







方案说明
我们的库存扣减,是基于 Redis+数据库的,先在 Redis 中做预扣减,然后再在数据库中做扣减。
但是我们有一种方案是没用 MQ的,而是在数据库中用了InventoryHint,他可以帮我们抗高并发的热点更新。
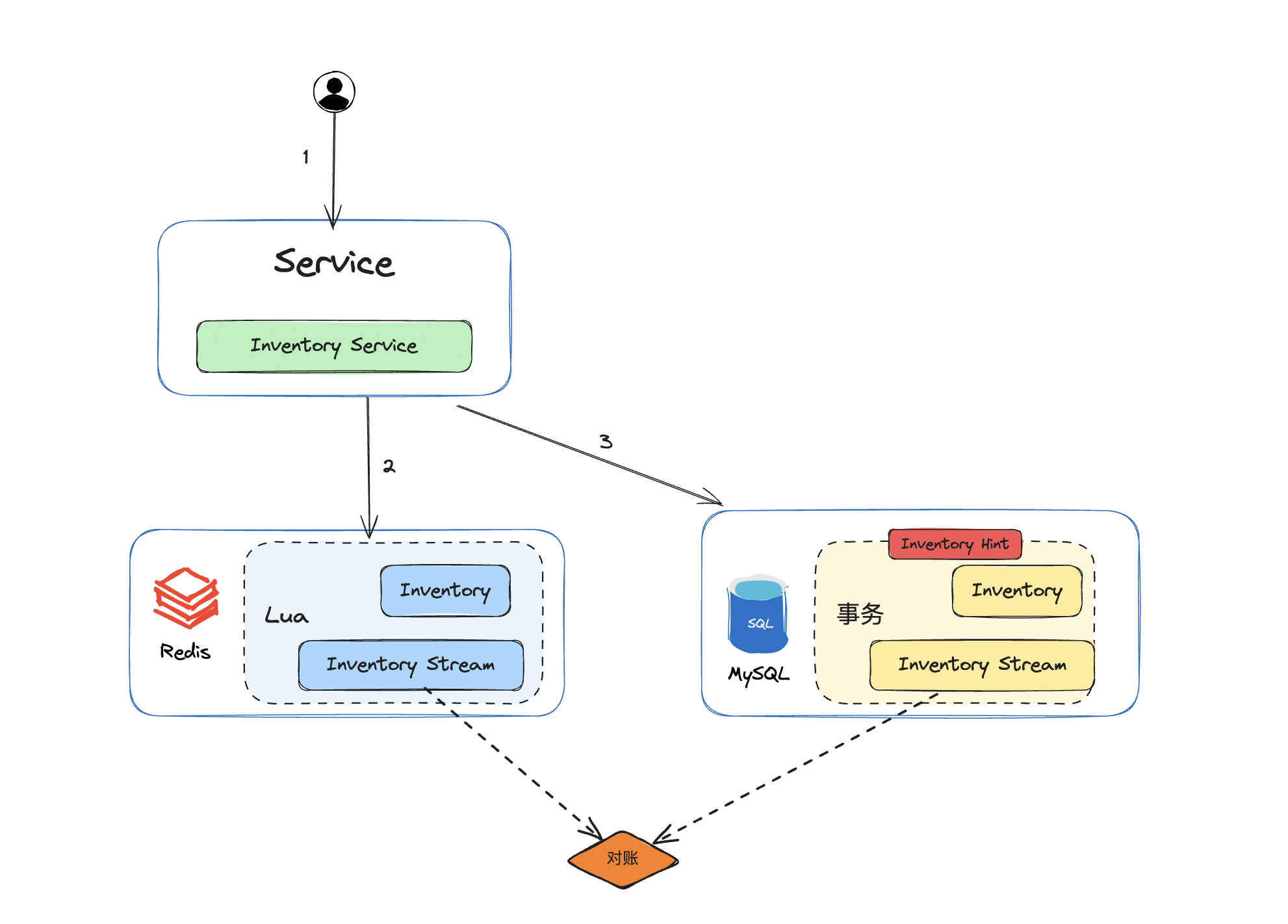
以上是整体的交互图,下面是更加详细的系统时序图。
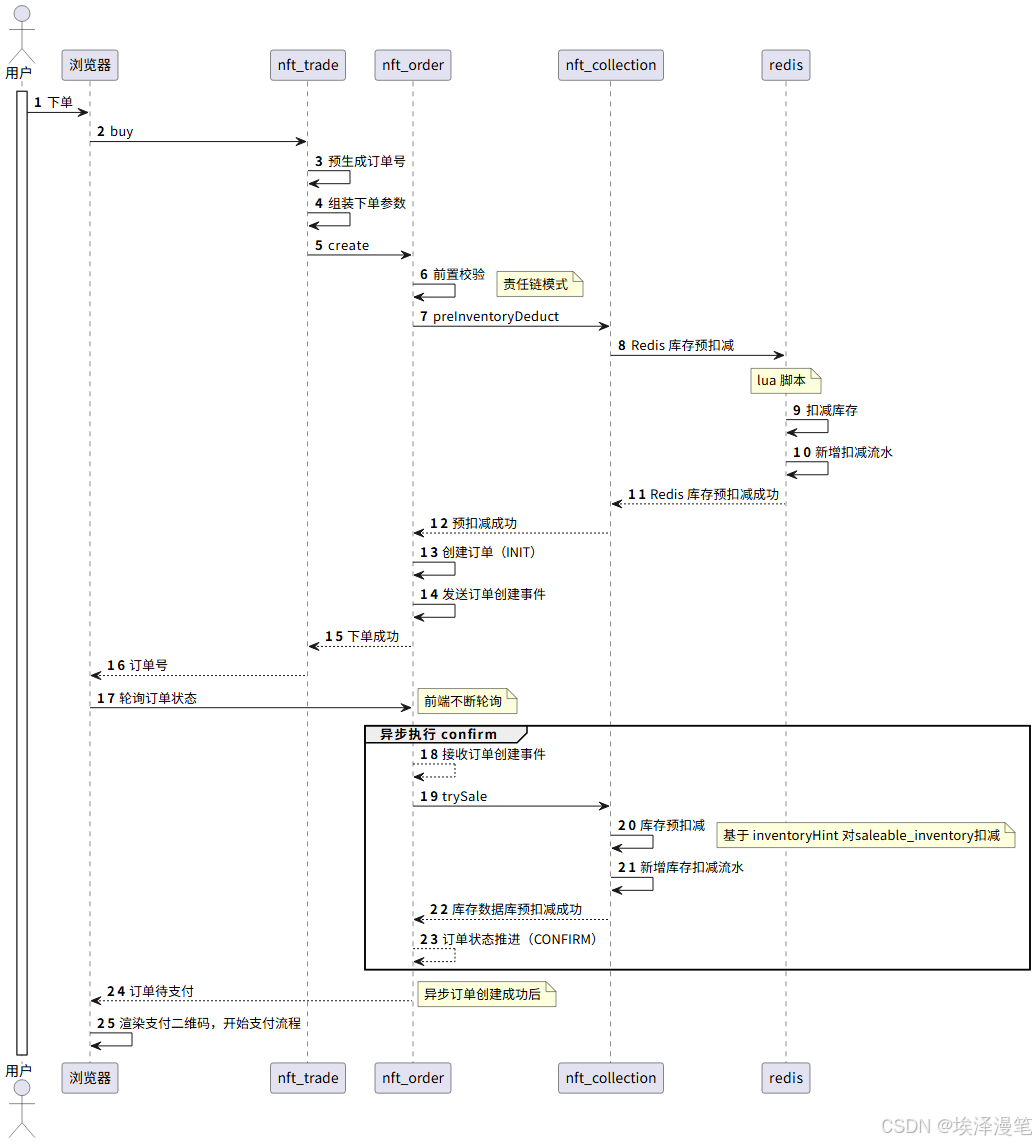
这里数据库在扣减的时候用了一个 InventoryHint
所谓Inventory Hint,其实就是一个补丁,是阿里云上的 RDS支持的一个功能。(官方介绍:https://help.aliyun.com/zh/rds/apsaradb-rds-for-mysql/inventory-hint )
因为我的项目中,数据库并不是自己搭建的,而是直接用的阿里云的 RDS,所以就用到了他的这个功能。
Inventory Hint的用法很简单,只需要在正常的update语句中增加上特殊的hint语句就行了,如:
<!-- 库存预扣减 -->
<update id="trySale">
UPDATE /*+ COMMIT_ON_SUCCESS ROLLBACK_ON_FAIL TARGET_AFFECT_ROW 1 */ collection
SET saleable_inventory = saleable_inventory - #{quantity}, lock_version = lock_version + 1
WHERE id = #{id} and <![CDATA[saleable_inventory >= #{quantity}]]>
</update>
<!-- 库存退还 -->
<update id="cancelSale">
UPDATE /*+ COMMIT_ON_SUCCESS ROLLBACK_ON_FAIL TARGET_AFFECT_ROW 1 */ collection
SET saleable_inventory = saleable_inventory + #{quantity}, lock_version = lock_version + 1
WHERE id = #{id} and <![CDATA[saleable_inventory + #{quantity} < quantity]]>
</update>
<!-- 库存占用 -->
<update id="confirmSale">
UPDATE /*+ COMMIT_ON_SUCCESS ROLLBACK_ON_FAIL TARGET_AFFECT_ROW 1 */ collection
SET occupied_inventory = occupied_inventory + #{quantity}, lock_version = lock_version + 1
WHERE id = #{id} and <![CDATA[occupied_inventory + #{quantity} < quantity ]]>
</update>我们的项目中,库存扣减这里采用了/*+ COMMIT_ON_SUCCESS ROLLBACK_ON_FAIL TARGET_AFFECT_ROW 1 */来标识 Hint。这里面的COMMIT_ON_SUCCESS、ROLLBACK_ON_FAIL和TARGET_AFFECT_ROW都是一些Hint语法:
- COMMIT_ON_SUCCESS:当前语句执行成功就提交事务上下文。
- ROLLBACK_ON_FAIL:当前语句执行失败就回滚事务上下文。
- TARGET_AFFECT_ROW(NUMBER):如果当前语句影响行数是指定的就成功,否则语句失败。
这样,我们的库存扣减如果出现热点,就能自动检测到,然后基于 Inventory Hint 的机制做高并发的热点更新了。
原理介绍
当我们是使用COMMIT_ON_SUCCESS等hint标记了一条SQL之后,就相当于告诉MySQL内核,这行可能是热点更新。
于是,MySQL的内核层就会自动识别带此类标记的更新操作,在一定的时间间隔内,将收集到的更新操作按照主键或者唯一键进行分组,这样更新相同行的操作就会被分到同一组中。
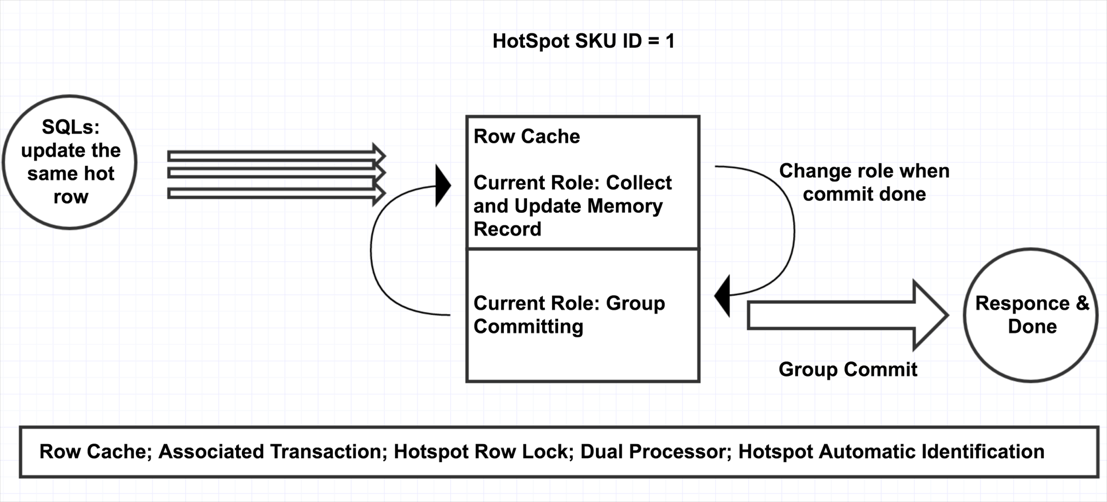
为了进一步提升性能,在实现上,使用两个执行单元。当第一个执行单元收集完毕准备提交时,第二个执行单元立即开始收集更新操作;当第二个执行单元收集完毕准备提交时,第一个执行单元已经提交完毕并开始收集新一批的更新操作,两个单元不断切换,并行执行。
根据热点行做了分组之后,就可以作进一步优化了,这个过程主要有3个关键的优化点:
1、减少行级锁的申请等待
在同一组中,需要更新的都是同一条记录,那么根据SQL的提交顺序,就可以排队了。
然后我们只需要在第一条更新SQL(Leader)执行的时候,尝试去获取目标行的锁,如果获取成功,则开始操作。
然后这一组中后续的更新操作(Follower)也会尝试获取锁,但是会先判断是不是已经被第一条更新操作获取到了,如果是的话,那么就不需要等待,直接获取锁。
这样就可以大大降低行级锁的申请的阻塞等待时长。
2、减少B+树的索引遍历操作
MySQL是以B+索引的方式管理数据的,每次执行查询时,都需要遍历索引才能定位到目标数据行,数据表越大,索引层级越多,遍历时间就越长。
如果针对热点行更新操作做了分组之后,我们只需要在每组的第一条SQL执行过程中,通过遍历索引定位数据行,之后就可以把这些数据行缓存到Row Cache中,并且在Row Cache进行修改。
在同组的后续操作时,也不再需要进行数据索引了,直接从Row Cache获取数据并修改就行了。
这样就大大降低了B+树的索引遍历操作的耗时。
3、减少事务提交次数
如果是没有用这种方式,我们的多条update语句会是多条事务,那么每一个事务都要单独做一次提交。
有了分组、排队、组提交之后,就只需要一组中的并发操作都执行完,然后做一次组提交即可,大大降低提交次数。


















 204
204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











