









论文源地址:http://aclweb.org/anthology/D/D14/D14-1074.pdf
参考:http://blog.csdn.net/wty__/article/details/52677834
Abstract
我们提出了一种基于递归神经网络的中国诗歌生成模型,我们认为这是一个非常适合捕捉诗歌的内容和形式的神经网络模型。 我们的生成器通过以下三个方面来实现内容(“what to say”)和表达(“how to say”):意象的表示以及把它们组合形成一行或多行,以及意象之间如何相互加强和约束。
通过考虑到迄今为止所产生的所有诗句而不是由前面的几行诗所限定的范围来生成诗。 实验结果表明,我们的模型优于使用自动和手动评估方法的中国诗歌生成系统。
1 Introduction
古典诗是中国文化遗产的重要组成部分。 它们的普及表现在日常生活的许多方面,例如作为表达个人情感,政治观点或在节日和葬礼上传达信息的手段。 在古典中国诗歌的许多不同类型中, 四行诗和律诗也许是最著名的。 这两种类型的诗必须符合一种特定结构,语音和语义的要求。
四行诗第二行和第四行要满足押韵,而第一行可以不押韵,第三行不押韵。
诗歌要满足平仄。
尽管电脑不能创造诗歌,但是电脑可以分析大量诗歌文本,并产生大量变体。而且外行诗人可能很难分辨出声调和结构约束,而电脑可以直接检查诗歌是否满足要求。诗歌生成在过去几年中受到相当多的关注,数十种计算系统被用来制作不同的诗歌。 除了建立能够创造有意义的诗歌的自主智能系统的长远目标之外,在电子工程和互动功能的不断增长的行业中,电脑生成的诗歌还有潜在的短期应用,如教育。 诗歌构成的辅助环境可以让教师和学生根据自己的要求创作诗歌,增强写作经验。
与以前的方法相比,我们的生成方法没有通过马尔科夫假设来确定依赖相同句中的或者不同句中的词的依赖关系。
2 Related Work
大多数的方法利用模版通过一些约束(例如押韵,韵律,重读和词频)把基于语料库和词典的资源组合成诗歌。
第二种方式是利用遗传算法生成诗歌。Manurung et al. (2012)认为机器生成的诗歌必须满足语法规范,有意义,而且像诗(能够被区分)。他们的模型产生一些候选诗,并从中选择符合要求的诗。
第三种方式从统计机器翻译和文本生成应用 (比如摘要)中获得灵感。
- Greene et al. (2010) 从诗歌的语料库中推断韵律,接下来用加权重的以IBM Model 1插入的有限状态转换器来利用诗歌语料库生成诗歌。
- Jiang and Zhou (2008)利用基于短语的SMT把对联的第一行转换成为第二行,从而生成对联。
- He et al. (2012)把上面算法扩展成为生成四行诗,把上一行诗转换成下一行诗。
- Yan et al. (2013)基于以查询为重点的总结框架生成四行诗。他们的系统需要几个关键字作为输入,从文本库中检索相关诗歌。被检索的诗歌然后被分割成为组成术语,这些术语又被分为几类。迭代的从那些术语类中选择术语并按照一定的韵律和结构连贯的组合在一起,最后生成诗。
我们的方法和上述方法的区别主要在两方面:
1. 使用递归神经网络。
2. 考虑上下文 生成每行诗,而不是直接生成。
3. The Poem Generator
就像之前的工作中,我们假设我们的生成器在交互式环境中工作。特别的,使用者提供关键字,强调中心思想。我们假设这些关键字都是出于ShiXueHanYing诗歌短语分类系统。ShiXueHanYing包括1026手工分类短语。每一个分类用一个关键字来标识。生成器基于关键字生成第一行诗,后序几行诗基于前面生成的几行诗来生成并且取决于音律和结构的限制。

为了创建第一行诗,我们选择了所有与关键字有关的短语并产生了所有可能的符合要求的组合。我们使用一个语言模型对所有候选诗句进行排序并且选择排名最高的作为第一行诗。作者使用了基于单个字符的RNN网络加上Kneser-Ney trigram来作为语言模型(避免了对古诗的分词)。
对于行
Si+1=w1,w2,…,wm
,给定所有之前的行
S1:i
时,预测:
当前行中的每一个词 ωj 基于前面生成的词 ω1:j−1 和前面几行诗 S1:i .这说明 P(Si+1|S1:i) 对之前生成的内容和当前生成的词敏感。
P(Si+1|S1:i) 的评价是我们模型的核心。

3.1 CSM
CSM把一行诗转换为一个向量。原则上来说,任何能够产生基于向量的短语或句子的模型都可以使用。我们使用 Kalchbrenner and Blunsom 推荐的CSM模型,,因为其使用的是单个字符而不是词语。
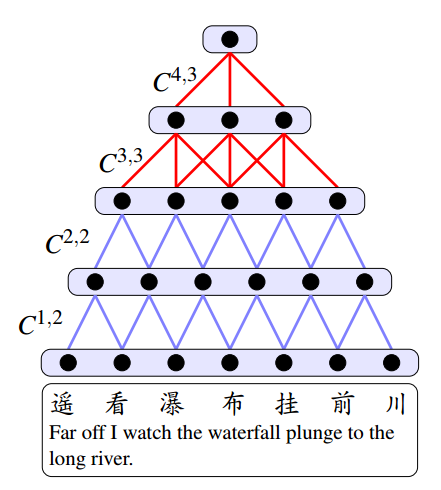
对于上述网络:
其中:
- Nl 是上图中第l层节点的个数
- q是隐含层节点的个数,即因空间的维度
- n表示当前层(第l层)计算下一层节点时使用的节点数量
- Tl∈Rq×Nl 是上图中第l层的表示
- Cl,n∈Rq×n 是一个权重矩阵,用于将第l层的n个节点计算出l+1层的一个节点的值
- ⊙ 是按元素的向量乘法
- σ 是非线性函数
- ω 是词典中的一个词语
- e(w)∈R|V|×1 是 ω 的独热码(one-hot)
- L∈Rq×|V| 是转换矩阵,矩阵的每一列都是一个字符向量
3.2 RCM
RCM把代表生成的所有i行诗的向量作为输入,并把它们压缩成为一个向量,然后用于生成下个字符。我们把这个压缩向量译码对应当前行不同字符的位置。输出层由几个向量组成。

表达式:
其中:
- q是隐含层的节点个数,即隐空间的维度。
- hi∈Rq×1 ,隐层状态。
- vi∈Rq×1 ,CSM模型的输出,即第i 行句子的向量表示。
- M∈Rq×2q 权重矩阵
- Uj∈Rq×q 权重矩阵
- uji∈Rq×1 输出
- σ 非线性函数
- m是当前行的字符个数
3.3 RGM
RGM本质上是递归神将网络有一个额外的输入层。
用
=ω1,ω2,⋯,ωm
表示生成的诗句,而前 i 行诗已经被编码成为向量
uji
,所以:
P(Si+!|S1:i)=∏m−1j=1(ωj+1|ω1:j,uji)

表达式:
其中:
- q是隐含层的节点个数,即隐空间的维度。
-
ri∈Rq×1
,隐含层的状态
-
uji∈Rq×1
,RCM网络的输出
-
yj∈R|V|×1
,RGM网络的输出
-
ω
是词典中的一个词语
-
e(w)∈R|V|×1
是w的独热码(one-hot)
-
R∈Rq×q
-
X∈Rq×|V|
-
H∈Rq×q
-
Y∈R|V|×q
-
σ
是非线性函数
网络最后的输出采用 softmax 进行激活,即:
P(wj+1=k|w1:j,uji)=exp(yj+1,k)∑|V|k=1exp(yj+1,k)
3.4 Training
网络的目标函数采用交叉熵损失:预测的字符和语料中实际字符的交叉熵。
3.5 Decoding
我们的解码器是一个堆。它贯彻声调模式和押韵要求。一旦第一行诗生成,它的声调模式就确定了。















 238
238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









