







文章目录
前言
网页爬虫经常遇到的问题就是登录账户,有些简单的网站我们可以简单的send key来输入账户密码就可以登录,但是有很多网站需要验证码之类的就不太好用了,这时候就体现到了cookie登录的优点了。下面将介绍一下使用selenium来操作cookie
一、python中操作cookie的方法
1.获取当前会话中的所有cookies - get_cookies()
代码如下(示例):
driver.get('https://www.baidu.com')
print(driver.get_cookies())
2.返回指定name名称的Cookie信息 - get_cookie(name值)
名称指的是下图中的名称
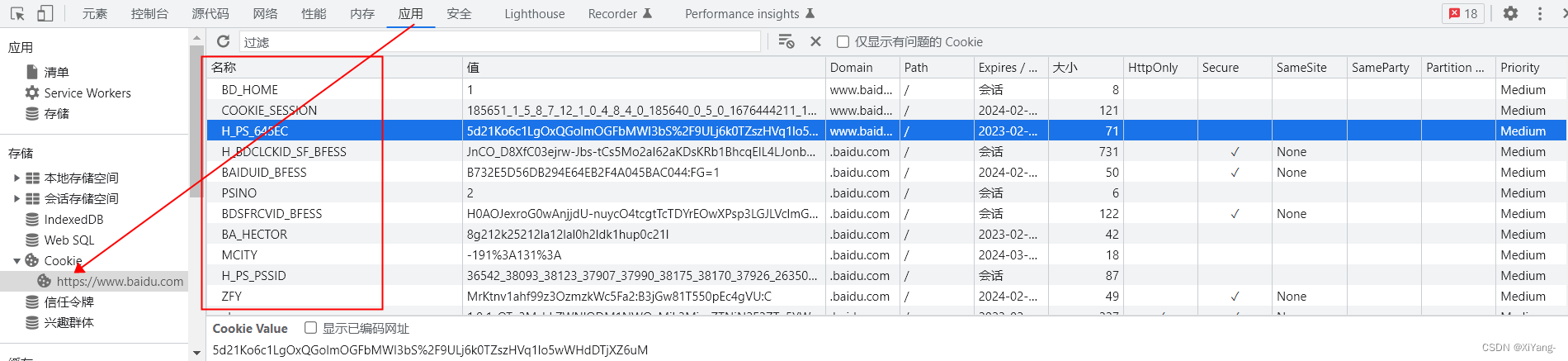
代码如下(示例):
driver.get('https://www.baidu.com')
print(driver.get_cookie('BIDUPSID')) # 以百度为例,传入指定的cookie值,会获得这个cookie的相关信息
> 返回:{'domain': '.baidu.com', 'expiry': 3803198408, 'httpOnly': False, 'name': 'BIDUPSID', 'path': '/', 'secure': False, 'value': '7BEE5AE370BED745E72662B0FE0030E2'}
3.添加cookie - add_cookie(cookie_dict)
代码如下(示例):
driver.get('https://www.baidu.com')
# 指定cookie
cookie = {'domain': '.www.baidu.com', 'httpOnly': False, 'name': 'sugstore', 'path': '/', 'secure': False, 'value': '0'}
# 添加cookie
driver.add_cookie(cookie)
# 添加后获取cookie
print(driver.get_cookies())
4.删除特定的cookie - delete_cookie(name)
代码如下(示例):
driver.get('https://www.baidu.com')
# 删除指定的cookie信息
driver.delete_cookie(cookie['domain'])
# 删除后获取cookie
print(driver.get_cookies())
5.删除所有的cookie - delete_all_cookies()
代码如下(示例):
driver.get('https://www.baidu.com')
# 删除所有的cookie信息
driver.delete_all_cookies()
# 删除后获取cookie
print(driver.get_cookies())
二、网站实例 - 百度为例
1.获取cookie
获取cookie最简单的方法就是我们首先使用selenium手动登录一下网站,然后获取cookie值保存到本地,之后再登陆的时候直接调用本地cookie就可以了。
代码如下(示例):
# 编写的getcookies.py文件
from selenium import webdriver # 导入webdriver驱动
import time
import json
driver.maximize_window() # 将窗口最大化
driver.get('https://www.baidu.com') # 访问百度网站
time.sleep(60) # 等待一段时间,该时间内手动操作登录网站
# 将cookie保存为json格式,此时会发现当前目录中多了一个cookies.txt的文件
with open('cookies.txt','w') as f:
f.write(json.dumps(driver.get_cookies()))
driver.quit() # 退出网站
2.使用cookie
代码如下(示例):
# 编写的addcookies.py文件
from selenium import webdriver # 导入webdriver驱动
import time
import json
driver.maximize_window() # 将窗口最大化
driver.get('https://www.baidu.com') # 访问百度网站
driver.delete_all_cookies() # 清除由于浏览器打开已有的cookies
with open('cookies-bd.txt','r') as f:
cookies_list = json.load(f) # 使用json读取cookie,注意读取的是文件,所以用load而不是loads
for cookie in cookies_list:
driver.add_cookie(cookie)
driver.refresh() # 刷新浏览器,刷新后发现网站已经通过cookie登录上了
3.常见问题
问题(1):
若expiry的值是小数,如:“expiry”: 2602060060.76,在运行后则会报错:
selenium.common.exceptions.InvalidArgumentException: Message: invalid argument: invalid ‘expiry’
这个 expiry 是cookie的生命周期,也就是失效时间
针对该报错我们有两种解决办法,以下两种方式可根据自己喜好选择:
方法1:将expiry类型变为int(其实不太清楚为什么变为int就可以)
方法2:删除该字段
问题(2):获取的cookie信息不完整或是不准确
情况1:若使用的不是设置等待时间 手动登录网站 去获取cookie的方式,而是通过selenium自动化实现登录,去获取cookie的方式,需要在点击登录之后,driver.get_cookies()之前,增加一个等待时间,以避免退出太快获取的还是登录之前的cookie。这样cookie获取的不正确,后边会对登录造成影响(登录不上)
情况2:再三对比,确认自动化获取的cookie信息完整,但是添加cookie后还是登录不上。-- 使用手动登录的cookie信息,替换抓取到的cookie一些关键的值,如access_token、secure等。再次使用cookie登录就能成功了
综上所述,建议获取cookie信息的时候使用手动登录的方式,能避免一些犹未可知的问题
4.最终代码
代码如下(示例):
# 编写的addcookies.py文件
from selenium import webdriver # 导入webdriver驱动
import time
import json
driver.maximize_window() # 将窗口最大化
driver.get('https://www.baidu.com') # 访问百度网站
driver.delete_all_cookies() # 清除由于浏览器打开已有的cookies
with open('cookies-bd.txt','r') as f:
cookies_list = json.load(f) # 使用json读取cookie,注意读取的是文件,所以用load而不是loads
# 方法1:将expiry类型变为int
for cookie in cookies_list:
if isinstance(cookie.get('expiry'),float):
cookie['expiry'] = int(cookie['expiry'])
driver.add_cookie(cookie)
# 方法2:删除该字段
# for cookie in cookies_list:
# if 'expiry' in cookie:
# del cookie['expiry']
# driver.add_cookie(cookie)
driver.refresh() # 刷新一下浏览器,就可以在页面中看到已登录的状态了















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









