







学习目标:
hadoop:包含分布式文件系统和分布式计算的一个框架。 HDFS,mapreduce
-
掌握HDFS的架构:三种节点:NN,SNN,DN。每个节点的主要作用。
- 不可替代
- 存放海量的数据。
- 数据 --》----》文件—》存放HDFS—》数据文件(元数据,内容数据)—》元数据在NN,内容数据形成block在DN。
- 非常兼容各种分布式计算
节点的作业:
NN: 1、接受客户端的读写请求。2、存储和管理HDFS的元数据
SNN: 合并元数据文件(edits 和 fsimage)(这个功能也可以由其他节点来完成)
DN :1、存放和管理block(数据),2、往NN汇报block
元数据:除文件内容之外的。包括文件的名字、时间、所属用户、权限、大小等等,包括block的位置信息。
-
block(数据块):一个块的最大存储为128M ,数据文件切割之后形成一个一个的数据块。 每个块默认有3个副本。
-
读写流程:重点
-
伪分布式环境部署
1 Hadoop 核心组件
1 hadoop通用组件 - Hadoop Common
包含了其他hadoop模块要用到的库文件和工具
2 分布式文件系统 - Hadoop Distributed File System (HDFS)
运行于通用硬件上的分布式文件系统,高吞吐,高可靠
3 资源管理组件 - Hadoop YARN
于2012年引入的组件,用于管理集群中的计算资源并在这些资源上调度用户应用。
4 分布式计算框架 - Hadoop MapReduce
用于处理超大数据集计算的MapReduce编程模型的实现。
2 HDFS
hdfs架构图
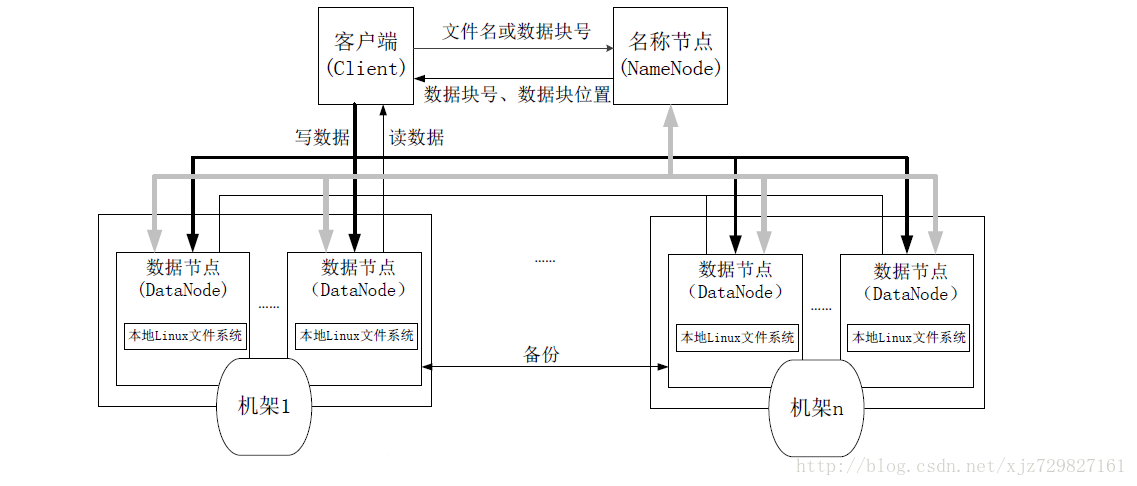
图片来自https://blog.csdn.net/weixin_38750084/article/details/82963235
NameNode管理文件系统的命名空间:
1、文件和目录的元数据(描述数据的数据):存在内存
文件的block副本个数
修改和访问的时间
访问权限
block大小以及组成文件的block信息

2、以两种方式在NameNode本地进行持久化:
命名空间镜像文件(fsimage)和编辑日志(edits log)。
3、fsimage文件不记录每个block所在的DataNode信息,这些信息在每次系统启动的时候从 DataNode重建。之后DataNode会周期性地通过心跳包向NameNode报告block信息。
DataNode向NameNode注册的时候NameNode请求DataNode发送block列表信息。
NameNode的目录结构 ${dfs.namenode.name.dir为属性名}

in_use.lock文件用于NameNode锁定存储目录。这样就防止其他同时运行的NameNode实例使用相同的存储目录。
edits表示edits log日志文件
fsimage表示文件系统元数据镜像文件
NameNode在checkpoint之前首先要切换新的edits log文件,在切换时更新seen_txid的值。
version为属性文件 包含以下内容
namespaceID是该文件系统的唯一标志符,当NameNode第一次格式化的时候生成。
clusterID是HDFS集群使用的一个唯一标志符,在HDFS联邦的情况下,就看出它的作用了,因为联邦情况下,集群有多个命名空间,不同的命名空间由不同的NameNode管理。
blockpoolID是池的唯一标志符,一个管理一个命名空间,该命名空间中的所有文件存储的都在池中。

本图片来源于:https://blog.csdn.net/csao204282/article/details/54634568
seen_txid为当前滚动序号,代表seen_txid之前的日志都已经合并完成。
每个fsimage文件都是系统元数据的一个完整的持久化检查点(checkpoint)(后缀表示镜像中的最后一个事务)

对于创建检查点(checkpoint)的过程,有三个参数进行配置:
1、默认情况下,SecondaryNameNode每个小时进行一次checkpoint合并
由dfs.namenode.checkpoint.period设置,单位秒
2、在不足一小时的情况下,如果edits log存储的事务达到了1000000个也进行一次checkpoint合并
由dfs.namenode.checkpoint.txns设置事务数量
3、事务数量检查默认每分钟进行一次
由dfs.namenode.checkpoint.check.period设置,单位秒。
DataNode
目录结构

文件切
文件线性切割成块(Block)
2、Block分散存储在集群节点中
3、单一文件Block大小一致,文件与文件可以不一致
4、Block可以设置副本数,副本分散在不同节点中
a) 副本数不要超过节点数量
b) 承担计算
5、文件上传可以设置Block大小和副本数
6、已上传的文件Block副本数可以调整,大小不变
7、只支持一次写入多次读取,同一时刻只有一个写入者
8、可以append追加数据
Block块 存放策略(依据机架感知)
第一个副本:放置在上传文件的DN;如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点。
第二个副本:放置在于第一个副本不同的 机架的节点上。
第三个副本:与第二个副本相同机架的节点。
更多副本:随机节点
hadoop安全模式
1 启动NameNode,NameNode加载fsimage到内存,对内存数据执行edits
log日志中的事务操作。
2 文件系统元数据内存镜像加载完毕,进行fsimage和edits
log日志的合并,并创建新的fsimage文件和一个空的edits
log日志文件
3NameNode等待DataNode上传block列表信息,直到副本数满足最小副本条件
4 当满足了最小副本条件,再过30秒,NameNode就会退出安全模式。最小副本条件指整个文件系统中有99.9%的block达到了最小副本数(默认值是1,可设置)
安全模式下行为
a、对文件系统元数据进行只读操作
b、当文件的所有block信息具备的情况下,对文件进行只读操作
c、不允许进行文件修改(写,删除或重命名文件)
HDFS写流程

伪分布式搭建
Linux下安装 hadoop伪分布式
1、搭建虚拟机4台,今天用一台
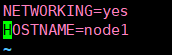
修改名称
vim /etc/sysconfig/network
为node1
2、网络配置好,关闭iptables防火墙,关闭selinux
service iptables stop
3、jdk1.7.0_80 (jdk1.8也是可以的)
hadoop-2.6.5.tar.gz
上传这两个包
4、安装jdk
rpm -ivh jdk-7u80-linux-x64.rpm
5、编辑vi /etc/profile(加入Java的环境变量)
添加两行记录:
export JAVA_HOME=/usr/java/jdk1.8.0_171-amd64/bin/
export PATH=
P
A
T
H
:
PATH:
PATH:JAVA_HOME/bin
执行 . /etc/profile让配置生效(一定要source 一下)
6、解压hadoop-2.6.5.tar.gz到/opt目录
tar -zxf hadoop-2.6.5.tar.gz -C /opt
7、向/etc/profile添加两行(加入hadoop的环境变量)
export HADOOP_PREFIX=/opt/hadoop-2.6.5
export PATH=
P
A
T
H
:
PATH:
PATH:HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin
执行. /etc/profile让配置生效
8、配置免秘钥登录
ssh-keygen -t dsa -P ‘’ -f ~/.ssh/id_dsa
注意是 ‘’ 如果复制该命令的话可能有问题哦,修改一下这个部分或者把-P的参数去掉 让passphrase为empty,就是在交互中回车两次就行(无奈,输入的东西到这个页面总是变形…)


-P passphrase
Provides the (old) passphrase.
-t type
Specifies the type of key to create. The possible values are “rsa1” for proto-
col version 1 and “dsa”, “ecdsa” or “rsa” for protocol version 2.
-f filename
Specifies the filename of the key file.
cat ~/.ssh/id_dsa.pub > ~/.ssh/authorized_keys
$HOME/.ssh/authorized_keys
存放 RSA/DSA 公钥, 用户通过它登录机器. sshd(8) 手册页描述了这个文件的格式. 最
简单的文件格式和 .pub 身份文件一样. 文件内容并非高度敏感, 但是仍然建议仅让此文
件的用户读写, 而拒绝其他用户的访问.
9、修改/opt/hadoop-2.6.5/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_80
export JAVA_HOME=/usr/java/jdk1.8.0_171-amd64
注释掉之前的javahome:

10、修改/opt/hadoop-2.6.5/etc/hadoop/slaves
输入:node1
设置datanode进程所在的主机
11、配置core-site.xml
fs.defaultFS
hdfs://node1:9000
hadoop.tmp.dir
/var/bjsxt/hadoop/pseudo
12、配置hdfs-site.xml
dfs.replication
1
dfs.namenode.secondary.http-address
node1:50090
13、格式化HDFS
hdfs namenode -format
14、启动HDFS
start-dfs.sh

http://node1:50070 也可以访问ip地址

15、上传文件
创建hello.txt
hdfs dfs -D dfs.replication=1 -D dfs.blocksize=1048576 -put hello.txt /

16、停止hdfs
stop-dfs.sh
17 安装ntp
yum -y install ntp
ntp更换 ntp服务器
ntpdate -u 210.72.145.44 :网络时间同步命令
注意:若不加上-u参数, 会出现以下提示:no server suitable for synchronization found
-u:从man ntpdate中可以看出-u参数可以越过防火墙与主机同步;``210.72.145.44:中国国家授时中心的官方服务器。
机架感知:HDFS采用一种称为机架感知(rack-aware)的策略来改进数据的可靠性、可用性和网络带宽的利用率。大型HDFS实例一般运行在跨越多个机架的计算机组成的集群上,不同机架上的两台机器之间的通讯需要经过交换机。在大多数情况下,同一个机架内的两台机器间的带宽会比不同机架的两台机器间的带宽大。通过一个机架感知的过程,Namenode可以确定每个Datanode所属的机架id。一个简单但没有优化的策略就是将副本存放在不同的机架上。这样可以有效防止当整个机架失效时数据的丢失,并且允许读数据的时候充分利用多个机架的带宽。这种策略设置可以将副本均匀分布在集群中,有利于当组件失效情况下的负载均衡。但是,因为这种策略的一个写操作需要传输数据块到多个机架,这增加了写的代价。在大多数情况下,副本系数是3,HDFS的存放策略是将一个副本存放在本地机架的节点上,一个副本放在同一机架的另一个节点上,最后一个副本放在不同机架的节点上。这种策略减少了机架间的数据传输,这就提高了写操作的效率。机架的错误远远比节点的错误少,所以这个策略不会影响到数据的可靠性和可用性。于此同时,因为数据块只放在两个(不是三个)不同的机架上,所以此策略减少了读取数据时需要的网络传输总带宽。在这种策略下,副本并不是均匀分布在不同的机架上。三分之一的副本在一个节点上,三分之二的副本在一个机架上,其他副本均匀分布在剩下的机架中,这一策略在不损害数据可靠性和读取性能的情况下改进了写的性能。
作者:csao204282
来源:CSDN
原文:https://blog.csdn.net/csao204282/article/details/54634568
EC数据存储方式:
HDFS存储数据的最小物理单元是block,默认的block size是128M。传统的顺序存储方式是:将文件顺序写入多个block中。
例如,一个768M的文件,将被顺序写入6个128M的block中,然后每个block再被异步复制2个副本到其它DataNode中:
顺序存储
EC采用叫做文件存储的最小物理单元依然是block,但是在block基础上增加了strip和cell的逻辑单元,其中cell就是RS码中的"单元"。6个数据单元(也就是6个cell)+3个校验单元构成一个条(strip)。
例如,同样一个768M的文件将被分为768个1M大小的逻辑单元cell,每6个cell做RS encoding,生成3个校验cell,这样9个cell构成一个逻辑条(strip),然后依次循环将这些条写入到block中。
参考来源:简书
https://www.jianshu.com/p/efa6cf8bf678















 2654
2654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









