







点击查看代码
点击下载论文
摘要
自从视觉Transformers(ViT)最近取得成功以来,对ViT风格架构的探索引发了ConvNets的复兴。在这项工作中,我们从一个新的多阶博弈论交互的角度探索了现代ConvNets的表示能力,该视角基于博弈论反映了不同尺度的上下文中变量间的交互效应。在现代ConvNet框架内,我们使用概念上简单但有效的深度卷积来定制两个特征混合器,以分别促进空间和信道空间中的中阶信息。有鉴于此,提出了一种新的纯ConvNet体系结构家族,称为MogaNet,该体系结构显示出优异的可扩展性,并通过更有效地使用ImageNet上的参数和各种典型的视觉基准(包括在COCO上的目标检测、ADE20K语义分割、2D和3D人体姿态估计以及视频预测),在sota模型之间取得了有竞争力的结果。通常,MogaNet在ImageNet上使用5.2M和181M个参数,达到80.0%和87.8%的top-1精度,优于ParC-Net-S和ConvNeXt-L,同时节省了59%的FLOP和17M个参数。
引言
自深度神经网络(DNN)[70]复兴以来,卷积神经网络(ConvNets)一直是计算机视觉[53,106,69]的首选方法。通过在池化和非线性操作之间交错分层卷积层[71,149,112,113],ConvNets可以利用内置的平移等变约束[53,159,91,148,60,163]对观测图像的潜在语义模式进行编码,并进一步成为当今计算机视觉系统的基本基础设施。然而,ConvNets学习到的表征已被证明对局部纹理有强烈的偏见[128],导致对全局信息的严重损害[6,56,36]。因此,已经努力去升级宏级架构[21,148,103,163]和上下文聚合模块[29,137,60,139,13]。
相比之下,通过宽松局部感应偏置,新出现的Vision Transformers (ViT)[38,85,135,23]迅速挑战了ConvNets在各种视觉基准上的长期主导地位。几乎一致认为,ViTs的这种优越性主要源于自我注意机制[5,129],无论拓扑距离如何,它都有助于长期的特征交互。然而,从实用的角度来看,自注意建模中的平方复杂性极大地限制了ViTs[134,61,140]的计算效率及其在需要高分辨率特征的细粒度场景[87,65,168]中的应用潜力。此外,归纳偏差的缺乏破坏了图像固有的几何结构,从而不可避免地导致邻域相关性的损害[100]。为了解决这一障碍,以牺牲模型的通用性和表达性为代价,努力将金字塔状分层布局[85,40,135]和移位不变先验[141,30,49,72,19]重新引入到ViT中。
最近的研究表明,ViT的表现能力应主要归功于其宏观层面的架构,而不是通常猜测的自我注意机制[121,104,154]。更重要的是,通过先进的训练设置和ViT风格的架构现代化,ConvNets可以很容易地提供卓越的可扩展性和有竞争力的性能。通过在各种视觉基准[138,86,36,100]上调整好的ViT,这加剧了ConvNets和ViT之间的争论,并进一步改变了深度架构设计的路线图。
与以往的尝试不同,我们通过多阶博弈论交互的视角研究了现代ConvNets的表示能力[1],这为解释基于博弈论的深度架构中编码的特征交互行为和效果提供了一个新的视角。如图3.b所示,大多数现代DNN倾向于编码具有极低或极高复杂性的博弈论交互,而不是最具鉴别力的中间交互[33],这限制了它们对复杂样本的表示能力和鲁棒性。
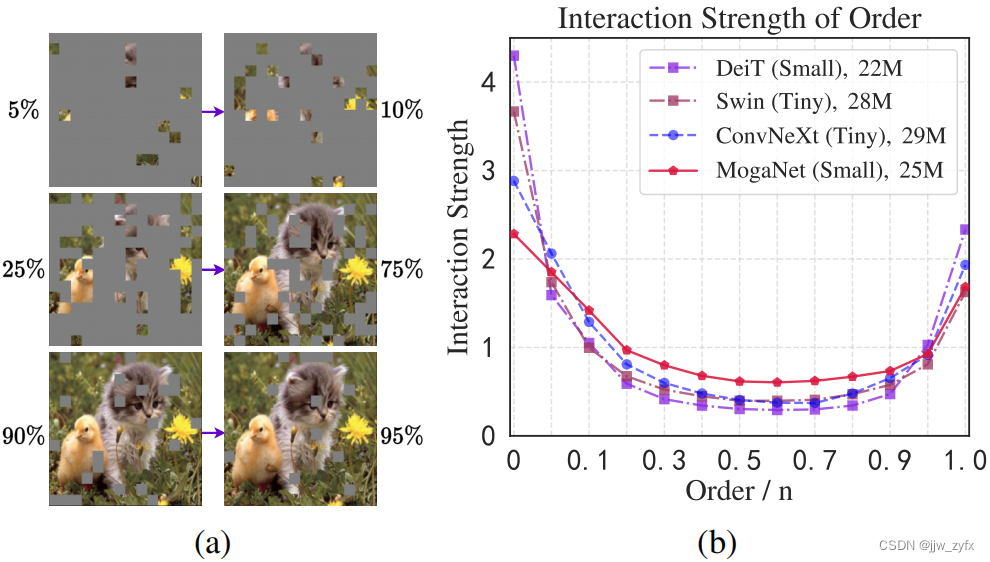
图3 (a)瓶颈表征的说明。人类可以从具有大约50%遮挡的图像中识别物体,而只学习很少的新信息(例如,5~10%),或者发现几乎所有遮挡都过于冗余(例如,90~95%)。DNN倾向于从极少数或最多的补丁中提取最多的信息,但通常在20~80%的补丁中获得的信息较少。 (b)在ImageNet-1K上用分辨率为
22
4
2
224^2
2242,n=14×14绘制了Transformers和ConvNets的相互作用强度
J
(
m
)
J^{(m)}
J(m)的分布。中间阶相互作用是指中间复杂的相互作用,其中有中等数量的补丁(例如0.2~0.8n)参与。
在这种观点下,我们开发了一种新的纯ConvNet架构,称为多阶门控聚合网络(MogaNet),用于平衡多阶交互强度,以提高ConvNet的性能。我们的设计将低阶局部先验和中阶上下文聚合封装到一个统一的空间聚合块中,其中平衡的多阶交互的特征通过并行的门控机制被有效地聚集和上下文化。从通道方面来看,由于现有方法容易出现通道信息冗余[104,61],我们定制了一个概念上简单但高效的通道聚合块,该块对多阶输入执行自适应通道特征重新分配,并以较低的计算成本显著优于主流相关的模型(例如,SE模块[60])。
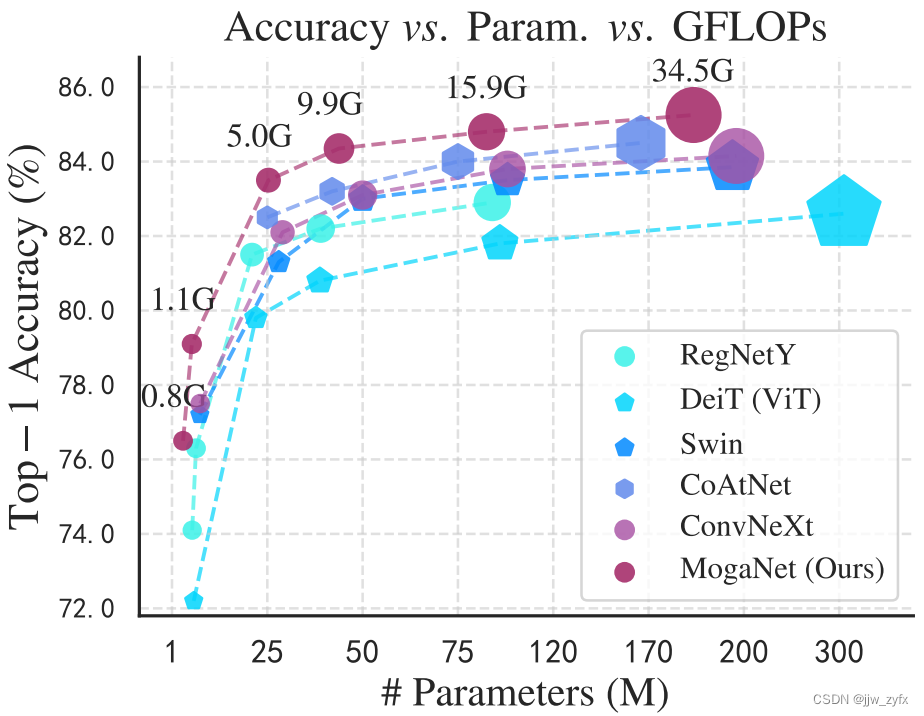
图1 在分辨率为
22
4
2
224^2
2242的情况下,在ImageNet-1K验证集上的性能。具有纯卷积的MogaNet在所有参数尺度上都优于Transformers(DeiT[122]和Swin[85])、ConvNets(RegNetY[103]和ConvNeXt[86])和混合模型(CoAtNet[30])。
大量实验证明了MogaNet在不同模型尺度下对各种计算机视觉任务的出色性能和高效性,包括图像分类、对象检测、语义分割、实例分割、姿态估计等。因此,MogaNet分别在25M和181M参数下达到83.4%和87.8%,与现有的小尺寸模型相比,其表现出良好的计算开销,如图1所示。MogaNet-T在ImageNet-1K上实现了80.0%的top-1精度,在相同设置下比最先进的ParCNet-S[161]高1.0%,FLOP降低2.04G。此外,MogaNet在各种下游任务上表现出强大的性能提升,例如,在COCO检测上以较少的参数和计算预算超过Swin-L[85]2.3%的
A
P
b
AP^b
APb。因此,MogaNet的性能提升并不是因为容量的增加,而是因为更有效地使用了模型参数。
2、相关工作
2.1、Vision Transformers
自从Transformer[129]在自然语言处理(NLP)[35,10]中取得重大成功以来,随后提出了Vision Transformers(ViT)[38],并在ImageNet[34]上获得了有希望的结果。然而,与Con-vNets相比,纯ViT更加参数化,并且依赖于大规模的预训练[38,7,51,75]。 针对这个问题,一个研究分支提出了具有有效注意力变体[134]的轻量级ViTs[147,93,77,18]。同时,将自注意和卷积作为混合主干的结合已被大力研究[47141,30,31,72,96,111],以赋予ViTs区域优先权。通过引入归纳偏见[14168,16,98,65,3]、高级训练策略[122123155125]或额外知识[66,78143],ViT及其变体可以与ConvNets相比实现具有竞争性的性能,并已扩展到各种计算机视觉领域。
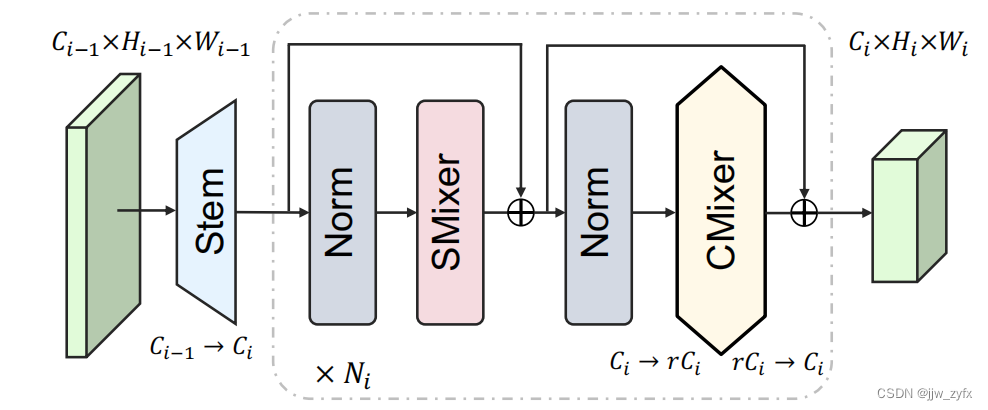
图2 宏架构说明。它在层次上有4个阶段,第i个阶段包含嵌入主干和具有PreNorm[133]和特征连接[53]的SMixer(·)和CMixer(·)的
N
i
N_i
Ni块。第i阶段内的特征具有相同的形状,除了CMixer(·)将让维度增加到具有将拓展比率r作为一个反向瓶颈[107]的
r
C
i
rC_i
rCi。
如图2所示,MetaFormer[154]基本上影响了深度架构设计的原理,其中所有的ViT[1221272130]都可以通过它们如何处理token-混合方法来分类,例如相对位置编码[142]、局部窗口移位[85]和MLP层[121]等。它主要包括三个基本组成部分:(i)嵌入主干,(ii)空间混合块,和(iii)通道混合块。嵌入主干对输入图像进行下采样,以减少图像固有的冗余和计算过载。我们假设输入特征X和输出Z的形状相同RC×H×W,我们得到: Z = S t e m ( X ) , (1) Z = Stem(X), \tag{1} Z=Stem(X),(1)其中Z是下采样的特征,例如: 特征流到残差块的堆栈。在每个阶段,网络模块可以解耦为两个独立的功能组件,SMixer(·)和CMixer(·),用于空间和信道信息传播[154], Y = X + S M i x e r ( N o r m ( X ) ) (2) Y = X + SMixer(Norm(X))\tag{2} Y=X+SMixer(Norm(X))(2) Z = Y + C M i x e r ( N o r m ( Y ) ) (3) Z = Y + CMixer(Norm(Y))\tag{3} Z=Y+CMixer(Norm(Y))(3)其中Norm(·)是一个归一化层,例如,批量 归一化[63](BN)。注意,SMixer(·)可以是各种空间操作(例如,自注意[129],卷积),而CMixer(·)通常通过反向瓶颈[107]中的通道MLP和r的扩展比来实现。
2.2、后ViT模型ConvNets
通过利用ViT风格的宏级架构[154]的优点,现在的ConvNets[127,86,36,82,105,150]在全局上下文聚合中显示了大深度卷积[50]的惊人性能。与ViT类似,现在的ConvNets中的上下文聚合操作可以概括为一组组件,这些组件自适应地强调上下文信息,并减少两个嵌入特征之间空间混合中的琐碎冗余:
O
=
S
(
F
ϕ
(
X
)
,
G
ψ
(
X
)
)
,
(4)
O=S(F_{\phi}(X), G_{\psi}(X)), \tag{4}
O=S(Fϕ(X),Gψ(X)),(4)其中
F
ϕ
(
⋅
)
F_{\phi}(·)
Fϕ(⋅)和
G
ψ
(
⋅
)
G_{\psi}(·)
Gψ(⋅)是分别带有参数
ϕ
和
ψ
\phi和\psi
ϕ和ψ的聚合和上下文分支。上下文聚合通过聚合分支
F
ϕ
(
X
)
F_{\phi}(X)
Fϕ(X)对X上每个位置的重要性进行建模,并通过S(·,·)将上下文分支
G
ψ
(
X
)
G_{\psi}(X)
Gψ(X)的嵌入特征重新加权。
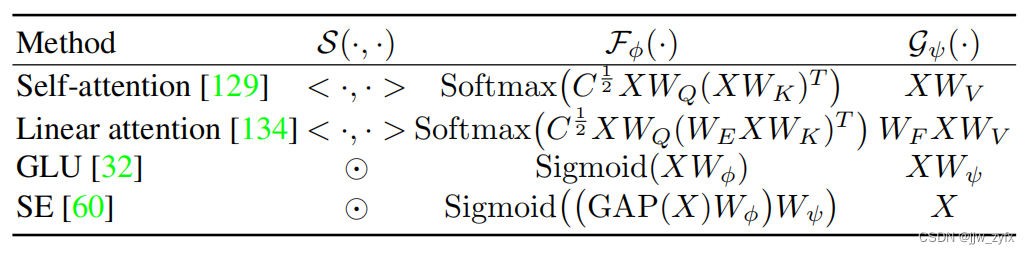
表1 根据等式(4)的上下文聚合方法的示例。自注意和线性注意的唱头版本作为一个例子,W表示线性投影。
如表1所示,现在的ConvNets的上下文聚合主要有两种类型:自注意机制[129,137,38]和门控注意[32,60]。X上每个位置的重要性是通过
F
ϕ
(
⋅
)
F_{\phi}(·)
Fϕ(⋅)中所有其他位置与点积的全局相互作用来计算的,这导致了二次计算的复杂性。为了克服这一限制,提出了线性复杂度[90102]中的注意变体来代替普通的自我注意,例如表1第二行中的线性注意[134195],但它们可能退化为微注意力[140]。与自注意不同,门控单元在线性复杂度中使用元素乘积S(·,·),例如,表1最后两行中的门控线性单元(GLU)变体[109]和压缩-激活(SE)模块[60]。
多阶博弈论交互视角下的表征瓶颈
最近对DNN的鲁棒性[94166,97]和泛化能力[44,2128,43]的分析为改进深度架构提供了一个新的视角。除了这些努力之外,我们还将研究范围扩展到了多阶博弈论相互作用的研究。如图3a所示,在极端遮挡率(例如,只有10~20%的可见块)下,DNN仍然可以识别目标对象,但在中等遮挡下产生的信息增益较小[33,94]。有趣的是,我们的人类大脑从具有大约50%补丁的图像中获得了最敏锐的激增的知识,这表明人类视觉和深度模型之间存在着有趣的认知差距。形式上,它可以用[162,33]中定义的第m阶博弈论相互作用 I ( m ) ( i , j ) I^{(m)}(i,j) I(m)(i,j)和m阶相互作用强度 j ( m ) j^{(m)} j(m)来解释。考虑到总共有n个补丁的图像, I ( m ) ( i , j ) I^{(m)}(i,j) I(m)(i,j)测量了由m个补丁组成的所有上下文中补丁对i,j之间的平均交互复杂度,其中0≤m≤n−2,并且m的阶数反映了像素i和j之间博弈论交互所涉及的上下文的规模,m∈(0,1)的相对相互作用强度 j ( m ) j^{(m)} j(m)测量DNN中编码的相互作用的复杂性。 值得注意的是,低阶相互作用倾向于编码常见或广泛共享的局部纹理,而高阶相互作用则倾向于强制记忆罕见异常值的模式[33,20]。有关定义和详细信息,请参阅附录B.1。如图3b所示,大多数DNN更倾向于编码过低阶或高阶博弈论交互,同时通常支持最灵活和最具鉴别力的中阶交互[33,20]。从我们的角度来看,ConvNets和ViTs中的这种困境可能归因于卷积归纳偏置和上下文聚合的不恰当组成[126,128,33,75]。特别是,自注意或卷积的天真实现可能本质上倾向于全局形状[43,36]或局部纹理[56]的强偏差,从而将虚假的极阶博弈论交互偏好注入深度网络。
4、方法
4.1、总揽MogaNet
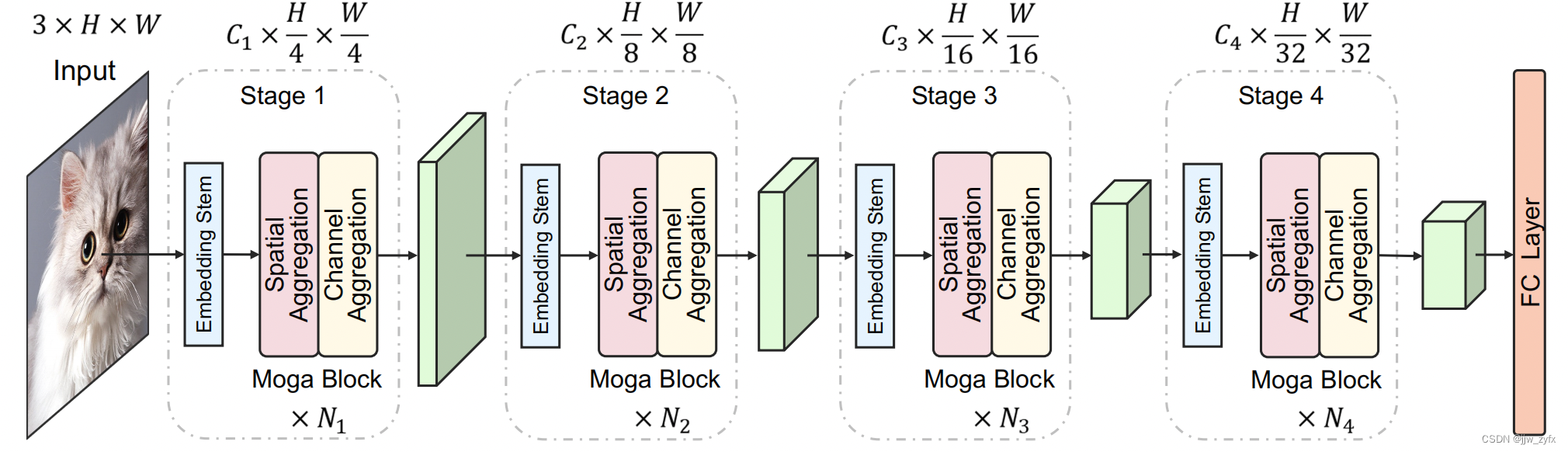
A1 MogaNet架构总揽。与[53,85,154,86]类似,MogaNet使用4个阶段的分层架构。第i阶段由嵌入主干和第
N
i
N_i
Ni的Moga块体组成,其中第
N
i
N_i
Ni的 Moga块体包含空间聚集块和通道聚集块。
基于图2,我们设计了四阶段MogaNet架构,如图A1所示。对于阶段i,输入图像或特征首先被馈送到嵌入主干中,以调节特征分辨率并嵌入到
C
i
C_i
Ci维度中。假设输入图像的分辨率为H×W,则四个阶段的特征的分辨率分别为
H
4
×
W
4
、
H
8
×
W
8
、
H
16
×
W
16
和
H
32
×
W
32
\frac{H}{4}×\frac{W}{4}、\frac{H}{8}×\frac{W}{8}、\frac{H}{16}×\frac{W}{16}和\frac{H}{32}×\frac{W}{32}
4H×4W、8H×8W、16H×16W和32H×32W。然后,嵌入的特征流入由空间和通道聚合块组成的第
N
i
N_i
NiMoga块,如第4.2节和第4.3节所示,用于进一步的上下文提取和聚合。在最终输出之后,为分类任务添加了GAP和线性层。对于密集预测任务[52146],四个阶段的输出可以通过颈部模块[79,69]使用。
4.2、多阶段门控聚合
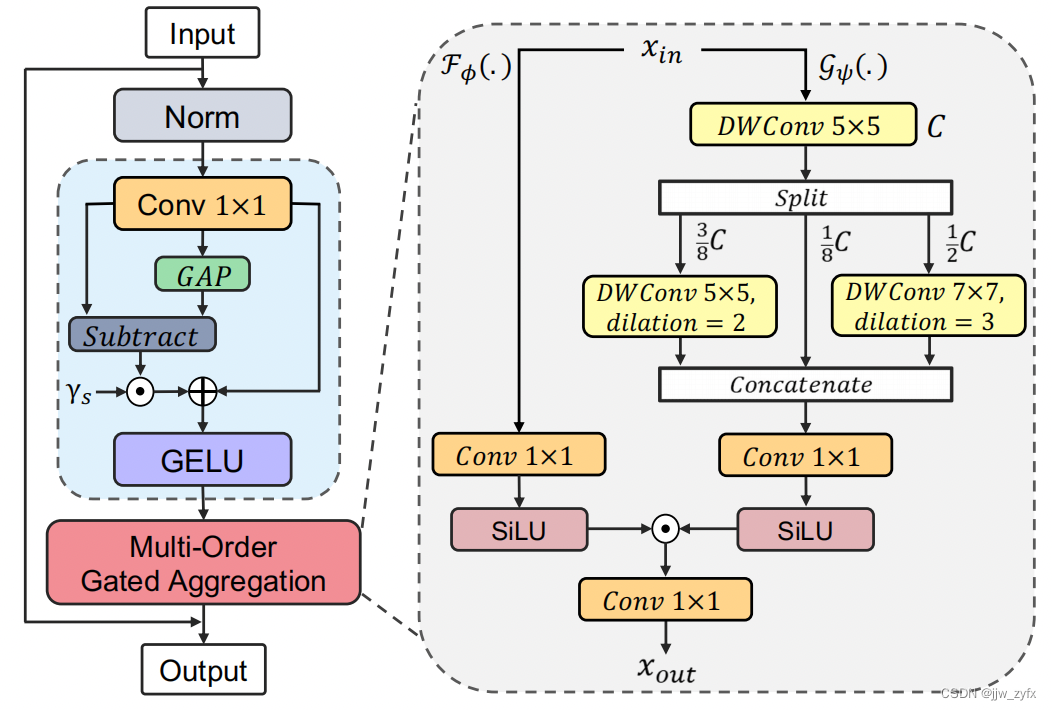
图4 Moga(·)空间聚合块结构

图5 Grad-CAM可视化的消融实验。1:0:0和0:0:1表示对于多阶DWConv层仅使用
C
l
或
C
h
C_l或C_h
Cl或Ch。具有极低(
C
l
C_l
Cl)或高(
C
h
C_h
Ch)阶相互作用的模型对相似的区域纹理(1:0:0)或过度的判别部分(0:0:1)敏感,而不是定位语义部分。门控可以有效地消除干扰上下文的噪声。
正如第三部分讨论的那样。具有不兼容的局部感知和上下文聚合组成的传统DNN倾向于集中于极端阶相互作用,同时抑制最具鉴别性的中间阶相互作用[72100,33]。如图5所示,主要的挑战是如何有效地捕捉具有平衡的多阶博弈论交互的上下文表征。为此,我们提出了一个空间聚合(SA)块作为SMixer(·),在统一设计中聚合多阶上下文,如图4所示,由两个级联组件组成。我们将等式(2)改写为:
Z
=
X
+
M
o
g
a
(
F
D
(
N
o
r
m
(
X
)
)
)
,
(5)
Z = X + Moga(FD(Norm(X))), \tag{5}
Z=X+Moga(FD(Norm(X))),(5)其中FD(·)表示特征分解模块(FD),Moga(·)是包括门控
F
ϕ
(
⋅
)
F_{\phi}(·)
Fϕ(⋅)和上下文分支
G
ψ
(
⋅
)
G_{\psi}(·)
Gψ(⋅)的多级门控聚合模块。
多阶上下文作为一种纯卷积结构,我们提取了具有静态和自适应局部感知的多阶特征。除了m阶相互作用外,还有两个互补的对应物,即普通局部纹理的0阶相互作用和覆盖复杂全局形状的“n阶”相互作用,分别用Conv1×1(·)和GAP(·)建模。为了迫使网络专注于平衡多种复杂性的交互,我们提出FD(·)来动态排除交互中的微小特征,定义为:
Y
=
C
o
n
v
1
×
1
(
X
)
,
(6)
Y = Conv_{1×1}(X), \tag{6}
Y=Conv1×1(X),(6)
Z
=
G
E
L
U
(
Y
+
γ
s
⊙
(
Y
−
G
A
P
(
Y
)
)
)
,
(7)
Z = GELU(Y + \gamma_s\odot (Y − GAP(Y ))), \tag{7}
Z=GELU(Y+γs⊙(Y−GAP(Y))),(7)其中
γ
s
∈
R
C
×
1
\gamma_s \in \Bbb R^{C\times 1}
γs∈RC×1表示为一个初始化为0的缩放因子。通过重新加权互补交互分量Y−GAP(Y),FD(·)也增加了空间特征的多样性[97,123]。然后,我们集成深度卷积(DWConv)来编码Moga(·)上下文分支中的多阶特征。与之前简单地将DWConv与自注意相结合来建模局部和全局相互作用[161,95111105]的工作不同,我们使用三个不同的DWConv层,其膨胀率为d∈{1,2,3},并行地捕获低阶、中阶和高阶相互作用:给定输入特征
X
∈
R
C
×
H
W
,
D
W
5
×
5
,
d
=
1
X\in \Bbb R^{C×HW}, DW_{5×5,d=1}
X∈RC×HW,DW5×5,d=1首先应用低阶特征。然后,输出沿着通道维度被分解为
X
l
∈
R
C
l
×
H
W
,
X
m
∈
R
C
m
×
H
W
,
和
X
h
∈
R
C
h
×
H
W
X_l ∈ \Bbb R^{C_l×HW} , X_m ∈ \Bbb R^{C_m×HW} ,和 X_h ∈ \Bbb R^{C_h×HW}
Xl∈RCl×HW,Xm∈RCm×HW,和Xh∈RCh×HW。其中
C
l
+
C
m
+
C
h
=
C
C_l + C_m + C_h = C
Cl+Cm+Ch=C;然后
X
m
和
X
h
X_m和X_h
Xm和Xh分别被分派给
D
W
5
×
5
,
d
=
2
和
D
W
7
×
7
,
d
=
3
DW_{5×5,d=2}和 DW_{7×7,d=3}
DW5×5,d=2和DW7×7,d=3,同时
X
l
X_l
Xl作为特征映射;最后
X
l
,
X
m
,
和
X
h
X_l, X_m, 和 X_h
Xl,Xm,和Xh是连接起来形成多阶上下文。
Y
C
=
C
o
n
c
a
t
(
Y
l
,
1
:
C
l
,
Y
m
,
Y
h
)
.
Y_C = Concat(Y_{l,1:Cl}, Y_m, Y_h).
YC=Concat(Yl,1:Cl,Ym,Yh).注意:与ConvNeXt[86]中使用的
D
W
7
×
7
DW_{7×7}
DW7×7相比,所提的FD(·)和多阶DWConv层只需要一点额外的计算开销和参数,例如,如表2所示,+多阶和+FD(·)比
D
W
7
×
7
DW_{7×7}
DW7×7.增加了0.04M参数和0.01G FLOPS。
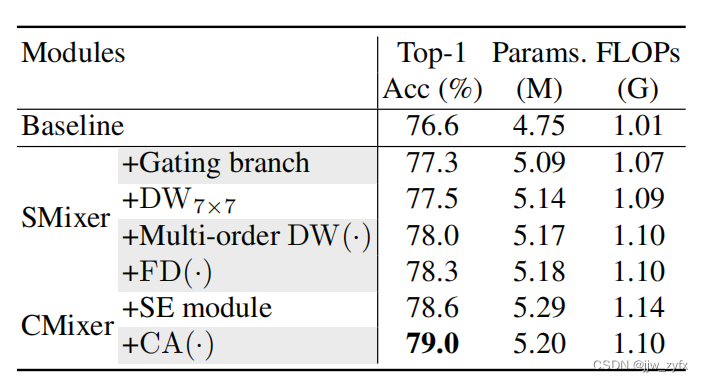
表2 在ImageNet-1K上的设计模块的消融实验。基线使用非线性投影,
D
W
5
×
5
DW_{5×5}
DW5×5作为SMixer(·),普通MLP作为CMixer(·)。与
D
W
7
×
7
DW_{7×7}
DW7×7和SE模块相比,多阶DW(·)+FD(·)作为多阶区域性 感知和CA(·)带来了显著的改进,只需少量的额外成本。
**门控聚合。**为了聚合上下文分支的多阶特征,我们在门控分支中使用SiLU[39]激活,即x·Sigmoid(x),它可以被视为Sigmoid的高级版本。如附录C.1中所验证的,我们发现SiLU既具有Sigmoid的门控效应,又具有稳定的训练特性。以FD(·)的输出作为输入,我们将等式(4)改写为:
Z
=
S
i
L
U
(
C
o
n
v
1
×
1
(
X
)
)
⏟
F
ϕ
⊙
S
i
L
U
(
C
o
n
v
1
×
1
(
Y
C
)
)
⏟
F
ψ
,
(8)
Z = \underbrace{SiLU(Conv_{1×1}(X))}_{F\phi}\odot\underbrace{SiLU(Conv_{1×1}(Y_C))}_{F\psi},\tag{8}
Z=Fϕ
SiLU(Conv1×1(X))⊙Fψ
SiLU(Conv1×1(YC)),(8)通过所提出的SA块,MogaNet捕获了更多的中阶交互,如图3b所示的验证。SA块产生具有与ConvNeXt中的
D
W
7
×
7
DW_{7×7}
DW7×7相似的参数和FLOP的判别性多阶表征,这远远超出了现有方法的范围,而不需要耗费成本的自注意力。
4.3、通过通道聚合实现多阶特征重新分配
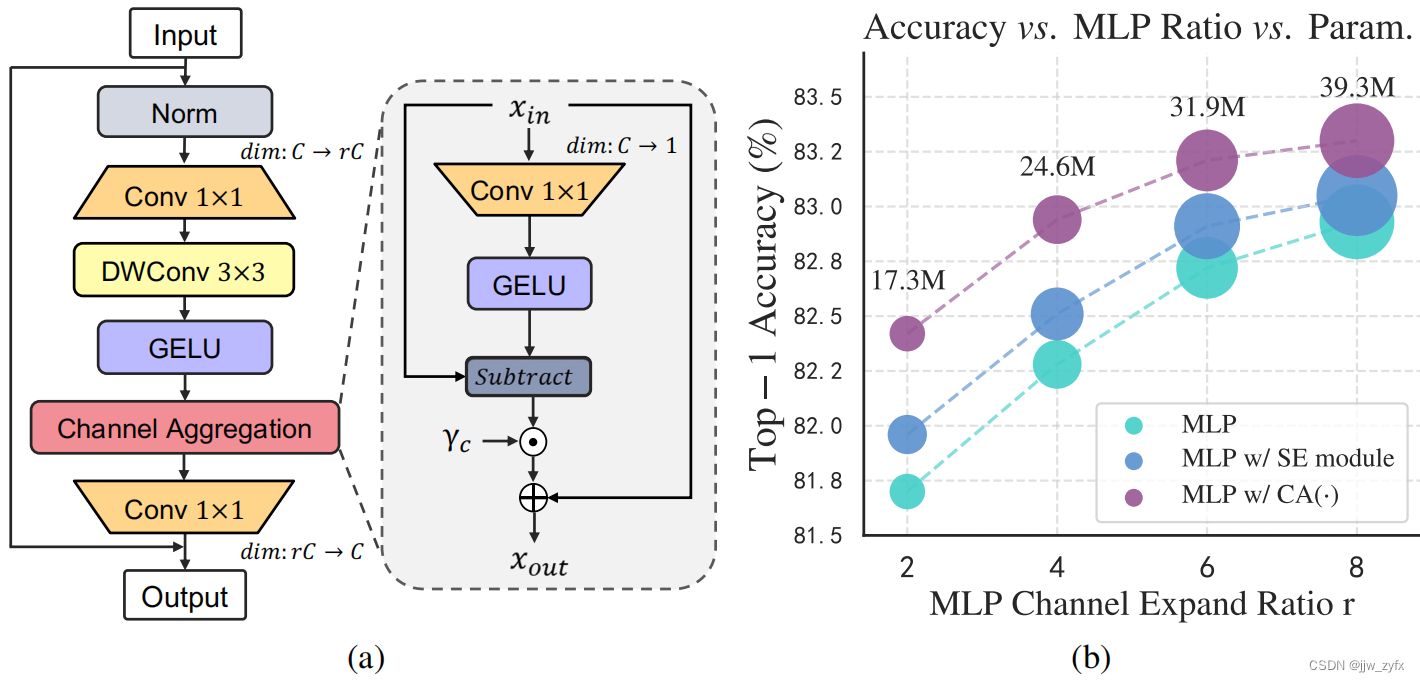
图6 (a)通道聚合块的结构。(b)通道MLP和通道聚合模块的分析。基于MogaNet-S,将原始通道MLP、具有SE块的MLP和通道聚合的性能和模型大小与{2,4,6,8}的MLP比率在ImageNet-1K上进行了比较。
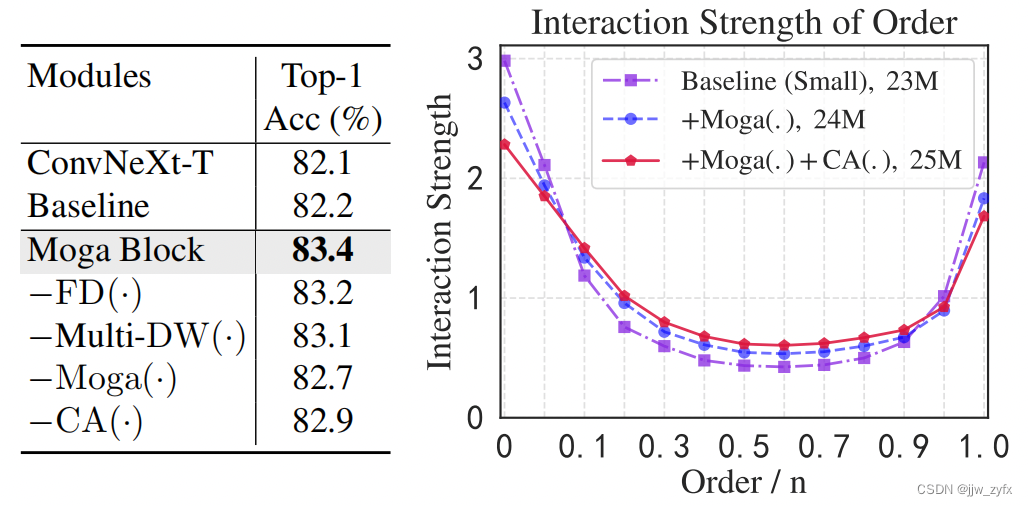
图7 在ImageNet-1K上的设计模型的消融实验。左边:该表通过基于MogaNet-S的基线移除每个模块来消融所提出的模块。右边:该图绘制了交互强度
J
(
m
)
J^{(m)}
J(m)的分布,并验证了Moga(·)对学习多阶交互贡献最大和更好的性能。
如第2节所示,主流架构主要通过两个线性投影执行信道混合CMixer(·),例如,具有信道扩展比r的2层信道MLP[38,85121]或具有介于[136,96,95]之间的3×3 DWConv的MLP。由于固有的冗余交叉信道[139,131119131],普通MLP需要许多参数(r默认为4或8)来实现预期性能,显示出较低的计算效率,如图6b所示。为了解决这个问题,大多数当前的方法直接将信道增强模块(例如SE模块[60])插入MLP中。与这些需要额外MLP瓶颈的设计不同,我们引入了一个轻量级信道聚合模块CA(·),以在高维隐藏空间中进行自适应信道重新分配,并将其进一步扩展到信道聚合(CA)块。如图6a所示,我们将CA块的等式(3)重写为:
Y
=
G
E
L
U
(
D
W
3
×
3
(
C
o
n
v
1
×
1
(
N
o
r
m
(
X
)
)
)
)
,
Z
=
C
o
n
v
1
×
1
(
C
A
(
Y
)
)
+
X
.
(9)
\begin{equation}\begin{aligned} Y&=GELU(DW_{3×3}(Conv_{1×1}(Norm(X)))),\\ Z&=Conv_{1×1}(CA(Y))+X. \end{aligned}\end{equation}\tag{9}
YZ=GELU(DW3×3(Conv1×1(Norm(X)))),=Conv1×1(CA(Y))+X.(9)具体地说,CA(·)由信道缩减投影
W
r
:
R
C
×
H
W
→
R
1
×
H
W
W_r : \Bbb R^{C×HW} → \Bbb R^{1×HW}
Wr:RC×HW→R1×HW和GELU实现,以收集和重新分配通道信息:
C
A
(
X
)
=
X
+
γ
c
⊙
(
X
−
G
E
L
U
(
X
W
r
)
)
,
(10)
CA(X)=X + γ_c\odot(X − GELU(XW_r)), \tag{10}
CA(X)=X+γc⊙(X−GELU(XWr)),(10)其中,
γ
c
γ_c
γc是初始化为零的通道比例因子,它在交互作用
X
−
G
E
L
U
(
X
W
r
)
X−GELU(XW_r)
X−GELU(XWr)中重新分配互补通道。如图7所示,CA(·)有效地促进了中阶博弈论的相互作用。图6b验证了CA(·)与普通MLP和带有SE模块的MLP相比在消除通道信息冗余方面的优越性。尽管对基线进行了一些改进,但MLP w/SE模块仍然需要大的MLP比率(例如,r=6)来实现预期性能,同时引入额外的参数和计算开销。相比之下,我们的r=4的CA(·)以较小的额外成本(0.04M ex-tra参数和0.01G FLOP)比基线带来了0.6%的增益,同时实现了与r=8的基线相同的性能。
4.4、实现细节
遵循ConvNets[86]的网络设计风格,我们通过在每个阶段堆叠不同数量的空间和信道聚合块,将MogaNet扩展到六种模型大小(X-Tiny、Tiny、Small、Base、Large和X-Large),这与RegNet[103]变体具有相似数量的参数。网络配置和超参数详见表A1。FLOP和吞吐量在附录C.3中进行了分析。我们将多阶DWConv层的通道设置为 C l : C m : C h C_l:C_m:C_h Cl:Cm:Ch=1:3:4(见附录C.2)。与[124,72,77]类似,MogaNet中的第一个嵌入主干被设计为两个3×3的堆叠卷积层,步长为2,同时在其他三个阶段采用单层版本嵌入主干。我们选择GELU[54]作为通用激活函数,并仅在Moga模块中使用SiLU,如等式(8)所示。
5、实验(略)
6、结论:
在本文中,我们从多阶博弈论交互的新角度提出了MogaNet,这是一种计算高效的纯ConvNet架构。 通过特别关注多阶博弈论交互,我们设计了一个统一的Moga Block,它有效地捕捉了跨空间和通道空间中稳健的多阶上下文。大量实验验证了MogaNet在精度和计算效率方面与各种视觉基准上的代表性ConvNets、ViTs和混合架构相比的一致优势。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









