






NoSQL-Not Only SQL
NoSQL 指的是非关系型数据库,是对不同于传统的关系型数据库的数据库管理系统的统称,用来存储相互之间没有联系的数据,如新闻,在大数据时代十分好用,NoSQL是web2.0时代海量数据催生的产物
特点
- 不支持SQL语法:
NoSQL的世界中没有一种通用的语法,每种NoSQL数据库都有自己的语法,以及擅长的业务场景 - 读写性能高(相对于传统关系型数据库而言)
NoSQL 数据库存在于内存当中,都具有非常高的读写性能,尤其在海量数据下,它的表现非常优秀 - 灵活的数据模型
NoSQL的存储方式十分灵活,存储方式可以是JSON文档(MongoDB),键值对(Key Value-----Redis)或者其他方式
4.NoSQL是存在于内存中的,具有非常高的读写性能,后台一般会把NoSQL和SQL结合使用,这是因为传统的关系型数据库可以保证数据的完整性,并体现数据之间的关系。
Redis:
Redis 全称: Remote Dictionary Server(远程字典服务器)的缩写,以字典结构存储数据,并允许其他应用通过TCP协议读写字典中的内容。 使用C语言编写,并以内存作为数据存储介质,所以读写数据的效率极高
特点
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用
- Redis不仅仅支持简单的key-value类型的数据,同时还把value分为list,set,zset,hash等数据结构存储
- 因为Redis交换数据快,所以在服务器中常用来存储一些需要频繁调取的数据,提高效率
- redis中只有0~15共16个数据库,不能新建,数据库名不可更改,且以数字命名,默认进来的是0号数据库。
Redis的使用:
打开Redis:
打开Redis的服务:

本地连接Redis:
远程连接Redis:

选择不同的数据库:

设置键值对
设置单个

同时设置多个

获得键对应的值
获得单个值

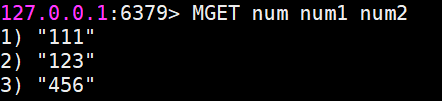
同时获得多个值
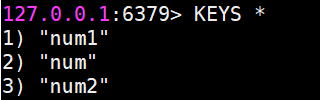
获得该库内所有值
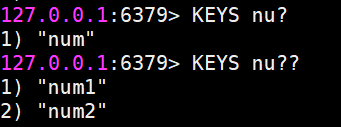
选择性获得该库内的值:
*号表示匹配n之后所有的字符,这里的ddd和ccc都不会被获取到:

一个?表示一个字符,两个?表示两个字符:
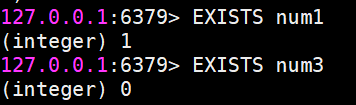
查看该键对应的值是否在(1代表存在,0代表不存在)
重命名键的名字

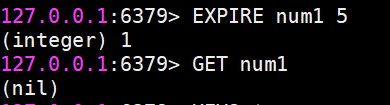
设置键的存活时间,单位为秒,时间结束就自动删除掉这个键值对。
在初始化的时候就设置yzm的生命周期为60

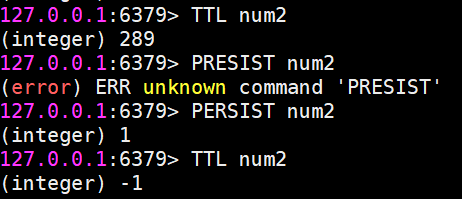
检查该键当前状态(-1代表永久存在,-2代表不存在,返回其他值代表当前生命剩下的时间,单位为秒数)

将一个正在倒数的键值对设置为永久:
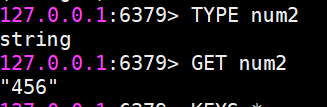
查看当前键对应的类型:
值在用SET关键字初始化的时候,类型会自动设置为string:
删除键值对
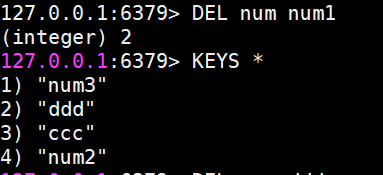
DEL命令的参数不支持通配符,但我们可以结合Linux的管道和xargs命令自己实现删除所有符合规则的键。比如要删除所有以n开头的键,就可以执行以下操作,先退出Redis,再执行命令,最后重新进入Redis:

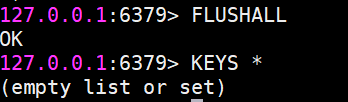
删除所有键值对
Redis 的数据类型
五种数据类型总结

string-SET
字符串是Redis的基本数据类型,使用SET生成的键值对,其value就是字符串类型.。字符串类型可以存储任何形式的字符串
关于字符串类型的方法:
SET num 1 #默认SET方法设置num为字符串类型
APPEND num2 # 往字符串后面追加字符
如果value值是数字,还可以进行加减
INCR num # 加 1
DECR num # 减 1
- 加上一个整数
INCRBY num 10
- 减去一个整数
DECRBY num 5
列表-list
添加元素
LPUSH 左边添加 (栈 先进后出)
LPUSH myli 3 4 5
加进去之后顺序为5 4 3
RPUSH 右边添加 (队列 先进先出)
RPUSH myli 2 1
加进去之后顺序为2 1
获取列表长度
LLEN myli
利用下标查看指定位置元素
LINDEX myli 3
获取列表片段
LRANGE myli 0 5
LRANGE myli 0 -1
-1 表示最后一个
删除元素
LPOP myli # 从左边删除元素
RPOP myli # 从右边删除元素
LREM key count value
LREM myli 2 1 # 当count>0时LREM命令会从列表左边开始删除前count个值为value的元素
LREM myli -1 2 # 当count<0时LREM命令会从列表右边开始删除前 | count | 个值为value的元素
LREM myli 0 4 # 当count=0是LREM命令会删除所有值为value的元素
哈希类型-hash
我们现在已经知道Redis是采用字典结构以键值对的形式存储数据的,而散列类型(hash)的键值也是一种字典结构,其存储了字段(field)和字段值的映射,但字段值只能是字符串,不支持其他数据类型,换句话说,散列类型不能嵌套其他的数据类型。一个散列类型键可以包含至多232−1个字段。

设置和获取
HSET key field value # 设置单个
HSET bd name budong
HSET bd age 18
HGET key field # 获取单个
HGET bd name
HMSET key field value [field value … ]
HMSET ks name kongshan age 18 # 设置多个
HMGET key field [ field … ]
HMGET ks name age # 获取多个
HKEYS bd # 获取所有keys
HVALS bd # 获取所有value
HGETALL key
HGETALL bd # 获取所有key 和 value
HLEN bd # 获取filed 个数
判断字段是否存在
HEXISTS key field
HEXISTS bd size # 存在返回1 不存在返回0
HSETNX bd size 180 # 不存在时添加,存在什么也不做
增加数字
HINCRBY key field increment
HINCRBY bd age 2
删除字段
HDEL key field [field…] # 删除一个/多个字段
HDEL bd size
集合-set(无序)
增加、查找 和 删除元素
SADD key member [member …] # 增加元素
SADD se1 1 2 3 a b
SADD se2 a b c 1 2
SREM key member [member …] # 删除元素
SREM se1 2 # 删除指定元素
SPOP key [cout] # 随机删除count个元素
SPOP se2 2 # 随机删除2个元素
SISMEMBER se1 1 # 判断元素是否存在
SMEMBERS key # 获取所有元素
SMEMBERS se1
SCARD key # 获取集合元素个数
SCARD se1
随机获取count 个数值,元素 count 为正数,返回count个不重复数,为负数可能出现重复数据
SRANDMEMBER key [count]
SRANDMEMBER se2 3
交集
SINTER key1 key2 …
SINTER se1 se2 # 求se1 和 se2 交集
SINTERSTORE destination key1 key2 …
SINTERSTORE se3 se1 se2 # 将交集保存到 se3中
并集
SUNION key1 key2
SUNION se1 se2 # 直接输出并集
SUNIONSTORE destination key1 key2
SUNIONSTORE se4 se1 se2 # 将并集保存到se4
差集
SDIFF key1 key2
SDIFF se1 se2 # 直接输出差集
SDIFFSTORE destination key1 key2
SDIFFSTORE se5 se1 se2 # 将差集保存到se5
有序集合ZSET
在集合类型的基础上有序集合类型为集合中的每个元素都关联了一个分数,这使得我们不仅可以完成插入、删除和判断元素是否存在等集合类型支持的操作,还能够获得分数(score)最高(或最低)的前N个元素、获得指定分数范围内的元素等与分数有关的操作。虽然集合中每个元素都是不同的,但是它们的分数(score)却可以相同
与其他类型的特点和差别:
(1)列表类型是通过链表实现的,获取靠近两端的数据速度极快,而当元素增多后,访问中间数据的速度会较慢,所以它更加适合实现如“新鲜事”或“日志”这样很少访问中间元素的应用。
(2)有序集合类型是使用散列表和跳跃表(Skiplist)实现的,所以即使读取位于中间部分的数据速度也很快(时间复杂度是O(log(N)))。
(3)列表中不能简单地调整某个元素的位置,但是有序集合可以(通过更改这个元素的分数)。
(4)有序集合要比列表类型更耗费内存。有序集合类型算得上是Redis的5种数据类型中最高级的类型了,在学习时可以与列表类型和集合类型对照理解。
增加、获取和删除 元素
ZADD key score member [score member … ]
ZADD math 90 bd 86 ks 88 yf #前面是分数,后面是值
ZADD 还可以用双精度浮点数,+inf 表示正无穷 -inf 表示负无穷
ZCARD key
ZCARD math # 查看元素个数
ZSCORE key member # 获取元素分数
ZSCORE math bd
从小到大打印 加上WITHSCORES 同时打印分数
ZRANGE key start stop [WITHSCORES]
ZRANGE math 0 -1
ZREVRANGE key start stop [WITHSCORES] # 从大到小打印
ZREVRANGE math 0 -1
ZREM key member # 移除元素
ZREM math yf
获取指定分数范围的元素
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
按照元素分数从小到大的顺序返回分数在min和max之间(包含min和max) LIMIT 向后偏移offset个元素,并且只获取前count个元素
ZRANGEBYSCORE math 70 90
ZRANGEBYSCORE math 70 (90 LIMIT 1 2 # 不取90
获取指定分数范围的元素的个数
ZCOUNT key min max
ZCOUNT math 70 90
增加某个元素的分数
ZINCRBY key increment member
ZINCRBY math 5 bd # 增加5分 分数也可以是负数,表示减分
按照排名范围删除元素
ZREMRANGEBYRANK key start stop
ZADD test 1 a 2 b 3 c 4 d 5 e 6 f
ZREMRANGEBYRANK test 0 2 # 删除排名1到3 的元素,(表示开区间
ZRANGE test 0 -1
按照分数范围删除元素
ZREMRANGEBYSCORE key min max
ZADD test 1 a 2 b 3 c 4 d 5 e 6 f
ZREMRANGEBYSCORE test (3 5 # 删除分数大于3小于5的元素,(表示开区间
计算有序集合的交集
ZINTERSTORE destination numkeys key [key…][WEIGHTS weight[weight…]] [AGGREGATE SUM|MIN|MAX]
计算多个有序集合的交集并将结果存储在destination键中(同样以有序集合类型存储),返回值为destination键中的元素个数。destination键中元素的分数是由AGGREGATE参数决定的,默认是SUM
ZADD s2 10 a 20 b
ZINTERSTORE s3 2 s1 s2 # 2 是指有几个集合交集的意思
此时若s1 和s2 有交集 a ,且各自的分数为3,则在s3中a 的分数会变为 6 。
同样也有并集 ZUNIONSTORE 用法类似,就不在再赘述
















 1129
1129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











