







你是否已然深陷对 DeepSeek “无所不能” 的沉迷?
写方案,全靠它!做 PPT,全靠它!甚至身体略有不适,也想向它求救!
然而,你可曾料到,这个被无数人奉为圭臬的 DeepSeek,竟会 “一本正经地胡诌八扯”?
别被蒙蔽了双眼,人工智能(AI)绝非万能!如今,已有不少人因过度信赖 DeepSeek 而惨痛 “中招”,你还要继续盲目跟风吗?
高校教授的烦恼
广州一所著名大学的教授,最近在朋友圈里抱怨DeepSeek查文献“太不靠谱”。
事情是这样的,这位教授想用DeepSeek查一本叫《Global Cantonese: The Spread of Cantonese Language and Culture》的书的信息。结果一查,发现DeepSeek给出的信息全是错的!作者是假的,出版年份也错了,出版社更是八竿子打不着。

教授很生气,就去找DeepSeek理论。DeepSeek也挺实诚,承认了错误,还感谢教授指正,表示很抱歉。
这事儿听起来有点离谱,但可不是个例。现在用AI的人越来越多,AI出错的情况也越来越常见。
知名媒体人的“被创作”经历
知名媒体人、人民日报海外版原总编辑詹国枢,也发表文章说DeepSeek有个“致命伤”——说假话。
老詹亲自体验了一把,让DeepSeek写一篇《史记·詹国枢列传》。结果呢?开头第一句,老詹的出生地、母亲姓氏等基本信息,就被“张冠李戴”了,完全是瞎编。
老詹还不死心,又让DeepSeek写一篇关于某位记者的文章。DeepSeek写得那叫一个文采飞扬,案例也挺多。结果拿给记者本人一看,人家直接否认了,说一个案例都不是自己写的。
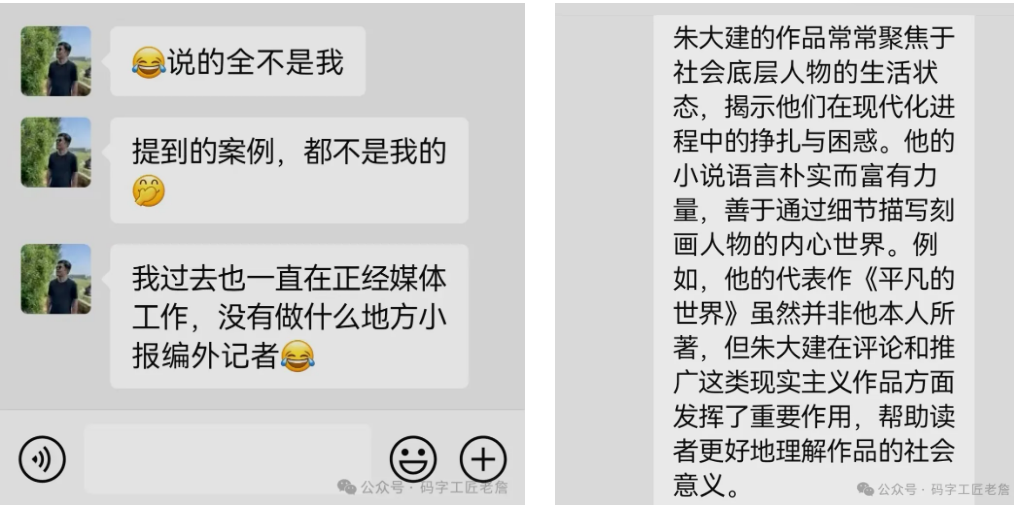
大家都说DeepSeek文采好,文学水平高。老詹就让它评价一下路遥的名著《平凡的世界》。结果DeepSeek说这是詹国枢老班长的代表作!
这要是让小孩子看了,那还不得误人子弟?
西安道路规划的“静默区”谜团
陕西有个自媒体叫“决明子”,一直不明白西安安定门那里的道路规划,为啥要绕一圈。他问过交警、出租车司机,都没人能说清楚。看到DeepSeek挺火,就想试试。他问DeepSeek:“西安的道路路线规划,从环城西路北段到环城西路南段为什么不直行,非得在安定门绕一圈?”
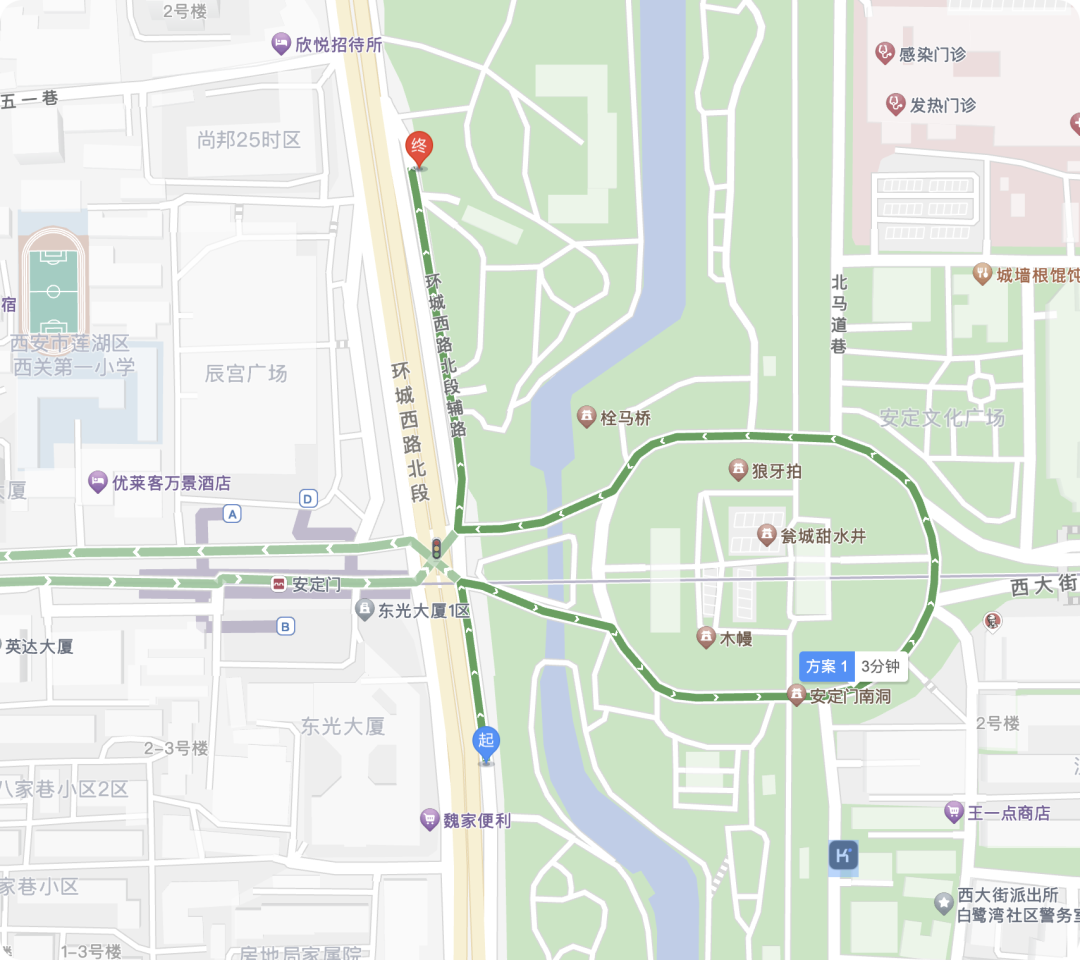
这下,DeepSeek可来劲了,开始了他的“表演”。
DeepSeek先是提出了一个“唐皇城交通静默区”的概念,说根据《西安历史文化名城保护规划(2020-2035)》,安定门周边划定了一级静默区、二级静默区,这是为了保护文物,防止过大的震动。他还列出了具体的空间数据,说距离增加多少、振动传递深度变化是多少。
听起来是不是很专业?有理论、有数据、有政策,可信度很高。
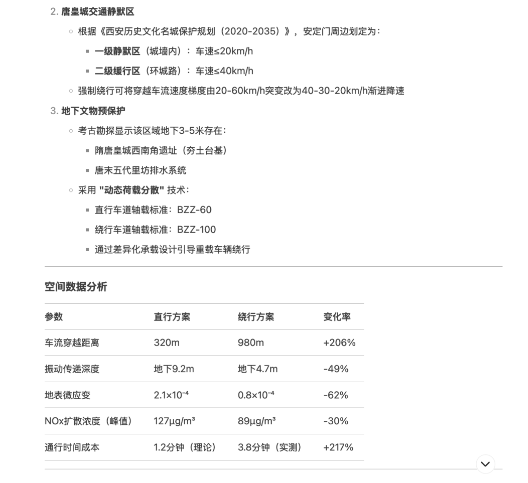
但是,“决明子”一查,发现这份《西安历史文化名城保护规划(2020-2035)》文件中,压根就没有什么“静默区”。这个看似极为专业、有理有据的回答,居然是DeepSeek自己“编”的。
“决明子”把这个情况反馈给DeepSeek。DeepSeek也很老实,承认错误,说文件里确实没有“静默区”的说法。但是,随后他又做出了新的修正和澄清,继续“编织”自己的答案。
AI的精心包装,让编的材料看起来如此真实,如同“有意识”地在操控一般,真有些让人觉得可怕。
DeepSeek为什么会“说假话”?——AI幻觉
那么,DeepSeek为啥要不懂装懂,甚至“说假话”呢?
这就要说到一个词——AI幻觉。
在人工智能领域,人们用这个词来形容AI“说假话”的现象。也就是说,AI输出的回答,表面上看内容合理、连贯,但实际上和输入的问题不符,和真实的世界知识不符,或者和已知的、可以验证的数据不符。
这可不是DeepSeek一家的问题。去年8月,一家叫Arthur AI的人工智能公司发布了一份报告,比较了OpenAI、Meta、Anthropic以及Cohere公司开发的大语言模型出现幻觉的概率。结果显示,这些厉害的大模型都会产生幻觉。
就连大洋彼岸最厉害的ChatGPT,也和DeepSeek一样“满嘴跑火车”。
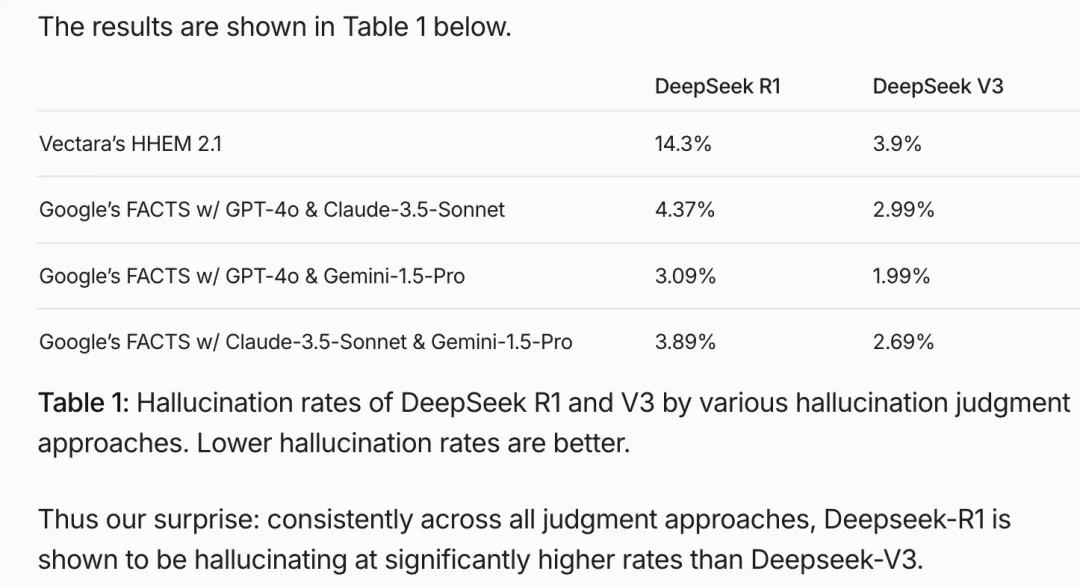
只不过,相比起其他AI,DeepSeek-R1的“幻觉”现象更明显一些。在一个叫Vectara HHEM人工智能幻觉测试(这是一个行业权威测试,通过检测语言模型生成的内容是否与原始证据一致,来评估模型的幻觉率)中,DeepSeek-R1的幻觉率达到了14.3%。
这不仅比它之前的版本DeepSeek-V3高了近4倍,也远超行业平均水平。
DeepSeek自己也承认了“技术局限性认知”,说现在的大模型生成内容的底层逻辑是基于概率的,所以确实存在生成信息可信度不高的问题。
简单来说,就是不“保真”。
互联网上的内容,不管是真的还是假的,都可能变成DeepSeek的引用素材。而它只负责根据已有的内容推理,不对信息本身负责。
DeepSeek-R1的“幻觉”为什么更严重?
DeepSeek-R1的幻觉之所以更加严重,是因为它加强了“思维链”(CoT)和创造力。
比如说,DeepSeek-R1写诗,不仅能写五绝、七律,而且“起承转合”也很流畅,对诗的意境也有自己的理解。有网友说,DeepSeek-R1写的诗比祖传的《唐诗三百首》还工整,让中文系毕业的学生都觉得惭愧。
甚至有人发出了这样的疑问:AI随手写一句诗都比中文系教授写得好,人类的文学还有必要存在吗?人类还能再诞生出伟大的诗人吗?
DeepSeek-R1之所以有这么强大的创作力,是因为在文科类任务的强化学习训练过程中,模型的创造性被不断鼓励。
就像“出门问问”大模型团队前工程副总裁、Netbase前首席科学家李维说的那样:“大模型是天生的艺术家,不是死记硬背的数据库。”
但是,“副作用”也随之而来。
比如在“思维链”的强化过程中,DeepSeek-R1不是对摘要、翻译、新闻写作这类相对简单的任务进行优化,而是增加各种层面的思考,会不断地延伸。
于是,面对复杂或者有难度的问题,它能超常发挥,甚至给出意想不到的答案。但是,当面对一些简单的任务时,DeepSeek-R1则可能因为习惯了深度思考,而过度发挥。
这就好比,你问它“隔壁老王有多高”,它可能就懵了,因为它没见过老王,也不知道你到底问的是哪个老王。但它又不得不回答,于是它就开始“脑补”,根据“一般人有多高”这个学到的概念,给你编织一个答案。
所以,DeepSeek-R1在“理科”方面更有逻辑性,而在“文科”方面则因为喜欢“发挥”,可能把不相干的内容关联起来胡编乱造,甚至彻底翻车。
AI 时代,我们该如何应对?
在这个 AI 时代加速到来的当下,我们比以往任何时候都更迫切地需要追寻真相,提升辨别是非和独立思考的能力。
今年过年时,在知乎一个关于 “如何看待冯骥盛赞 ‘DeepSeek’” 的问题下,一位自称 “DeepSeek 创始人梁文锋” 的用户发表了回复。这段回复有场景、有细节,有气魄、带感情,让许多人看了都深受感动。
然而,令人震惊的是,这段话竟然是假的!后来经证实,这个知乎账号在除夕发布的这段话,并非梁文锋本人所写,很可能是 DeepSeek 自己生成的。也就是说,DeepSeek 生成的广为流传的 “第一个假新闻”,矛头直指其创始人。
更令人不安的是,这份回应竟然如此契合人们对梁文锋的想象,以至于在科技界和金融界被疯狂传播。有人仅将截图发到公众号文章,就获得了 2.6 万转发。很少有人怀疑这个 “梁文锋” 是假的,反而有不少读者留言夸赞他 “有情怀”“让人热泪盈眶”“为年轻一代创业者点赞”……
这种现象,恰恰揭示了我们面临的风险,为 AI 时代的来临敲响了警钟。
今年 1 月,世界经济论坛发布了《2025 年全球风险报告》。报告显示,虚假信息和错误信息连续两年位居短期风险首位,对社会凝聚力和治理构成了巨大威胁,它们会破坏公众信任,加剧国内外矛盾。AI 聊天机器人的存在,正在加剧这种风险。Vectara 公司针对文档内容的一项研究显示,一些聊天机器人编造事实、虚构信息的几率高达 30%。
哈尔滨工业大学(深圳)的张民教授长期从事自然语言处理、大模型和人工智能研究。他表示,现阶段 AI 幻觉很难完全消除,也就是说,DeepSeek 等大模型会说假话,短期内无法避免。
作为使用者,我们能做的就是找到 AI 的正确使用方法,避免 “上当”。例如,最简单的方法就是勤快一点,通过其他搜索引擎对比查询,或者针对 DeepSeek 在回答中引用的网页消息源,点击进去查看提到的案例是否真实存在。
归根结底,AI 并不能让人一劳永逸,反而提出了更高的要求,包括如何提问、如何与 AI 对话以及如何辨别信息等。最终,人与人之间的差距可能会因此变得更大。
到最后,人与人的差距可能会变得更大。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











