






一 hive 是什么
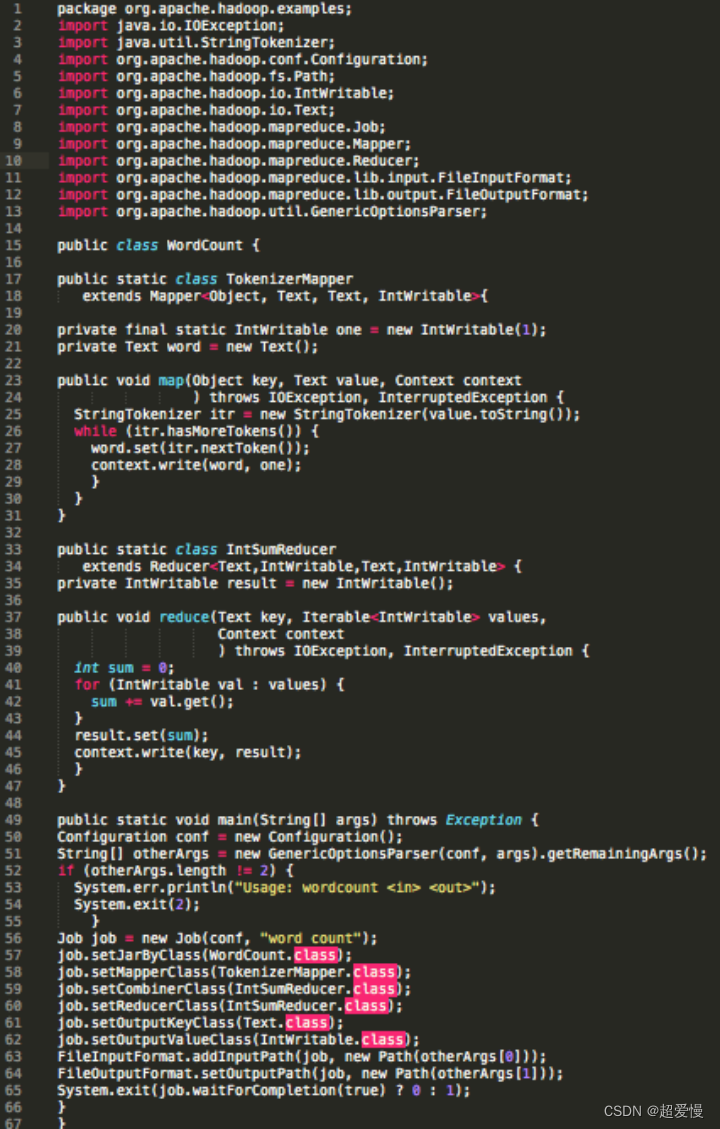
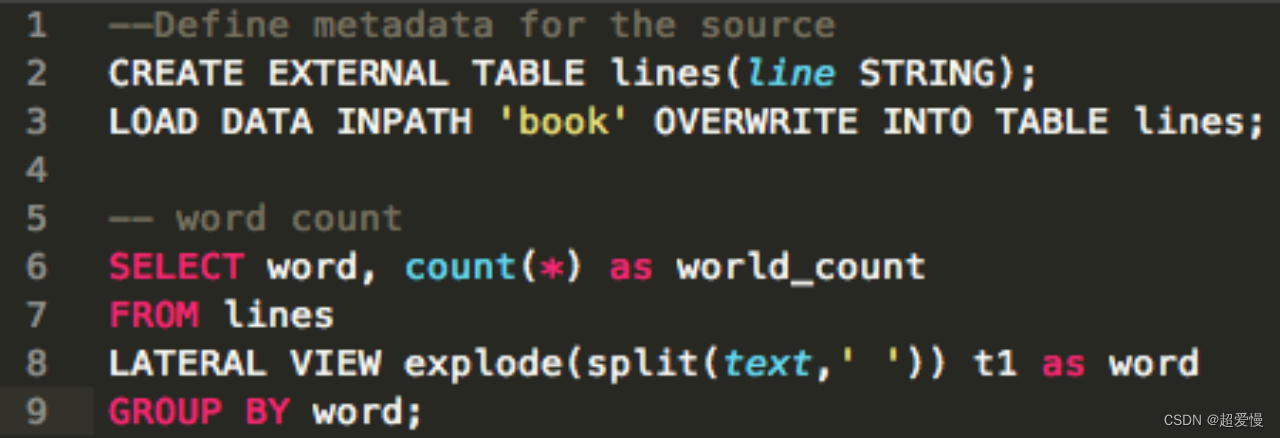
在本节前我们需要明确 hive 是什么
上面两个代码块,左边的是 mapreduce 的代码块,右边的是hive 的代码块
很容易看出来,右边的 hive 写起来要更容易更快些,而执行效率,右边的 hive 只比左边多一个翻译的过程,就是将写的 HQL语句 翻译成 mapreduce 去执行
简单来说 hive 就是一个中间件,可以让我们写的 HQL 语句可以被翻译成 mapreduce去执行,让我们不必再去写 mapreduce 的代码,提升我们的开发效率
二 Hive的优势和特点
- 提供了一个简单的优化模型
- HQL类SQL语法,简化MR开发
- 支持在不同的计算框架上运行
- 支持在HDFS和HBase上临时查询数据
- 支持用户自定义函数、格式
- 常用于ETL操作和BI 稳定可靠(真实生产环境)的批处理
- 有庞大活跃的社区
三 Hive的发展里程碑和主流版本
Hive发展历史及版本
- 07年8月 – 始于Facebook
- 13年5月 – 0.11 Stinger Phase 1 ORC HiveServer2
- 13年10月 – 0.12.0 Stinger Phase 2 - ORC improvement
- 14年4月 – Hive 0.13.0 as Stinger Phase 3
- 14年11月 – Hive 0.14.0
- 15年2月 – Hive 1.0.0
- 15年5月 – Hive 1.2.0 (1.2.1 本系列课实验重点版本 )
- 16年2月 – Hive 2.0.0 (添加 HPLSQL, LLAP)
- 16年6月 – Hive 2.1.0
四 Hive元数据管理
- 记录数据仓库中模型的定义、各层级间的映射关系
- 存储在关系数据库中
- 默认Derby, 轻量级内嵌SQL数据库
- Derby非常适合测试和演示
- 存储在.metastore_db目录中
- 实际生产一般存储在MySQL中
- 修改配置文件hive-site.xml
- 默认Derby, 轻量级内嵌SQL数据库
- HCatalog
- 将Hive元数据共享给其他应用程序
五 Hive环境搭建
- 环境准备
- 安装jdk、hadoop、mysql(元数据管理使用)
- 主要步骤
- 下载并解压
- 配置环境变量
- 修改配置文件
- 配置hive元数据管理
- 启动验证
安装 hive 查看
在 linux 虚拟机上安装配置 hive_超爱慢的博客-CSDN博客
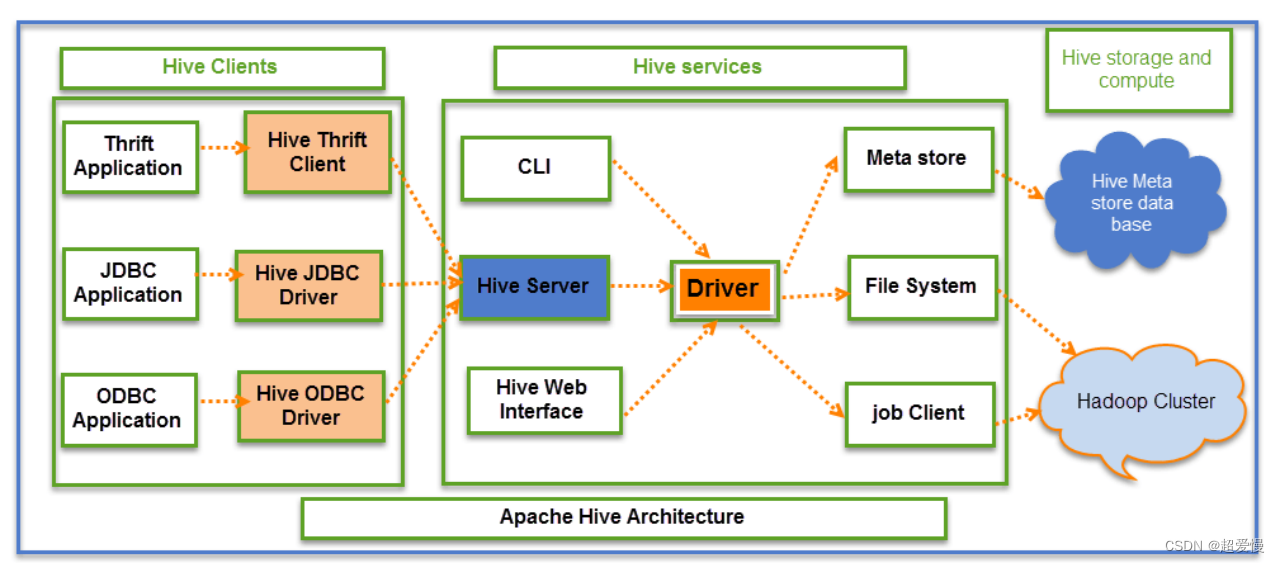
六 hive 架构
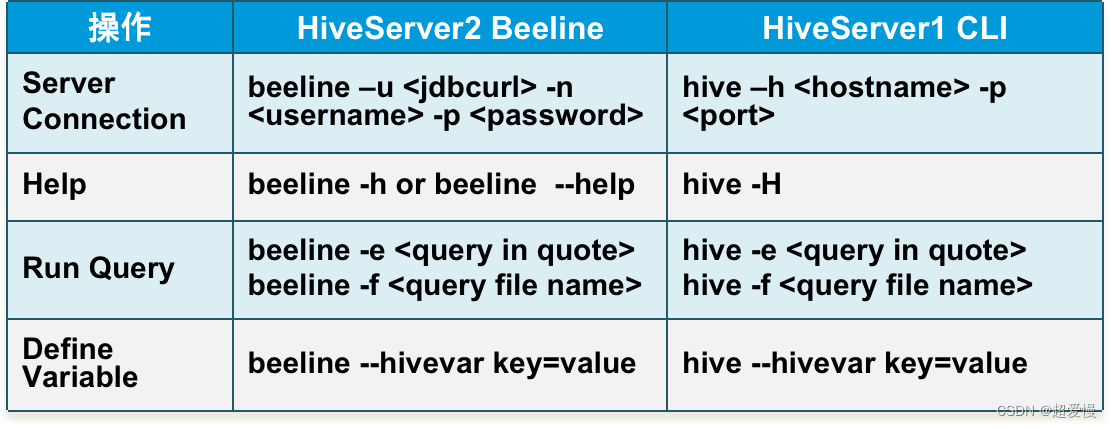
七 Hive操作-命令行模式
- 有两种客户端工具:Beeline和Hive命令行(CLI)
- 有两种模式:命令行模式和交互模式
- 命令行模式
八 Hive操作-窗口交互模式
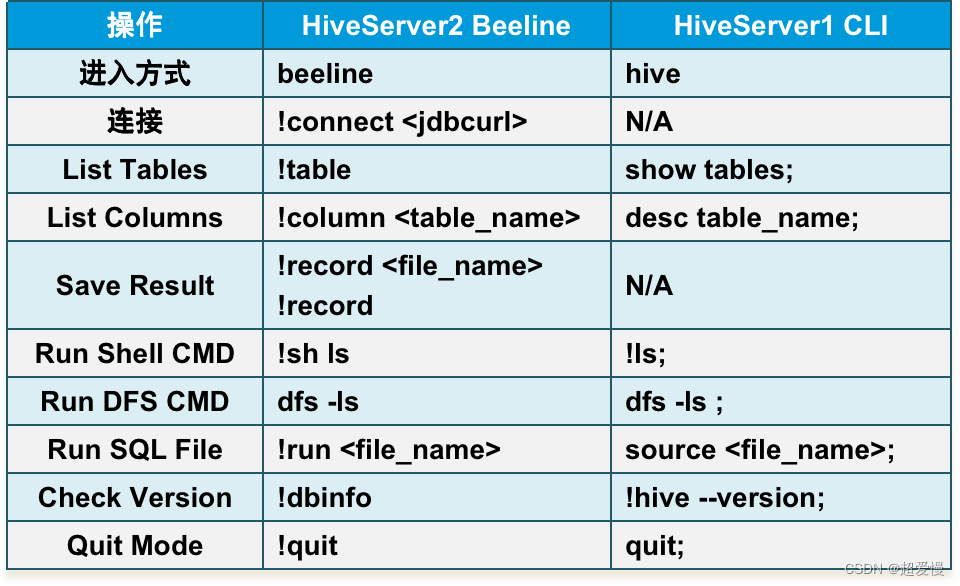
九 Hive操作-客户端交互模式
- 检查Hive服务是否已经正常启动
- 使用Hive交互方式(输入hive即可)
- 使用beeline
- 需启动hiveserver2服务
- nohup hive --service metastore &(非必须)
- nohup hive --service hiveserver2 &
- 输入beeline进入beeline交互模式
- !connect jdbc:hive2://hadoop101:10000
- 需启动hiveserver2服务















 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









