







文章目录
前言
fairseq给出的preprocess代码只支持一个语言对的binarize,而笔者在[机器翻译] 记一次多语言机器翻译模型的训练想要对多个语言对同时进行binarize,过程中能够创建一个共享的词典。
和师兄交流之后,实现这一结果有两种方式:1. 在使用sentencepiece学习bpe之后,就会得到一个共享词表,需要对这个词表进行一些修改,然后作为binarize的参数;2. 不使用bpe得到的词表,而是做两次binarize,第一次是为每一个语言对进行一次binarize,然后得到不同的词表。接着将这些词表进行合并,作为第二次binarize的参数。
本文内容:
- 本文记录笔者通过对fairseq-preprocess流程的理解,参考https://github.com/RayeRen/multilingual-kd-pytorch/blob/master/preprocess_universal.py,实现更加简便的、一步到位的多个语言对binarize流程。
- 当然,本文也给出了上面所说的第一种的预处理方式。(关于第二种,随缘补充)
内容1基于subword-nmt进行bpe;内容2基于sentence-piece进行bpe。
multilingual fairseq-preprocess1(iwslt14_preprocess_subwordnmt_new_version)
方法简介
该方法通过对fairseq.fairseq_cli.preprocess.py的理解,修改得到一个用于multilingual fairseq-preprocess的代码。
[机器翻译] 记一次多语言机器翻译模型的训练中也记录了类似过程,但由于那个版本(iwslt14_preprocess_old_version)中使用的fairseq版本太老,一般不适用于新版本的fairseq,所以下面给出了解决方案,主要是修改了preprocess_multilingual.py的代码。
脚本运行
bash prepare-iwslt14.sh
具体实现
具体来说,首先在当前目录下创建预处理脚本文件:prepare-iwslt14.sh和preprocess_multilingual.py,这两个文件各自的代码如下:
- prepare-iwslt14.sh(这部分和[机器翻译] 记一次多语言机器翻译模型的训练基本一致,除了最后一行,调用了不一样的preprocess_multilingual.py)
#!/usr/bin/env bash
#
# Adapted from https://github.com/facebookresearch/MIXER/blob/master/prepareData.sh
echo 'Cloning Moses github repository (for tokenization scripts)...'
git clone https://github.com/moses-smt/mosesdecoder.git
echo 'Cloning Subword NMT repository (for BPE pre-processing)...'
git clone https://github.com/rsennrich/subword-nmt.git
SCRIPTS=mosesdecoder/scripts
TOKENIZER=$SCRIPTS/tokenizer/tokenizer.perl
LC=$SCRIPTS/tokenizer/lowercase.perl
CLEAN=$SCRIPTS/training/clean-corpus-n.perl
BPEROOT=subword-nmt
BPE_TOKENS=30000
prep=iwslt14.tokenized
tmp=$prep/tmp
orig=orig
rm -r $orig
rm -r $tmp
rm -r $prep
mkdir -p $orig $tmp $prep
for src in ar de es fa he it nl pl; do
tgt=en
lang=$src-en
echo "pre-processing train data..."
for l in $src $tgt; do
if [[ ! -f $src-en.tgz ]]; then
wget https://wit3.fbk.eu/archive/2014-01//texts/$src/en/$src-en.tgz
fi
cd $orig
tar zxvf ../$src-en.tgz
cd ..
f=train.tags.$lang.$l
tok=train.tags.$lang.tok.$l
cat $orig/$lang/$f | \
grep -v '<url>' | \
grep -v '<talkid>' | \
grep -v '<keywords>' | \
sed -e 's/<title>//g' | \
sed -e 's/<\/title>//g' | \
sed -e 's/<description>//g' | \
sed -e 's/<\/description>//g' | \
perl $TOKENIZER -threads 8 -l $l > $tmp/$tok
echo ""
done
perl $CLEAN -ratio 1.5 $tmp/train.tags.$lang.tok $src $tgt $tmp/train.tags.$lang.clean 1 175
for l in $src $tgt; do
perl $LC < $tmp/train.tags.$lang.clean.$l > $tmp/train.tags.$lang.$l
done
echo "pre-processing valid/test data..."
for l in $src $tgt; do
for o in `ls $orig/$lang/IWSLT14.TED*.$l.xml`; do
fname=${o##*/}
f=$tmp/${fname%.*}
echo $o $f
grep '<seg id' $o | \
sed -e 's/<seg id="[0-9]*">\s*//g' | \
sed -e 's/\s*<\/seg>\s*//g' | \
sed -e "s/\’/\'/g" | \
perl $TOKENIZER -threads 8 -l $l | \
perl $LC > $f
echo ""
done
done
echo "creating train, valid, test..."
for l in $src $tgt; do
awk '{if (NR%23 == 0) print $0; }' $tmp/train.tags.$src-$tgt.$l > $tmp/valid.en-$src.$l
awk '{if (NR%23 != 0) print $0; }' $tmp/train.tags.$src-$tgt.$l > $tmp/train.en-$src.$l
cat $tmp/IWSLT14.TED.dev2010.$src-$tgt.$l \
$tmp/IWSLT14.TEDX.dev2012.$src-$tgt.$l \
$tmp/IWSLT14.TED.tst2010.$src-$tgt.$l \
$tmp/IWSLT14.TED.tst2011.$src-$tgt.$l \
$tmp/IWSLT14.TED.tst2012.$src-$tgt.$l \
> $tmp/test.en-$src.$l
done
TRAIN=$tmp/train.all
BPE_CODE=$prep/code
rm -f $TRAIN
for l in $src $tgt; do
cat $tmp/train.en-$src.$l >> $TRAIN
done
done
echo "learn_bpe.py on ${TRAIN}..."
python $BPEROOT/learn_bpe.py -s $BPE_TOKENS < $TRAIN > $BPE_CODE
for src in ar de es fa he it nl pl; do
for L in $src $tgt; do
for f in train.en-$src.$L valid.en-$src.$L test.en-$src.$L; do
echo "apply_bpe.py to ${f}..."
python $BPEROOT/apply_bpe.py -c $BPE_CODE < $tmp/$f > $prep/$f
done
done
done
rm -r text
mkdir -p text/train_data
mkdir -p text/valid_data
mkdir -p text/test_data
cp iwslt14.tokenized/train.en-* text/train_data/
cp iwslt14.tokenized/valid.en-* text/valid_data/
cp iwslt14.tokenized/test.en-* text/test_data/
python preprocess_multilingual.py --pref=text --destdir=data-bin
- preprocess_multilingual.py
#!/usr/bin/env python3
# Copyright (c) Facebook, Inc. and its affiliates.
#
# This source code is licensed under the MIT license found in the
# LICENSE file in the root directory of this source tree.
"""
Data multilingual preprocess: build vocabularies and binarize multilingual training data.
"""
import logging
import os
import shutil
import sys
import typing as tp
from argparse import Namespace
from itertools import zip_longest
import glob
from fairseq import options, tasks, utils
from fairseq.binarizer import (
AlignmentDatasetBinarizer,
FileBinarizer,
VocabularyDatasetBinarizer,
)
from fairseq.data import Dictionary
logging.basicConfig(
format="%(asctime)s | %(levelname)s | %(name)s | %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
level=os.environ.get("LOGLEVEL", "INFO").upper(),
stream=sys.stdout,
)
logger = logging.getLogger("fairseq_cli.preprocess")
#####################################################################
# file name tools
#####################################################################
def _train_path(lang, trainpref):
return "{}{}".format(trainpref, ("." + lang) if lang else "")
def _file_name(prefix, lang):
fname = prefix
if lang is not None:
fname += ".{lang}".format(lang=lang)
return fname
def _dest_path(prefix, lang, destdir):
return os.path.join(destdir, _file_name(prefix, lang))
def _dict_path(lang, destdir):
return _dest_path("dict", lang, destdir) + ".txt"
def dataset_dest_prefix(args, output_prefix, lang):
base = os.path.join(args.destdir, output_prefix)
if lang is not None:
lang_part = f".{args.source_lang}-{args.target_lang}.{lang}"
elif args.only_source:
lang_part = ""
else:
lang_part = f".{args.source_lang}-{args.target_lang}"
return "{}{}".format(base, lang_part)
def dataset_dest_file(args, output_prefix, lang, extension):
return "{}.{}".format(dataset_dest_prefix(args, output_prefix, lang), extension)
#####################################################################
# dictionary tools
#####################################################################
def _build_dictionary(
filenames,
task,
args,
src=False,
tgt=False,
):
assert src ^ tgt
return task.build_dictionary(
filenames,
workers=args.workers,
threshold=args.thresholdsrc if src else args.thresholdtgt,
nwords=args.nwordssrc if src else args.nwordstgt,
padding_factor=args.padding_factor,
)
#####################################################################
# bin file creation logic
#####################################################################
def _make_binary_dataset(
vocab: Dictionary,
input_prefix: str,
output_prefix: str,
lang: tp.Optional[str],
num_workers: int,
args: Namespace,
):
logger.info("[{}] Dictionary: {} types".format(lang, len(vocab)))
binarizer = VocabularyDatasetBinarizer(
vocab,
append_eos=True,
)
input_file = "{}{}".format(input_prefix, ("." + lang) if lang is not None else "")
full_output_prefix = dataset_dest_prefix(args, output_prefix, lang)
final_summary = FileBinarizer.multiprocess_dataset(
input_file,
args.dataset_impl,
binarizer,
full_output_prefix,
vocab_size=len(vocab),
num_workers=num_workers,
)
logger.info(f"[{lang}] {input_file}: {final_summary} (by {vocab.unk_word})")
def _make_binary_alignment_dataset(
input_prefix: str, output_prefix: str, num_workers: int, args: Namespace
):
binarizer = AlignmentDatasetBinarizer(utils.parse_alignment)
input_file = input_prefix
full_output_prefix = dataset_dest_prefix(args, output_prefix, lang=None)
final_summary = FileBinarizer.multiprocess_dataset(
input_file,
args.dataset_impl,
binarizer,
full_output_prefix,
vocab_size=None,
num_workers=num_workers,
)
logger.info(
"[alignments] {}: parsed {} alignments".format(
input_file, final_summary.num_seq
)
)
#####################################################################
# routing logic
#####################################################################
def _make_dataset(
vocab: Dictionary,
input_prefix: str,
output_prefix: str,
lang: tp.Optional[str],
args: Namespace,
num_workers: int,
):
if args.dataset_impl == "raw":
# Copy original text file to destination folder
output_text_file = _dest_path(
output_prefix + ".{}-{}".format(args.source_lang, args.target_lang),
lang,
args.destdir,
)
shutil.copyfile(_file_name(input_prefix, lang), output_text_file)
else:
_make_binary_dataset(
vocab, input_prefix, output_prefix, lang, num_workers, args
)
def _make_all(lang, vocab, args):
lng_pair = f"{args.source_lang}-{args.target_lang}"
_make_dataset( ## iwslt14.tokenized/train.en-ar
vocab, os.path.join(args.pref, "train_data", f"train.{lng_pair}"), "train", lang, args=args, num_workers=args.workers
)
_make_dataset(
vocab, os.path.join(args.pref, "valid_data", f"valid.{lng_pair}"), "valid", lang, args=args, num_workers=args.workers
)
_make_dataset(
vocab, os.path.join(args.pref, "test_data", f"test.{lng_pair}"), "test", lang, args=args, num_workers=args.workers
)
def _make_all_alignments(args):
if args.trainpref and os.path.exists(args.trainpref + "." + args.align_suffix):
_make_binary_alignment_dataset(
args.trainpref + "." + args.align_suffix,
"train.align",
num_workers=args.workers,
args=args,
)
if args.validpref and os.path.exists(args.validpref + "." + args.align_suffix):
_make_binary_alignment_dataset(
args.validpref + "." + args.align_suffix,
"valid.align",
num_workers=args.workers,
args=args,
)
if args.testpref and os.path.exists(args.testpref + "." + args.align_suffix):
_make_binary_alignment_dataset(
args.testpref + "." + args.align_suffix,
"test.align",
num_workers=args.workers,
args=args,
)
#####################################################################
# align
#####################################################################
def _align_files(args, src_dict, tgt_dict):
assert args.trainpref, "--trainpref must be set if --alignfile is specified"
src_file_name = _train_path(args.source_lang, args.trainpref)
tgt_file_name = _train_path(args.target_lang, args.trainpref)
freq_map = {}
with open(args.alignfile, "r", encoding="utf-8") as align_file:
with open(src_file_name, "r", encoding="utf-8") as src_file:
with open(tgt_file_name, "r", encoding="utf-8") as tgt_file:
for a, s, t in zip_longest(align_file, src_file, tgt_file):
si = src_dict.encode_line(s, add_if_not_exist=False)
ti = tgt_dict.encode_line(t, add_if_not_exist=False)
ai = list(map(lambda x: tuple(x.split("-")), a.split()))
for sai, tai in ai:
srcidx = si[int(sai)]
tgtidx = ti[int(tai)]
if srcidx != src_dict.unk() and tgtidx != tgt_dict.unk():
assert srcidx != src_dict.pad()
assert srcidx != src_dict.eos()
assert tgtidx != tgt_dict.pad()
assert tgtidx != tgt_dict.eos()
if srcidx not in freq_map:
freq_map[srcidx] = {}
if tgtidx not in freq_map[srcidx]:
freq_map[srcidx][tgtidx] = 1
else:
freq_map[srcidx][tgtidx] += 1
align_dict = {}
for srcidx in freq_map.keys():
align_dict[srcidx] = max(freq_map[srcidx], key=freq_map[srcidx].get)
with open(
os.path.join(
args.destdir,
"alignment.{}-{}.txt".format(args.source_lang, args.target_lang),
),
"w",
encoding="utf-8",
) as f:
for k, v in align_dict.items():
print("{} {}".format(src_dict[k], tgt_dict[v]), file=f)
#####################################################################
# MAIN
#####################################################################
def main(args):
# setup some basic things
utils.import_user_module(args)
os.makedirs(args.destdir, exist_ok=True)
logger.addHandler(
logging.FileHandler(
filename=os.path.join(args.destdir, "preprocess.log"),
)
)
logger.info(args)
assert (
args.dataset_impl != "huffman"
), "preprocessing.py doesn't support Huffman yet, use HuffmanCodeBuilder directly."
# build shared dictionaries
# target = not args.only_source
train_files = glob.glob('{}/train_data/train.*-*.*'.format(args.pref))
train_files = [f for f in train_files if len(f.split('.')) in [3, 4, 5]]
test_files = glob.glob('{}/valid_data/test.*-*.*'.format(args.pref))
test_files = [f for f in test_files if len(f.split('.')) in [3, 4, 5]]
valid_files = glob.glob('{}/test_data/valid.*-*.*'.format(args.pref))
valid_files = [f for f in valid_files if len(f.split('.')) in [3, 4, 5]]
lng_pairs = set([f.split('/')[-1].split(".")[1] for f in (train_files + test_files + valid_files)])
task = tasks.get_task(args.task)
shared_dictionary = _build_dictionary(
train_files,
task=task,
args=args,
src=True,
)
# save dictionaries
if args.joined_dictionary:
shared_dictionary.save(os.path.join(args.destdir, "dict.txt"))
else:
for lng_pair in lng_pairs:
src, tgt = lng_pair.split('-')
tmp_src_dict_path = os.path.join(args.destdir, f'dict.{src}.txt')
tmp_tgt_dict_path = os.path.join(args.destdir, f'dict.{tgt}.txt')
if not os.path.exists(tmp_src_dict_path):
shared_dictionary.save(tmp_src_dict_path)
if not os.path.exists(tmp_tgt_dict_path):
shared_dictionary.save(tmp_tgt_dict_path)
if args.dict_only:
return
for lng_pair in lng_pairs:
src_and_tgt = lng_pair.split('-')
if len(src_and_tgt) != 2:
continue
src, tgt = src_and_tgt
print("| building: ", src, tgt)
args.source_lang = src
args.target_lang = tgt
_make_all(src, shared_dictionary, args)
_make_all(tgt, shared_dictionary, args)
logger.info("Wrote preprocessed data to {}".format(args.destdir))
def cli_main():
parser = options.get_preprocessing_parser()
parser.add_argument('--pref', metavar='FP', default=None, help='data prefix')
args = parser.parse_args()
main(args)
if __name__ == "__main__":
cli_main()
对于preprocess_multilingual.py的解释
从fairseq.fairseq_cli.preprocess.py中可以看到:
如果提供srcdict或者tgtdict,则会通过task.load_dictionary(args.srcdict)来读取词典。task.load_dictionary的执行流程为:[fairseq.tasks.translation.TranslationTask]->[fairseq.tasks.fairseq_task.FairseqTask.load_dictionary]->[fairseq.data.dictionary.Dictionary.load]->[fairseq.data.dictionary.Dictionary.add_from_file]。
如果不提供dict,则会通过task.build_dictionary来创建词典,[fairseq.tasks.fairseq_task.FairseqTask.build_dictionary代码如下:
d = Dictionary()
for filename in filenames:
Dictionary.add_file_to_dictionary(
filename, d, tokenizer.tokenize_line, workers
)
d.finalize(threshold=threshold, nwords=nwords, padding_factor=padding_factor)
return d
只要把所有语言对的train data都加入到filenames中,就可以直接创建一个共享的词表,接下来只要用这个词表对所有语言对进行binarize就可以了。因此,修改过程如下:
笔者首先将fairseq.fairseq_cli.preprocess.py复制到当前目录一份,然后修改以下3个函数:
cli_main
def cli_main():
parser = options.get_preprocessing_parser()
parser.add_argument('--pref', metavar='FP', default=None, help='data prefix')
args = parser.parse_args()
main(args)
main
def main(args):
# setup some basic things
utils.import_user_module(args)
os.makedirs(args.destdir, exist_ok=True)
logger.addHandler(
logging.FileHandler(
filename=os.path.join(args.destdir, "preprocess.log"),
)
)
logger.info(args)
assert (
args.dataset_impl != "huffman"
), "preprocessing.py doesn't support Huffman yet, use HuffmanCodeBuilder directly."
# build shared dictionaries
# target = not args.only_source
train_files = glob.glob('{}/train.*-*.*'.format(args.pref))
train_files = [f for f in train_files if len(f.split('.')) in [3, 4, 5]]
test_files = glob.glob('{}/test.*-*.*'.format(args.pref))
test_files = [f for f in test_files if len(f.split('.')) in [3, 4, 5]]
valid_files = glob.glob('{}/valid.*-*.*'.format(args.pref))
valid_files = [f for f in valid_files if len(f.split('.')) in [3, 4, 5]]
lng_pairs = set([f.split('/')[-1].split(".")[1] for f in (train_files + test_files + valid_files)])
task = tasks.get_task(args.task)
shared_dictionary = _build_dictionary(
train_files,
task=task,
args=args,
src=True,
)
# save dictionaries
if args.joined_dictionary:
shared_dictionary.save(os.path.join(args.destdir, "dict.txt"))
else:
for lng_pair in lng_pairs:
src, tgt = lng_pair.split('-')
tmp_src_dict_path = os.path.join(args.destdir, f'dict.{src}.txt')
tmp_tgt_dict_path = os.path.join(args.destdir, f'dict.{tgt}.txt')
if not os.path.exists(tmp_src_dict_path):
shared_dictionary.save(tmp_src_dict_path)
if not os.path.exists(tmp_tgt_dict_path):
shared_dictionary.save(tmp_tgt_dict_path)
if args.dict_only:
return
for lng_pair in lng_pairs:
src_and_tgt = lng_pair.split('-')
if len(src_and_tgt) != 2:
continue
src, tgt = src_and_tgt
print("| building: ", src, tgt)
args.source_lang = src
args.target_lang = tgt
_make_all(src, shared_dictionary, args)
_make_all(tgt, shared_dictionary, args)
logger.info("Wrote preprocessed data to {}".format(args.destdir))
_make_all
def _make_all(lang, vocab, args):
lng_pair = f"{args.source_lang}-{args.target_lang}"
_make_dataset( ## iwslt14.tokenized/train.en-ar
vocab, os.path.join(args.pref, f"train.{lng_pair}"), "train", lang, args=args, num_workers=args.workers
)
_make_dataset(
vocab, os.path.join(args.pref, f"valid.{lng_pair}"), "valid", lang, args=args, num_workers=args.workers
)
_make_dataset(
vocab, os.path.join(args.pref, f"test.{lng_pair}"), "test", lang, args=args, num_workers=args.workers
)
multilingual fairseq-preprocess2(iwslt14_preprocess_sentencepiece)
方法简介
该方法在学习bpe之后,就会得到一个共享词表,需要对这个词表进行一些修改,然后作为binarize的参数。
该方法使用sentencepiece进行bpe。
具体实现
generate_split.sh
当前目录有以下文件:

执行下面脚本,完成数据的划分后,得到下面的文件,其中的train.all用于学习sentencepiece:
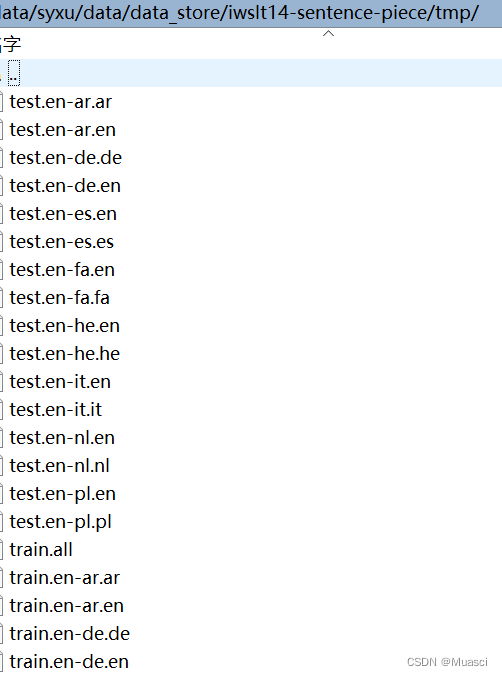
#!/usr/bin/env bash
# Adapted from https://github.com/facebookresearch/MIXER/blob/master/prepareData.sh
echo 'Cloning Moses github repository (for tokenization scripts)...'
git clone git://github.com/moses-smt/mosesdecoder.git
###
# just generate train\test\valid data for iwslt14
# with same simple preprocess steps and without tokenization, because the next step is learn spm
###
SCRIPTS=mosesdecoder/scripts
LC=$SCRIPTS/tokenizer/lowercase.perl
CLEAN=$SCRIPTS/training/clean-corpus-n.perl
tmp=tmp
orig=orig
tgt=en
rm -r $orig
rm -r $tmp
mkdir -p $orig $tmp
for src in ar de es fa he it nl pl; do
lang=$src-en
echo "pre-processing train data..."
for l in $src $tgt; do
if [[ ! -f $src-en.tgz ]]; then
wget https://wit3.fbk.eu/archive/2014-01//texts/$src/en/$src-en.tgz
fi
cd $orig
tar zxvf ../$src-en.tgz
cd ..
f=train.tags.$lang.$l
cat $orig/$lang/$f | \
grep -v '<url>' | \
grep -v '<talkid>' | \
grep -v '<keywords>' | \
grep -v '<transcript>' | \
sed -e 's/<title>//g' | \
sed -e 's/<\/title>//g' | \
sed -e 's/<description>//g' | \
sed -e 's/<\/description>//g' > $tmp/$f
echo ""
done
for l in $src $tgt; do
perl $LC < $tmp/train.tags.$lang.$l > $tmp/train.$lang.$l
rm $tmp/train.tags.$lang.$l
done
echo "pre-processing valid/test data..."
for l in $src $tgt; do
for o in `ls $orig/$lang/IWSLT14.TED*.$l.xml`; do
fname=${o##*/}
f=$tmp/${fname%.*}
echo $o $f
grep '<seg id' $o | \
sed -e 's/<seg id="[0-9]*">\s*//g' | \
sed -e 's/\s*<\/seg>\s*//g' | \
sed -e "s/\’/\'/g" | \
perl $LC > $f
echo ""
done
done
echo "creating train, valid, test..."
for l in $src $tgt; do
mv $tmp/train.$src-$tgt.$l $tmp/train-valid.$src-$tgt.$l
awk '{if (NR%23 == 0) print $0; }' $tmp/train-valid.$src-$tgt.$l > $tmp/valid.en-$src.$l
awk '{if (NR%23 != 0) print $0; }' $tmp/train-valid.$src-$tgt.$l > $tmp/train.en-$src.$l
rm $tmp/train-valid.$src-$tgt.$l
cat $tmp/IWSLT14.TED.dev2010.$src-$tgt.$l \
$tmp/IWSLT14.TEDX.dev2012.$src-$tgt.$l \
$tmp/IWSLT14.TED.tst2010.$src-$tgt.$l \
$tmp/IWSLT14.TED.tst2011.$src-$tgt.$l \
$tmp/IWSLT14.TED.tst2012.$src-$tgt.$l \
> $tmp/test.en-$src.$l
rm $tmp/IWSLT14.TED*.$src-$tgt.$l
done
TRAIN=$tmp/train.all
for l in $src $tgt; do
cat $tmp/train.en-$src.$l >> $TRAIN
done
done
echo "counting..."
for src in ar de es fa he it nl pl; do
for split in train valid test; do
for l in $src $tgt; do
wc -l $tmp/$split.en-$src.$l
done
done
done
echo "done"
learn_and_encode_spm-iwslt14.sh
学习spm,并apply,得到下面文件,用于binarize。
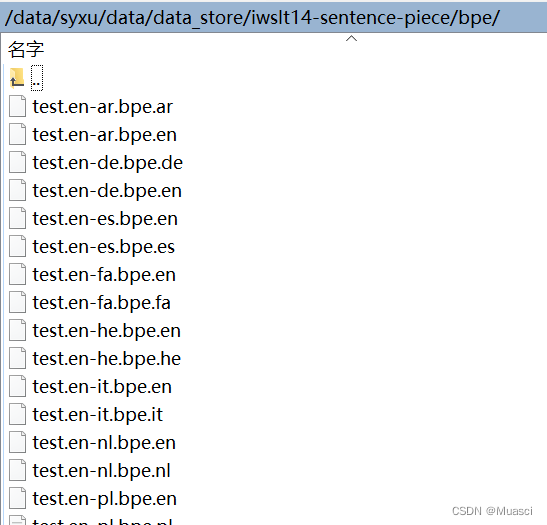
#!/usr/bin/env bash
echo 'Cloning fairseq repository...'
git clone git@github.com:facebookresearch/fairseq.git
# learn bpe
bpe=bpe
tmp=tmp
tgt=en
SCRIPTS=mosesdecoder/scripts
CLEAN=$SCRIPTS/training/clean-corpus-n.perl
rm -r $bpe
mkdir -p $bpe
python -u fairseq/scripts/spm_train.py \
--input=$tmp/train.all \
--model_prefix=spm.bpe \
--vocab_size=30000 \
--character_coverage=1.0 \
--model_type=bpe \
--num_threads=45 \
--shuffle_input_sentence
# apply bpe
for split in train valid test; do
for src in ar de es fa he it nl pl; do
echo ${split} en-${src}
python fairseq/scripts/spm_encode.py \
--model spm.bpe.model \
--output_format=piece \
--inputs ${tmp}/${split}.en-${src}.${src} ${tmp}/${split}.en-${src}.en \
--outputs ${bpe}/${split}.en-${src}.bpe.unclean.${src} ${bpe}/${split}.en-${src}.bpe.unclean.en
perl $CLEAN -ratio 1.5 ${bpe}/${split}.en-${src}.bpe.unclean ${src} en ${bpe}/${split}.en-${src}.bpe 1 256
rm ${bpe}/${split}.en-${src}.bpe.unclean.*
done
done
binarize.sh
#!/usr/bin/env bash
# create share dict
path=data-bin
rm -r $path
mkdir -p $path
# https://github.com/facebookresearch/fairseq/issues/2110#issue-614837309
cut -f1 spm.bpe.vocab | tail -n +4 | sed "s/$/ 100/g" > $path/dict.txt
#for lang in ar de es fa he it nl pl en; do
# cp $path/dict.txt $path/dict.${lang}.txt
#done
for src in ar de es fa he it nl pl; do
echo en-${src}
fairseq-preprocess \
--source-lang $src --target-lang en \
--trainpref bpe/train.en-${src}.bpe \
--validpref bpe/valid.en-${src}.bpe \
--testpref bpe/test.en-${src}.bpe \
--destdir $path \
--srcdict $path/dict.txt \
--tgtdict $path/dict.txt
done
参考
https://github.com/RayeRen/multilingual-kd-pytorch/blob/master/data/iwslt/raw/prepare-iwslt14.sh
https://github.com/facebookresearch/fairseq/issues/2110#issue-614837309
https://github.com/facebookresearch/fairseq/tree/main/examples/m2m_100















 2710
2710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









