







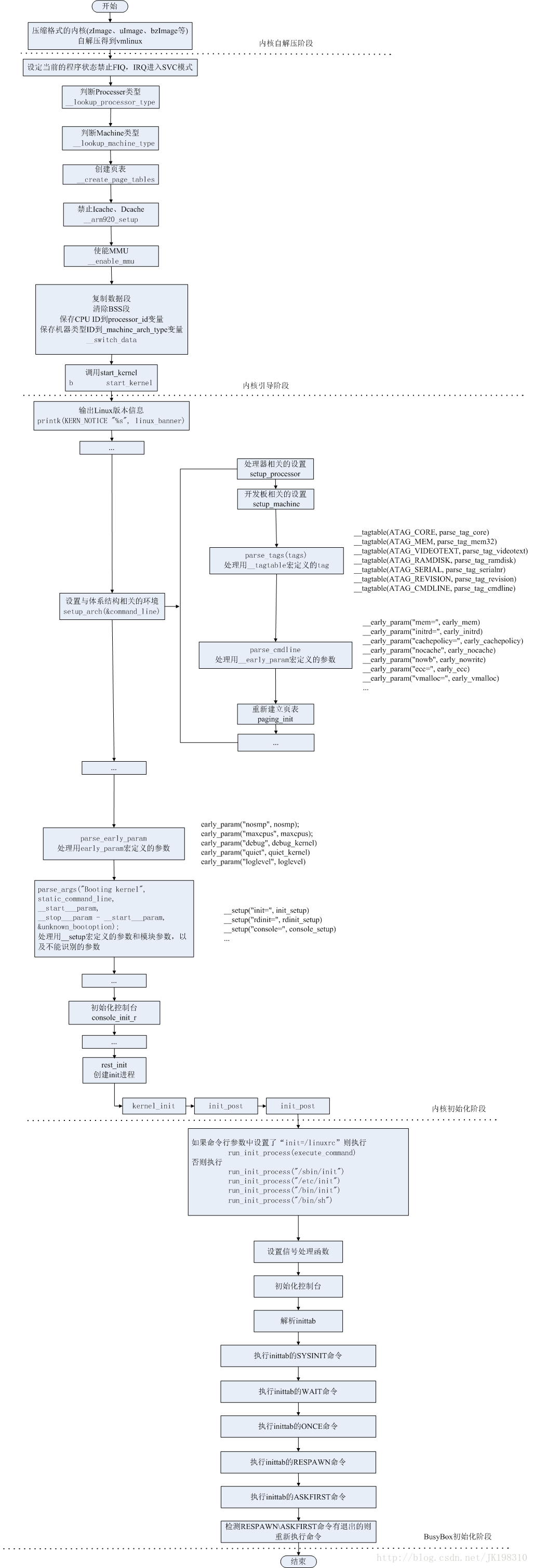
图解ARM Linux的启动全过程
图解ARM-Linux的启动全过程:内核自解压阶段—>内核引导阶段—>内核初始化阶段—>BusyBox初始化阶段。
图片有点大,打开的时候比较慢。大家可以免费下载http://download.csdn.net/detail/ce123/4275871。
注意:本图在不断的修改中,本网页中的图是最新的。下载链接中的图不能替换,可能有些错误!
 9284
3925
9284
3925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言























