







文章目录
前言

论文地址:https://arxiv.org/abs/2106.15115v1
时间线
1947:Warren Weaver提出了机器翻译的可能性
1954:IBM发明了word-for-word翻译系统
…
技术
归纳低资源机器翻译中用到的技术。
数据增强(data augmentation)
主要包含:1. 基于单词和短语替换产生伪平行语料的方法;2. 基于回译产生伪平行语料的方法;3. 基于多语言预训练模型挖掘平行语料的方法
基于单词、短语替换的数据增强(坑1)
利用双语词典,替换选定句子的所有单词或稀有词,产生对应翻译[119][127]
替换掉target句子中稀有词,进一步对source句子做相应的对齐,产生更多平行语料[47]
为了解决上述方法中伪平行语料流利度不足的问题:
- 选择最好的单词子集进行替换[52][166]
- 替换短语[108]
- 利用词形学、part-of-speech、依存规则[41][157]
缺点:需要外部特定语言的资源,如双语词典、POS taggers、dependency parser等
基于回译的数据增强
回译通常是把target句子翻译回source句子,产生伪平行语料,因为真实的target句子能改善翻译模型的流利度([48]表明从source句子开始效果差)
为了解决回译产生的伪平行句噪声多的问题:
- 迭代式回译(坑2)
- 迭代式完成s2t和t2s[10][72]
- dual-learning等[31][70]
- 统一了两个独立翻译器[191]
- 单语数据选择:选择单语子集[39][48]
- 伪平行句过滤:[77][78]
- 区分真、伪平行句:
- 增加标签以区分[21][85][115]
- 根据句子的质量来分配权重以区分[39][85][163]
- 采样:为一个target句子生成多个source句子来均衡错误[58][75]
缺点:
- 需要一个初始MT
- 依赖于真、伪平行句的比例
- 依赖于真平行句和单语的领域相关度
平行语料挖掘
第一步是生成多语对齐的向量空间
- 利用NMT任务有监督地训练encoder-decoder:
- 对偶编码器[64][179]
- 共享的多语encoder-decoder架构[140][11]
- 无监督[95]
- self-learning[138]
- 利用多语预训练模型(mBERT\XLM-R)[2][84][155][184]
第二步是句子相似度排序,利用基于cosine的无监督相似度、有监督的相似度度量。
缺点:
- 多语预训练模型方法只作用于出现过的语言
无监督机器翻译(unsupervised NMT)
包含三个步骤:1. 初始化;2. 回译;3. 判别分类器
缺点:
- 先前的工作都是在有丰富单语资源的语言上研究,而没有探索:1. 极端低资源(没有丰富单语资源的语言);2. 语种不相似的语言对;3. 领域不相似的设置;4. 不同的数据集
上述缺点的解决:
- 去除encoder端的language embedding,让encoder更加language\domain agnostic[87](问题2、3)
- 利用迁移学习(先在HRL上pretrain,再在LRL上finetune)缓解HRL-LRL之间的翻译[26](问题1、2)
初始化
利用不同的语言资源:
- 双语词典[9][42][100][102]
- word-by-word gloss[131](用语言模型来选择更好的word-by-word translation)
利用不同的神经表示策略:
- 使用对齐的双语单词嵌入[9][42][100]
- Joint BPE[102]
- 多语语言模型
- 掩膜token预测之[29]
- 掩膜n-grams预测对应的翻译[136]
回译
研究发现,相比于双语,多语初始化的模型能带来更好的回译效果[53][105][143][154][162]
判别分类器
使用对抗策略:
- cycle-GAN[8]
- local-global GAN[182]
增加额外的损失函数:
- 单词嵌入一致(word embedding agreement)[153]
- 编辑和抽取[173]
- comparative translations(类似于引入判别器D和映射矩阵W,同时训练,希望D区分,W混淆)[153]
半监督机器翻译(semi-supervised NMT)
缺点:
- 先前研究通过从高资源语言中提取部分来模拟低资源场景
- 先前研究用了过分多的单语
- 大多数研究只和BT比
使用单语来产生伪平行语料
回译
使用单语来产生语言模型
利用语言模型的不同策略:
- 语言模型融合(缺点:1. 语言模型和NMT分开训练,且不会被finetune;2. 只被用于decoder端; 3. 深层融合中,只包含了语言模型的最高层,忽略了低层的特征;4. NMT模型需要被改变):
- 浅层融合:语言模型用于给NMT decoder端的输出单词打分[63][147][151]
- 深层融合:NMT decoder端包含了额外的语言模型
- 把语言模型当作一个弱信息先验[15]
- 把BERT融入NMT(也可视为fusion?)[194]
- 用source embeddings初始化encoder[1]
- 把语言模型作为NMT encoder和decoder的初始化[134]
- seq2seq的多语语言模型预训练
改变NMT训练目标来利用单语(坑3)
- 联合训练s2t和t2s NMT,整体作为autoencoder,引入重构目标[23]
- 回译的初始形态(EM+MLE)[188]
多任务学习
- 使用1个encoder+2个decoder,同时完成翻译和倒序重排任务[186]
- 使用1个RNN decoder,同时完成翻译和预测下一个target单词任务[37]
- 同时完成1. s2t NMT;2. t2s NMT;3. LM[192](坑4)
对偶学习
和回译类似,但模型优化基于强化学习[70][168][174]
多语言机器翻译(multilingual NMT)
缺点:
- 语言之间有很大差异
- 平行语料的噪声
- 数据不平衡
- 其它如书写风格、话题的因素
- 先前工作没有关注特定语言,利用特定语种特性
有监督的多语言机器翻译有三种模型架构:
- 1encoder1decoder:最大的挑战是让decoder区分要翻译的语言,主要方法有:
- 语言识别标签[18][66][80][170]
- 语言名称[67]
- 语言独立的位置嵌入[170][172][193]
- NencoderNdecoder:挑战变为了从不同语言中学习通用信息,主要方法有:
- 共享attention[50][110][133][161]
- 基于source和target的参数生成器[129]
- 1\NencoderN\1decoder:
- 1encoderNdecoder:decoder端的部分参数共享[139][171]
- Nencoder1decoder:N个encoder端的输出需要合并输入到decoder,解决策略有:
- 把不存在的语言句子用null表示[124]
- 用预训练模型生成缺的语言[123]
多语言机器翻译用于低资源机器翻译有几种应用场景:1. 有监督的机器翻译;2. 无监督的机器翻译;3. 半监督的机器翻译;4. 基于预训练多语言模型的迁移学习。
有监督的多语言机器翻译
解决低资源和高资源数据不平衡的问题:
- 采样:上采样+基于温度的采样[6][50][164][167]
- mini-batch的设置:
- 按语言对依次训练[50]
- mini-batch包含不同的语言对[80][139]
- mini-batch包含target相同的语言对[18]
无监督的多语言机器翻译
- 和无监督的双语机器翻译不同的初始化方式:non-english被映射到english的向量空间[143]
- 增强back-translation:知识蒸馏[154]
- 利用少量的、非目标语言对的平行语料[53][105][162]
半监督的多语言机器翻译
和半监督机器翻译一样,也是探究如何利用单语:
- 使用mass[149]训练目标[146]
- source端使用MLM,target端使用denoising autoencoding[169]
基于预训练多语言模型的迁移学习
[35][60][61][97][121]
不一定是预训练,也有改进多语言模型在低资源语言上的性能[60]
输入的表示(坑5)
- surface form representation:
- 单词+language token[66]
- 单词+POS[46]
- subword(BPE[80][139]、sentence piece representation[6]、transliteration[57][112])
- embedding-based representation:
- 使用预训练模型(mBERT[109])
- 其它:[60][165]
迁移学习
- 分类1(使用child parallel data的时机):
- 热启动(parent model训练时,就利用child parallel data):[36][90][113][122][196]
- 冷启动(反之,更接近于真实场景):[86][91][97]
- 分类2(parent model的种类):
- 双语(大多数是)
- 多语:
- many2one场景[35][60][61][97][121]
- mBART[30]
- 分类3(child model的种类):
- 双语(大多数是)
- 多语[97]
- 分类4(parent 、child model的关系):
- 相同的target语言[4][36][86][113][118][122][196]
- 相同的source语言[91]
- 不相同[90][111][112]
有以下改进的方向:1. 缩小语言间空间不匹配;2. finetune策略; 3. 迁移策略;4. parent模型
影响性能的因素:
- parent language和child language之间的相关度,进一步影响词表的重叠。策略:
- 使用子词
- 控制child的子词不被parent的压倒[90][121]
- 对于相关的语言,直译(transliteration)可减少词性的分歧[57][112][122]
- 重排parent数据,可减少句法的分歧[86][118]
- 语料大小
- 域
- language script(坑6)
缩小语言间空间不匹配
- 热启动:
- 对parent和child training data构建联合词典[35][121]
- 构建通用词汇表
- 冷启动:
- 动态词表[97]
- 预训练一个通用的输入表示(其中包含了child单语数据)[60][79][86]
finetune策略
- 不finetune:[4][79]
- finetune嵌入层:
- parent和child model翻译相同的target语言:直接 transfer[196]
- 不相同:计算词表重叠部分,把剩余的替换成child vocabulary[97][122]
- finetune整个parent model:[79][91][97][112]
- finetune部分层:[4][86][91][196]
迁移策略
- 迁移一系列NMT model[97]
- parent | parent + children | child[35][113]
- 在parent data上训练parent model
- 在parent data+child data(可能有多个目标child)上finetune child model
- 最后再在选定的child data上finetune child model
- parent | intermediate | child[76][111]
- 在unrelated parent data上训练parent model
- 再在相似的中间语言上finetune
- 最后再在child data上finetune
parent模型
parent模型为multi-NMT性能往往更好[86][97][112][113]
parent模型为multi-NMT+迁移到child vs 直接合并parent和child训练一个multi-NMT的性能有待进一步研究
zero-shot机器翻译
有几种解决方式:1. pivot;2. 迁移学习; 3. multi-NMT; 4. 无监督
pivot
s-p for source-pivot | p-t for pivot-target
提升性能:
- 减少级联错误:
- 训练期间通过共享pivot language embedding来让s-p和p-t产生关联[24]
- 迁移学习:使用s-p的encoder和p-t的decoder初始化s-t[88]
- 使用s-p平行语料来指导p-t的训练[22]
- 把训练目标从1. s-p和p-t独立的极大似然估计 改变为 2. p-t在p-s上的极大期望似然估计[190](坑7)
- 利用平行语料:
- 真[22][[24][88][135]
- 伪
缺点:
- 先前工作对于s-p和p-t使用大量平行语料,不符合真实场景
- 语言之间的相关性很重要
迁移学习
- 首先利用s-p数据预训练一个通用编码器,来对p-t NMT做初始化
- 然后利用p-t数据训练
- 最后直接在s-t上推理[79]
multi-NMT
按照文章的理解:如果multi-NMT真的学习到了一个国际语,source和target语言之间应当会有更少的联系,每一种语言都有language-specific的参数,把它转换成国际语。然而,目前面临参数量过少,不同语言共用部分参数的问题。解决方法:
- 显式地使得source和target不相关[6][62][128][145](坑8)
- 提高模型的容量[49][185]
- 使用pivot或bt来为zero-shot language pair构造伪平行句
无监督
上述无监督机器翻译可以看作是zero-shot的特例
趋势
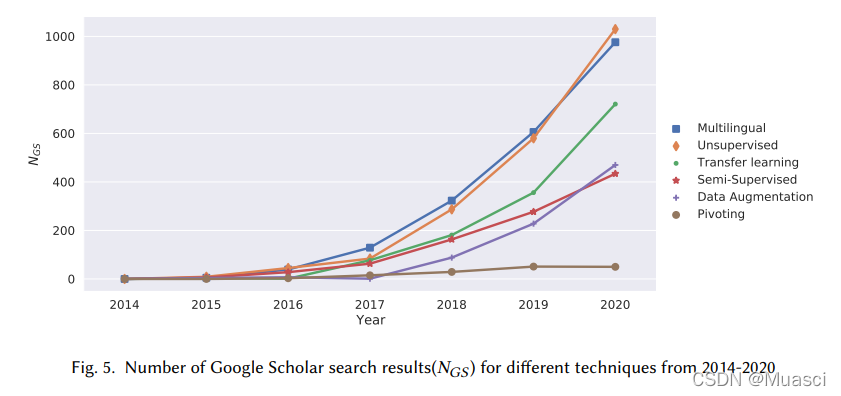
发展大方向
- 模型
- 大模型(massive multilingual NMT)[3][6][49]:massive多语言模型是大势所趋,存在1. 模型容量不够,无法包含足够多语言;2. 提升低资源语言的性能的同时,会损害高资源语言等问题
- 模型鲁棒性[4][6][44]:受到1. 数据集大小;2. 数据集域(不符合真实场景); 3. 语言相关度(句法、code-mixed data)的限制
- 模型可解释性[80][94][189]
- 消除偏见[104][152]
- 资源
- 数据集创建
- 开源框架
- 模型可利用
- 计算资源可利用
总结
低资源机器翻译主要涉及了:数据增强、无监督\半监督\多语言\zero-shot机器翻译、迁移学习。个人感觉:机器翻译的场景可分为:有监督、zero-shot、无监督、半监督,可用到的方法论有:多语言机器翻译、数据增强、zero-shot、对偶学习等。
比较特别的是:多语言机器翻译可能早些时候是一个机器翻译的场景,但实验发现,它能够帮助到有监督、zero-shot、无监督、半监督这一系列的机器翻译场景,逐渐演变为了一种方法论。
多语言机器翻译是大势所趋,虽然已经有了比较多的工作,但也存在很多方向待改进:
- 多语言预训练模型的训练目标与NMT任务不匹配问题(MASS\MBART…)
- 模型容量问题(LASS\SHARE OR NOT SHARE)
- 词表不重叠导致向量空间不对齐问题(BPE…)
- 翻译方向指示问题(language tag\language name\language embedding…)
- …
生词
- tremendous:巨大的
- spurt of growth:喷涌式增长
- pivotal:关键的
- societal:社会的
- prominent:重要的、突出的
- ample:充足的
- specification:规格
- a catalogue of:一系列
- elevate:提升
- initialtive:工作
- irrespective of:不管不顾
- resource-intensive:资源密集的


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









