
 关注
关注
 分享
分享
hadoop
Joie.
这个作者很懒,什么都没留下…
展开
-
数据仓库理论概述
数据仓库理论概述1、数据仓库理论1.1学习数据仓库的目的1.2数据仓库的概念1.2.1面向主题1.2.2集成1.2.3非易失1.2.4随时间变化1.3数据仓库分层:2、数据仓库和数据库的区别2.1数据仓库和数据库的区别2.2OLTP和OLAP的区别3、数据仓库的架构3.1Inmon架构3.2Kimball架构3.3混合型架构3.4数据仓库的解决方案4、数据ETLETL工具5、数据仓库的建模5.1数据仓库模型构建5.1.1选择业务流程5.1.2声明粒度5.1.3确认维度5.1.4确认事实模型星型模型雪花模型原创 2020-10-09 17:11:50 · 152 阅读 · 0 评论 -
sqoop介绍及数据迁移
sqoop介绍及数据迁移1、sqoop概述2、sqoop常用命令3、sqoop数据迁移3.1从RDB导入数据到HDFS3.2从RDB导入数据到Hive3.3从RDB导入数据到HBase1、sqoop概述在上次的博客中,我们已经装好了sqoop,并且运行成功了,若是,有同学不清楚安装流程,请参考博客:sqoop安装及配置。那么sqoop到底是什么呢,作用是什么,我们现在就来看一看:Sqoop是一个用于在Hadoop和关系数据库之间传输数据的工具将数据从RDBMS导入到HDFSHDFS、Hiv原创 2020-09-29 19:11:35 · 270 阅读 · 0 评论 -
sqoop安装及配置
sqoop安装即环境配置一、sqoop 安装安装 sqoop 的前提是已经具备 Java 和 Hadoop、Hive、ZooKeeper、HBase 的 环境。1.1 下载并解压1.上传安装包 sqoop-1.4.6-cdh5.14.2.tar.gz 到虚拟机中2.解压 sqoop 安装包到指定目录tar -zxf sqoop-1.4.6-cdh5.14.2.tar.gz -C /opt/3.配置环境变量vi /etc/profile让配置文件生效source /etc/profi原创 2020-09-26 15:06:03 · 729 阅读 · 0 评论 -
phoenix理论、安装配置和对HBase的操作
phoenix理论和、安装配置和对HBase的操作phoenix理论概述应用场景架构SQL语法phoenix安装配置phoenix对Hbase的操作phoenix理论概述Phoenix简介构建在HBase上的SQL层使用标准SQL在HBase中管理数据使用JDBC来创建表,插入数据、对HBase数据进行查询Phoenix JDBC Driver容易嵌入到支持JDBC的程序中Phoenix无法代替RDBMS缺乏完整约束,很多领域尚不成熟Phoenix使HBase更易用应用原创 2020-09-26 14:22:25 · 157 阅读 · 0 评论 -
HBase基本命令
hbase基本命令用户权限:user_permission ['表名']grant '用户名','RWXCA'表:增:create '表名',{NAME=>'列簇名'},{NAME=>'列簇名'}删:disable '表名' ---> drop '表名'改:snapshot '表名','镜像名' clone_snapshot '镜像名','表名' delete_snapshot '镜像名'查:list行:put的时候:put '表名','行键','列原创 2020-09-25 16:16:58 · 84 阅读 · 0 评论 -
NoSQL综述及HBase基础
@[TOC](这里写目录标题NoSQLHBaseNoSQL什么是NoSQLNoSQL:not only SQL,非关系型数据库NoSQL是一个通用术语指不遵循传统RDBMS模型的数据库数据是非关系的,且不使用SQL作为主要查询语言解决数据库的可伸缩性和可用性问题不针对原子性或一致性问题为什么使用NoSQL互联网的发展,传统关系型数据库出现瓶颈高并发读写高存储量高可用性高扩展性低成本NoSQL与关系型数据库对比主要区别如下NoSQL的特点最终一原创 2020-09-25 16:13:45 · 213 阅读 · 0 评论 -
Hive函数及性能优化
Hive函数及性能优化Hive函数分类内置函数标准函数字符函数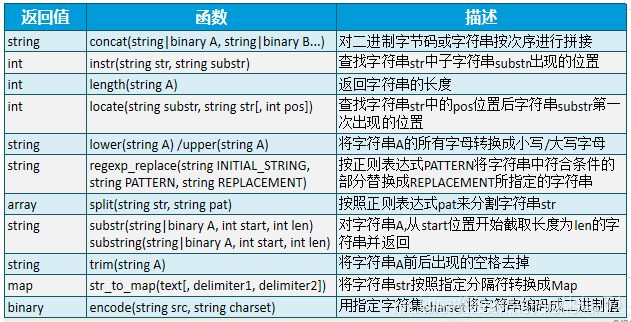类型转换函数数学函数![在这里原创 2020-09-25 15:14:58 · 371 阅读 · 0 评论 -
Hive窗口函数
Hive窗口函数概述排序聚合分析窗口定义概述窗口函数是一组特殊函数扫描多个输入行来计算每个输出值,为每行数据生成一行结果可以通过窗口函数来实现复杂的计算和聚合语法Function (arg1,..., arg n) OVER ([PARTITION BY <...>] [ORDER BY <....>] [<window_clause>])PARTITION BY类似于GROUP BY,未指定则按整个结果集只有指定ORDER BY子句之原创 2020-09-22 17:24:33 · 72 阅读 · 0 评论 -
Hive聚合函数
Hive聚合函数GROUP BYHAVING基础聚合高级聚合GROUP BYgroup by用于分组Hive基本内置聚合函数与group by一起使用如果没有指定group by子句,则默认聚合整个表除聚合函数外,所选的其他列也必须包含在group by中group by支持使用case when或表达式支持按位置编号分组:set hive.groupby.orderby.position.alias=true;案例:#执行失败(原因:除聚合函数外,所选的其他列也必须包含在group原创 2020-09-22 17:14:57 · 2110 阅读 · 0 评论 -
Hive数据排序
Hive数据排序order by(全局排序)sort by(分区内排序)/distribute bycluster by总结order by(全局排序)order by (asc|desc)类似于标准SQL只使用一个Reducer执行全局数据排序速度慢,应提前做好数据过滤支持使用case when或表达式支持按位置编号排序set hive.groupby.orderby.position.alias=true;案例:select name,id,info from employee原创 2020-09-22 17:06:18 · 98 阅读 · 0 评论 -
zeppelin安装配置
zeppelin安装配置一、下载安装包上传并解压修改配置文件四、启动zeppelin五、配置hive解释器六、使用Zepplin的hive解释器一、下载安装包http://zeppelin.apache.org/download.html进入页面后可以选择相应版本进行下载,我们这里选择zeppelin-0.8.1-bin-all.tgz上传并解压我们先将下载好的zeppelin包上传至Linux解压zeppelin包至/opt目录下tar -zxvf zeppelin-0.8.1-bi原创 2020-09-19 15:23:20 · 437 阅读 · 0 评论 -
hive查询语句中显示列名
要想在hive查询语句中显示列名,我们可以在hive命令行中手动开启:set hive.cli.print.header=true;但是这条命令有个弊端,那就是命令只能在当前会话有效,退出hive就失效,而且会显示表名,使得列名会十分冗长,所以我们可以使用下面的方法让命令自动生效,而且不显示表名。在hive/conf/hive-site.xml配置文件中添加下面的内容。<property> <name>hive.resultset.use.unique.column.na原创 2020-09-17 18:58:38 · 1344 阅读 · 0 评论 -
hive 支持的文件格式
hive 支持的文件格式hive支持的文件格式TEXTFILE 格式SEQUENCEFILE 格式RCFILE 文件格式hive支持的文件格式Hive文件存储格式包括以下几类:1、TEXTFILE2、SEQUENCEFILE3、RCFILE4、ORCFILE(0.11以后出现)其中TEXTFILE为默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理。SEQUENCEFILE,RCFILE,ORCFILE格式的表不能直接从本地文件导入数据,数据要原创 2020-09-17 16:24:48 · 898 阅读 · 0 评论 -
Apache Hive基础
Apache Hive基础Hive理论基础Hive操作Hive理论基础1、什么是Hive?基于Hadoop的数据仓库解决方案将结构化的数据文件映射为数据库表提供类sql的查询语句HQL(Hive Query Language)Hive让更多人使用HadoopHive成为Apache顶级项目Hive始于2007年的Facebook官网:http://hive.apache.org2、Hive的优势和特点提供了一个简单的优化模型HQL类SQL语法,简化MR开发原创 2020-09-16 18:25:29 · 240 阅读 · 0 评论 -
MapReduce原理
什么是MapReduce?MapReduce是一个分布式计算框架它将大型数据操作作业分解为可以跨服务器集群并行执行的单个任务。起源于Google适用于大规模数据处理场景每个节点处理存储在该节点的数据每个job包含Map和Reduce两部分MapReduce的设计思想分而治之简化并行计算的编程模型构建抽象模型:Map和Reduce开发人员专注于实现Mapper和Reducer函数隐藏系统层细节开发人员专注于业务逻辑实现MapReduce特点原创 2020-09-15 22:12:17 · 123 阅读 · 0 评论 -
Hive安装配置
Hive安装配置Hive理论Hive安装配置Hive理论1、Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。2、Hvie是建立在Hadoop上的数据仓库基础架构。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存原创 2020-09-15 19:52:33 · 180 阅读 · 0 评论 -
HBase安装配置
HBase安装配置HBase理论一级目录HBase理论HBase1、Hbase是hadoop领域的的数据库2、Hbase是面向列存储的列式数据库1)行式数据库优缺点a、数据在表中的位置空间是确定的,指针在访问只要知道首地址就可以高效获取其他数据b、但在常用的可能只是所有列中的部分列的数据,可是行式数据库会自动查询所有的列,只是在客户端进行数据的过滤,会浪费大量的带宽和空间2)列式数据库的优缺点a、一张不规则的表(人物画像)每行属性有大量的nullb、类似于交错数组,只使用在特原创 2020-09-15 19:41:06 · 135 阅读 · 0 评论 -
java实现MapRuduce的wordcount方法
Java实现wordcount词频统计需求分析:1.Map过程:并行读取文本,对读取的单词进行map操作,每个词都以<key,value>形式生成2.Reduce操作是对map的结果进行排序合并最后得出词频一、下载安装maven依赖包首先我们需要创建一个maven工程;我们要去到maven的网站去寻找我们hadoop所对应版本各依赖包,下面的是查询的网站;https://mvnrepository.com/我们在网站中直接搜索hadoop,寻找对应的依赖包;在之后就是添原创 2020-09-15 19:24:11 · 290 阅读 · 0 评论 -
分布式应用协调服务ZooKeeper
分布式应用协调服务ZooKeeperZooKeeper简介ZooKeeper数据结构ZooKeeper客户端命令ZooKeeper角色ZooKeeper选举机制ZooKeeper简介ZooKeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目ZooKeeper=文件系统+通知机制ZooKeeper从设计模式上来看是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册一旦数据的状态发生变化,Zookeeper就将负责通知已经在Z原创 2020-09-15 16:41:33 · 73 阅读 · 0 评论 -
分布式资源调度框架YARN
分布式资源调度框架YARNyarn的诞生和概念yarn的基本架构核心组件yarn的工作机制(图解)yarn的资源调度器yarn常用命令yarn的诞生和概念yarn的前世今生hadoop1.x版本中最大的问题是资源问题对数据的处理和资源调度主要依赖MapReduce完成,只能运行MapReduce程序JobTracker负责资源管理和程序调度,压力较大hadoop2.x版本中添加yarn主要负责集群的资源管理,分担MapReduce压力yarn概述yarn(Yet An原创 2020-09-15 16:27:39 · 125 阅读 · 0 评论 -
mapreduce流程图解
原创 2020-09-15 14:48:23 · 114 阅读 · 0 评论 -
hadoop高可用HA集群配置
hadoop HA模式搭建一 、 搭建集群二 、修改配置文件三 、启动集群四 、测试集群是否部署成功一 、 搭建集群Hadoop HA模式搭建前需要完成hadoop集群配置、时区同步设置和zookeeper安装配置二 、修改配置文件修改core-site.xml文件<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://ns</原创 2020-09-10 18:57:46 · 193 阅读 · 0 评论 -
时区同步和zookeeper集群配置
配置集群的时间同步大数据系统是对时间敏感的计算处理系统,时间同步是基础保障,是大数据得以发挥作用的技术支撑,所以需要保证所有机器时间同步!确认是否安装过ntp: rpm -qa | grep ntp,若有的话使用:yum -y remove 相关文件名命令卸载安装ntp: yum -y install ntp修改所有节点的ntp配置文件: vi /etc/ntp.conf,添加如下内容:#当前节点IP地址restrict 192.168.206.33 nomodify notra原创 2020-09-09 17:21:43 · 151 阅读 · 0 评论 -
ELK集群搭建
复制虚拟机克隆2台虚拟机修改主机名和主机列表1.网络地址 (1)输入:vi /etc/sysconfig/network-script/ifcfg-enp0s3 修改网络ip地址2.主机名 (1)hostnamectl set-hostname test01 (2)vi /etc/hostname 内容修改为test013.主机列表 (1)vi /etc/hosts 内容增加 主机的ip地址 主机名配置免密登录1.ssh-keygen -t rsa -P ""原创 2020-09-08 14:05:11 · 87 阅读 · 0 评论 -
hadoop与java交互
Maven工程:<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.6.0</version></dependency><dependency> <groupId>org.apache.hadoop</groupI原创 2020-09-05 14:45:13 · 227 阅读 · 0 评论 -
hadoop安装和基本配置
Hadoop安装1.Jdk(建议使用JDK 1.8.11)2.Tar hadoop.tar.gz(建议使用Hadoop 2.7.3)3.配置环境变量export JAVA_HOME=/usr/local/softwave/jdk1.8.0_111export PATH=JAVAHOME/bin:JAVA_HOME/bin:JAVAHOME/bin:PATHexport CLASSPATH=.:JAVAHOME/lib/dt.jar:JAVA_HOME/lib/dt.jar:JAVAHOME/原创 2020-09-03 16:17:28 · 134 阅读 · 0 评论