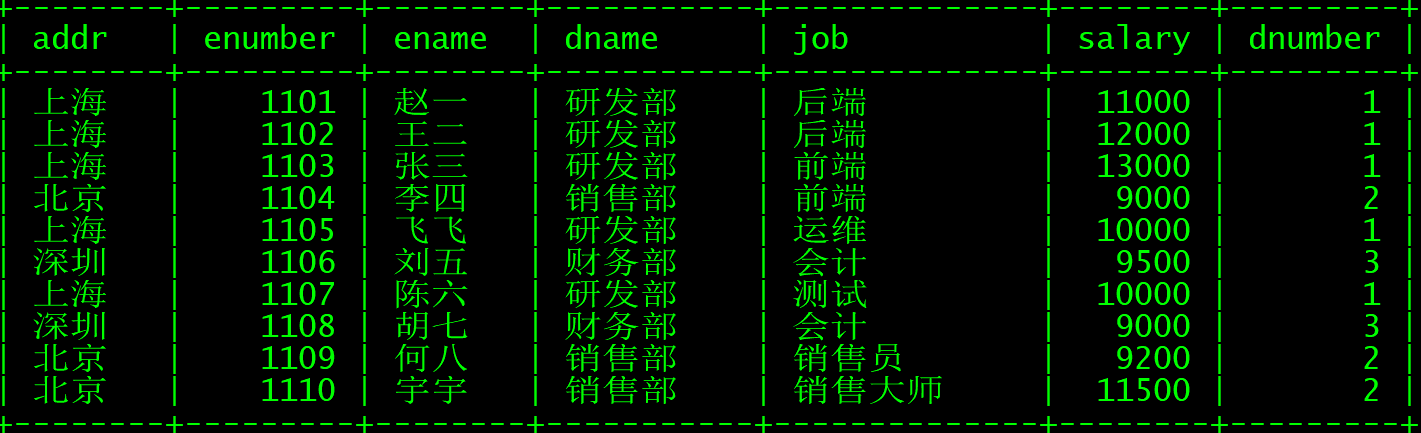
右连接查询,以右表为主表
select a.*,b.ename from department a right join employee b on a.dnumber=b.dnumber;
数据查询之内连接查询
内连接查询的语法与左右连接查询相似
内连接:获取两个表中字段匹配关系的记录
主要语法:INNER JOIN 表名 ON 条件;
内连接只保留两边都匹配的记录
比如我们想查出飞飞所在部门的地址
select a.addr from department a inner join employee b
on a.dnumber=b.dnumber and b.ename='飞飞';
也可以这样写,结果是一样的
select a.addr from department a,employee b
where a.dnumber=b.dnumber and b.ename ='飞飞';数据查询之联合查询
联合查询:就是把多个查询语句的查询结果结合在一起 主
要语法1:... UNION ... (去除重复)
主要语法2:... UNION ALL ...(不去重复)
union查询的注意事项
(1)两个select语句的查询结果的“字段数”必须一致;(类似于聚合查询)
select ename,dname,dnumber from employee
union
select dname,dnumber from department;
ERROR 1222 (21000): The used SELECT statements have a different number of columns可以看到,如果不一致就会报错
(2)通常,也应该让两个查询语句的字段类型具有一致性;
也就是VARCHAR 和INT这种,如果不一致的话,我们来举个例子,将上述的语句,第二个select语句以null来填充
select ename,dname,dnumber from employee
union
select dname,dnumber,null as dnumber from department;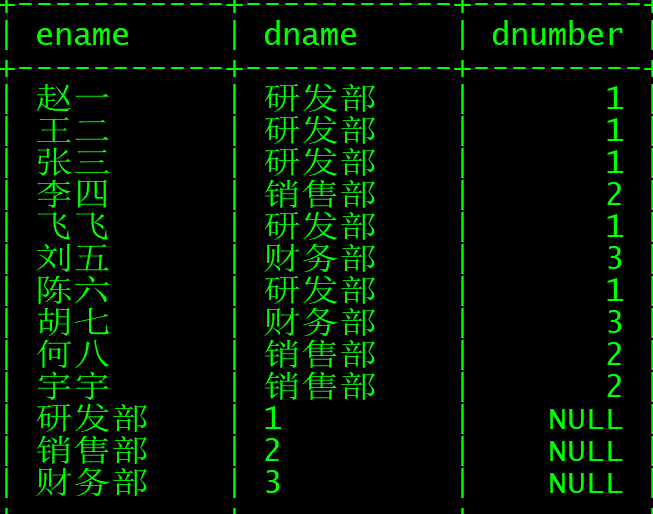
可以看到,类型不一致的话会非常的不美观
(3)也可以联合更多的查询结果,也就是两个三个
(4)用到order by排序时,需要加上limit(加上最大条数就行),需要对子句用括号括起来,现在我们要对员工的工资进行排序
对后端员工工资升序排序,对前端员工工资降序排序,对会计工资升序
(select * from employee a where a.job = '后端' order by a.salary limit 999999 )
union
(select * from employee b where b.job = '前端' order by b.salary desc limit 999999)
union
(select * from employee c where c.job = '会计' order by c.salary asc limit 999999);

这里有人可能会疑问为什么要加limit,这是因为,三个字句都被union联合起来了,MySQL 认为,union的结果是一个集合,理论上集合是无序的。因此,子查询中的order by通常会被优化器忽略,除非明确指定limit,如果不加limit,结果就会是
(select * from employee a where a.job = '后端' order by a.salary )
union
(select * from employee b where b.job = '前端' order by b.salary desc )
union
(select * from employee c where c.job = '会计' order by c.salary asc );
可以看到,会计的工资不再是升序而变成降序,因为这里行数太少,不能更好的体现,但是记住,如果不用limit,union所联合的字句将不会是按照order by排序好的结果输出,而是无序!
union all查询
union all查询是不会去重的,我们可以简单的举几个例子
select ename, job, salary from employee where job = '后端'
union
select ename, job, salary from employee where ename = '赵一';
select ename, job, salary from employee where job = '后端'
union all
select ename, job, salary from employee where ename = '赵一';
可以看到是有差别的
在union中,第一个字句会显示工作是后端人员的列,第二个字句会显示名字叫赵一的列,但是union会自动去重,所以就展示了两列,而union all是不会自动去重的,所以会展示三列,也就是说union all会自动合并
在数据量大的时候使用union,对性能会有很大影响!
总练习
在复习完所有的知识后,来个总练习吧,补充一下,查询出来的信息表,主要由select和from中间的语句来决定
1.列出所有部门的部门编号,部门名称,部门地址,部门人数
select a.*,b.sum from
department a,(select dnumber,count(*) as sum from employee group by dnumber) b
where a.dnumber=b.dnumber;
部门表(department)为a表,至于b表则是括号里的子查询
select dnumber,count(*) as sum from employee group by dnumber这里表示以部门编号为主,对部门里的人数进行排序,b表就是排序好的部门人数表
2.列出工资比飞飞高的员工
select ename from employee
where salary > (select salary from employee where ename = '飞飞'); 这个比较简单
这个比较简单
3.列出部门名称和部门里员工的信息
select a.dname,b.ename,b.enumber,b.job from department a,employee b
where a.dnumber=b.dnumber;
4.列出所有后端人员的姓名及其部门名称,所在部门总人数
这个可能有点复杂
select a.ename,b.dname,c.sum
from employee a,department b,
(select dnumber,count(*) as sum from employee group by dnumber)c
where a.job='后端' and a.dnumber=b.dnumber and a.dnumber=c.dnumber;
这是三个表的连接条件
a.dnumber=b.number关联员工表和部门表,确保员工所属部门正确。
a.dnumber=c.number关联员工表和子查询结果,获取员工所在部门的总人数。
5.列出最低薪金大于10000的各种工作及从事此工作的员工人数。
select job,count(*) from employee group by job having min(salary) > 10000;这里还要记住group by的字句和select的字句必须一致!
还有这样一种情况

那么为什么会报错呢?这是因为在having子句中引用了 salary 列,但该列并未包含在group by或聚合函数中。MySQL 不允许直接在having中引用未分组的列。
6.列出与张三从事相同工作的所有员工及其部门名称
两种都是一样的
select a.ename,b.dname from employee a,
department b where a.dnumber=b.dnumber
and a.job=(select job from employee where ename='张三');select a.ename,b.dname from employee a
join department b on a.dnumber=b.dnumber
where a.job=(select job from employee where ename='张三');
复习完毕!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









