








原文地址:http://www.viva64.com/en/a/0004/
译者注:由于能力有限,没能一次性翻译完。这篇文章分两次完成,这是第一部分。恳请指正翻译错误。
摘要
当从32位平台向64位平台进行代码移植的时候,程序发生错误是可以被观察到(observed)的。文章中给出了错误代码示例以及纠正的方法。并且列出了诊断错误的代码分析方法。
这篇文章包含了各种64位错误的例子。但是,自从我们开始写这边文章后,我们已经学习了更多的例子和各种错误。它们没有包含在本文中。请参见这篇覆盖了我们已知的在64位编程中的缺陷的文章,“ACollection of Examples of 64-bit Errors in RealPrograms”。我们也同样推荐你学习这篇课程 "Lessonson development of 64-bit C/C++applications",在这篇文章中,我们描述了使用Viva64代码分析器创建正确的64位代码及查找各种类型的缺陷的方法。
引言
这篇文章描述了移植32位程序到64位系统的过程。这篇文章适合于使用C++的程序员,但是也可能对所有在其他平台同样面临移植问题的程序员有用。这篇文章的作者是64位系统移植领域的专家,也是Viva64工具的开发人员。Viva64可以帮助查找64位程序的错误。
要知道,这种在开发64位程序的过程中出现的新类型的错误,不只是在成千上万的构建中一些新的错误的构建。这必然是每个程序开发人员所面临的困难。这篇文章将帮助你为这些困难做好准备并且给出克服的方法。除了好处,任何新技术(在编程领域,其他领域也是),在使用的过程中,带来了一些局限甚至是问题。同样地,在64位软件开发方面,也存在着类似的问题。众所周知,64位软件是信息技术发展的下一步。但是,现实中,只有少数的程序员认识了到这个领域和64位程序开发的细微差别。
我们不会讲解64位架构提供的好处。因为已经有许多致力于这方面的出版物,并且读者能够轻易地找到他们。
这篇文章的目标是彻底地研究64位程序开发人员所面对的问题。在这篇文章中,你将学到:
-
在64位系统中出现的典型编程错误
-
造成这些错误的原因,及相应的示例
-
错误纠正的方法
-
回顾在64位程序中查找错误的方法与手段
给出的信息会让你:
-
发现32位与64位系统的不同之处
-
当为64位系统写代码时,避免错误
-
通过减少调试及测试的必要时间,加速在64位架构下32位应用程序的迁移过程
-
准确认真地预测在64位系统中移植代码的必要时间
这篇文章包含了大量示例,为了更好地理解,你应该在编程环境中试试。深入它们将会给你带来远大于单个示例的好处。你将打开进入64位系统的世界之门。
| 类型名 | 类型大小(32位系统) | 类型大小(64位系统) | 描述 |
| ptrdiff_t | 32 | 64 | 有符号整型类型,表示两个指针值之差。这个类型用于保存内存大小。有时也被用作返回大小的函数的结果,或者-1(如果发生错误)。 |
| size_t | 32 | 64 | 无符号整型类型。这个类型的数值是sizeof()操作符返回的。这个类型用来保存对象的个数或大小。 |
| intptr_t, uintptr_t, SIZE_T, SSIZE_T, INT_PTR,DWORD_PTR, etc | 32 | 64 | 能表示指针值的整型类型 |
| time_t | 32 | 64 | 以秒为单位的时间 |
表N1.一些整型类型的描述
本文,我们将使用“内存大小(memsize)”类型这个术语。这个术语是指,在32位到64位平台变更中,任何能够保存指针的并且能够改变其大小的简单整型类型。例如,memsize类型是:size_t,ptrdiff,allpointers, intptr_t, INT_PTR, DWORD_PTR.
关于那些决定着不同系统间基础数据类型一致性的数据模型,我们有话要说。表N2包含了我们感兴趣的数据模型。
|
| ILP32 | LP64 | LLP64 | ILP64 |
| char | 8 | 8 | 8 | 8 |
| short | 16 | 16 | 16 | 16 |
| int | 32 | 32 | 32 | 64 |
| long | 32 | 64 | 32 | 64 |
| long long | 64 | 64 | 64 | 64 |
| size_t | 32 | 64 | 64 | 64 |
| pointer | 32 | 64 | 64 | 64 |
表N2. 32为和64位数据模型
在这篇文章中,我们假设程序从具有ILP32位数据模型的系统迁移到LP64位或LLP64位模型系统。4
最终,Linux的64位模型(LP6)与Windows的(LLP64)的不同仅在于long类型的大小。既然,它是他们的唯一不同之处,我们将避免使用long,unsignedlong数据类型,并且将使用ptrdiff_t,size_t类型来概括本文。
让我们观察在64位架构移植程序时发生的这种类型的错误。
1.禁止警告
所有高质量代码开发的书籍都推荐你设置显示警告的级别尽可能地高。但是,实际中会有一些项目,该诊断级别很低甚至被禁掉。通常,古老的代码只被支持而不会被修改。为项目工作的程序员已经习惯了代码工作但不考虑质量的事实。因此,没一个人都会在64位系统移植时,与各种严重的警告擦肩而过。
当移植程序时,你应当强制性地为整个工程打开警告。这会帮助你检查代码的兼容性并且彻底地分析代码。这种方法能够帮你在新架构中调试项目时节省大量的时间。
如果我们不这样做,我们将面临这各种各样的简单并且愚蠢的错误。这是一个出现在64位程序中简单的溢出的例子,如果我们完全忽略警告。
unsigned char *array[50];unsigned char size = sizeof(array);32-bit system: sizeof(array) = 20064-bit system: sizeof(array) = 400
2.具有可变参数函数的使用
典型的例子是printf,scanf函数及他们参数的错误使用:
1) const char *invalidFormat = "%u";size_t value = SIZE_MAX;printf(invalidFormat, value);2) char buf[9];sprintf(buf, "%p", pointer);
在第一个例子中,没有考虑到size_t类型不等同于64位平台的unsigned类型。如果值大于UINT_MAX,这将导致打印错误。
在第二个例子中,开发者没有考虑到指针的大小将来可能大于32位。结果,这些代码在64位架构中会导致缓存溢出。
可变参数函数的错误使用是所有架构中常见的错误而不仅仅存在于64位架构之中。这关乎使用C++语言结构的基础风险。通常的做法是拒绝这些风险并使用安全编程的方法。我们强烈建议你采用安全编程的方法来修改那段代码。例如,你可以使用cout替换printf,boost::format或std::stringstream替换sprintf。
如果你不得不维护一段采用类似sscanf之类函数的代码,在输入格式控制字符串中我么可以采用特殊的宏,这些宏会根据不同的系统转变为必要的修饰符。例如:
// PR_SIZET on Win64 = "I"// PR_SIZET on Win32 = ""// PR_SIZET on Linux64 = "l"// ...size_t u;scanf("%" PR_SIZET "u", &u);
3.神奇的数字
低质量代码往往包含神奇的数字,它的存在是危险的。在64位系统代码迁移时,这些数字如果参与地址,对象大小或比特操作,那么可能使代码变得无效。
表N3包含了基本的一些神奇数字,他们可以影响应用程序在新平台的正常工作。
| Value | Description |
| 4 | 指针类型的字节数 |
| 32 | 指针类型的位数 |
| 0x7fffffff | 32位有符号整型变量的最大值。将32位最高位置零的掩码。 |
| 0x80000000 | 32位有符号整型变量的最小值。获取32位最高位的掩码。 |
| 0xffffffff | 32位变量的最大值。可以选择-1作为错误标志。 |
N3. 从32位到64位平台迁移时危险的基础神奇数字
你应该彻底地研究下代码,找到神奇的数字,并且使用安全的数字和表达式替换它们。例如,你可一使用sizeof运算符,来自<limits.h>、<inttypes.h>的特殊值。
让我们看一下一些与使用神奇数字相关的错误。最频繁的是使用数字存储类型的大小。
1) size_t ArraySize = N * 4;intptr_t *Array = (intptr_t *)malloc(ArraySize);2) size_t values[ARRAY_SIZE];memset(values, 0, ARRAY_SIZE * 4);3) size_t n, newexp;n = n >> (32 - newexp);
我们可以认为所有的案例中使用的类型的大小总是4个字节。为了使代码正确,我们应当使用sizeof运算符。
1) size_t ArraySize = N * sizeof(intptr_t);intptr_t *Array = (intptr_t *)malloc(ArraySize);2) size_t values[ARRAY_SIZE];memset(values, 0, ARRAY_SIZE * sizeof(size_t));
或者
memset(values, 0, sizeof(values)); //preferred alternative3) size_t n, newexp;n = n >> (CHAR_BIT * sizeof(n) - newexp);
有时候,我们可能需要一个特定的数值。例如,我们需要一个除低四位外全是1的size_t类型的数值。在一个32位程序中,这个数值可能以一下方式声明。
// constant '1111..110000'const size_t M = 0xFFFFFFF0u;
这段代码对于64位系统是错误的。这种错误是非常不舒服的,因为神奇数字可能以各种各样的形式出现并且查找他们是个体力活。不幸的是,除了使用#ifdef或特殊的宏来修正代码外,没有其他方法。
#ifdef _WIN64#define CONST3264(a) (a##i64)#else#define CONST3264(a) (a)#endifconst size_t M = ~CONST3264(0xFu);
有时,作为一个错误码或者其他特殊标记,“-1”值被写成“0xffffffff”来使用。在64位平台上,这个写下的表达式是不正确的,并且我们应当显示地使用“-1”值。下面是一段采用“0xffffffff”作为错误标记的错误代码的例子。
#define INVALID_RESULT (0xFFFFFFFFu)size_t MyStrLen(const char *str) {if (str == NULL)return INVALID_RESULT;...return n;}size_t len = MyStrLen(str);if (len == (size_t)(-1))ShowError();
为了安全起见,我们假设你清楚地知道"(size_t)(-1)"在64位平台上是什么值。你可能错误地认为是 0x00000000FFFFFFFFu。根据C++的规则,-1先转换成有符号的更高类型的等价值,然后转换成一个无符号值:
int a = -1; // 0xFFFFFFFFi32ptrdiff_t b = a; // 0xFFFFFFFFFFFFFFFFi64size_t c = size_t(b); // 0xFFFFFFFFFFFFFFFFui64
因此,“(size_t)(-1)”在64位架构上以0xFFFFFFFFFFFFFFFFui64形式表示,这是64位size_t类型的最大值。
让我们回到带有INVALID_RESULT的错误。数值0xFFFFFFFFu的使用会导致"len==(size_t)(-1)"条件在64位程序中计算错误。最好的解决方案是以不需要特定标记值的方式来修改代码。如果你出于某种原因确实需要使用它们或者认为这个建议是不合理的,那么请使用-1的等价值完全地修正代码。
#define INVALID_RESULT (size_t(-1))...
4.以double类型存储整型
作为规则,double类型有64位,并且在32位和64位系统上是和IEEE-754标准是兼容的。一些程序员使用double类型来存储整型或者和它们一起工作。
size_t a = size_t(-1);double b = a;--a;--b;size_t c = b; // x86: a == c// x64: a != c
给出的例子在32位系统上是正当的,因为double类型有52个有效位并且能够毫无损失地存储32位整型数值。但是,当试图以double类型存储64位整型时,确切的值会丢失(见图1)。
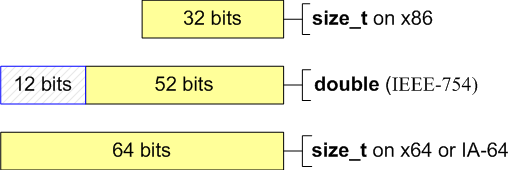
图1:size_t和double数据类型的有效位数
你的程序很有可能使用约数。但是为了安全起见,我们要警告你对新架构可能会造成影响。并且在任何情况下,混合整型运算和浮点型运算是不推荐的。
5.移位操作
如果不小心的话,移位操作在从32位向64位系统移植时会导致大量的问题。让我们以一个函数的例子开始,这个函数可以将一个memsize类型的变量中你所选择的位置为1。
ptrdiff_t SetBitN(ptrdiff_t value, unsigned bitNum) {ptrdiff_t mask = 1 << bitNum;return value | mask;}上述代码只能在32位架构下工作,并且只允许定义第0至31之间的位。该程序当移植到64位平台后,应该可以定义0-63位的值。Set(0,32)会返回什么值呢?如果你认为那个值是0x100000000,作者很高兴,因为他没有徒劳地准备这篇文章。你将得到0。注意,“1”的类型是整型,当进行32位移位时,将发生溢出。如图2所示。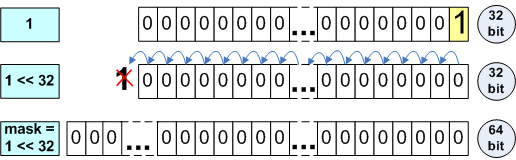
图2:计算掩码值
为了纠正代码,必须让常量“1”的类型与变量mask的类型相同。ptrdiff_t mask = ptrdiff_t(1) << bitNum;orptrdiff_t mask = CONST3264(1) << bitNum;还有一个问题。不正确的函数SetBitN(0,31)会返回什么结果呢?正确的结果是0xffffffff80000000。表达式1 << 31的结果是负数-2147483648。这个数的64位整型形式是0xffffffff80000000。你应该注意并且要考虑到不同类型的值移位带来的影响。为了让你更好地理解上述信息,表N4包含了在64位系统中有趣的移位表达式。
| 表达式 | 结果(十进制) | 结果(十六进制) |
| ptrdiff_tResult; Result = 1 << 31; | -2147483648 | 0xffffffff80000000 |
| Result= ptrdiff_t(1) << 31; | 2147483648 | 0x0000000080000000 |
| Result= 1U << 31; | 2147483648 | 0x0000000080000000 |
| Result= 1 << 32; | 0 | 0x0000000000000000 |
| Result= ptrdiff_t(1) << 32; | 4294967296 | 0x0000000100000000 |
表N4.64位系统移位表达式及其结果
6.指针地址的存储
在进行64位系统移植时许多错误与指针大小的改变有关,即通常整型数据类型的大小。在ILP32数据模型的环境中,通常的整型数据类型和指针有相同的大小。不幸的是,所有地方的32位代码都是基于这个假设。指针经常转换成有符号整型、无符号整型和其他类型进行不合适的指针计算。一个人应该只使用memsize类型来表示整型形式的指针。uintptr_t类型是首选,因为它很清楚地显示出程序员的意图并且考虑到未来可能的变化使代码具有更好的可移植性。让我们看两个小例子。1) char *p;p = (char *) ((int)p & PAGEOFFSET);2) DWORD tmp = (DWORD)malloc(ArraySize);...int *ptr = (int *)tmp;两个例子都没考虑到指针的大小可能不是32位。他们使用显式类型转换,截断了指针的高位字节。这在64位系统上是错误。下面是修正的版本,使用整型memsize类型intptr_t和DWORD_PTR存储指针地址:1) char *p;p = (char *) ((intptr_t)p & PAGEOFFSET);2) DWORD_PTR tmp = (DWORD_PTR)malloc(ArraySize);...int *ptr = (int *)tmp;刚才研究的两个例子是危险的,因为程序的失败可能会发现的更晚。处理64位系统上少量位于前4Gb内存的数据,这个程序可能绝对正确。然后,为了处理更大的产品目标,将会有内存分配超出前4Gb。当处理指针时,示例中给出的代码将导致超出前4Gb的对象出现未定义的行为。下面的代码不会隐藏并将显示在第一次执行时。void GetBufferAddr(void **retPtr) {...// Access violation on 64-bit system*retPtr = p;}unsigned bufAddress;GetBufferAddr((void **)&bufAddress);选择能够存储指针类型的类型也是正确的。uintptr_t bufAddress;GetBufferAddr((void **)&bufAddress); //OK有一些必要地将指针地址存储到32位类型的情况。这些情况大多出现在不得不和老的API一起工作的时候。针对那些情况,一个程序员应该求助于特殊的函数,例如LongToIntPtr, PtrToUlong等。最后,我想说的是将指针的地址存储到总是与64位等价的类型中是一个不好的风格。当128位系统出现时,程序员将不得不再进一步修正给出的代码。PVOID p;// Bad style. The 128-bit time will come.__int64 n = __int64(p);p = PVOID(n);
7.联合中的Memsize类型
联合的特性是分配一块相同的内存为所有的成员使用,他们是重叠的。尽管,可以使用任何成员访问这块内存区域,但是满足这个目标的变量的选取应该有意义。
程序员应该注意那些包含指针和memsize类型的联合。
当不得不与作为整型的指针一起工作时,使用下面的例子显示的联合会很方便。并且不使用显式转换处理它的数字形式。
union PtrNumUnion {char *m_p;unsigned m_n;} u;u.m_p = str;u.m_n += delta;
这段代码在32位系统上是正确的,但是在64位上是错误的。当在64位系统上改变m_n成员,我们仅处理了m_p的一部分。我们应当使用与指针类型相一致的类型。
union PtrNumUnion {char *m_p;size_t m_n; //type fixed} u;
联合的两一个频繁使用是一个成员表示其他小成员的集合。例如,我们可能需要将一个size_t类型的数值分割成字节以执行计算字节中“零”位的个数的表算法。
union SizetToBytesUnion {size_t value;struct {unsigned char b0, b1, b2, b3;} bytes;} u;SizetToBytesUnion u;u.value = value;size_t zeroBitsN = TranslateTable[u.bytes.b0] +TranslateTable[u.bytes.b1] +TranslateTable[u.bytes.b2] +TranslateTable[u.bytes.b3];
这里有一个根本算法错误,size_t类型只包含4个字节。自动查找算法的错误几乎是不可能的,但是我们可以查找所有的联合成员并检查memsize类型的存在。如果发现了这样一个能够找出算法错误的联合,以下面的方法重写代码。
union SizetToBytesUnion {size_t value;unsigned char bytes[sizeof(value)];} u;SizetToBytesUnion u;u.value = value;size_t zeroBitsN = 0;for (size_t i = 0; i != sizeof(bytes); ++i)zeroBitsN += TranslateTable[bytes[i]];
8.改变数组类型
有时必要(或者仅仅为了方便)将不同类型的元素表示为数组项。下面的代码显示了风险与安全类型转换。
int array[4] = { 1, 2, 3, 4 };enum ENumbers { ZERO, ONE, TWO, THREE, FOUR };//safe cast (for MSVC2005)ENumbers *enumPtr = (ENumbers *)(array);cout << enumPtr[1] << " ";//unsafe castsize_t *sizetPtr = (size_t *)(array);cout << sizetPtr[1] << endl;//Output on 32-bit system: 2 2//Output on 64 bit system: 2 17179869187
正如你看到的,在32位和64位系统上,程序的输出是不同的。在32位系统上,对数组项的访问可以正确地完成,因为size_t和int的大小是一致的,所以我们看到的是“22”。
在64位系统上,我们得到的输出是"217179869187"。因为17179869187是在sizePtr数组的第一项(看图3)。在一些请款下,我们需要这种非常的行为,但是这通常是个错误。
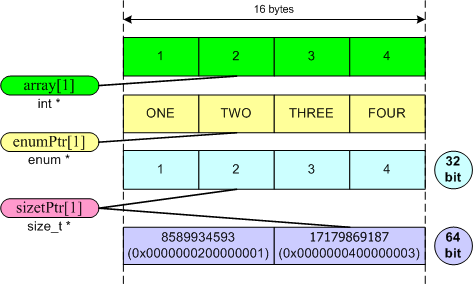
图3:内存中数组项的布局
上述情况的修复方法是通过程序现代化拒绝危险的类型转换。另一种方法是创建一个新的数组并把原数组的值拷贝进去。
9.带有memsize类型参数的虚函数
如果有带有虚函数的大的继承类图,那么存在疏忽使用不同类型参数的风险。然而,事实上这些类型在32位系统上相一致。例如,在基类中使用以size_type作为参数的虚函数,在派生类中你使用unsigned类型。因此,这段代码在64位系统上是错误的。
但是类似这样的错误不一定躲在大的派生类图中,下面是其中一个例子。
class CWinApp {...virtualvoidWinHelp(DWORD_PTR dwData,UINT nCmd);};classCSampleApp:publicCWinApp{...virtualvoidWinHelp(DWORD dwData,UINT nCmd);};
让我们遵循应用程序开发的生命周期。想象一下首先当CWinApp类中的WinHelp函数具有下面的原型时,它是为MicrosoftVisual C++ 6.0开发的。
virtual void WinHelp(DWORD dwData, UINT nCmd = HELP_CONTEXT);
就像例子中显示的那样,能够正确地执行CSampleApp中虚函数的覆盖。然后,项目被移植到MicrosoftVisual C++2005中,CWinApp中的函数原型经受了一些改变,即用DWORD_PTR类型替换DWORD类型。在32位系统上,这个程序运行绝对正确,因为DWORD和DWORD_PTR是一致的。在为64位平台编译给出的代码期间,问题会出现。我们将得到两个相同名字但参数不同的函数,结果用户的代码将不会执行。
修正的方法是在相应的虚函数中使用相同的参数类型。
class CSampleApp : public CWinApp{...virtualvoidWinHelp(DWORD_PTRdwData,UINT nCmd);};
10.序列化和数据交换
在向新平台移植软件解决方案期间,重要的一点是继承已存在的数据交换协议。例如,读取已存在的项目格式,执行32位进程和64位进程间数据交换,是必要的。
这种类型的错误大多数在memsize类型的序列化和使用它们的数据交换操作中。
1)size_t PixelCount;fread(&PixelCount,sizeof(PixelCount),1,inFile);2)__int32 value_1;SSIZE_T value_2;inputStream>>value_1>>value_2;3)time_ttime;PackToBuffer(MemoryBuf,&time,sizeof(time));
在所有给出的例子中,有两种类型的错误:可变二进制接口大小的类型的使用和忽略字节序。
可变大小类型的使用
在数据交换的二进制接口中,使用依赖于开发环境而改变大小的数据类型是不可接受的。C++语言的所有类型没有唯一的大小,因此,使用他们不能满足所有的目的。这就是为什么各种环境的开发者和程序元自己创建精确大小的数据类型,例如__int8、__int16、INT32、word64等。
在不同平台的程序中,这种类型的使用提供了数据兼容性,尽管需要这些古怪类型的使用。下述三个例子写得不太准确,这将显示出从32位到64位一些数据类型容量的改变。为了考虑到支持旧数据格式的必要性,修正可能看起来如下:
1) size_t PixelCount;__uint32 tmp;fread(&tmp,sizeof(tmp),1,inFile);PixelCount=static_cast<size_t>(tmp);2)__int32 value_1;__int32 value_2;inputStream>>value_1>>value_2;3)time_ttime;__uint32 tmp=static_cast<__uint32>(time);PackToBuffer(MemoryBuf,&tmp,sizeof(tmp));
但是,给出的修正版本不是最好的。在64位系统移植期间,程序可能处理大量的数据并且32位数据类型的使用可能成为严重的问题。在这种情况下,为了与旧的数据格式兼容我们可能抛开旧的已修正错误类型的代码,并且考虑到产生的错误执行新的二进制数据格式。另一个方法是复用二进制格式并且采用文本格式或其他库提供的数据格式。
字节序的忽视
甚至当修正可变数据类型大小后,你可能面临着二进制格式的不兼容性。原因是不同的数据表示。大多数与不同字节序有关。
字节序是一种多字节数字字节记录方法(见图4)。小端序的意思是记录以低字节开始而以高字节结束。这种记录字节序是可以被带有x86处理器的PC的内存接受的。大端序-记录以高字节开始而以低字节结束。这种顺序是TCP/IP协议的标准。这就是为什么大端序又经常被称为网络字节序。这种字节序被Motorola68000, SPARC采用。

图4:64位数据类型在大端和小端系统上的字节序
当开发二进制接口或者数据格式时,你应该注意字节序。如果移植32位应用程序的64位系统有不同类型的字节序,你将不得不在你的代码中考虑它。为了进行大端序和小端序的转换,你可以使用这些函数,例如htonl()、htons()、bswap_64等。















 5212
5212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









