









TITLE: Understanding intermediate layers using linear classifier probes
AUTHOR: Guillaume Alain, Yoshua Bengio
ASSOCIATION: Université de Montréal
FROM: arXiv:1610.01644
CONTRIBUTIONS
The concept of the linear classifier probe (probe) is introduced to understand the roles of the intermediate layers of a neural network, to measure how much information is gained at every layer (answer : technically, none). This powerful concept can be very useful to understand the dynamics involved in a deep neural network during training and after.
Linear Classifier Probes
Probes
The probes are implemented in a very simple manner, that using a fully-connected layer and a softmax as a linear classifier. The classifier’s error takes NO part in the back-propagation process and is only used to measure the features’ ability of solving classification problems, which are extracted from different layers of different depth in the network.
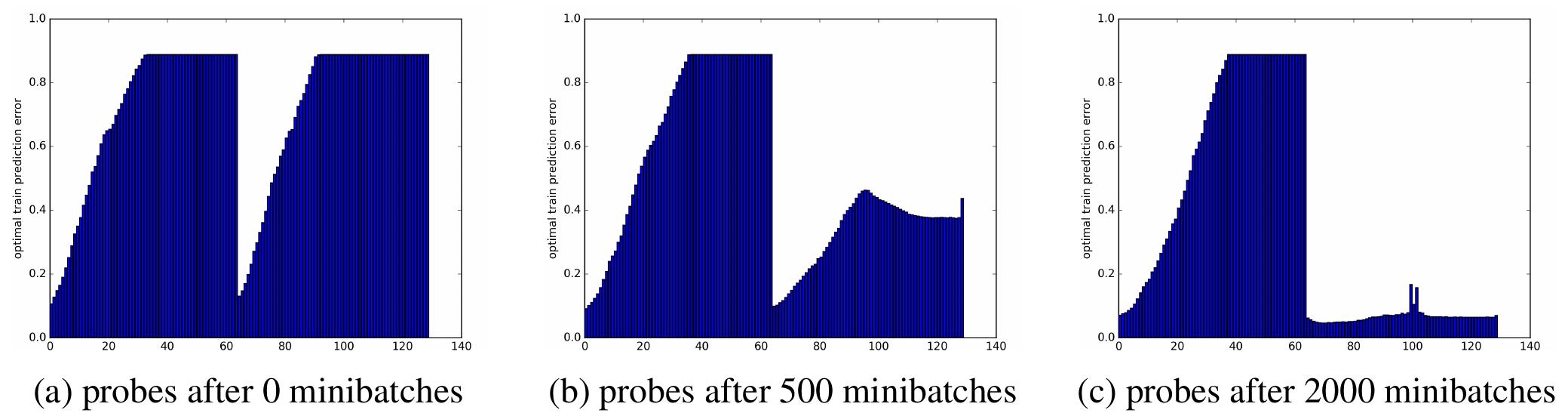
Probes on untrained model
Given an untrained network, the probes are set to see whether each layer would give useful features for a classification task. The data is generated from a Gaussian distribution, a very easy task.
The probe to layer 0 corresponding to the raw data are able to classify perfectly. And the performance degrades when applying random transformations brought by the intermediate layers. The phenomenon indicates that at the beginning on training, the usefulness of layers decays as we go deeper, reaching the point where the deeper layers are utterly useless. The authors give a very strong claim: garbage forwardprop, garbage backprop
Auxiliary loss branches and skip connections
From the experiment in the paper, it seems that Auxiliary loss branches help make the untrainable model trainable.
From another experiment, if we added a bridge (a skip connection) between layer 0 and layer 64, the model completely ignores layers 1-63. The following figure illustrates the phenomenon.
Some Ideas
- the probes can be used to visualize the role of each layers.
- ResNet is really necessary? Why it works if the skip will ignore the layers it covers.
- Training stage by stage could be very useful when a very deep network is use.















 1891
1891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









