







概述
在java的工具包java.util包中
数组和集合类同是容器,有何不同?
数组长度固定,集合长度可变
数组可以存储基本数据类型,集合只能存储对象
数组只能存储同一类型的对象或数据,集合可以存储不同类型的对象
集合类的特点
集合只用于存储对象,集合长度是可变的,集合可以存储不同类型的对象
数据多了用对象存,对象多了用集合存
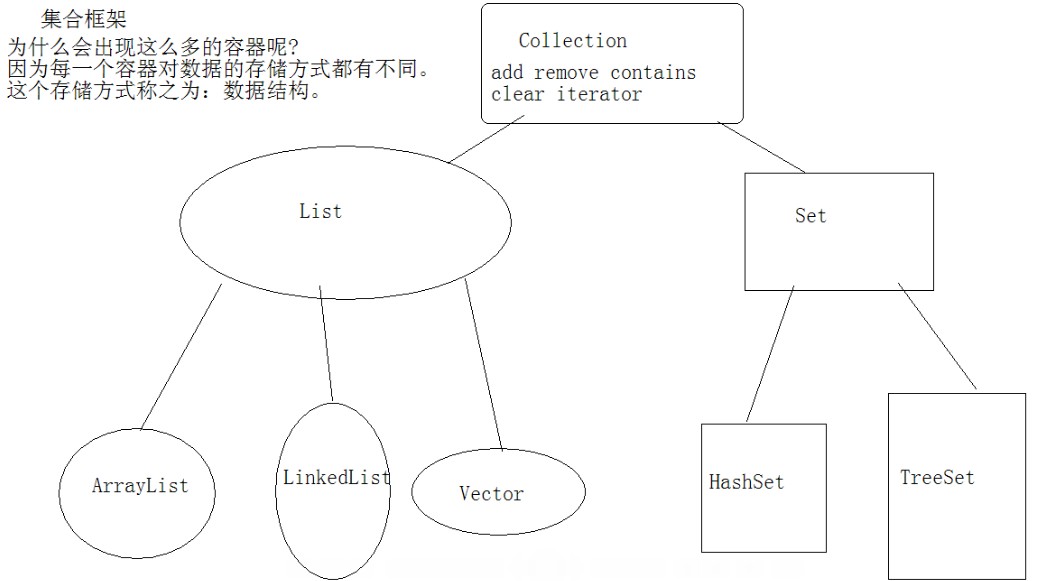
集合体系图
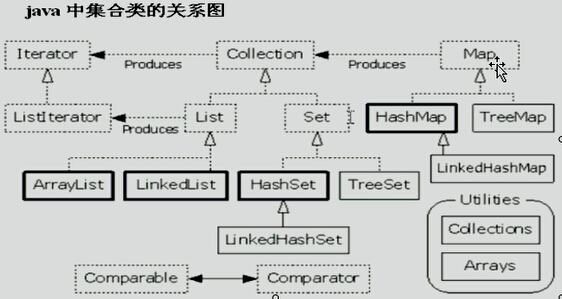
Collection
|---List
|---Set
Collection的共性方法
创建一个集合对象(以ArrayList为例):ArrayList al = new ArrayList();
Collection定义了集合框架的共性功能。
1,添加
add(e); //add方法的参数类型是Object。以便于接收任意类型对象。但是当存储自定义类型时,会发生自动类型提升为Object类型,所以要使用对象的特有方法,就要向下转型。
addAll(collection);
2,删除
remove(e);
removeAll(collection);
clear();
3,判断。
contains(e);
isEmpty();
4,获取
iterator();
size(); //数组是length变量,字符串是length()方法
5,获取交集。
boolean retainAll(Collection<?> c);//保留此 collection 中那些也包含在指定 collection 的元素
boolean removeAll(Collection<?> c);//移除此 collection 中那些也包含在指定 collection 的元素
Object [ ] toArray();
集合中存储的都是对象的引用(地址)
迭代器
其实就是集合的取出元素的方式。如同抓娃娃游戏机中的夹子。
迭代器是取出方式,会直接访问集合中的元素。所以将迭代器通过内部类的形式来进行描述。通过容器的iterator()方法获取该内部类的对象。
原理:为了可以直接访问集合内部的元素,就把取出方式定义在集合的内部,因此取出方式被定义成了
内部类,如果定义在外部还得创建集合对象访问里面的元素。又因为每一个集合容器的数据结构不同,所以取出的动作细节也不一样,但都有共性内容:判断和取出。那么可以将这个共性内容进行抽取,成为Iterator接口。这些内部类都符合一个规则,该规则就是Iterator。如何获取集合的取出对象呢?通过一个对外提供的方法iterator(); 比喻:娃娃机是容器,夹子是迭代器(很多大型游戏机夹子不一样),并且被封装在内部,娃娃是元素。
代码实现:
Iterator it = al.iterator(); //获取迭代器,al 为集合对象
while(it.hasNext())
{
sop(it.next());
}
国外:for循环结束it释放了,节省资源
for(Iterator it = al.iterator() ; it.hasNext() ; )
{
sop(it.next());
}
在迭代时,循环中next调用一次,就要hasNext判断一次
注意:next方法返回值类型是Object,一般需要进行强制转换
List
元素是
有序的(存入和取出顺序一致,要么先进先出-队列,要么先进后出-堆栈),元素
可以重复。因为该集合体系有
索引。
List集合判断元素是否相同,比如contains()方法,删除元素,比如remove(),底层都调用了元素的equals方法,当进行自定义判断对象是否相同时,比如定义同姓名同年龄为同一人要覆写Object类的equals()方法
List集合特有方法
凡是可以操作角标的方法都是该体系特有的方法
增
add(index, element);
addAll(index, Collection);
删
remove(index);
改
set(index, element);
查
indexOf(element);
get(index); //通过角标获取某个元素, 可以结合size()方法获取所有元素
subList(from, to);
listIterator();
列表迭代器listIterator
是List集合的特有迭代器,ListIterator是Iterator的子接口,可以对集合进行在遍历过程中的增删改查操作
在迭代时,不可以通过集合对象的方法操作集合中的元素,会发生ConcurrentModificationException异常
所以,在迭代时,只能用迭代器的方法操作元素,可是Iterator方法是有限的,只能对元素进行判断,取出,删除的操作,如果想要其他的操作如添加,修改等,就需要使用其子接口,ListIterator。
该接口只能通过List集合的listIterator方法获取。
List常见子类对象
ArrayList
最常用集合
底层的数据结构是
数组数据结构,特点:查询速度很快,但是增删稍慢。
线程不同步。可变长度数组,不断new数组产生的。
LinkedList
底层使用的是
链表数据结构,特点:增删速度很快,查询稍慢
特有方法
addFirst();
addLast();
getFirst();
getLast();
获取元素,但不删除元素。
removeFirst();
removeLast();
获取元素,但元素被删除。如果集合中没有元素,会出现NoSuchElementException
在jdk1.6出现了替代方法
offerFirst();
offerLast();
peekFirst();
peekLast();
获取元素,但是不删除元素。如果集合中没有元素,会返回null
pollFirst();
pollLast();
获取元素,但是元素会删除。如果集合中没有元素,会返回null
应用:用LinkedList模拟一个堆栈或者队列数据结构
/*
使用LinkedList模拟一个堆栈或者队列数据结构。
堆栈:先进后出 如同一个杯子。
队列:先进先出 First in First out FIFO 如同一个水管。
*/
import java.util.*;
class Queue
{
private LinkedList link;
Queue()
{
link = new LinkedList();
}
public void myAdd(Object obj)
{
link.addFirst(obj);
}
public Object myGet()
{
return link.removeLast();
}
public boolean isNull()
{
return link.isEmpty();
}
}
class Stack {
private LinkedList ll;
Stack(){
ll = new LinkedList();
}
public void add(Object obj){
ll.addFirst(obj);
}
public Object get(){
return ll.removeFirst();
}
public boolean isNull(){
return ll.isEmpty();
}
}
class LinkedListTest
{
public static void main(String[] args)
{
Queue q = new Queue();
q.myAdd("java01");
q.myAdd("java02");
q.myAdd("java03");
q.myAdd("java04");
while(!q.isNull())
{
System.out.println(q.myGet());
}
}
}Vector
底层是
数组数据结构。 线程同步。被ArrayList替代了,多线程自己加锁,也不用Vector
特有方法:
Enumeration elements();
枚举是Vector的特有取出方式,发现枚举和迭代器很像。其实枚举和迭代器是一样的,因为枚举的名称以及方法的名称都过长,所以被迭代器取代了,但是io流用到了枚举
Set
元素是
无序的(存入和取出的顺序不一定一致),元素
不可以重复。
Set集合的功能和Collection是一致的
HashSet
底层数据结构是
哈希表,线程不同步
哈希值是系统底层的哈希算法算出来的
哈希值一样,对象内容一致,就不会存进去。
不是同一对象,但是哈希地址值一样(比如覆写hashCode方法使其一样),就会顺延存储
HashSet是如何
保证元素唯一性的呢?
是通过元素的两个方法:hashCode和equals方法。
如果元素的HashCode值相同,才会判断equals是否为true
如果元素的hashCode值不同,不会调用equals
HashSet存储自定义对象
所以在描述自定义事物的时候需要向集合里面存储时,一般都需要覆写hashCode和equals方法
为了保证效率,即尽量不判断equals方法,就应该自定义hashCode方法,例如:
return name.hashCode()+age*39; // 乘以39(不是1就行)是为了保证自定义hash值得唯一性。
HashSet判断和删除元素的原理
对于判断元素是否存在,以及删除等操作,依赖的方法依次是元素的hashCode和equals方法,ArrayList只依赖equals方法(数据结构不同,所依赖的方法也不同)
/*
往hashSet集合中存入自定对象
姓名和年龄相同为同一个人,重复元素。去除重复元素
*/
import java.util.*;
class Person {
private String name;
private int age;
Person(String name, int age){
this.name = name;
this.age = age;
}
public int hashCode(){
return name.hashCode()+age*28;
}
public boolean equals(Object obj){
if(!(obj instanceof Person))
return false;
Person p = (Person)obj;
return this.name.equals(p.name)&&this.age == p.age;
}
public String getName(){
return this.name;
}
public int getAge(){
return this.age;
}
}
public class HashSetDemo {
public static void main(String[] args) {
HashSet hs = new HashSet();
hs.add(new Person("张三",22));
hs.add(new Person("李四",25));
hs.add(new Person("王五",22));
hs.add(new Person("李四",25));
for(Iterator it = hs.iterator(); it.hasNext();){
Person p = (Person)it.next();
System.out.println(p.getName()+"...."+p.getAge());
}
}
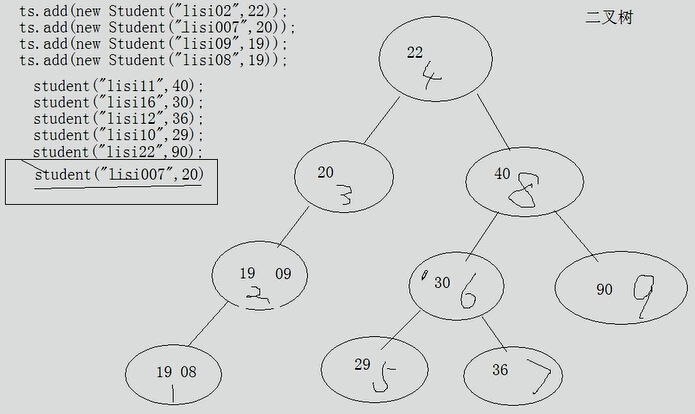
}TreeSet
可以对Set集合中的元素进行排序。底层数据结构是二叉树。保证元素唯一性的依据是compareTo方法的返回值,返回值为0代表两个对象相等,不会存入。
二叉树(红黑树)
减少比较次数,提高性能
TreeSet排序的两种方式
TreeSet排序的第一种方式(自然排序)
让元素自身具备比较性。元素的类必须要实现
Comparable接口,覆盖
compareTo方法才能被存入TreeSet集合,否则会出现异常:cannot be cast to java.lang.Comparable。String类已经实现了compareTo方法,可以直接存入TreeSet。这种方式也称为元素的自然排序,或者叫做默认排序,
/*
需求:
往TreeSet集合中存储自定义对象学生。
想按照学生的年龄进行排序。
*/
class TreeSetDemo
{
public static void main(String[] args)
{
TreeSet ts = new TreeSet();
ts.add(new Student("lisi02",22));
ts.add(new Student("lisi007",20));
ts.add(new Student("lisi09",19));
ts.add(new Student("lisi08",19));
//ts.add(new Student("lisi007",20));
//ts.add(new Student("lisi01",40));
Iterator it = ts.iterator();
while(it.hasNext())
{
Student stu = (Student)it.next();
System.out.println(stu.getName()+"..."+stu.getAge());
}
}
}
class Student implements Comparable//该接口强制让学生具备比较性。
{
private String name;
private int age;
Student(String name,int age)
{
this.name = name;
this.age = age;
}
public int compareTo(Object obj)
{
if(!(obj instanceof Student))
throw new RuntimeException("不是学生对象");
Student s = (Student)obj;
System.out.println(this.name+"....compareto....."+s.name);
if(this.age>s.age)
return 1;
if(this.age==s.age)//当主要条件相等时,一定要判断次要条件
{
return this.name.compareTo(s.name);
}
return -1;
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
}TreeSet排序的第二种方式(比较器)
当元素自身不具备比较性时,或者具备的比较性不是所需要的,这时就需要让集合自身具备比较性。在集合初始化时就有了比较方式
定义一个类实现
Comparator接口,定义比较器,覆盖里面的
compare方法,该方法传入两个比较的形参,将比较器对象作为参数传递给TreeSet构造函数(此处可以考虑匿名内部类)
class Student{
String name;
int age;
Student(String name, int age){
this.name = name;
this.age = age;
}
}
class MyComparator implements Comparator{
public int compare(Object o1, Object o2){
Student s1 = (Student)o1;//为了简略,这里没有判断对象类型
Student s2 = (Student)o2;
int num = new Integer(s1.age).compareTo(new Integer(s2.age));//通过此条语句简化书写,用num记录比值,直接返回,不需要条件判断语句
if(num ==0)
return s1.name.compareTo(s2.name);
return num;
}
}
public class TreeSetDemo {
public static void main(String[] args) {
TreeSet ts = new TreeSet(new MyComparator());
ts.add(new Student("李四",15));
ts.add(new Student("张三",12));
ts.add(new Student("张三",12));
ts.add(new Student("王五",34));
for(Iterator it = ts.iterator(); it.hasNext();){
Student s = (Student)it.next();
System.out.println(s.name+".."+s.age);
}
}
}
注意:如果两种方式都存在时,以比较器为主。
泛型
泛型概述
jdk1.5版本以后出现的新特性,用于解决安全问题,是一个类型安全机制。
问题代码:
class GenericDemo
{
public static void main(String[] args)
{
ArrayList al = new ArrayList();
al.add("abc01");
al.add("abc0991");
al.add("abc014");
al.add(4);//al.add(new Integer(4));自动装箱
Iterator it = al.iterator();
while(it.hasNext())
{
String s = it.next();
System.out.println(s+":"+s.length());//此处会出现运行错误ClassCastException,因为int型没有length方法
}
}
}
集合中存储不同类型元素,取出时会有安全问题,为了统一集合中的类型,使用泛型机制
好处:
- 将运行时期出现的问题ClassCastException转移到了编译时期,方便于程序员解决问题,让运行时期问题减少,安全。
- 避免了强转的麻烦。例:implements Comparator<String>
在使用java提供的对象时,什么时候写泛型呢?
通常在集合框架中很常见,只要见到<>就要定义泛型。其实<>就是用来接受类型的,当使用集合时,将集合中要存储的数据类型作为参数传递到<>中即可
泛型类
带泛型的类,强制让用户指定要操作的类型
什么时候定义泛型类?
当类中要操作的
引用数据类型不确定的时候,早期定义Object来完成扩展,现在定义泛型来完成扩展
class Utils<Q> {
private Q q;
public void setObject(Q q) {
this.q = q;
}
public Q getObject() {
return q;
}
}Utils<Worker> u = new Utils<Workter>();
u.setObject(new Worker());
Worker w = u.getObject();//这里不再需要强转了泛型方法
泛型类定义的泛型在整个类中都有效。泛型类的对象明确要操作的具体类型后,所有要操作的类型就已经固定了。
为了让给不同方法可以操作不同类型,而且类型还不确定,那么可以将泛型定义在方法上。
public <T> void show(T t) { }
泛型定义在方法上放到返回值类型的前面,修饰符的后面
静态方法的泛型
特殊之处:静态方法不可以访问类上定义的泛型。如果静态方法操作的引用数据类型不确定,可以将泛型定义在方法上
public static <w> void method (W w) { }代码示例
//定义一个Work和Student类
class Worker{}
class Student{}
//泛型前做法。
class Tool
{
private Object obj;
public void setObject(Object obj)
{
this.obj = obj;
}
public Object getObject()
{
return obj;
}
}
//使用泛型类
class Utils<QQ>{
private QQ q;
public void setObject(QQ q){
this.q = q;
}
public QQ getObject(){
return q;
}
}
class GenericDemo3
{
public static void main(String[] args)
{
Utils<Worker> u = new Utils<Worker>();
u.setObject(new Student());//编译器报错,该类的对象的方法不能使用student对象
Worker w = u.getObject();
/*
Tool t = new Tool();
t.setObject(new Student());
Worker w = (Worker)t.getObject();
*/
}
}泛型接口
interface Inter<T>
{
void show(T t);
}
class InterImpl implements Inter<String> //子类实现时已经指定类型
{
public void show (String t) { }
}
class InterImpl<T> implements Inter<T> //子类实现时没有指定类型
{
public void show (T t) { }
}泛型限定
对泛型进行限定,比如让传入的类型具备比较性
接收任意类型
一个通用的打印方法,可以接收任意类型的ArrayList集合
?表示不明确类型,叫做
通配符,也可以理解为
占位符
public static void printColl (ArrayList<?> al)
{
Iterator<?> it = al.iterator();
while(it.hasNext())
{
Sop(it.next());
}
}
T代表一个具体的类型
public static <T> void printColl (ArrayList<T> al)
{
Iterator<T> it = al.iterator();
while(it.hasNext())
{
T t = it.next(); // 可以对T类型的对象进行接收并操作
Sop(t);
}
}ArrayList<Student> al = new ArrayList<Person>(); //error 左右两边类型要一致,注意传参数时候也会出现该问题只接收父类型及其子类型
public static void printColl (ArrayList<? extends Person> al)
{
Iterator<? extends Person> it = al.iterator();
while(it.hasNext())
{
Sop(it.next());
}
}
? extends
E: 可以接受E类型或者E的子类型。上限 应用:addAll (Collection<? extends E> c)
?super E:可以接受E类型或者E的父类型。下限 应用:TreeSet的比较器 TreeSet (Comparator<? super E> comparator) 比较器里面的方法只能是父类的
Map集合
Map<K, V>
和Collection接口一样,都可以属于集合框架中的顶层接口
该集合存储键值对,一对一对往里存,而且要保证
键的唯一性
当数据之间存在映射关系时,就可以使用Map集合
Map集合共性方法
添加
V put(K key, V value) //
如果出现添加时相同的键,后添加的值会覆盖原有的键对应的值,并返回被覆盖的值,
putAll(Map<? extends K, ? extends V> m)
删除
clear()
V remove(Object key)
判断
containsKey(Object key)
containsValue(Object value)
isEmpty()
获取
V get(Object key) //可以通过get方法的返回值来判断一个键是否存在。通过返回null来判断
size()
Collection<V> values()
entrySet()
keySet()
Map子类对象
Map
|--Hashtable:底层是哈希表数据结构,不允许使用null作为键和值,该集合是同步的 jdk1.0 效率低
|--HashMap:底层是哈希表数据结构,允许使用null作为值和键,该集合是不同步的 jdk1.2 效率高
|--TreeMap:底层是二叉树数据结构,线程不同步,可以用于给map集合中的键进行排序
和Set很像。其实Set底层就是使用了Map集合
Map集合的两种取出方式
Set<K> keySet()
将map中所有的键存入到Set集合,因为Set具备迭代器,所以可以通过迭代方式取出所有的键,再根据get方法获取每一个键对应的值
Map集合取出原理:将Map集合转成Set集合,再通过迭代器取出
Set<String> set = map.keySet();
Iterator<String> it = set.iterator();
while(it.hasNext()){
// System.out.println(it.next());
String key = it.next();
System.out.println(key+"..."+map.get(key));
}Set<Map.Entry<K,V>> entrySet()
将Map集合中的映射关系存入到了Set集合中,而这个关系的数据类型就是
Map.Entry
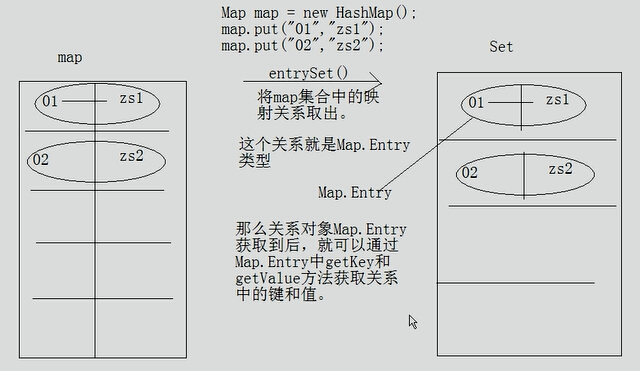
Set<Map.Entry<String,String>> set = map.entrySet();
Iterator<Map.Entry<String, String>> it = set.iterator();
while(it.hasNext()){
Map.Entry<String, String> me = it.next();
System.out.println(me.getKey()+"..."+me.getValue());
}
Map.Entry 其实Entry是Map接口中的一个内部接口
interface Map
{
public static interface Entry //该接口直接访问Map的成员,没有Map就没有映射关系,所以定义在Map内部
{
public abstract Object getKey();
public abstract Object getValue();
}
}
class HashMap implements Map
{
class Haha implements Map.Entry
{
public Object getKey() { }
public Object getValue() { }
}
}集合里面嵌套集合
例子:一个学校有多个教室,每个教室有多个名称,教室里的学生有学号
HashMap<String, HashMap<String, String>> school = new HashMap<String, HashMap<String, String>>();
HashMap<String, String> ban1 = new HashMap<String, String>();
HashMap<String, String> ban2 = new HashMap<String, String>();
将姓名和学号封装成学生对象以后,就要用Collection来存储了,因为没有了映射关系。
集合框架工具类Collections
专门对集合进行操作的工具类,
方法都是静态的,泛型都定义在方法上
排序sort
public static <T extends Comparable<? super T>> void sort (List<T> list); //让泛型具备比较性,不能给set排序,因为有TreeSet
public static <T> void sort (List<T> list, Comparator<? super T> c); //传入自定义比较器进行排序最值max
查找binarySearch
如果不存在,返回的是-(插入点)-1
替换
Collections.fill(list,"pp");//将集合中的元素全部替换为“pp”
Collections.repalceAll(list,"aaa","pp");//按元素替换
将list集合中部分元素替换成指定元素
反转
reverse(list) 将list集合中的元素顺序反转
逆转
Comparator<T> reverseOrder() ; 该方法返回一个Comparator,它强行逆转实现了Comparator接口的对象collection的
自然顺序
Comparator<T> reverseOrder(Comparator<T> cmp);返回一个比较器,强行逆转
指定比较器的顺序
使集合同步
synchronizedCollection(Collection<T> c)、synchronizedList(List<T> list)、synchronizedSet、synchronizedMap与之类似
置换list集合中两个元素的位置
swap(List<?>, int i, int j) 因为角标,只能置换List集合
随机置换
shuffle(List<?> list) 使用默认随机源对指定列表进行置换
应用:骰子,扑克牌,调用一次该方法,就洗牌一次
数组工具类Arrays
用于操作数组的工具类,里面都是静态方法
数组变字符串
Arrays.toString(arr):将arr变为字符串的形式,比StringBuffer简单
数组变集合
asList:将数组变成List集合,返回一个list集合
把数组变成list集合有什么好处?
可以使用集合的思想和方法操作数组中的元素,比如判断元素是否存在,不用再遍历数组,使用contains方法即可
注意:
- 将数组变成集合,不可以使用集合的增删方法,因为数组的长度是固定的,如果增删了,会发生UnsupportedOperationException,可以使用的方法有:contains,get,indexOf(),subList()
- 如果数组中的元素都是对象,那么变成集合时,数组中的元素就直接转成集合中的元素;如果数组中的元素都是基本数据类型,那么会将该数组作为集合中的元素存在
集合变数组
Collection接口中的toArray方法
Object [ ] toArray ( ) :返回包含此 collection 中所有元素的数组。
<T> T [ ] toArray (T [ ] a ); 传入一个指定类型的数组,返回一个与指定类型的数组类型相同的数组,不再需要强转
指定类型的数组到底要定义多长?
当指定类型的数组长度小于集合的size,该方法的内部会创建并返回一个数组长度为集合的size
当指定类型的数组长度大于集合的size,该方法不会创建新的数组,而是使用传递进来的指定类型的数组
所以创建一个刚刚好的数组最优:String [ ] arr = al.toArray (new String [
al.size() ] );
为什么要将集合变数组?
为了限定对元素的操作,比如增删,而只能进行查询和获取
高级for循环
为了简化迭代器的书写
格式:
for (数据类型 变量名 :被遍历的
集合(Collection)或者数组 ) //Map不支持迭代!
{
}
对集合进行遍历,只能获取元素,但是不能对集合进行操作,而且在集合上需要加上泛型,否则编译出错
迭代器除了遍历,还可以remove集合中的元素
如果使用ListItetator,还可以在遍历过程中对集合进行增删改查的操作
传统for和高级for有什么区别?
高级for有局限性,必须有遍历的目标
建议在遍历数组的时候还是用传统for,因为传统for可以访问数组角标
方法的可变参数
jdk1.5出现的一个新特性
当需要传多个相同类型的参数到一个方法中时,为了避免函数过多重载和定义多个数组,使用可变参数。
其实就是数组参数的简写形式,不用每一次都手动建立数组对象,只要将操作的元素作为参数传入即可,隐式将这些参数封装成了数组
格式 method ( int . . . arr ) { }
在使用时注意可变参数一定要定义在
参数列表的最后面,否则编译不通过
静态导入StaticImport
import
static java.util.Arrays.*;//导入的是Arrays这个类中所有的静态成员
注意此时如果直接使用Arrays类中的toString(arr)方法会编译失败,因为默认是Object类中的同名无参方法,此时必须要写Arrays.toString(arr)原因如下:
当类名重名时,指定具体的所属包名
当方法重名时,指定方法所属的对象或者类
import 后加static时,导入的时某一个类中所有的静态成员,不加static,导入的都是包中的类















 562
562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









