









detach
官网解释:

实验结论

import torch
x = torch.arange(4.0)
x.requires_grad_(True) # 等价于 `x = torch.arange(4.0, requires_grad=True)`
y = x * x
# detach作用是:将u作为常数处理。即将y.detach的返回值作为常数而不再是关于x的函数
u = y.detach()
z = u * x
z.sum().backward() # 为啥不直接求导原因是在机器学习或深度学习中一般不用向量(矩阵)求导,
# 而是用标量求导,所以就先求和在求导
# backward 是计算梯度并存入x.grad中
print(x.grad == u)
x.grad中保存的是求导结果
输出结果:
tensor([True, True, True, True])
numel的用法

retain_graph
每次 backward() 时,默认会把整个计算图free掉。一般情况下是每次迭代,只需一次 forward() 和一次 backward() ,前向运算forward() 和反向传播backward()是成对存在的,一般一次backward()也是够用的,但是不排除,由于自定义loss等的复杂性,需要一次forward(),多个不同loss的backward()来累积同一个网络的grad,来更新参数。于是,若在当前backward()后,不执行forward() 而是执行另一个backward(),需要在当前backward()时,指定保留计算图,backward(retain_graph=true)
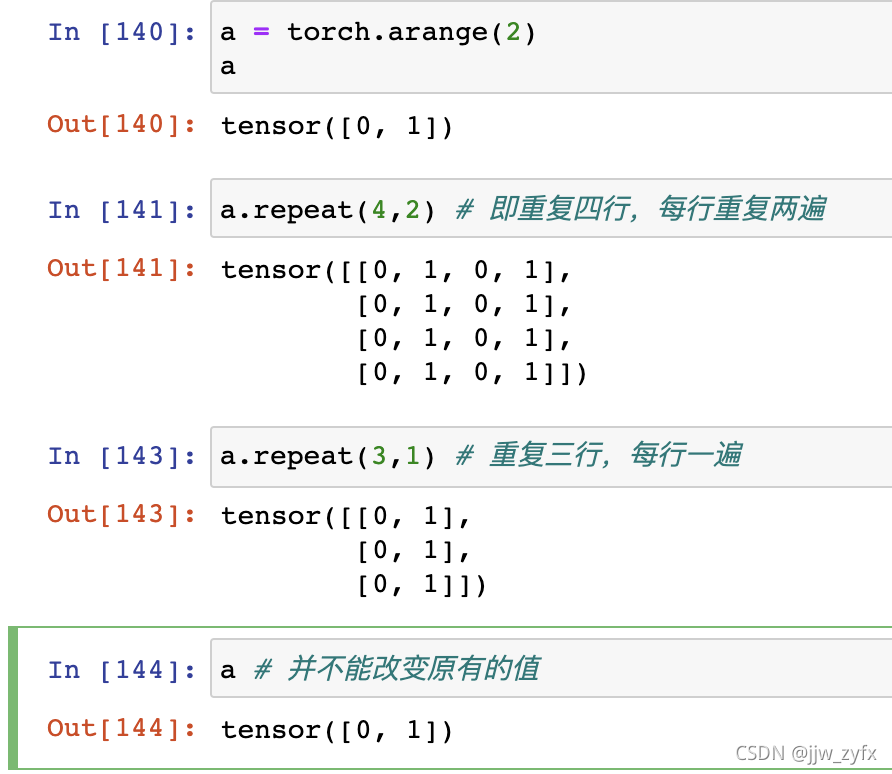
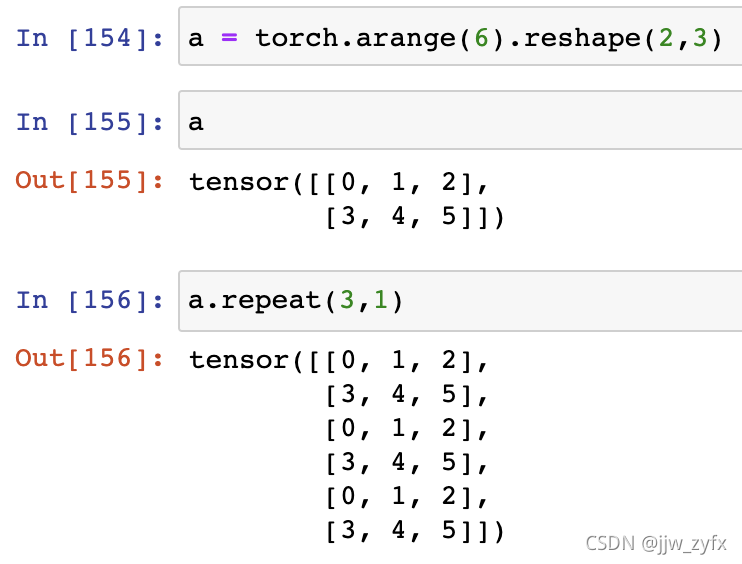
repeat
repeat_interleave



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









